













Nella programmazione Python, NumPy e Pandas si distinguono come due delle librerie più potenti per il calcolo numerico e la manipolazione dei dati.
NumPy: La Fondazione del Calcolo Numerico
NumPy (Numerical Python) fornisce supporto per array multidimensionali e una vasta gamma di funzioni matematiche, rendendolo essenziale per il calcolo scientifico.
- NumPy è il pacchetto fondamentale per il calcolo numerico in Python.
- Uno dei motivi per cui NumPy è così importante per i calcoli numerici è che è progettato per l’efficienza con grandi array di dati. Le ragioni di ciò includono:
- Memorizza i dati internamente in un blocco continuo di memoria, indipendente da altri oggetti Python incorporati.
- Esegue calcoli complessi su interi array senza la necessità di cicli “for”.
- Il
ndarrayè un efficiente array multidimensionale che offre veloci operazioni aritmetiche orientate agli array e flessibili capacità di broadcasting. - L’oggetto
ndarraydi NumPy è un contenitore veloce e flessibile per grandi set di dati in Python. - Gli array ti consentono di memorizzare più elementi dello stesso tipo di dati. Sono le funzionalità attorno all’oggetto array che rendono NumPy così comodo per eseguire operazioni matematiche e di manipolazione dei dati.
Operazioni in NumPy
Creazione dell’array:

Rimodellare l’array:

Taglio e indicizzazione:

Operazioni aritmetiche:
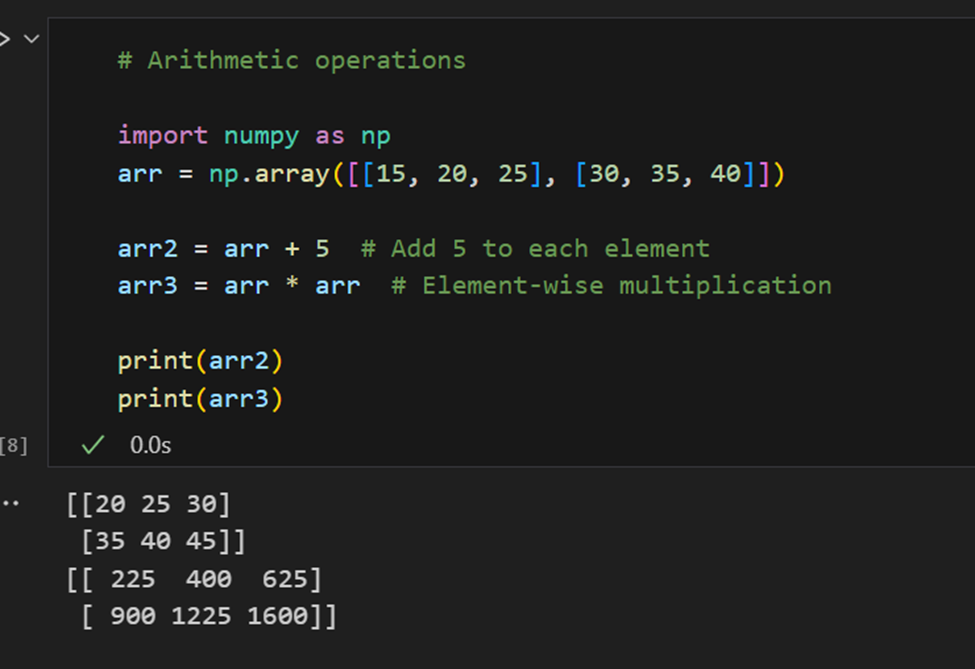
Algebra lineare:

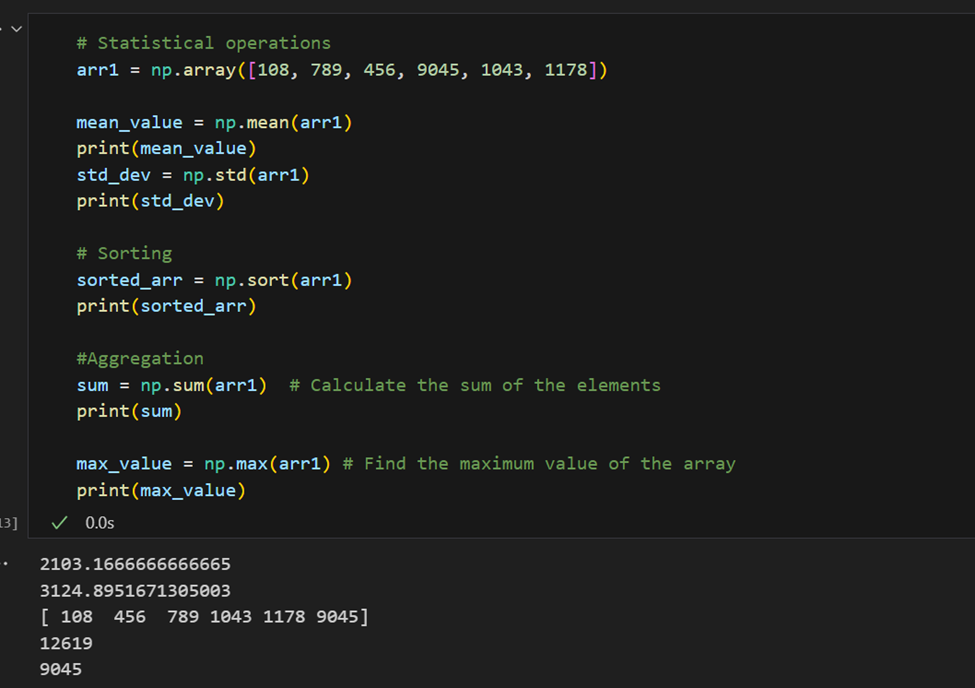
Operazioni statistiche:
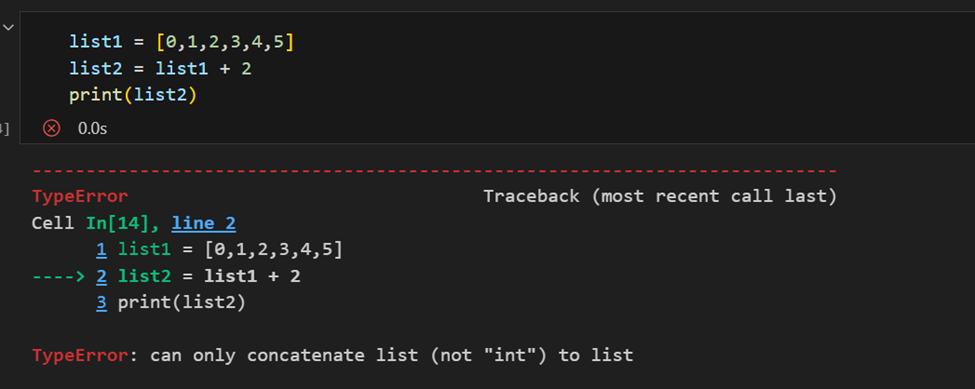
Differenza tra Array NumPy e Lista Python
La differenza principale tra un array e una lista è che gli array sono progettati per gestire operazioni vettorializzate, mentre una lista Python no. Ciò significa che, se si applica una funzione, viene eseguita su ogni elemento dell’array, anziché sull’intero oggetto array.
Pandas
Pandas si distingue come una delle librerie più potenti per il calcolo numerico e la manipolazione dei dati, fondamentali per aree come l’intelligenza artificiale e il machine learning.
Pandas, come NumPy, è una delle librerie Python più popolari. Si tratta di un’astrazione di alto livello su NumPy, scritta in puro C. Pandas fornisce strutture dati ad alte prestazioni e strumenti di analisi dei dati facili da usare. Pandas utilizza due strutture principali: data framee serie.
Indici nelle Serie Pandas
Una serie Pandas è simile a una lista, ma si differenzia dal fatto che a ogni elemento è associata un’etichetta. Questo la fa assomigliare a un dizionario. Se un indice non è fornito esplicitamente dall’utente, Pandas crea un RangeIndex che va da 0 a N-1. Ogni oggetto serie ha anche un tipo di dati.
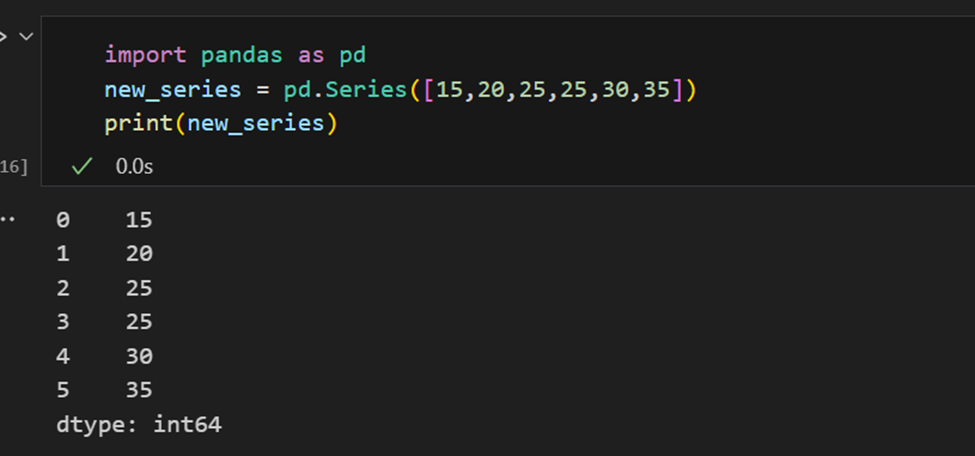
Una serie Pandas ha modi per estrarre tutti i valori nella serie, così come singoli elementi per indice.
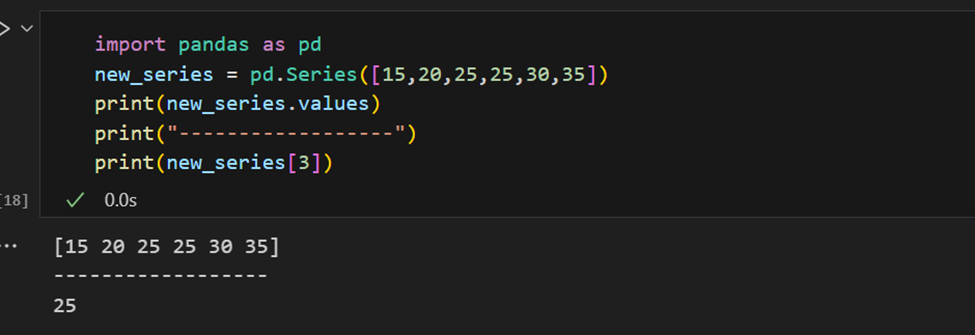
L’indice può essere fornito anche manualmente.
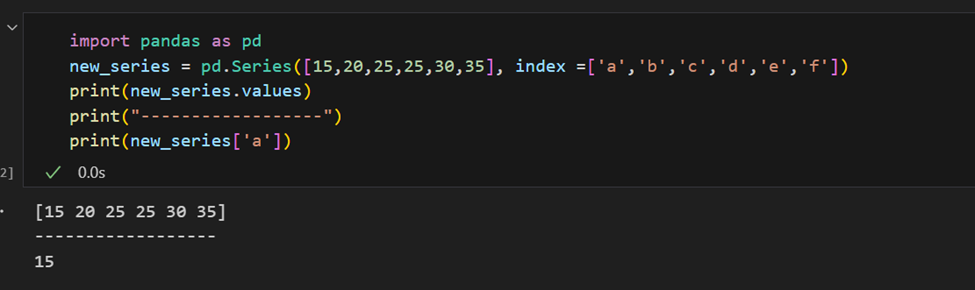
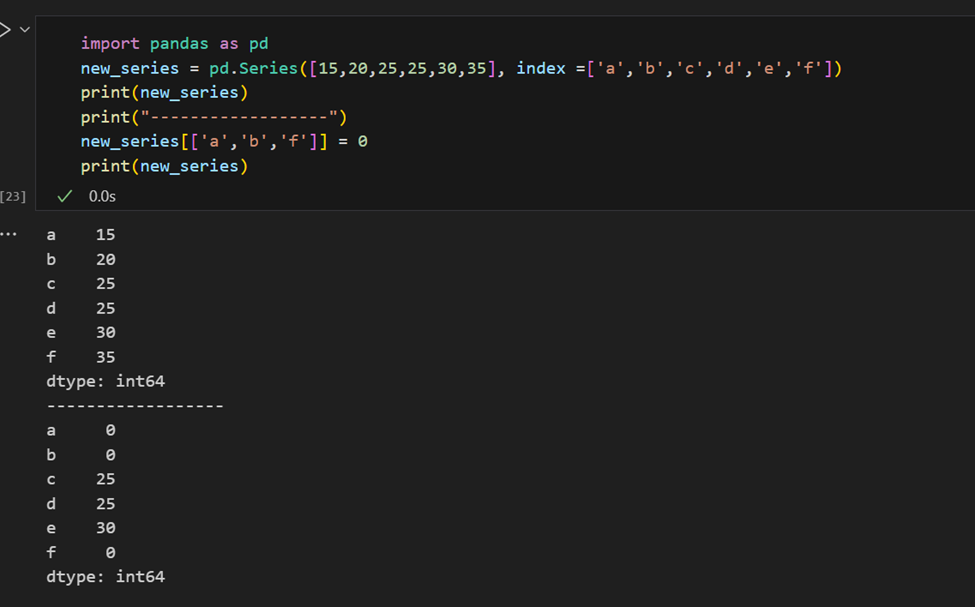
È facile recuperare diversi elementi di una serie dai loro indici o fare assegnazioni di gruppo.
DataFrames di Pandas
Un DataFrame è una tabella con righe e colonne. Ogni colonna in un dataframe è un oggetto di serie. Le righe consistono negli elementi all’interno delle serie. DataFrames di Pandas offrono una vasta gamma di operazioni per la manipolazione e l’analisi dei dati. Ecco una panoramica di alcune operazioni comuni:
Operazioni di Base
Creazione di DataFrames
- Da un dizionario:
pd.DataFrame({'col1': [1, 2], 'col2': [3, 4]}) - Da un file CSV:
pd.read_csv('dati.csv') - Da un file Excel:
pd.read_excel('dati.xlsx')
Accesso ai Dati
- Selezione delle colonne:
df['col1'] - Selezione delle righe:
df.loc[0] (per etichetta di indice), df.iloc[0](per posizione di indice) - Fetta:
df [0:2] (prime due righe), df[['coll', 'col2']](più colonne)
Aggiunta e Rimozione di Colonne/Righe
- Aggiunta di una colonna:
df['nuova_col'] = - Rimozione di una colonna:
df.drop('coll', asse=1) - Aggiunta di una riga:
df.append({'col1': 7, 'col2': 8}, ignore_index=True) - Rimuovere una riga:
df.drop(0)
Filtraggio dei dati
- Utilizzo di condizioni booleane:
df [df['col1'] > 2]
Operazioni matematiche
- Operazioni aritmetiche:
df['col1'] + df['col2'],df * 2, ecc. - Funzioni di aggregazione:
df.sum(),df.mean(),df.max(),df.min(), ecc. - Applicazione di funzioni personalizzate:
df.apply(lambda x: x**2)
Gestione dei dati mancanti
- Verifica dei valori mancanti:
df.isnull() - Eliminazione dei valori mancanti:
df.dropna() - Riempimento dei valori mancanti:
df.fillna(0)
Unione e unione di DataFrame
- Unione:
pd.merge(df1, df2, on='key_column') - Unione:
df1.join(df2, on='key_column')
Raggruppamento e aggregazione
- Raggruppamento:
df.groupby('col1') - Aggregazione:
df.groupby('col1').mean()
Operazioni sulle serie temporali
- Risampling:
df.resample('D').sum()(ridimensionare alla frequenza giornaliera) - Spostamento temporale:
df.shift(1)(spostare i dati di un periodo)
Visualizzazione dei dati
Tracciamento: df.plot() (grafico a linee), df.hist() (istogramma), ecc.
Esempi complessi di Pandas
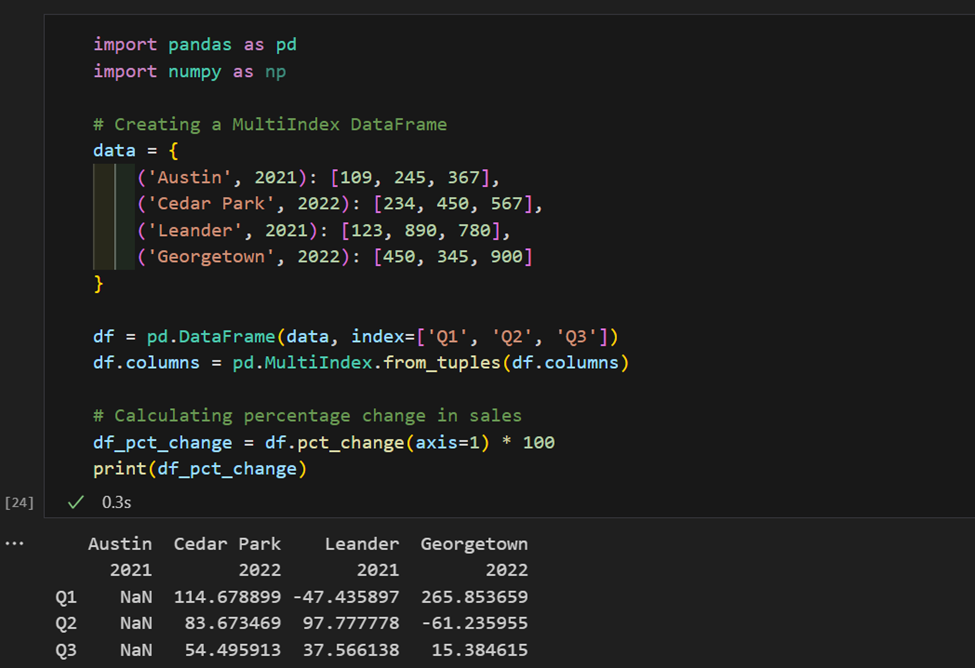
1. Qui, abbiamo dati sulle vendite indicizzati per regione e anno. Ora, qui calcoliamo la variazione percentuale delle vendite per regione.
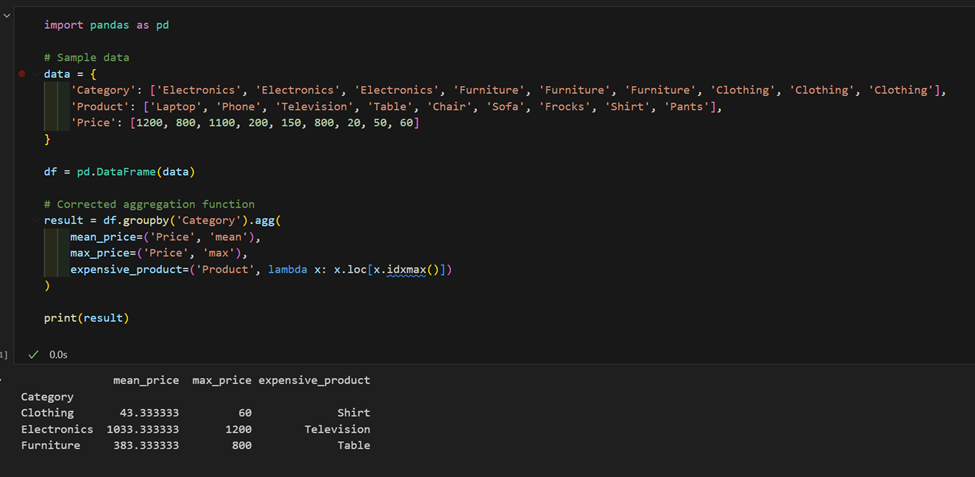
2. Abbiamo un set di dati con prodotti e prezzi, calcoliamo il prezzo medio per categoria e troviamo il prodotto più costoso in ciascuna.
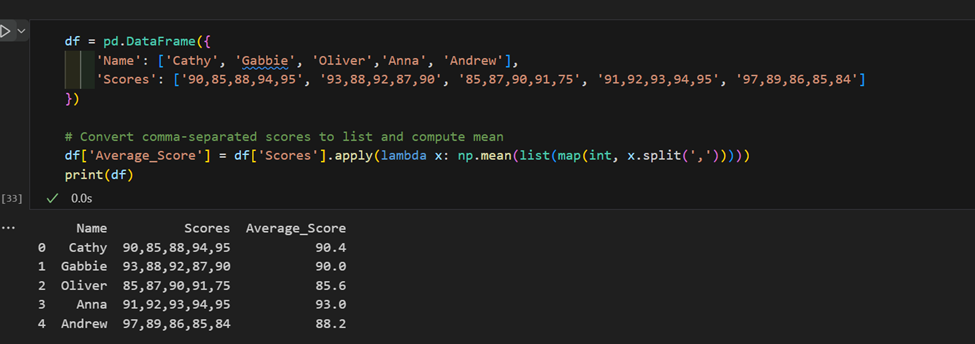
3. Complesso utilizzo di “apply”:
Conclusion
Queste due librerie, NumPy e Pandas, sono ampiamente utilizzate in applicazioni reali come BFSI (analisi finanziaria), calcolo scientifico, IA e ML, e elaborazione di big data. Queste due librerie svolgono un ruolo cruciale nella presa di decisioni basata sui dati, dall’analisi delle tendenze critiche del mercato azionario alla gestione di dati commerciali ERP su larga scala.
Per i principianti, il prossimo passo è praticare l’uso di NumPy e Pandas lavorando su piccoli progetti, esplorando set di dati e applicando le loro funzioni in scenari reali. Si possono scaricare dati open-source da GitHub su dati finanziari, immobiliari o di produzione generale. Con quei dati di origine e queste librerie, si può creare una storia convincente o un’analisi empirica. L’esperienza pratica aiuterà a solidificare i concetti e preparare gli studenti per compiti più avanzati di scienza dei dati.
In conclusione, sia NumPy che Pandas sono due librerie Python essenziali per la manipolazione e l’analisi dei dati. NumPy fornisce un forte supporto per calcoli numerici con le sue efficienti operazioni su array, mentre Pandas si basa su NumPy per offrire strutture dati intrinseche e intuitive come Series e DataFrame per gestire dati strutturati.
Source:
https://dzone.com/articles/python-libraries-introduction-numpy-pandas