













Mitten in der Nacht wegen eines Datenfehlers aufwachen, hast du jemals von einer idealen Datenwelt geträumt, in der Abfragen in Sekunden zurückkehren, Daten nie verloren gehen und die Kosten so niedrig sind, dass dein Chef lächelt? Klingt wie ein Traum? Nein! Dies wird zur Realität.
Erinnere dich an die Nacht, in der du von Datenpartitionierungsproblemen überwältigt wurdest, während der Produktmanager verzweifelt nach Fortschritt drängte, während du mit verstreuten Daten kämpftest? Cross-Source-Abfragen waren so langsam wie eine Schnecke, die einen Berg erklimmt, und Schemenänderungen erforderten Koordination über sieben Abteilungen hinweg.
Aber jetzt werden diese Schmerzpunkte neu geschrieben.
Die Kombination aus Apache Doris und Iceberg definiert neu, wie Datenseen funktionieren. Es ist nicht nur eine einfache 1+1=2; es bringt einen qualitativen Sprung: Abfragen auf Sekundärebene, nahtlose Schemaentwicklung und echte Datenkonsistenzgarantien.
Die perfekte Symphonie von Doris und Iceberg
Im Bereich des Daten-Engineerings stoßen wir oft auf solche Probleme:
Xiao Zhang arbeitet an einer Datenanalyseanforderung und muss Verhaltensdaten der Benutzer aus den letzten drei Monaten analysieren. Die Daten sind über Hive-Datenlager, Geschäftsdatenbanken und Objektspeicher verstreut. Die Leistung von Cross-Source-Joins ist schlecht, mit Abfragen, die über 40 Minuten dauern, und Dateninkonsistenzen treten oft auf.
Zusätzlich muss Xiao Zhang auch Daten-Governance-Arbeiten erledigen, und jede Änderung an der Tabellenstruktur bereitet ihm Kopfschmerzen. Mehrere nachgelagerte Anwendungen sind von diesen Tabellen abhängig, und Schemenänderungen erfordern die Koordination mehrerer Teams, was möglicherweise eine Woche dauert, um eine einzige Änderung abzuschließen.
Diese Probleme sind mit dem explosionsartigen Wachstum von Daten immer deutlicher geworden. Die traditionelle Trennung von Datenlagern und Datenseen kann den Anforderungen nicht mehr gerecht werden.
Zum Glück wurde in Version 2.1 die „Lakehouse“-Architektur von Apache Doris erheblich verbessert. Sie verbessert nicht nur die Lese- und Schreibfähigkeiten der gängigen Datenformate von Datenseen (Hudi, Iceberg, Paimon usw.), sondern führt auch eine Mehr-SQL-Dialektkompatibilität ein, die ein nahtloses Wechseln von bestehenden Systemen zu Apache Doris ermöglicht. In Szenarien der Datenwissenschaft und des Lesens von Daten im großen Maßstab integriert Doris die Arrow Flight Hochgeschwindigkeitslese-Schnittstelle und erreicht eine 100-fache Verbesserung der Datenübertragungseffizienz.
Daher entschied sich Xiao Zhang, Doris + Iceberg für seine Aufgabe zu verwenden.
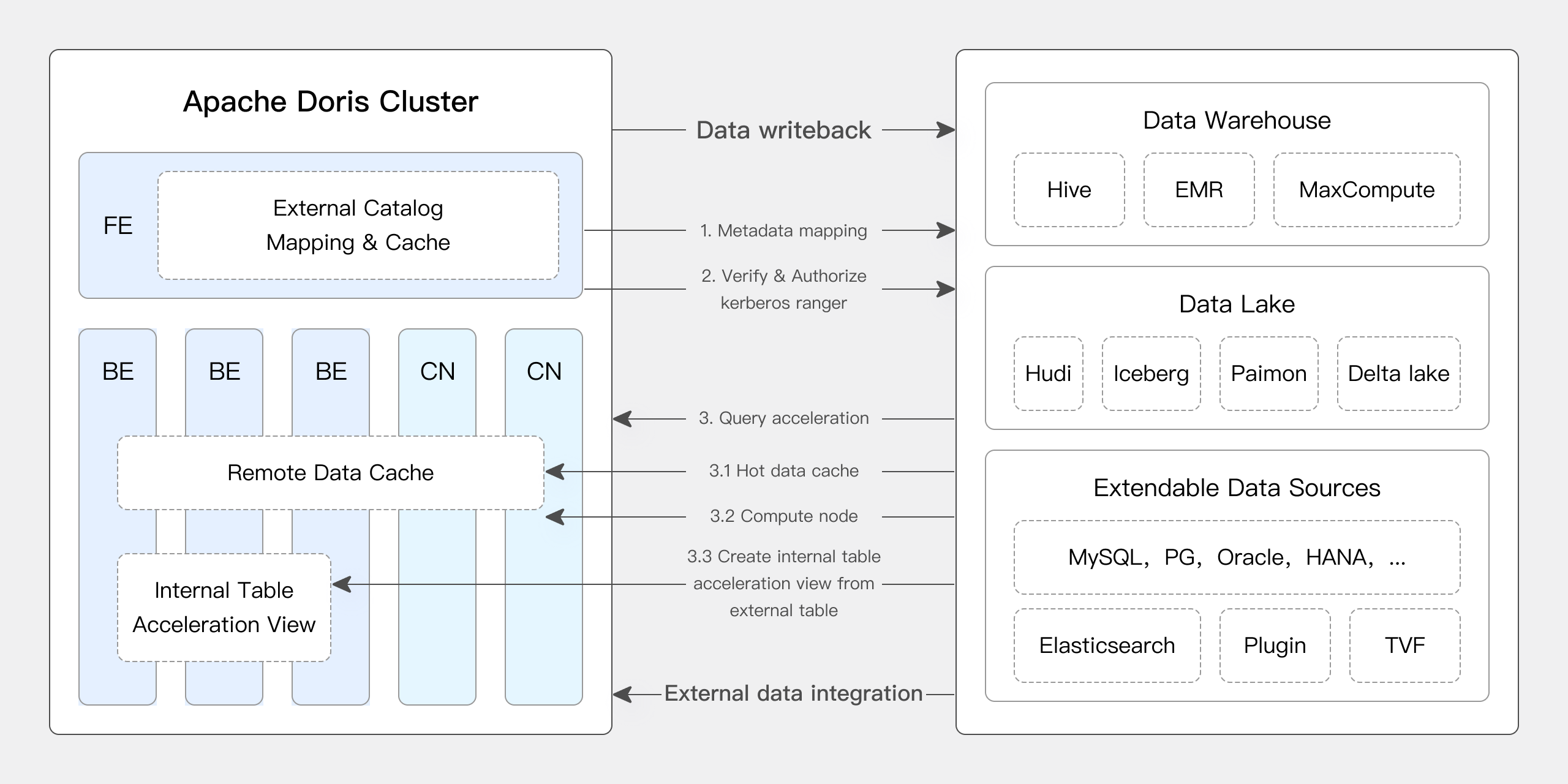
Apache Doris bietet native Unterstützung für viele Kernfunktionen von Iceberg:
- Unterstützt verschiedene Typen von Iceberg-Katalogen wie Hive Metastore, Hadoop, REST, Glue, Google Dataproc Metastore und DLF.
- Unterstützt nativ Iceberg V1/V2 Tabellenformate sowie das Lesen von Position-Delete- und Equality-Delete-Dateien.
- Unterstützt Abfragen des Historien-Snapshots von Iceberg-Tabellen über Tabellenfunktionen.
- Unterstützt die Funktion der Zeitreise.
- Unterstützt nativ den Iceberg-Tabellen-Engine. Apache Doris kann direkt Daten in Iceberg-Tabellen erstellen, verwalten und schreiben. Es unterstützt eine vollständige Reihe von Partitionstransformationsfunktionen, die Funktionen wie versteckte Partitionen und die Evolution des Partitionslayouts bieten.
Zusätzlich brachte Version 2.1.6 von Doris bedeutende Upgrades für Doris + Iceberg:
Apache Doris unterstützt DDL- und DML-Operationen auf Iceberg. Benutzer können Datenbanken und Tabellen direkt in Iceberg durch Apache Doris erstellen und Daten in Iceberg-Tabellen schreiben.
Mit dieser Funktion können Benutzer vollständige Datenabfragen und Schreiboperationen auf Iceberg mit Apache Doris durchführen und so die Lakehouse-Architektur weiter vereinfachen.
Daher kann Xiao Zhang schnell eine effiziente Lakehouse-Lösung auf der Grundlage von Apache Doris + Apache Iceberg aufbauen, um flexibel verschiedene Anforderungen für die Echtzeit-Datenanalyse und -verarbeitung zu erfüllen:
- Verwenden Sie Doris‘ leistungsstarken Abfrage-Engine, um Daten aus Iceberg-Tabellen und anderen Datenquellen zu verknüpfen und zu analysieren, und so eine einheitliche föderierte Datenanalyseplattform aufzubauen.
- Verwalten und erstellen Sie Iceberg-Tabellen direkt in Doris, bereinigen und verarbeiten Sie Daten und schreiben Sie sie in Iceberg-Tabellen, um eine einheitliche Lakehouse-Datenverarbeitungsplattform aufzubauen.
- Teilen Sie Doris-Daten mit anderen Upstream- und Downstream-Systemen für weitere Verarbeitung durch den Iceberg-Tabellen-Engine, um eine einheitliche offene Datenlagerplattform aufzubauen.
Dies ist nicht länger eine einfache Oberflächenintegration, sondern eine tiefe Verschmelzung von Lakehouse-Architekturen!
Praktische Zusammenfassung von Doris und Iceberg
Nach einer Reihe von Höhen und Tiefen in der Erkundung und Praxis hat Xiao Zhang einige praktische Erfahrungen mit Doris + Iceberg zusammengefasst:
Intelligente Verwaltung von Metadaten
In traditionellen Lösungen war die Verwaltung von Metadaten immer ein heikles Thema. Tabellenpartitionierungsinformationen, Dateipfade und Historien von Schemaänderungen sind überall verstreut, was zu schlechten Abfrageleistungen sowie komplexen Betriebs- und Wartungsanforderungen führt.
Doris + Iceberg bietet eine einheitliche Schicht zur Verwaltung von Metadaten:
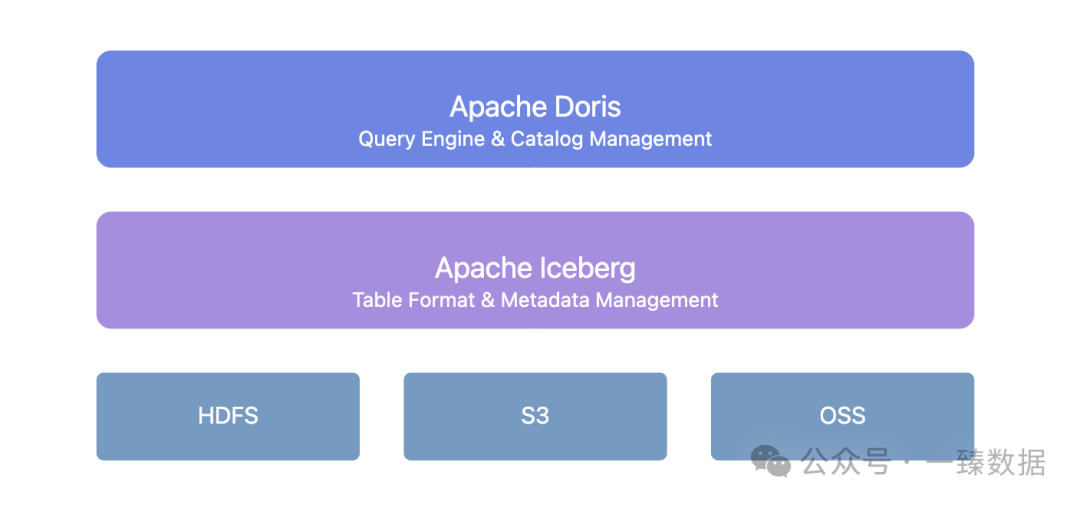
Diese Architektur bringt mehrere wichtige Werte:
- Nahtlose Schema-Evolution: Änderungen an der Tabellenstruktur erfordern keine Ausfallzeiten mehr. Doris + Iceberg unterstützt das Hinzufügen, Löschen und Ändern von Feldern sowie die Anpassung von Partitionierungsmethoden.
- Verwaltung von Datenversionen: Durch Icebergs Snapshot-Mechanismus können Sie den Datenstatus zu jedem beliebigen Zeitpunkt wiederherstellen.
- Einheitlicher Katalogdienst: Unterstützt verschiedene Iceberg-Katalogtypen wie Hive Metastore, Hadoop, REST, Glue, Google Dataproc Metastore und DLF und integriert sich nahtlos in die bestehende Infrastruktur.
Xiao Zhang kann jetzt Schemaänderungen mit einer einzigen ALTER TABLE-Anweisung durchführen. Das System kümmert sich automatisch um die Kompatibilität, und nachgelagerte Anwendungen bleiben von den Änderungen unberührt.
Effiziente Datenorganisation
Doris kombiniert innovativ die MPP-Engine mit den Datenorganisationsmethoden von Iceberg:
-- Create a partitioned Iceberg table
-- Partition columns must be in the table's column definition list
CREATE TABLE sales (
ts DATETIME,
user_id BIGINT,
amount DOUBLE,
pt1 STRING,
pt2 STRING
) ENGINE=iceberg
-- Iceberg's partition type corresponds to List partitioning in Doris
PARTITION BY LIST (DAY(ts), pt1, pt2) ()
PROPERTIES (
-- Compression format
-- Parquet: snappy, zstd (default), plain (no compression)
-- ORC: snappy, zlib (default), zstd, plain (no compression)
'write-format'='orc',
'compression-codec'='zlib'
);
Diese SQL-Anweisung verbirgt leistungsstarke technische Mechanismen:
- Dateiorganisation: Unterstützt gängige Speichermedien wie HDFS und Objektspeicher.
- Intelligente Partitionierung: Unterstützt Partitionstransformationsfunktionen, um die implizite Partitionierung und die Evolution von Partitionen in Iceberg zu ermöglichen.
- Speicheroptimierung: Unterstützt spaltenbasierte Speicherformate wie Parquet und ORC, kombiniert mit verschiedenen Kompressionsmethoden zur Leistungssteigerung.
Mit der Unterstützung von Doris für DDL- und DML-Operationen auf Iceberg werden auch Datenkonsistenzprobleme vollständig gelöst.
Betriebs- und Wartungsmanagement
Um die Stabilität der Datenplattform zu gewährleisten, nutzt Xiao Zhang die folgenden Methoden zur Überwachung und Verwaltung von Iceberg-Tabellen:
-- View table snapshot information
SELECT * FROM iceberg_meta(
"table" = "iceberg.nyc.taxis",
"query_type" = "snapshots"
);
-- Query a specific snapshot using FOR VERSION AS OF
SELECT * FROM iceberg.nyc.taxis FOR VERSION AS OF {snapshot_id};
-- Query a specific snapshot using FOR TIME AS OF
SELECT * FROM iceberg.nyc.taxis FOR TIME AS OF {committed_at};
-- Manage snapshots
...
Diese Werkzeugkette bietet:
- Metriküberwachung: Echtzeitüberwachung des Tabellenstatus und der Snapshot-Metriken.
- Snapshot-Management: Bereinigung abgelaufener Snapshots zur Freigabe von Speicherplatz.
- Fehlerbehebung: Unterstützt das Zurückrollen auf jede historische Version (lesen von historischen Versionsdaten basierend auf Snapshot-ID oder Erstellungszeit des Snapshots).
Durch diese Praktiken hat die Datenplattform von Xiao Zhang, die auf Doris + Iceberg basiert, neue Höhen erreicht:
- Abfrageleistung um 300% verbessert.
- Speicherkosten um 40% gesenkt.
- Betriebs- und Wartungseffizienz um 200% erhöht.
Die aufregende Reise von Doris‘ Seehaus ist endlos.
Bleiben Sie dran für weitere interessante, nützliche und wertvolle Inhalte in der nächsten Ausgabe!