













Midden in de nacht wakker worden vanwege een datafout, heb je ooit gedroomd van een ideale datawereld waarin queries binnen seconden terugkomen, data nooit verloren gaat en kosten zo laag zijn dat je baas glimlacht? Klinkt als een droom? Nee! Dit wordt werkelijkheid.
Herinner je je die nacht nog dat je werd overweldigd door data-partitioneringsproblemen, terwijl de productmanager wanhopig vooruitgang boekte terwijl jij worstelde met verspreide data? Cross-source queries waren zo traag als een slak die een berg beklom, en schemawijzigingen vereisten coördinatie over zeven afdelingen.
Maar nu worden deze pijnpunten herschreven.
De combinatie van Apache Doris en Iceberg herdefinieert de manier waarop datalakes werken. Het is niet slechts een eenvoudige 1+1=2; het brengt een kwalitatieve sprong: queries op het niveau van seconden, naadloze schemamutatie en echte gegevensconsistentiegaranties.
De Perfecte Symfonie van Doris en Iceberg
In het vakgebied van data-engineering komen we vaak dergelijke problemen tegen:
Xiao Zhang werkt aan een data-analysevereiste, waarbij hij gebruikersgedragsgegevens van de afgelopen drie maanden moet analyseren. De data is verspreid over Hive datawarehouses, bedrijfsdatabases en objectopslag. De prestaties van cross-source Joins zijn slecht, met queries die meer dan 40 minuten in beslag nemen, en gegevensinconsistentie komt vaak voor.
Bovendien moet Xiao Zhang ook omgaan met datagovernancewerk, en elke wijziging in tabelstructuur bezorgt hem hoofdpijn. Meerdere downstream-toepassingen zijn afhankelijk van deze tabellen, en schemawijzigingen vereisen coördinatie over meerdere teams, mogelijk een week om een enkele wijziging te voltooien.
Deze problemen zijn prominenter geworden met de explosieve groei van gegevens. De traditionele scheiding tussen gegevensmagazijnen en datalakes kan niet langer aan de behoeften voldoen.
Gelukkig is in versie 2.1 de ‘lakehouse-architectuur van Apache Doris’ aanzienlijk verbeterd. Het verbetert niet alleen de lees- en schrijfmogelijkheden van mainstream datalake-formaten (Hudi, Iceberg, Paimon, enz.), maar introduceert ook compatibiliteit met meerdere SQL-dialecten, waardoor naadloos kan worden overgestapt van bestaande systemen naar Apache Doris. In scenarios voor datawetenschap en het lezen van grootschalige gegevens integreert Doris de Arrow Flight high-speed leesinterface, wat resulteert in een verbetering van 100x in gegevensoverdrachtsefficiëntie.
Daarom besloot Xiao Zhang Doris + Iceberg te gebruiken voor zijn inlossing.
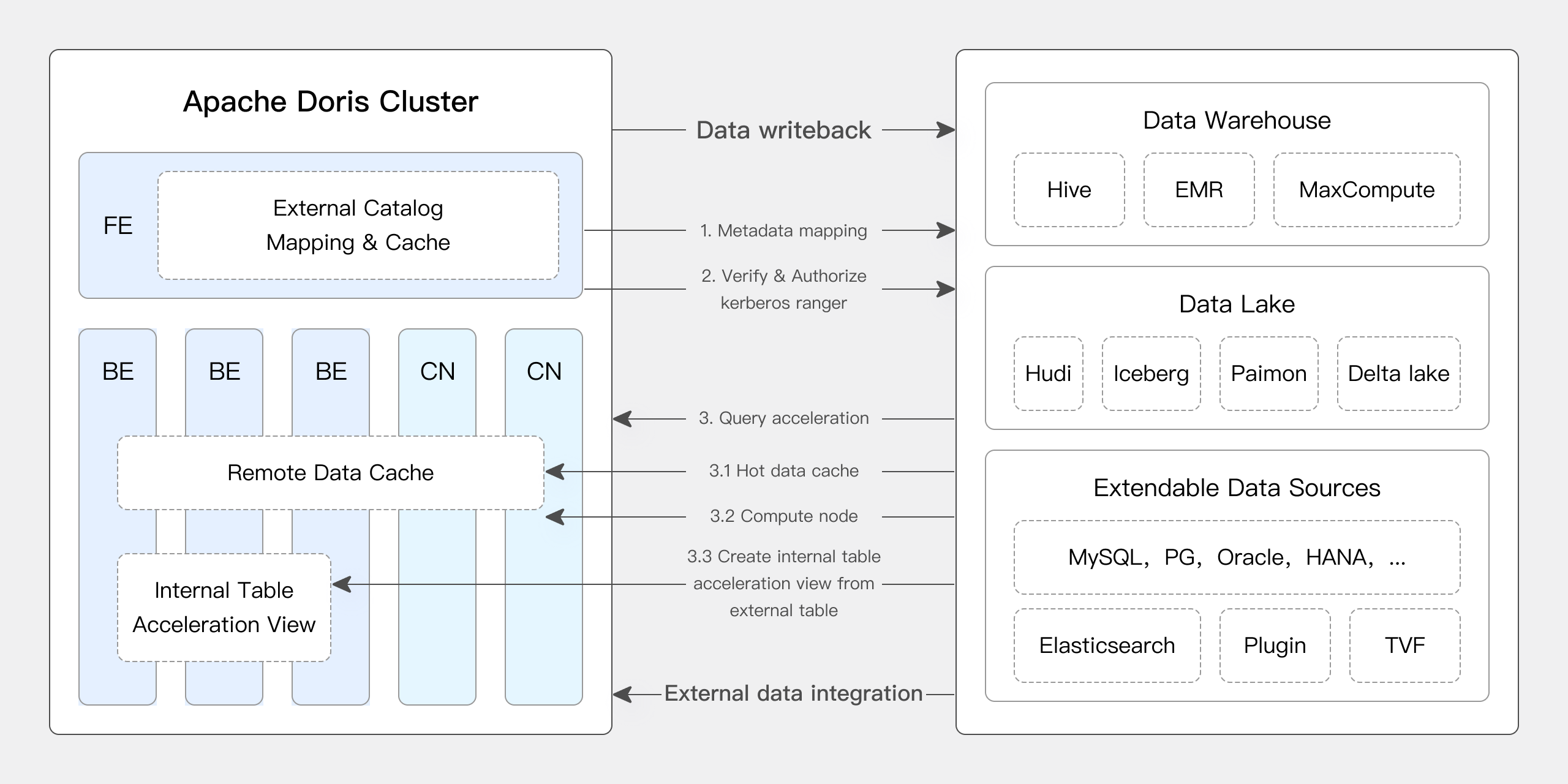
Apache Doris biedt native ondersteuning voor vele kernfuncties van Iceberg:
- Ondersteunt verschillende Iceberg-catalogustypen zoals Hive Metastore, Hadoop, REST, Glue, Google Dataproc Metastore en DLF.
- Ondersteunt native Iceberg V1/V2 tabelindelingen, evenals het lezen van Position Delete- en Equality Delete-bestanden.
- Ondersteunt het opvragen van de geschiedenis van Iceberg-tabelmomentopnamen via tabelfuncties.
- Ondersteunt functionaliteit voor tijdreizen.
- Ondersteunt native de Iceberg-tabelengine. Apache Doris kan rechtstreeks gegevens maken, beheren en schrijven in Iceberg-tabellen. Het ondersteunt een volledige reeks partitietransformatiefuncties, biedt mogelijkheden zoals verborgen partities en partitie-indelingsevolutie.
Bovendien bracht versie 2.1.6 van Doris aanzienlijke upgrades naar Doris + Iceberg:
Apache Doris ondersteunt DDL- en DML-bewerkingen op Iceberg. Gebruikers kunnen rechtstreeks databases en tabellen aanmaken in Iceberg via Apache Doris en gegevens schrijven in Iceberg-tabellen.
Met deze functie kunnen gebruikers volledige gegevensquery’s uitvoeren en schrijfbewerkingen op Iceberg uitvoeren met behulp van Apache Doris, waardoor de lakehouse-architectuur verder wordt vereenvoudigd.
Daarom kan Xiao Zhang snel een efficiënte lakehouse-oplossing bouwen op basis van Apache Doris + Apache Iceberg om flexibel te voldoen aan verschillende behoeften voor realtime gegevensanalyse en verwerking:
- Gebruik de krachtige query-engine van Doris om gegevens van Iceberg-tabellen en andere gegevensbronnen te koppelen en analyseren, waardoor een uniform gegevensanalyseplatform wordt gebouwd.
- Beheer en bouw Iceberg-tabellen rechtstreeks in Doris, reinig en verwerk gegevens, en schrijf ze in Iceberg-tabellen, waardoor een uniform lakehouse-dataverwerkingsplatform wordt gebouwd.
- Deel Doris-gegevens met andere upstream- en downstreamsystemen voor verdere verwerking via de Iceberg-tabelengine, waardoor een uniform open gegevensopslagplatform wordt gebouwd.
Dit is niet langer een eenvoudige oppervlakte-integratie maar een diepe fusie van lakehouse-architecturen!
Praktische samenvatting van Doris en Iceberg
Na een reeks ups en downs in verkenning en praktijk heeft Xiao Zhang enkele praktische ervaringen samengevat met Doris + Iceberg:
Intelligent Metadata Management
In traditionele oplossingen is metadatamanagement altijd een lastig punt geweest. Tabelpartitioneringsinformatie, bestandslocaties en schemawijzigingsgeschiedenissen zijn overal verspreid, wat leidt tot slechte queryprestaties en complexe operaties en onderhoud.
Doris + Iceberg biedt een uniforme metadatamanagementlaag:
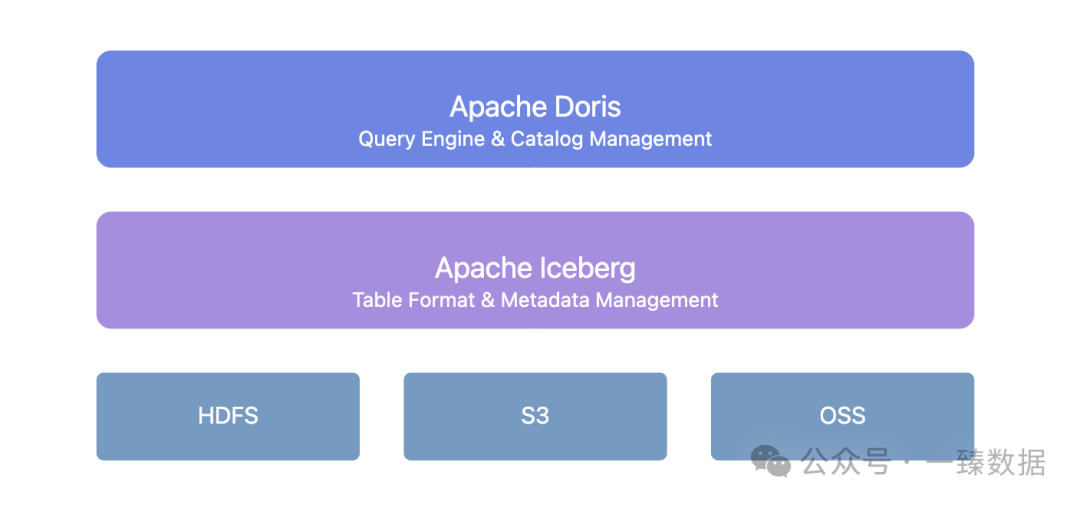
Deze architectuur brengt verschillende belangrijke waarden met zich mee:
- Naadloze schemaevolutie: Tabelstructuurwijzigingen vereisen geen downtime meer. Doris + Iceberg ondersteunt het toevoegen, verwijderen en wijzigen van velden, evenals het aanpassen van partioneringsmethoden.
- Data-versiebeheer: Via het snapshotsmechanisme van Iceberg kunt u op elk moment terugkeren naar de gegevenstoestand.
- Uniforme catalogusservice: Ondersteunt verschillende Iceberg Catalogustypen zoals Hive Metastore, Hadoop, REST, Glue, Google Dataproc Metastore en DLF, naadloos geïntegreerd met bestaande infrastructuur.
Xiao Zhang kan nu schema wijzigingen voltooien met een enkele ALTER TABLE-verklaring. Het systeem handelt automatisch de compatibiliteit af en downstream-toepassingen blijven onbewust van de wijzigingen.
Efficiënte gegevensorganisatie
Doris combineert op een innovatieve manier de MPP-engine met de gegevensorganisatiemethoden van Iceberg:
-- Create a partitioned Iceberg table
-- Partition columns must be in the table's column definition list
CREATE TABLE sales (
ts DATETIME,
user_id BIGINT,
amount DOUBLE,
pt1 STRING,
pt2 STRING
) ENGINE=iceberg
-- Iceberg's partition type corresponds to List partitioning in Doris
PARTITION BY LIST (DAY(ts), pt1, pt2) ()
PROPERTIES (
-- Compression format
-- Parquet: snappy, zstd (default), plain (no compression)
-- ORC: snappy, zlib (default), zstd, plain (no compression)
'write-format'='orc',
'compression-codec'='zlib'
);
Deze SQL-instructie verbergt krachtige technische mechanismen:
- Bestandsorganisatie: Ondersteunt gangbare opslagmedia zoals HDFS en objectopslag.
- Slimme partitionering: Ondersteunt partition-transformatiefuncties om de impliciete partitionering en partition-evolutiefuncties van Iceberg mogelijk te maken.
- Opslagoptimalisatie: Ondersteunt kolomgebaseerde opslagformaten zoals Parquet en ORC, gecombineerd met verschillende compressiemethoden om de prestaties te verbeteren.
Met de ondersteuning van Doris voor DDL- en DML-bewerkingen op Iceberg zijn ook de problemen met gegevensconsistentie volledig opgelost.
Beheer van operaties en onderhoud
Om de stabiliteit van het dataplatform te waarborgen, gebruikt Xiao Zhang de volgende methoden om Iceberg-tabellen te monitoren en te beheren:
-- View table snapshot information
SELECT * FROM iceberg_meta(
"table" = "iceberg.nyc.taxis",
"query_type" = "snapshots"
);
-- Query a specific snapshot using FOR VERSION AS OF
SELECT * FROM iceberg.nyc.taxis FOR VERSION AS OF {snapshot_id};
-- Query a specific snapshot using FOR TIME AS OF
SELECT * FROM iceberg.nyc.taxis FOR TIME AS OF {committed_at};
-- Manage snapshots
...
Deze toolchain biedt:
- Prestatiemonitoring: Real-time controle van de tabelstatus en snapshot-metrics.
- Snapshotbeheer: Verwijder verlopen snapshots om opslagruimte vrij te maken.
- Foutherstel: Ondersteunt het terugrollen naar elke historische versie (het lezen van historische versiegegevens op basis van snapshot-ID of creatietijd van de snapshot).
Door deze praktijken heeft het dataplatform van Xiao Zhang, gebaseerd op Doris + Iceberg, nieuwe hoogten bereikt:
- De queryprestaties zijn met 300% verbeterd.
- De opslagkosten zijn met 40% verlaagd.
- De efficiëntie van operaties en onderhoud is met 200% toegenomen.
De spannende reis van het meerhuis van Doris is eindeloos.
Blijf op de hoogte voor meer interessante, nuttige en waardevolle inhoud in het volgende nummer!