













Acordando no meio da noite devido a um bug de dados novamente, você já sonhou com um mundo de dados ideal onde as consultas retornam em segundos, os dados nunca são perdidos e os custos são tão baixos que seu chefe está sorrindo? Parece um sonho? Não! Isso está se tornando realidade.
Lembre-se daquela noite em que você foi esmagado por problemas de particionamento de dados, com o gerente de produto empurrando freneticamente por progresso enquanto você lutava com dados espalhados? As consultas entre fontes eram lentas como um caracol subindo uma montanha, e as mudanças de esquema exigiam coordenação entre sete departamentos.
Mas agora, esses pontos de dor estão sendo reescritos.
A combinação de Apache Doris e Iceberg está redefinindo a forma como os lagos de dados funcionam. Não é apenas um simples 1+1=2; traz um salto qualitativo: consultas de segundo nível, evolução de esquema sem emendas e verdadeiras garantias de consistência de dados.
A Sinfonia Perfeita de Doris e Iceberg
No campo da engenharia de dados, frequentemente nos deparamos com problemas como estes:
Xiao Zhang está trabalhando em um requisito de análise de dados, precisando analisar dados de comportamento do usuário dos últimos três meses. Os dados estão espalhados em data warehouses Hive, bancos de dados de negócios e armazenamento de objetos. O desempenho de junção entre fontes é ruim, com consultas levando mais de 40 minutos, e incoerência de dados frequentemente ocorre.
Além disso, Xiao Zhang também precisa lidar com o trabalho de governança de dados, e cada mudança na estrutura da tabela lhe dá dor de cabeça. Múltiplas aplicações dependentes dessas tabelas, e as mudanças de esquema exigem coordenação entre várias equipes, podendo levar uma semana para concluir uma única mudança.
Essas questões tornaram-se mais proeminentes com o crescimento explosivo de dados. A separação tradicional entre data warehouses e data lakes não consegue mais atender às necessidades.
Felizmente, na versão 2.1, a arquitetura de lakehouse do Apache Doris foi significativamente aprimorada. Ela não apenas melhora as capacidades de leitura e escrita de formatos de data lake mainstream (Hudi, Iceberg, Paimon, etc.), mas também introduz compatibilidade com múltiplos dialetos SQL, permitindo a troca contínua de sistemas existentes para o Apache Doris. Em cenários de ciência de dados e leitura de dados em larga escala, o Doris integra a interface de leitura de alta velocidade Arrow Flight, alcançando uma melhoria de 100 vezes na eficiência de transferência de dados.
Assim, Xiao Zhang decidiu usar o Doris + Iceberg para sua redenção.
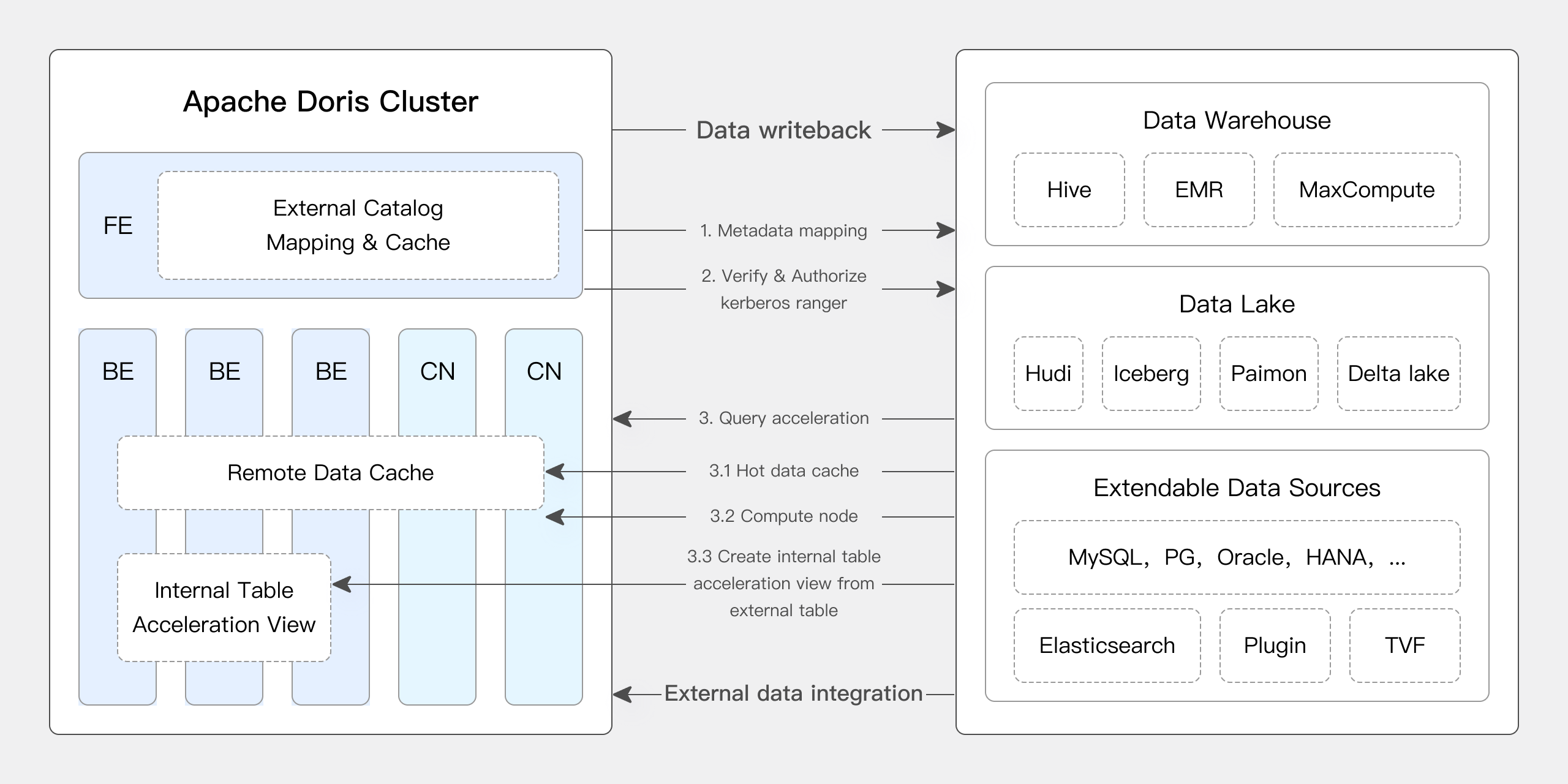
O Apache Doris fornece suporte nativo para muitos recursos principais do Iceberg:Iceberg:
- Suporta vários tipos de catálogo Iceberg, como Hive Metastore, Hadoop, REST, Glue, Google Dataproc Metastore e DLF.
- Suporta nativamente os formatos de tabela Iceberg V1/V2, bem como a leitura de arquivos Position Delete e Equality Delete.
- Suporta consultas ao histórico de snapshots da tabela Iceberg por meio de funções de tabela.
- Suporta funcionalidade de viagem no tempo.
- Oferece suporte nativo ao mecanismo de tabela Iceberg. O Apache Doris pode criar, gerenciar e gravar dados diretamente em tabelas Iceberg. Ele suporta um conjunto completo de funções de transformação de partição, fornecendo capacidades como partições ocultas e evolução do layout de partição.
Além disso, a versão 2.1.6 do Doris trouxe melhorias significativas para Doris + Iceberg:
O Apache Doris suporta operações DDL e DML no Iceberg. Os usuários podem criar bancos de dados e tabelas diretamente no Iceberg através do Apache Doris e gravar dados em tabelas Iceberg.
Através deste recurso, os usuários podem realizar consultas de dados completas e operações de gravação no Iceberg usando o Apache Doris, simplificando ainda mais a arquitetura lakehouse.
Portanto, Xiao Zhang pode rapidamente construir uma solução eficiente de lakehouse com base no Apache Doris + Apache Iceberg para atender de forma flexível a várias necessidades de análise e processamento de dados em tempo real:
- Usar o mecanismo de consulta de alto desempenho do Doris para unir e analisar dados de tabelas Iceberg e outras fontes de dados, construindo uma plataforma unificada de análise de dados federados.
- Gerenciar diretamente e construir tabelas Iceberg no Doris, limpar e processar dados, e escrevê-los em tabelas Iceberg, construindo uma plataforma unificada de processamento de dados de lakehouse.
- Compartilhar dados do Doris com outros sistemas a montante e a jusante para processamento adicional através do mecanismo de tabela Iceberg, construindo uma plataforma unificada de armazenamento de dados abertos.
Isso não é mais uma simples integração superficial, mas uma fusão profunda das arquiteturas de lakehouse!
Resumo Prático de Doris e Iceberg
Depois de uma série de altos e baixos na exploração e prática, Xiao Zhang resumiu algumas experiências práticas com Doris + Iceberg:
Gestão Inteligente de Metadados
Nas soluções tradicionais, a gestão de metadados sempre foi um problema complicado. As informações de partição de tabela, localizações de arquivos e históricos de alterações de esquema estão espalhados por toda parte, levando a um desempenho de consulta ruim e operações e manutenção complexas.
Doris + Iceberg fornece uma camada unificada de gestão de metadados:
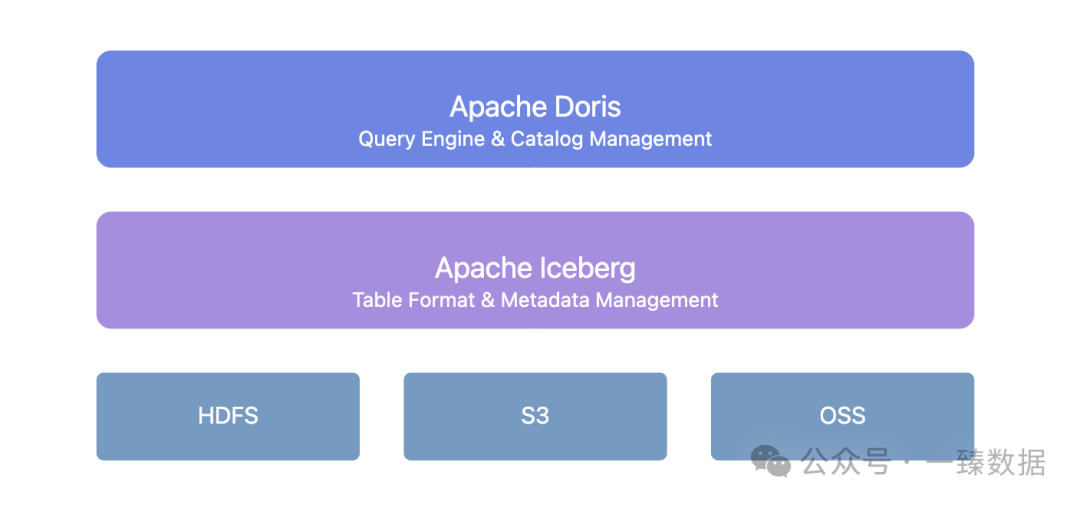
Esta arquitetura traz diversos valores-chave:
- Evolução de esquema contínua: As alterações na estrutura da tabela não exigem mais tempo de inatividade. Doris + Iceberg suporta adição, exclusão e modificação de campos, bem como ajuste de métodos de partição.
- Gestão de versão de dados: Através do mecanismo de snapshot do Iceberg, você pode reverter para o estado dos dados em qualquer momento.
- Serviço de catálogo unificado: Suporta diversos tipos de Catálogo Iceberg como Hive Metastore, Hadoop, REST, Glue, Google Dataproc Metastore e DLF, integrando-se perfeitamente com a infraestrutura existente.
Xiao Zhang agora pode concluir as alterações de esquema com uma única instrução ALTER TABLE. O sistema lida automaticamente com a compatibilidade, e as aplicações downstream permanecem inconscientes das mudanças.
Organização Eficiente de Dados
Doris combina de forma inovadora o mecanismo MPP com os métodos de organização de dados do Iceberg:
-- Create a partitioned Iceberg table
-- Partition columns must be in the table's column definition list
CREATE TABLE sales (
ts DATETIME,
user_id BIGINT,
amount DOUBLE,
pt1 STRING,
pt2 STRING
) ENGINE=iceberg
-- Iceberg's partition type corresponds to List partitioning in Doris
PARTITION BY LIST (DAY(ts), pt1, pt2) ()
PROPERTIES (
-- Compression format
-- Parquet: snappy, zstd (default), plain (no compression)
-- ORC: snappy, zlib (default), zstd, plain (no compression)
'write-format'='orc',
'compression-codec'='zlib'
);
Esta declaração SQL oculta poderosos mecanismos técnicos:
- Organização de arquivos: Suporta mídias de armazenamento comuns como HDFS e armazenamento de objetos.
- Particionamento inteligente: Suporta funções de transformação de partições para habilitar o particionamento implícito e recursos de evolução de partições do Iceberg.
- Otimização de armazenamento: Suporta formatos de armazenamento colunar como Parquet e ORC, combinados com vários métodos de compressão para aprimorar o desempenho.
Com o suporte do Doris para operações DDL e DML no Iceberg, os problemas de consistência de dados também são completamente resolvidos.
Operações e Gerenciamento de Manutenção
Para garantir a estabilidade da plataforma de dados, Xiao Zhang utiliza os seguintes métodos para monitorar e gerenciar as tabelas do Iceberg:
-- View table snapshot information
SELECT * FROM iceberg_meta(
"table" = "iceberg.nyc.taxis",
"query_type" = "snapshots"
);
-- Query a specific snapshot using FOR VERSION AS OF
SELECT * FROM iceberg.nyc.taxis FOR VERSION AS OF {snapshot_id};
-- Query a specific snapshot using FOR TIME AS OF
SELECT * FROM iceberg.nyc.taxis FOR TIME AS OF {committed_at};
-- Manage snapshots
...
Esta cadeia de ferramentas fornece:
- Monitoramento de métricas: Controle em tempo real do status da tabela e métricas de snapshot.
- Gerenciamento de snapshots: Limpeza de snapshots expirados para liberar espaço de armazenamento.
- Recuperação de falhas: Suporta retorno a qualquer versão histórica (leitura de dados da versão histórica com base no ID do snapshot ou no momento da criação do snapshot).
Através dessas práticas, a plataforma de dados de Xiao Zhang baseada em Doris + Iceberg atingiu novos patamares:
- O desempenho de consulta melhorou em 300%.
- Os custos de armazenamento foram reduzidos em 40%.
- A eficiência das operações e da manutenção aumentou em 200%.
A empolgante jornada da casa do lago de Doris é interminável.
Fique ligado para mais conteúdo interessante, útil e valioso na próxima edição!