













Se réveiller au milieu de la nuit à cause d’un bug de données, avez-vous déjà rêvé d’un monde de données idéal où les requêtes se font en quelques secondes, où les données ne sont jamais perdues et où les coûts sont si bas que votre patron sourit ? Cela semble être un rêve ? Non ! Cela devient une réalité.
Rappelez-vous de cette nuit où vous étiez écrasé par des problèmes de partitionnement de données, avec le chef de produit poussant frénétiquement pour avancer pendant que vous luttiez avec des données éparpillées ? Les requêtes inter-sources étaient aussi lentes qu’un escargot escaladant une montagne, et les changements de schéma nécessitaient une coordination à travers sept départements.
Mais maintenant, ces points douloureux sont en train d’être réécrits.
La combinaison d’Apache Doris et Iceberg redéfinit la façon dont les data lakes fonctionnent. Ce n’est pas simplement un 1+1=2 ; cela apporte un bond qualitatif : des requêtes au niveau de la seconde, une évolution du schéma sans couture et de vraies garanties de cohérence des données.
La Symphonie Parfaite de Doris et Iceberg
Dans le domaine de l’ingénierie des données, nous rencontrons souvent de tels problèmes :
Xiao Zhang travaille sur une exigence d’analyse de données, ayant besoin d’analyser les données de comportement des utilisateurs des trois derniers mois. Les données sont éparpillées à travers les entrepôts de données Hive, les bases de données métier et le stockage objet. Les performances des jointures inter-sources sont médiocres, les requêtes prenant plus de 40 minutes, et des incohérences de données se produisent souvent.
De plus, Xiao Zhang doit également s’occuper du travail de gouvernance des données, et chaque changement de structure de table lui donne des maux de tête. De nombreuses applications en aval dépendent de ces tables, et les changements de schéma nécessitent une coordination à travers plusieurs équipes, pouvant prendre une semaine pour effectuer un seul changement.
Ces problèmes sont devenus plus prédominants avec la croissance explosive des données. La séparation traditionnelle entre les entrepôts de données et les data lakes ne peut plus répondre aux besoins.
Heureusement, dans la version 2.1, l’architecture lakehouse d’Apache Doris a été considérablement améliorée. Elle améliore non seulement les capacités de lecture et d’écriture des formats de data lake les plus courants (Hudi, Iceberg, Paimon, etc.), mais introduit également une compatibilité multi-dialectes SQL, permettant une transition transparente des systèmes existants vers Apache Doris. Dans les scénarios de science des données et de lecture de données à grande échelle, Doris intègre l’interface de lecture haute vitesse Arrow Flight, obtenant une amélioration de 100 fois de l’efficacité de transfert des données.
Ainsi, Xiao Zhang a décidé d’utiliser Doris + Iceberg pour sa récupération.
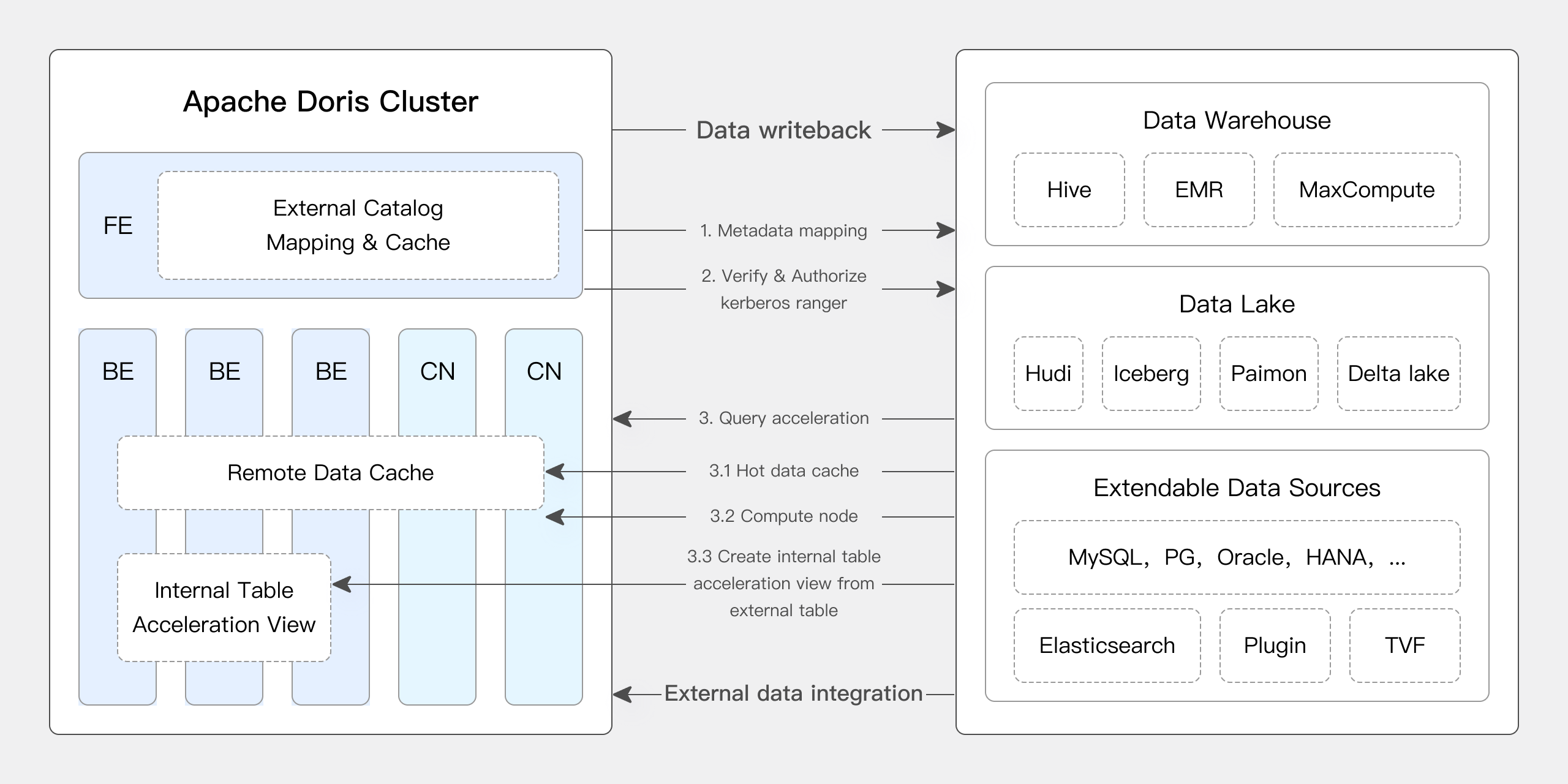
Apache Doris prend en charge nativement de nombreuses fonctionnalités principales d’Iceberg :
- Prend en charge divers types de catalogues Iceberg tels que Hive Metastore, Hadoop, REST, Glue, Google Dataproc Metastore et DLF.
- Prend en charge nativement les formats de table Iceberg V1/V2, ainsi que la lecture des fichiers Position Delete et Equality Delete.
- Prend en charge la consultation de l’historique de snapshot de table Iceberg via des fonctions de table.
- Prend en charge la fonctionnalité de voyage dans le temps.
- Prend en charge nativement le moteur de table Iceberg. Apache Doris peut créer, gérer et écrire directement des données dans les tables Iceberg. Il prend en charge un ensemble complet de fonctions de transformation de partition, offrant des capacités telles que les partitions cachées et l’évolution de la disposition des partitions.
De plus, la version 2.1.6 de Doris a apporté des mises à niveau significatives à Doris + Iceberg :
Apache Doris prend en charge les opérations DDL et DML sur Iceberg. Les utilisateurs peuvent créer directement des bases de données et des tables dans Iceberg via Apache Doris et écrire des données dans les tables Iceberg.
Grâce à cette fonctionnalité, les utilisateurs peuvent effectuer des requêtes de données complètes et des opérations d’écriture sur Iceberg en utilisant Apache Doris, simplifiant davantage l’architecture lakehouse.
Ainsi, Xiao Zhang peut rapidement construire une solution lakehouse efficace basée sur Apache Doris + Apache Iceberg pour répondre de manière flexible à divers besoins en matière d’analyse et de traitement des données en temps réel :
- Utiliser le moteur de requête haute performance de Doris pour joindre et analyser des données provenant de tables Iceberg et d’autres sources de données, construisant ainsi une plateforme d’analyse de données fédérée unifiée.
- Gérer directement et construire des tables Iceberg dans Doris, nettoyer et traiter les données, et les écrire dans les tables Iceberg, construisant ainsi une plateforme de traitement de données lakehouse unifiée.
- Partager les données Doris avec d’autres systèmes amont et aval pour un traitement ultérieur via le moteur de table Iceberg, construisant ainsi une plateforme de stockage de données ouverte unifiée.
Il ne s’agit plus d’une simple intégration de surface mais d’une fusion profonde des architectures lakehouse !
Résumé pratique de Doris et Iceberg
Après une série de hauts et de bas dans l’exploration et la pratique, Xiao Zhang a résumé certaines expériences pratiques avec Doris + Iceberg :
Gestion intelligente des métadonnées
Dans les solutions traditionnelles, la gestion des métadonnées a toujours été un problème épineux. Les informations de partition de table, les emplacements de fichiers et les historiques de modification de schéma sont dispersés partout, entraînant de mauvaises performances de requête et des opérations et une maintenance complexes.
Doris + Iceberg fournit une couche de gestion unifiée des métadonnées :
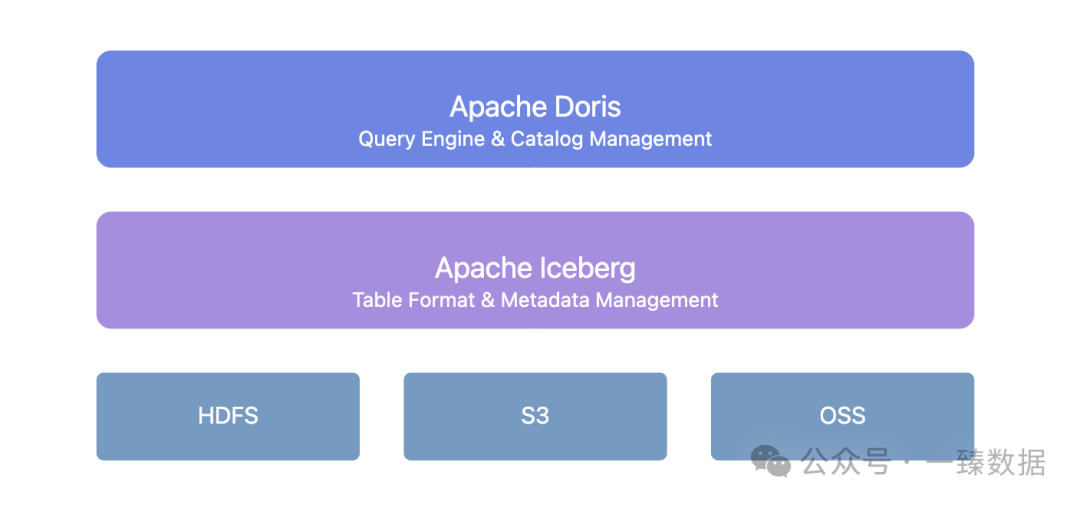
Cette architecture apporte plusieurs valeurs clés :
- Évolution de schéma transparente : Les changements de structure de table ne nécessitent plus d’arrêt. Doris + Iceberg prend en charge l’ajout, la suppression et la modification de champs, ainsi que l’ajustement des méthodes de partitionnement.
- Gestion des versions de données : Grâce au mécanisme de cliché d’Iceberg, vous pouvez revenir à l’état des données à n’importe quel moment.
- Service de catalogue unifié : Prend en charge divers types de catalogue Iceberg tels que Hive Metastore, Hadoop, REST, Glue, Google Dataproc Metastore et DLF, s’intégrant parfaitement à l’infrastructure existante.
Xiao Zhang peut désormais effectuer des changements de schéma avec une seule déclaration ALTER TABLE. Le système gère automatiquement la compatibilité, et les applications en aval restent inconscientes des changements.
Organisation efficace des données
Doris combine de manière innovante le moteur MPP avec les méthodes d’organisation des données d’Iceberg :
-- Create a partitioned Iceberg table
-- Partition columns must be in the table's column definition list
CREATE TABLE sales (
ts DATETIME,
user_id BIGINT,
amount DOUBLE,
pt1 STRING,
pt2 STRING
) ENGINE=iceberg
-- Iceberg's partition type corresponds to List partitioning in Doris
PARTITION BY LIST (DAY(ts), pt1, pt2) ()
PROPERTIES (
-- Compression format
-- Parquet: snappy, zstd (default), plain (no compression)
-- ORC: snappy, zlib (default), zstd, plain (no compression)
'write-format'='orc',
'compression-codec'='zlib'
);
Cette déclaration SQL cache de puissants mécanismes techniques :
- Organisation des fichiers : Prend en charge les supports de stockage courants tels que HDFS et le stockage d’objets.
- Partitionnement intelligent : Prend en charge les fonctions de transformation de partitions pour activer le partitionnement implicite d’Iceberg et les fonctionnalités d’évolution des partitions.
- Optimisation du stockage : Prend en charge les formats de stockage colonnaires tels que Parquet et ORC, combinés à diverses méthodes de compression pour améliorer les performances.
Avec le support de Doris pour les opérations DDL et DML sur Iceberg, les problèmes de cohérence des données sont également complètement résolus.
Gestion des opérations et de la maintenance
Pour garantir la stabilité de la plateforme de données, Xiao Zhang utilise les méthodes suivantes pour surveiller et gérer les tables Iceberg :
-- View table snapshot information
SELECT * FROM iceberg_meta(
"table" = "iceberg.nyc.taxis",
"query_type" = "snapshots"
);
-- Query a specific snapshot using FOR VERSION AS OF
SELECT * FROM iceberg.nyc.taxis FOR VERSION AS OF {snapshot_id};
-- Query a specific snapshot using FOR TIME AS OF
SELECT * FROM iceberg.nyc.taxis FOR TIME AS OF {committed_at};
-- Manage snapshots
...
Cet ensemble d’outils fournit :
- Surveillance des métriques : Contrôle en temps réel de l’état des tables et des métriques des instantanés.
- Gestion des instantanés : Nettoyer les instantanés expirés pour libérer de l’espace de stockage.
- Récupération des erreurs : Prend en charge le retour à n’importe quelle version historique (lecture des données de version historique en fonction de l’ID de l’instantané ou de l’heure de création de l’instantané).
Grâce à ces pratiques, la plateforme de données de Xiao Zhang basée sur Doris + Iceberg a atteint de nouveaux sommets :
- Les performances des requêtes ont augmenté de 300%.
- Les coûts de stockage ont été réduits de 40%.
- L’efficacité des opérations et de la maintenance a augmenté de 200%.
L’excitante aventure de la maison au bord du lac de Doris est sans fin.
Restez à l’écoute pour plus de contenu intéressant, utile et précieux dans le prochain numéro !