













深夜にデータのバグで目が覚めたことがありますか?クエリが数秒で返ってくる理想的なデータの世界を夢見たことがありますか?データが失われることはなく、コストが低く、上司がにっこり笑っている姿が浮かぶでしょうか?夢のような話?いいえ!これは現実になりつつあります。
データパーティショニングの問題で悩まされ、製品マネージャーが進捗を急いでいる中、データの散乱に苦しんでいたあの夜を覚えていますか?クロスソースのクエリは山を登るカタツムリのように遅く、スキーマの変更には7つの部署での調整が必要でした。
しかし、これらの痛みは再定義されつつあります。
Apache DorisとIcebergの組み合わせがデータレイクの動作方法を再定義しています。これは単なる1+1=2ではなく、質的な飛躍をもたらしています:秒単位のクエリ、シームレスなスキーマ進化、真のデータの一貫性の保証です。
DorisとIcebergの完璧なシンフォニー
データエンジニアリングの世界では、よくこのような問題に直面します:
小林さんは過去3か月間のユーザーの行動データを分析する必要があるデータ分析の要件に取り組んでいます。データはHiveデータウェアハウス、ビジネスデータベース、オブジェクトストレージに散在しています。クロスソースの結合のパフォーマンスが悪く、クエリには40分以上かかり、データの不整合が頻繁に発生します。
さらに、小林さんはデータガバナンスの作業にも対応しなければならず、各テーブル構造の変更が頭痛の種です。複数の下流アプリケーションがこれらのテーブルに依存しており、スキーマの変更には複数のチームとの調整が必要で、1つの変更を完了するのに1週間かかるかもしれません。
これらの問題はデータの爆発的な成長とともにより顕著になっています。データウェアハウスとデータレイクの従来の分離では、もはやニーズを満たすことができません。
幸いにも、バージョン2.1では、Apache Dorisのレイクハウスアーキテクチャが大幅に強化されました。これにより、主要なデータレイクフォーマット(Hudi、Iceberg、Paimonなど)の読み書き機能が向上し、既存のシステムからApache Dorisにシームレスに切り替えることができるマルチSQLダイアレクトの互換性が導入されました。データサイエンスや大規模データ読み取りシナリオでは、DorisはArrow Flight高速読み取りインターフェースを統合し、データ転送効率を100倍向上させました。
そのため、小さな張さんは自分のリデンプションにDoris + Icebergを使用することに決めました。
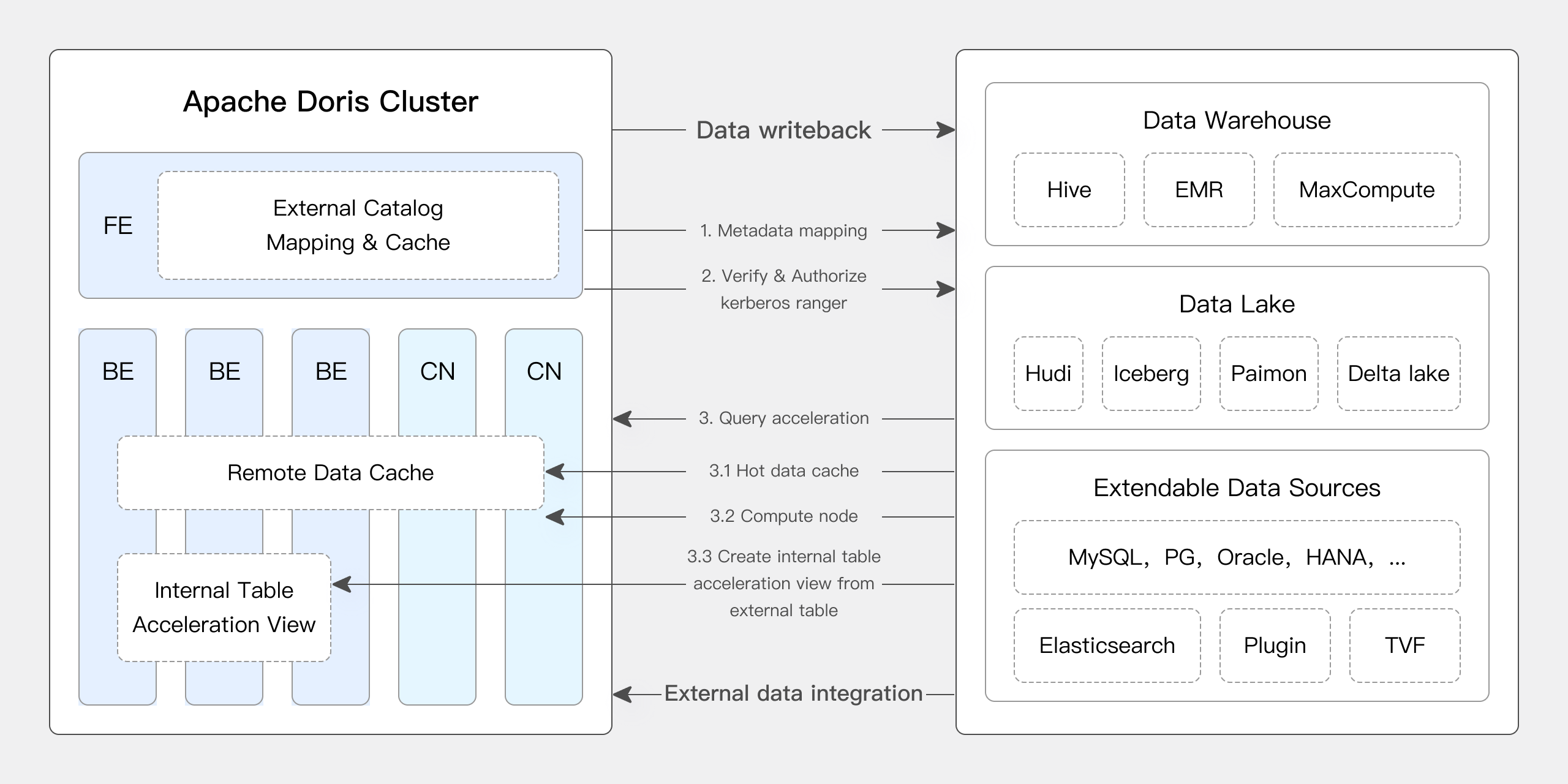
Apache Dorisは、Icebergの多くのコア機能をネイティブでサポートしています:
- Hive Metastore、Hadoop、REST、Glue、Google Dataproc Metastore、およびDLFなどのさまざまなIcebergカタログタイプをサポートしています。
- Iceberg V1/V2テーブルフォーマットをネイティブでサポートし、Position DeleteとEquality Deleteファイルの読み取りを行います。
- テーブル関数を介してIcebergテーブルのスナップショット履歴をクエリできます。
- タイムトラベル機能をサポートしています。
- アイスバーグテーブルエンジンをネイティブでサポートしています。Apache Dorisは、アイスバーグテーブルに直接データを作成、管理、書き込むことができます。完全なセットのパーティション変換関数をサポートし、非表示パーティションやパーティションレイアウトの進化などの機能を提供しています。
さらに、Dorisのバージョン2.1.6では、Doris + Icebergに大幅なアップグレードがもたらされました。
Apache DorisはIcebergでのDDLおよびDML操作をサポートしています。ユーザーはApache Dorisを介してIcebergでデータベースやテーブルを直接作成し、データをIcebergテーブルに書き込むことができます。
この機能により、ユーザーはApache Dorisを使用してIcebergで完全なデータクエリと書き込み操作を実行でき、さらにレイクハウスアーキテクチャをさらに簡素化できます。
したがって、小さな湖は、リアルタイムのデータ分析と処理のさまざまなニーズに柔軟に対応するために、Apache Doris + Apache Icebergに基づいた効率的なレイクハウスソリューションを迅速に構築できます。
- アイスバーグテーブルや他のデータソースからデータを結合して分析するためにDorisの高性能クエリエンジンを使用し、統合された連邦データ分析プラットフォームを構築します。
- DorisでIcebergテーブルを直接管理および構築し、データをクリーンアップして処理し、Icebergテーブルに書き込み、統合されたレイクハウスデータ処理プラットフォームを構築します。
- Icebergテーブルエンジンを介して他の上流および下流システムとDorisデータを共有し、統合されたオープンデータストレージプラットフォームを構築します。
これは単なる表面的な統合ではなく、レイクハウスアーキテクチャの深い融合です!
ドリスとアイスバーグの実用的な要約
探査と実践の一連の挑戦の後、小張はドリス+アイスバーグに関するいくつかの実用的な経験をまとめました:
インテリジェントメタデータ管理
従来のソリューションでは、メタデータ管理は常に難題でした。テーブルのパーティション情報、ファイルの場所、スキーマの変更履歴があちこちに散らばっており、クエリのパフォーマンスが低下し、操作とメンテナンスが複雑化していました。
ドリス+アイスバーグは統一されたメタデータ管理レイヤーを提供します:
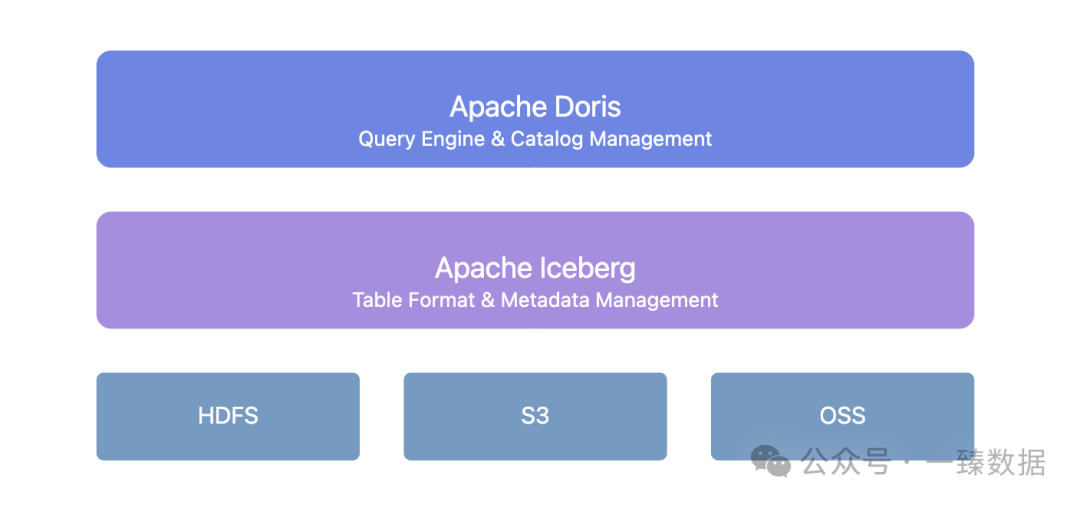
このアーキテクチャにはいくつかの重要な価値があります:
- シームレスなスキーマ進化:テーブル構造の変更に downtime が不要になりました。ドリス+アイスバーグはフィールドの追加、削除、変更、およびパーティショニング方法の調整をサポートしています。
- データバージョン管理:Icebergのスナップショットメカニズムを通じて、任意の時点でデータの状態に戻すことができます。
- 統一されたカタログサービス:Hive Metastore、Hadoop、REST、Glue、Google Dataproc Metastore、DLF など、さまざまな Iceberg カタログタイプをサポートし、既存のインフラとシームレスに統合します。
小張は今や単一の ALTER TABLE ステートメントでスキーマ変更を完了できます。システムが互換性を自動的に処理し、下流アプリケーションは変更に気づくことはありません。
効率的なデータの整理
Dorisは、Icebergのデータ整理方法とMPPエンジンを革新的に組み合わせています。
-- Create a partitioned Iceberg table
-- Partition columns must be in the table's column definition list
CREATE TABLE sales (
ts DATETIME,
user_id BIGINT,
amount DOUBLE,
pt1 STRING,
pt2 STRING
) ENGINE=iceberg
-- Iceberg's partition type corresponds to List partitioning in Doris
PARTITION BY LIST (DAY(ts), pt1, pt2) ()
PROPERTIES (
-- Compression format
-- Parquet: snappy, zstd (default), plain (no compression)
-- ORC: snappy, zlib (default), zstd, plain (no compression)
'write-format'='orc',
'compression-codec'='zlib'
);
このSQLステートメントは、強力な技術メカニズムを隠しています。
- ファイルの整理:HDFSやオブジェクトストレージなど、一般的なストレージメディアをサポートしています。
- スマートパーティショニング:Icebergの暗黙のパーティショニングとパーティション進化機能を有効にするパーティション変換関数をサポートしています。
- ストレージ最適化:ParquetやORCなどのカラムストレージ形式をサポートし、さまざまな圧縮方法と組み合わせてパフォーマンスを向上させます。
DorisがIcebergでのDDLおよびDML操作をサポートすることで、データ整合性の問題も完全に解決されます。
操作とメンテナンス管理
データプラットフォームの安定性を確保するため、Xiao ZhangはIcebergテーブルを監視および管理するために以下の方法を使用しています。
-- View table snapshot information
SELECT * FROM iceberg_meta(
"table" = "iceberg.nyc.taxis",
"query_type" = "snapshots"
);
-- Query a specific snapshot using FOR VERSION AS OF
SELECT * FROM iceberg.nyc.taxis FOR VERSION AS OF {snapshot_id};
-- Query a specific snapshot using FOR TIME AS OF
SELECT * FROM iceberg.nyc.taxis FOR TIME AS OF {committed_at};
-- Manage snapshots
...
このツールチェーンは次のものを提供します。
- メトリックモニタリング:テーブルの状態とスナップショットメトリックのリアルタイム制御。
- スナップショット管理:期限切れのスナップショットをクリーンアップしてストレージスペースを解放します。
- 障害復旧:任意の過去バージョンにロールバックすることをサポートします(スナップショットIDまたはスナップショット作成時の時刻に基づいて過去バージョンデータを読み取る)。
これらの実践により、Xiao ZhangのDoris + Icebergベースのデータプラットフォームは新たな高みに達しました。
- クエリパフォーマンスが300%向上しました。
- ストレージコストが40%削減されました。
- 操作とメンテナンスの効率が200%向上しました。
ドリスの湖畔の刺激的な旅は終わることはありません。
次号でもさらに興味深く、役立つ、貴重なコンテンツをお楽しみに!