













再次因数据错误而在半夜醒来,你是否曾梦想过一个理想的数据世界,在那里查询可以在几秒内返回结果,数据永不丢失,成本如此之低以至于你的老板都会面带微笑?听起来像是梦想吗?不!这正在变成现实。
还记得那个夜晚你被数据分区问题压垮的时刻吗?产品经理在拼命推动进展,而你却在处理分散的数据时苦苦挣扎?跨源查询像蜗牛爬山一样慢,而架构更改需要跨越七个部门进行协调。
但是现在,这些痛点正在被重写。
Apache Doris和Iceberg的结合正在重新定义数据湖的工作方式。这不仅仅是简单的1+1=2;它带来了质的飞跃:秒级查询、无缝架构演进和真正的数据一致性保证。
Doris和Iceberg的完美交响曲
在数据工程领域,我们经常会遇到这样的问题:
小张正在处理一个数据分析需求,需要分析过去三个月的用户行为数据。这些数据分散在Hive数据仓库、业务数据库和对象存储中。跨源联接性能差,查询需要超过40分钟,数据不一致经常发生。
此外,小张还必须处理数据治理工作,每次表结构更改都让他头疼不已。多个下游应用程序依赖于这些表,架构更改需要跨多个团队协调,可能需要一周的时间才能完成一次更改。
这些问题随着数据的爆炸性增长变得更加突出。数据仓库和数据湖的传统分离已经无法满足需求。
幸运的是,在2.1版本中,Apache Doris的Lakehouse架构已经得到显著增强。它不仅提升了主流数据湖格式(Hudi、Iceberg、Paimon等)的读写能力,还引入了多SQL方言兼容性,允许从现有系统无缝切换到Apache Doris。在数据科学和大规模数据读取场景中,Doris集成了Arrow Flight高速读取接口,实现了数据传输效率提升100倍。
因此,小张决定在他的赎回中使用Doris + Iceberg。
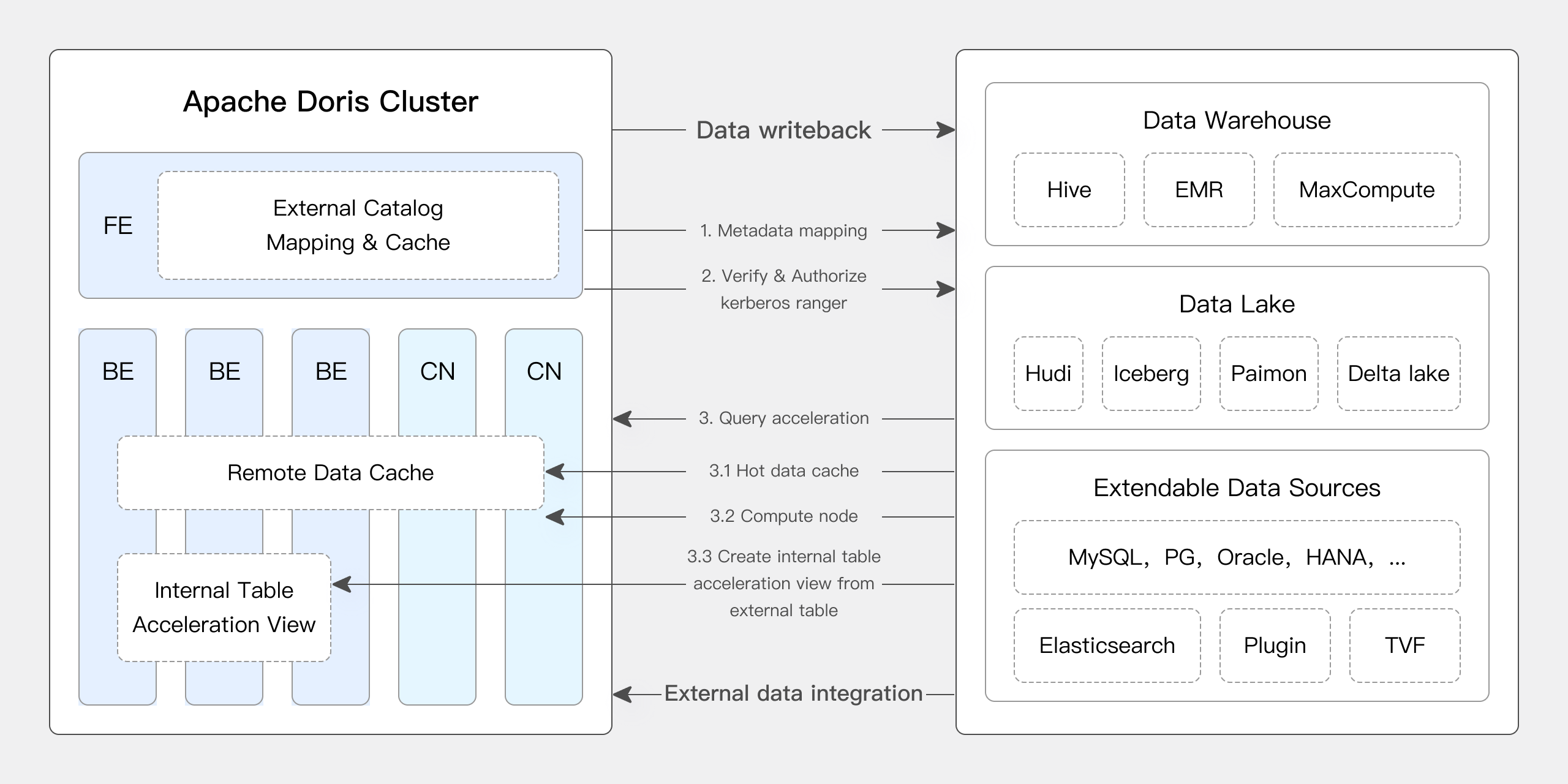
Apache Doris原生支持Iceberg的许多核心功能:
- 支持各种Iceberg Catalog类型,如Hive Metastore、Hadoop、REST、Glue、Google Dataproc Metastore和DLF。
- 原生支持Iceberg V1/V2表格格式,以及读取Position Delete和Equality Delete文件。
- 支持通过表函数查询Iceberg表格快照历史。
- 支持时间旅行功能。
- Apache Doris原生支持Iceberg表引擎。Apache Doris可以直接创建、管理和写入Iceberg表中的数据。它支持一整套分区转换函数,提供了隐藏分区和分区布局演进等功能。
此外,Doris 2.1.6版本带来了对Doris + Iceberg的重大升级:
Apache Doris支持对Iceberg进行DDL和DML操作。用户可以通过Apache Doris直接在Iceberg中创建数据库和表,并向Iceberg表中写入数据。
通过这一特性,用户可以使用Apache Doris在Iceberg上执行完整的数据查询和写入操作,进一步简化湖仓架构。
因此,小张可以快速构建基于Apache Doris + Apache Iceberg的高效湖仓解决方案,灵活满足实时数据分析和处理的各种需求:
- 利用Doris的高性能查询引擎从Iceberg表和其他数据源中联接和分析数据,构建统一的联邦数据分析平台。
- 在Doris中直接管理和构建Iceberg表,清洗和处理数据,并将其写入Iceberg表,构建统一的湖仓数据处理平台。
- 通过Iceberg表引擎将Doris数据与其他上游和下游系统共享,以进一步处理,构建统一的开放数据存储平台。
这不再是简单的表面集成,而是湖仓架构的深度融合!
多瑞丝(Doris)和冰山(Iceberg)的实用总结
在探索和实践中的一系列起伏之后,小张总结了一些关于Doris + Iceberg的实用经验:
智能元数据管理
在传统解决方案中,元数据管理一直是一个棘手的问题。表分区信息、文件位置和模式更改历史散落在各处,导致查询性能差、操作和维护复杂。
Doris + Iceberg提供了统一的元数据管理层:
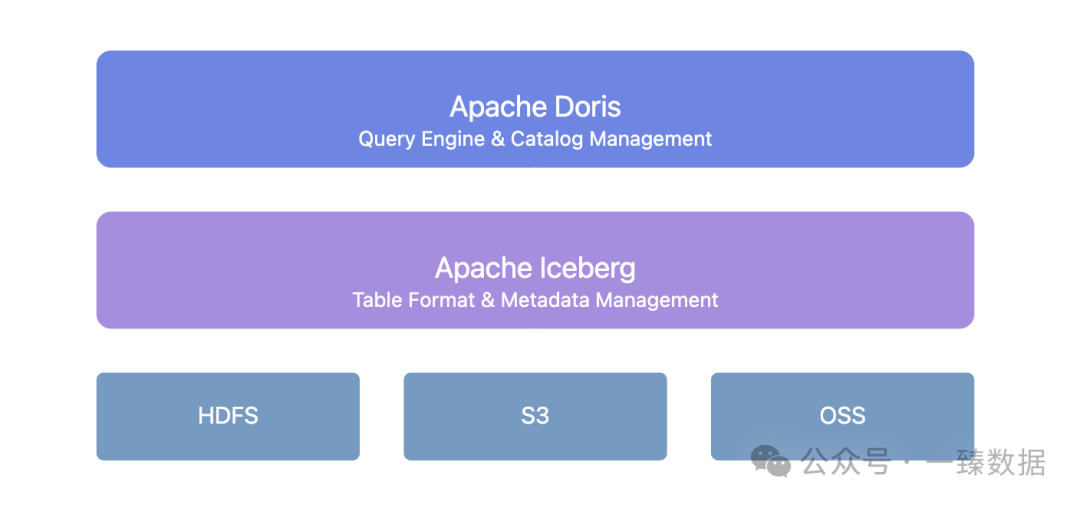
这种架构带来了几个关键价值:
- 无缝模式演进:表结构更改不再需要停机时间。Doris + Iceberg支持添加、删除和修改字段,以及调整分区方法。
- 数据版本管理:通过Iceberg的快照机制,您可以在任何时间点恢复数据状态。
- 统一目录服务:支持各种Iceberg目录类型,如Hive Metastore、Hadoop、REST、Glue、Google Dataproc Metastore和DLF,与现有基础设施无缝集成。
现在小张可以通过单个ALTER TABLE语句完成模式更改。系统会自动处理兼容性,并且下游应用程序保持不变。
高效的数据组织
Doris 创新地将 MPP 引擎与 Iceberg 的数据组织方法相结合:
-- Create a partitioned Iceberg table
-- Partition columns must be in the table's column definition list
CREATE TABLE sales (
ts DATETIME,
user_id BIGINT,
amount DOUBLE,
pt1 STRING,
pt2 STRING
) ENGINE=iceberg
-- Iceberg's partition type corresponds to List partitioning in Doris
PARTITION BY LIST (DAY(ts), pt1, pt2) ()
PROPERTIES (
-- Compression format
-- Parquet: snappy, zstd (default), plain (no compression)
-- ORC: snappy, zlib (default), zstd, plain (no compression)
'write-format'='orc',
'compression-codec'='zlib'
);
这个 SQL 语句隐藏了强大的技术机制:
- 文件组织:支持 HDFS 和对象存储等常见存储介质。
- 智能分区:支持分区转换函数,以启用 Iceberg 的隐式分区和分区演化功能。
- 存储优化:支持 Parquet 和 ORC 等列式存储格式,结合各种压缩方法以增强性能。
在 Doris 对 Iceberg 的 DDL 和 DML 操作支持下,数据一致性问题也得到了完全解决。
运维管理
为了确保数据平台的稳定性,小张采用以下方法监控和管理 Iceberg 表:
-- View table snapshot information
SELECT * FROM iceberg_meta(
"table" = "iceberg.nyc.taxis",
"query_type" = "snapshots"
);
-- Query a specific snapshot using FOR VERSION AS OF
SELECT * FROM iceberg.nyc.taxis FOR VERSION AS OF {snapshot_id};
-- Query a specific snapshot using FOR TIME AS OF
SELECT * FROM iceberg.nyc.taxis FOR TIME AS OF {committed_at};
-- Manage snapshots
...
这个工具链提供:
- 度量监控:实时控制表状态和快照指标。
- 快照管理:清理过期快照以释放存储空间。
- 故障恢复:支持回滚到任何历史版本(根据快照 ID 或快照创建时间读取历史版本数据)。
通过这些实践,基于 Doris + Iceberg 的小张数据平台已经达到了新的高度:
- 查询性能提升了 300%。
- 存储成本降低了 40%。
- 运维效率提高了 200%。
多丽丝湖屋令人兴奋的旅程永不停歇。
敬请期待下一期更多有趣、实用和有价值的内容!