













Svegliarsi nel cuore della notte a causa di un bug dei dati, hai mai sognato un mondo ideale dei dati in cui le query vengono restituite in pochi secondi, i dati non vengono mai persi e i costi sono così bassi che il tuo capo sorride? Sembra un sogno? No! Questo sta diventando realtà.
Ricordi quella notte in cui sei stato schiacciato dai problemi di partizionamento dei dati, con il product manager che spingeva freneticamente per fare progressi mentre lottavi con dati dispersi? Le query cross-source erano lente come una lumaca che scalava una montagna, e i cambiamenti dello schema richiedevano coordinazione tra sette dipartimenti.
Ma ora, questi punti critici stanno venendo riscritti.
La combinazione di Apache Doris e Iceberg sta ridefinendo il modo in cui funzionano i data lake. Non è solo un semplice 1+1=2; porta un salto qualitativo: query di secondo livello, evoluzione dello schema senza soluzione di continuità e vere garanzie di consistenza dei dati.
La Perfetta Sinfonia di Doris e Iceberg
Nel campo dell’ingegneria dei dati, incontriamo spesso problemi del genere:
Xiao Zhang sta lavorando a un requisito di analisi dei dati, avendo bisogno di analizzare i dati sul comportamento degli utenti degli ultimi tre mesi. I dati sono sparsi tra i data warehouse Hive, i database aziendali e lo storage degli oggetti. Le performance di Join cross-source sono scarse, con query che impiegano oltre 40 minuti, e spesso si verificano incongruenze nei dati.
Inoltre, Xiao Zhang deve anche occuparsi del lavoro di governance dei dati, e ogni modifica alla struttura delle tabelle gli provoca mal di testa. Diverse applicazioni downstream dipendono da queste tabelle, e i cambiamenti dello schema richiedono coordinazione tra più team, impiegando eventualmente una settimana per completare una singola modifica.
Queste problematiche sono diventate più evidenti con la crescita esplosiva dei dati. La separazione tradizionale tra data warehouse e data lake non può più soddisfare le esigenze.
Fortunatamente, nella versione 2.1, l’architettura lakehouse di Apache Doris è stata significativamente migliorata. Non solo migliora le capacità di lettura e scrittura dei formati di data lake mainstream (Hudi, Iceberg, Paimon, ecc.), ma introduce anche la compatibilità con diversi dialetti SQL, consentendo il passaggio senza soluzione di continuità dai sistemi esistenti ad Apache Doris. Nei contesti di data science e lettura di dati su larga scala, Doris integra l’interfaccia di lettura ad alta velocità Arrow Flight, ottenendo un miglioramento del 100x nell’efficienza di trasferimento dei dati.
Di conseguenza, Xiao Zhang ha deciso di utilizzare Doris + Iceberg per il suo recupero.
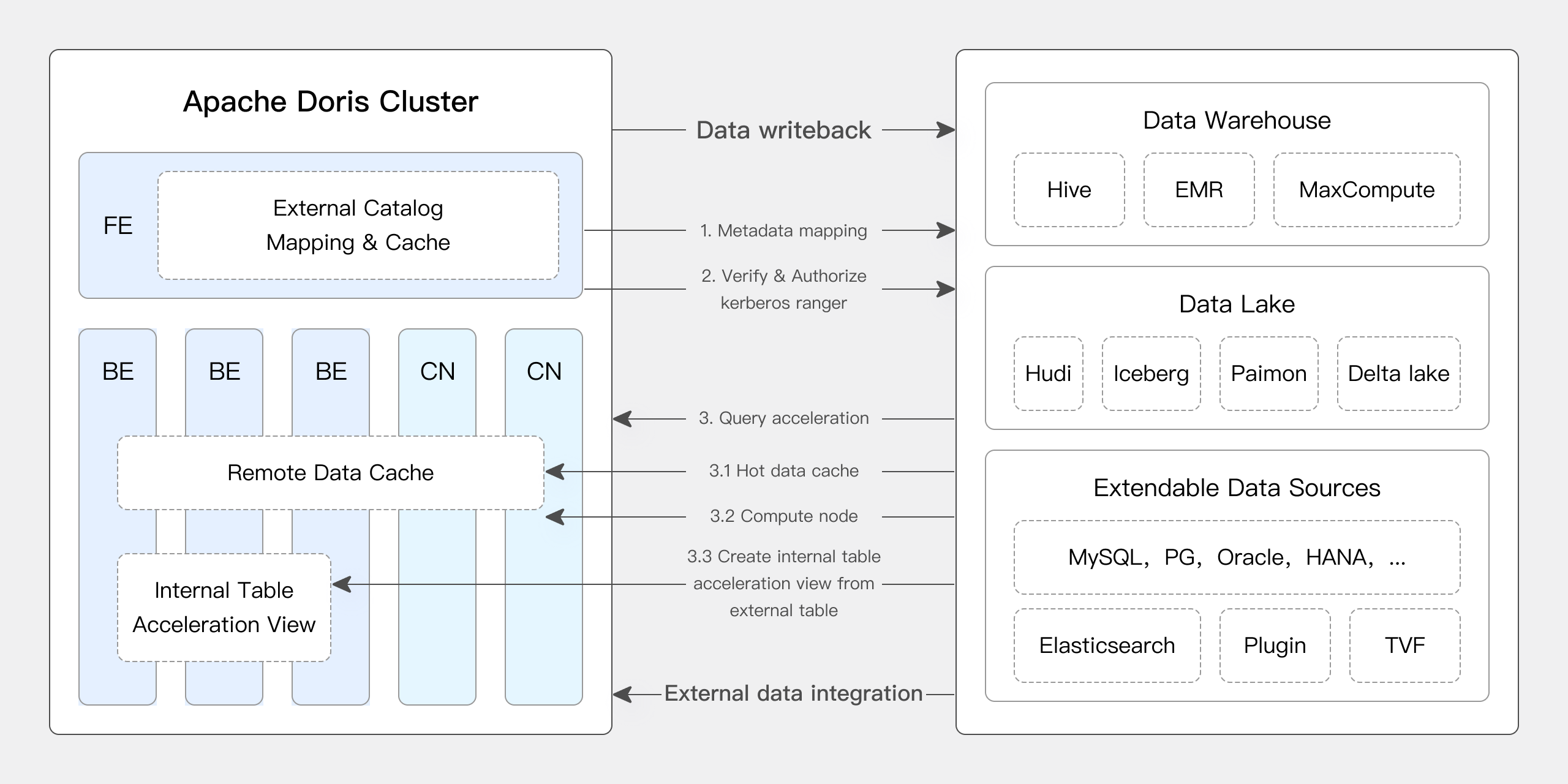
Apache Doris fornisce supporto nativo per molte funzionalità fondamentali di Iceberg:
- Supporta vari tipi di catalogo Iceberg come Hive Metastore, Hadoop, REST, Glue, Google Dataproc Metastore e DLF.
- Supporta nativamente i formati tabella Iceberg V1/V2, così come la lettura di file di eliminazione di posizione e di eliminazione di uguaglianza.
- Supporta il recupero dello storico degli snapshot della tabella Iceberg tramite funzioni di tabella.
- Supporta la funzionalità di viaggio nel tempo.
- Supporta nativamente il motore di tabella Iceberg. Apache Doris può creare, gestire e scrivere direttamente dati nelle tabelle Iceberg. Supporta un set completo di funzioni di trasformazione delle partizioni, fornendo capacità come partizioni nascoste e evoluzione del layout delle partizioni.
Inoltre, la versione 2.1.6 di Doris ha portato significativi miglioramenti a Doris + Iceberg:
Apache Doris supporta operazioni DDL e DML su Iceberg. Gli utenti possono creare direttamente database e tabelle in Iceberg tramite Apache Doris e scrivere dati nelle tabelle Iceberg.
Attraverso questa funzionalità, gli utenti possono eseguire query complete sui dati e operazioni di scrittura su Iceberg utilizzando Apache Doris, semplificando ulteriormente l’architettura lakehouse.
Pertanto, Xiao Zhang può rapidamente costruire una soluzione lakehouse efficiente basata su Apache Doris + Apache Iceberg per soddisfare flessibilmente vari requisiti per l’analisi e l’elaborazione dei dati in tempo reale:
- Utilizzare il motore di query ad alte prestazioni di Doris per unire ed analizzare dati da tabelle Iceberg e altre fonti di dati, costruendo una piattaforma di analisi dati federata unificata.
- Gestire direttamente e costruire tabelle Iceberg in Doris, pulire ed elaborare dati e scriverli nelle tabelle Iceberg, costruendo una piattaforma di elaborazione dati lakehouse unificata.
- Condividere i dati di Doris con altri sistemi a monte e a valle per ulteriori elaborazioni attraverso il motore di tabella Iceberg, costruendo una piattaforma di archiviazione dati aperta unificata.
Non si tratta più di una semplice integrazione superficiale ma di una fusione profonda delle architetture lakehouse!
Sommario pratico di Doris e Iceberg
Dopo una serie di alti e bassi nell’esplorazione e nella pratica, Xiao Zhang ha riassunto alcune esperienze pratiche con Doris + Iceberg:
Gestione intelligente dei metadati
Nelle soluzioni tradizionali, la gestione dei metadati è sempre stata un problema spinoso. Le informazioni sulle partizioni delle tabelle, le posizioni dei file e la cronologia delle modifiche dello schema sono sparse ovunque, portando a scarse prestazioni delle query e a operazioni e manutenzione complesse.
Doris + Iceberg fornisce uno strato unificato di gestione dei metadati:
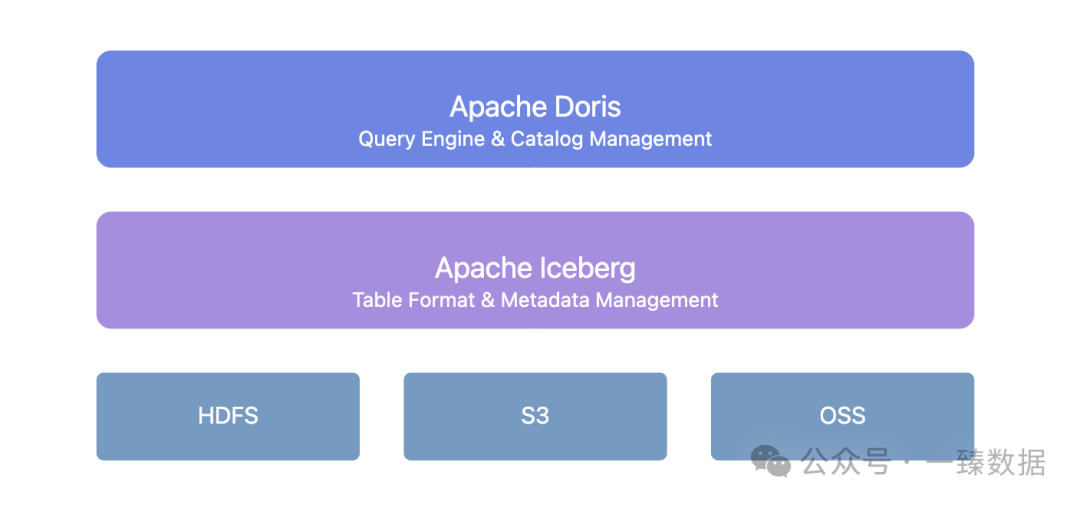
Questa architettura porta diversi valori chiave:
- Evolution dello schema senza soluzione di continuità: Le modifiche alla struttura della tabella non richiedono più tempi di inattività. Doris + Iceberg supporta l’aggiunta, la cancellazione e la modifica dei campi, così come l’aggiustamento dei metodi di partizionamento.
- Gestione delle versioni dei dati: Attraverso il meccanismo di snapshot di Iceberg, è possibile tornare allo stato dei dati in qualsiasi momento.
- Servizio di catalogo unificato: Supporta vari tipi di Catalogo Iceberg come Hive Metastore, Hadoop, REST, Glue, Google Dataproc Metastore e DLF, integrandosi senza soluzione di continuità con l’infrastruttura esistente.
Xiao Zhang può ora completare le modifiche dello schema con una singola istruzione ALTER TABLE. Il sistema gestisce automaticamente la compatibilità e le applicazioni downstream rimangono ignare dei cambiamenti.
Efficiente organizzazione dei dati
Doris combina in modo innovativo il motore MPP con i metodi di organizzazione dei dati di Iceberg:
-- Create a partitioned Iceberg table
-- Partition columns must be in the table's column definition list
CREATE TABLE sales (
ts DATETIME,
user_id BIGINT,
amount DOUBLE,
pt1 STRING,
pt2 STRING
) ENGINE=iceberg
-- Iceberg's partition type corresponds to List partitioning in Doris
PARTITION BY LIST (DAY(ts), pt1, pt2) ()
PROPERTIES (
-- Compression format
-- Parquet: snappy, zstd (default), plain (no compression)
-- ORC: snappy, zlib (default), zstd, plain (no compression)
'write-format'='orc',
'compression-codec'='zlib'
);
Questo statement SQL nasconde potenti meccanismi tecnici:
- Organizzazione dei file: Supporta supporti di archiviazione comuni come HDFS e archiviazione di oggetti.
- Partizionamento intelligente: Supporta le funzioni di trasformazione delle partizioni per abilitare il partizionamento implicito di Iceberg e le funzionalità di evoluzione delle partizioni.
- Ottimizzazione dello storage: Supporta formati di archiviazione colonnari come Parquet e ORC, combinati con vari metodi di compressione per migliorare le prestazioni.
Con il supporto di Doris per le operazioni DDL e DML su Iceberg, le problematiche legate alla consistenza dei dati sono completamente risolte.
Gestione delle operazioni e della manutenzione
Per garantire la stabilità della piattaforma dati, Xiao Zhang utilizza i seguenti metodi per monitorare e gestire le tabelle Iceberg:
-- View table snapshot information
SELECT * FROM iceberg_meta(
"table" = "iceberg.nyc.taxis",
"query_type" = "snapshots"
);
-- Query a specific snapshot using FOR VERSION AS OF
SELECT * FROM iceberg.nyc.taxis FOR VERSION AS OF {snapshot_id};
-- Query a specific snapshot using FOR TIME AS OF
SELECT * FROM iceberg.nyc.taxis FOR TIME AS OF {committed_at};
-- Manage snapshots
...
Questo insieme di strumenti fornisce:
- Monitoraggio delle metriche: Controllo in tempo reale dello stato delle tabelle e delle metriche degli snapshot.
- Gestione degli snapshot: Pulizia degli snapshot scaduti per rilasciare spazio di archiviazione.
- Recupero dei guasti: Supporta il ripristino a qualsiasi versione storica (lettura dei dati della versione storica basata sull’ID dello snapshot o sul tempo di creazione dello snapshot).
Attraverso queste pratiche, la piattaforma dati di Xiao Zhang basata su Doris + Iceberg ha raggiunto nuove vette:
- Le prestazioni delle query sono migliorate del 300%.
- Costi di archiviazione ridotti del 40%.
- Efficienza delle operazioni e della manutenzione aumentata del 200%.
L’entusiasmante viaggio della casa sul lago di Doris non ha mai fine.
Rimanete sintonizzati per ulteriori contenuti interessanti, utili e preziosi nel prossimo numero!