













En programmation Python, NumPy et Pandas se distinguent comme deux des bibliothèques les plus puissantes pour le calcul numérique et la manipulation de données.
NumPy : La Fondation du Calcul Numérique
NumPy (Numerical Python) fournit un support pour les tableaux multidimensionnels et une large gamme de fonctions mathématiques, ce qui le rend essentiel pour le calcul scientifique.
- NumPy est le paquet le plus fondamental pour le calcul numérique en Python.
- Une des raisons pour lesquelles NumPy est si important pour les calculs numériques est qu’il est conçu pour l’efficacité avec de grands tableaux de données. Les raisons à cela incluent :
- Il stocke les données internement dans un bloc continu de mémoire, indépendamment des autres objets Python intégrés.
- Il effectue des calculs complexes sur des tableaux entiers sans avoir besoin de boucles « for ».
- Le
ndarrayest un tableau multidimensionnel efficace offrant des opérations arithmétiques rapides orientées tableau et des capacités de diffusion flexibles. - L’objet NumPy
ndarrayest un conteneur rapide et flexible pour de grands ensembles de données en Python. - Les tableaux vous permettent de stocker plusieurs éléments du même type de données. Ce sont les fonctionnalités autour de l’objet tableau qui rendent NumPy si pratique pour effectuer des manipulations mathématiques et de données.
Opérations en NumPy
Création du tableau:

Remodelage du tableau:

Découpage et indexation:

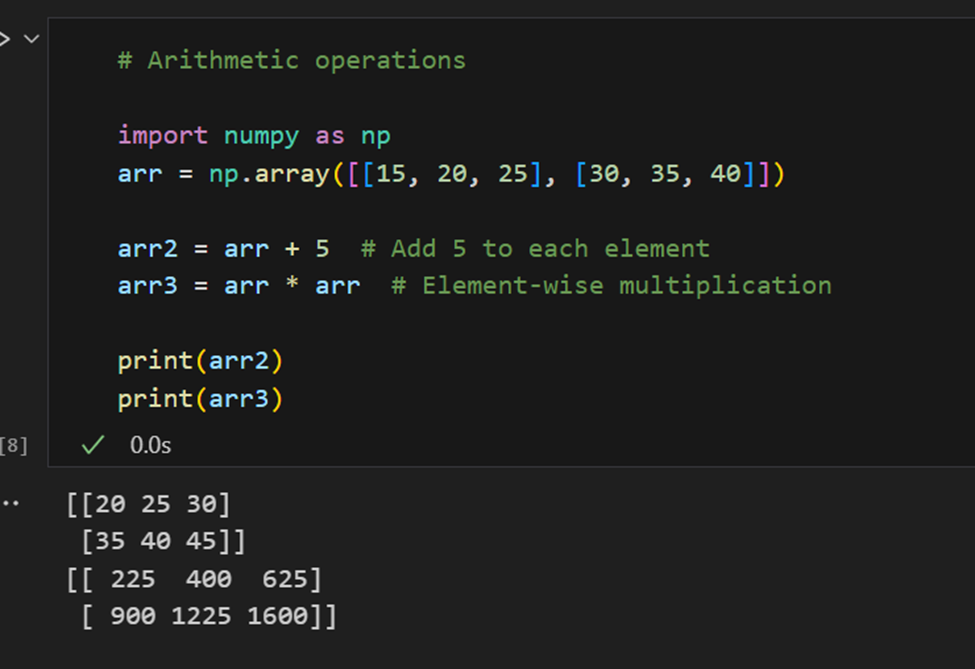
Opérations arithmétiques:
Algèbre linéaire:

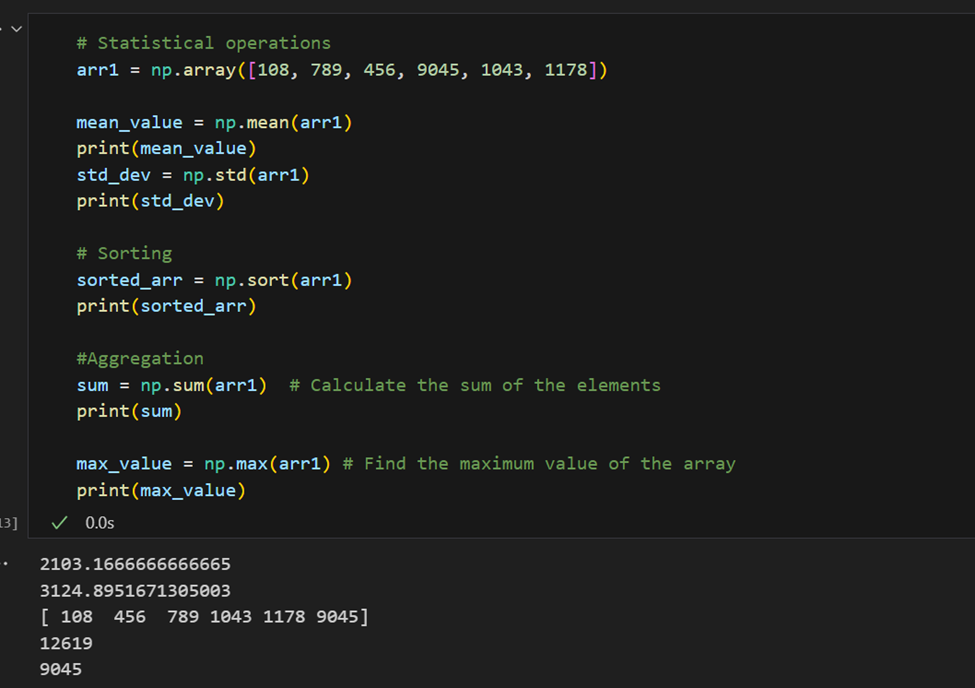
Opérations statistiques:
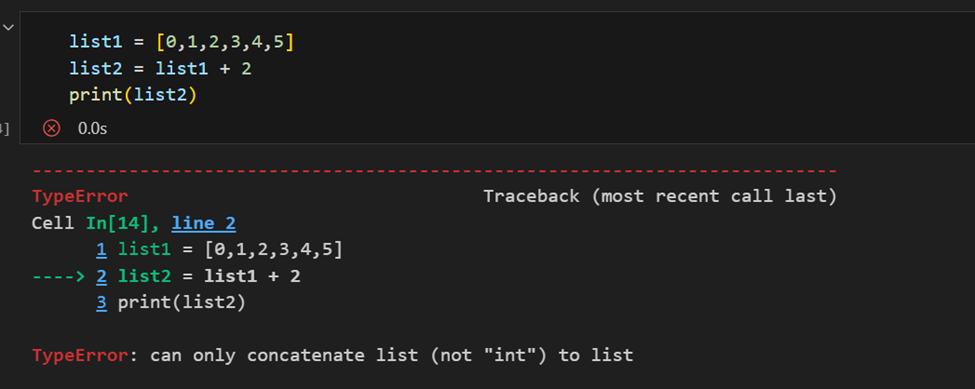
Différence entre un tableau NumPy et une liste Python
La principale différence entre un tableau et une liste est que les tableaux sont conçus pour gérer des opérations vectorisées, tandis qu’une liste Python ne l’est pas. Cela signifie que si vous appliquez une fonction, elle est effectuée sur chaque élément du tableau, plutôt que sur l’ensemble de l’objet tableau.
Pandas
Pandas se distingue comme l’une des bibliothèques les plus puissantes pour le calcul numérique et la manipulation des données, ce qui est essentiel pour les domaines de l’intelligence artificielle et de l’apprentissage automatique.
Pandas, comme NumPy, est l’une des bibliothèques Python les plus populaires. C’est une abstraction de haut niveau sur le bas niveau de NumPy, qui est écrit en pur C. Pandas fournit des structures de données et des outils d’analyse de données performants et faciles à utiliser. Pandas utilise deux structures principales: les cadres de données et séries.
Indices dans les séries Pandas
Une série Pandas est similaire à une liste, mais elle diffère en ce qu’une série associe une étiquette à chaque élément. Cela la fait ressembler à un dictionnaire. Si un index n’est pas explicitement fourni par l’utilisateur, Pandas crée un RangeIndex allant de 0 à N-1. Chaque objet série a également un type de données.
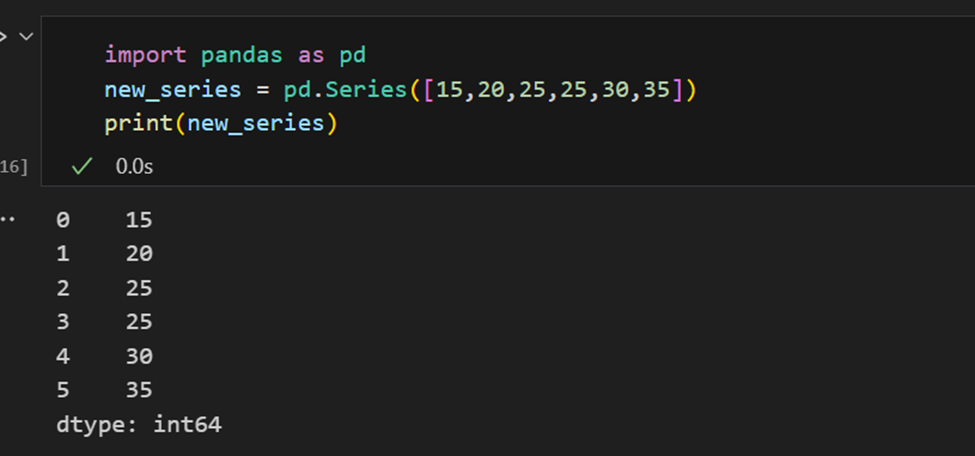
Une série Pandas a des moyens d’extraire toutes les valeurs de la série, ainsi que des éléments individuels par indice.
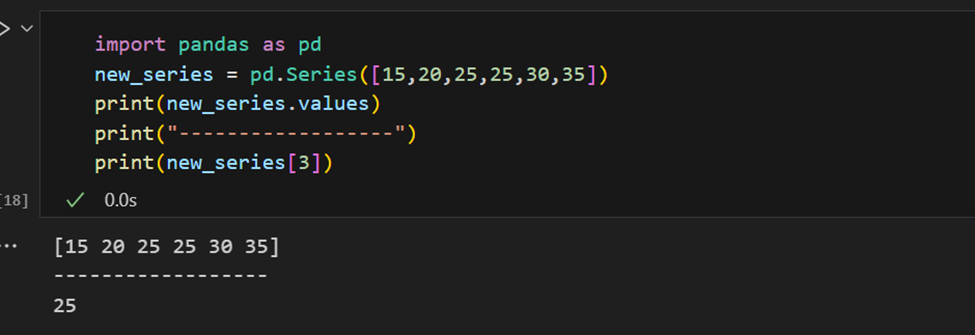
L’indice peut également être fourni manuellement.
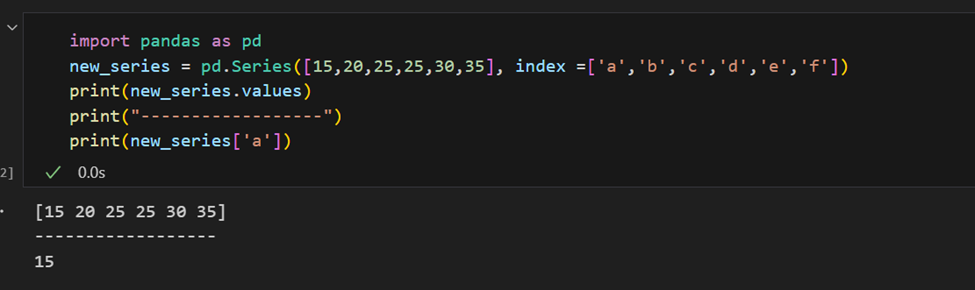
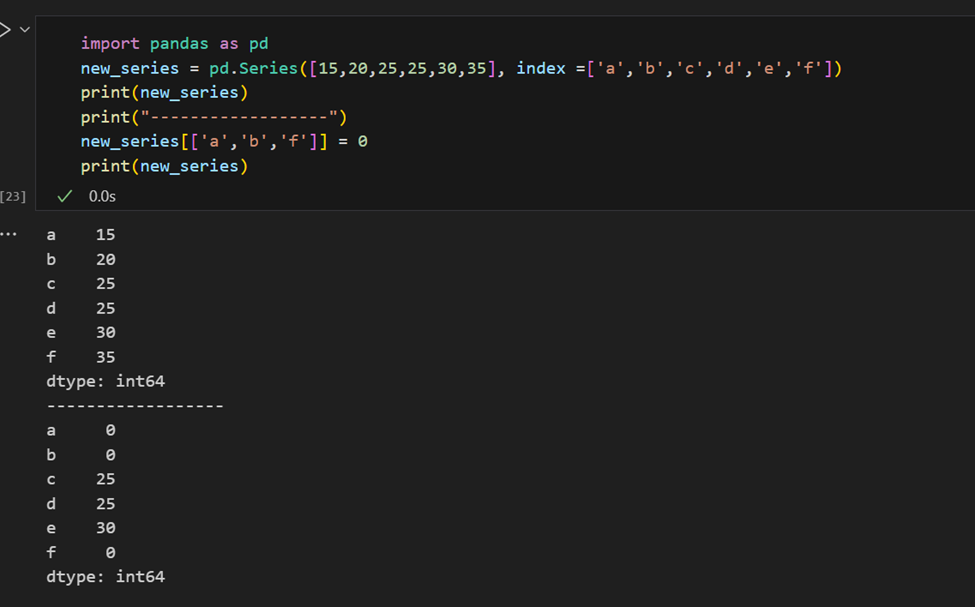
Il est facile de récupérer plusieurs éléments d’une série par leurs indices ou de faire des affectations de groupe.
Les DataFrames Pandas
Un DataFrame est une table avec des lignes et des colonnes. Chaque colonne dans un DataFrame est un objet de série. Les lignes sont constituées d’éléments à l’intérieur des séries. Les DataFrames Pandas offrent une large gamme d’opérations pour la manipulation et l’analyse des données. Voici un aperçu de certaines opérations courantes:
Opérations de base
Création de DataFrames
- À partir d’un dictionnaire:
pd.DataFrame({'col1': [1, 2], 'col2': [3, 4]}) - À partir d’un fichier CSV:
pd.read_csv('data.csv') - À partir d’un fichier Excel:
pd.read_excel('data.xlsx')
Accès aux données
- Sélection des colonnes:
df['col1'] - Sélection des lignes:
df.loc[0] (par étiquette d'indice), df.iloc[0](par position d’indice) - Tranchage:
df [0:2] (premières deux lignes), df[['coll', 'col2']](colonnes multiples)
Ajout et suppression de colonnes/lignes
- Ajout d’une colonne:
df['new_col'] = - Suppression d’une colonne:
df.drop('coll', axis=1) - Ajout d’une ligne:
df.append({'col1': 7, 'col2': 8}, ignore_index=True) - Suppression d’une ligne:
df.drop(0)
Filtrage des données
- Utilisation des conditions booléennes:
df [df['col1'] > 2]
Opérations mathématiques
- Opérations arithmétiques:
df['col1'] + df['col2'],df * 2, etc. - Fonctions d’agrégation:
df.sum(),df.mean(),df.max(),df.min(), etc. - Application de fonctions personnalisées:
df.apply(lambda x: x**2)
Gestion des données manquantes
- Vérification des valeurs manquantes:
df.isnull() - Suppression des valeurs manquantes:
df.dropna() - Remplissage des valeurs manquantes:
df.fillna(0)
Fusion et jointure de DataFrames
- Fusion:
pd.merge(df1, df2, on='key_column') - Jointure:
df1.join(df2, on='key_column')
Regroupement et agrégation
- Regroupement:
df.groupby('col1') - Agrégation:
df.groupby('col1').mean()
Opérations sur les séries temporelles
- Reéchantillonnage:
df.resample('D').sum()(rééchantillonnage à une fréquence quotidienne) - Décalage temporel:
df.shift(1)(décaler les données d’une période)
Visualisation des données
Tracé: df.plot() (tracé de ligne), df.hist() (histogramme), etc.
Exemples complexes de Pandas
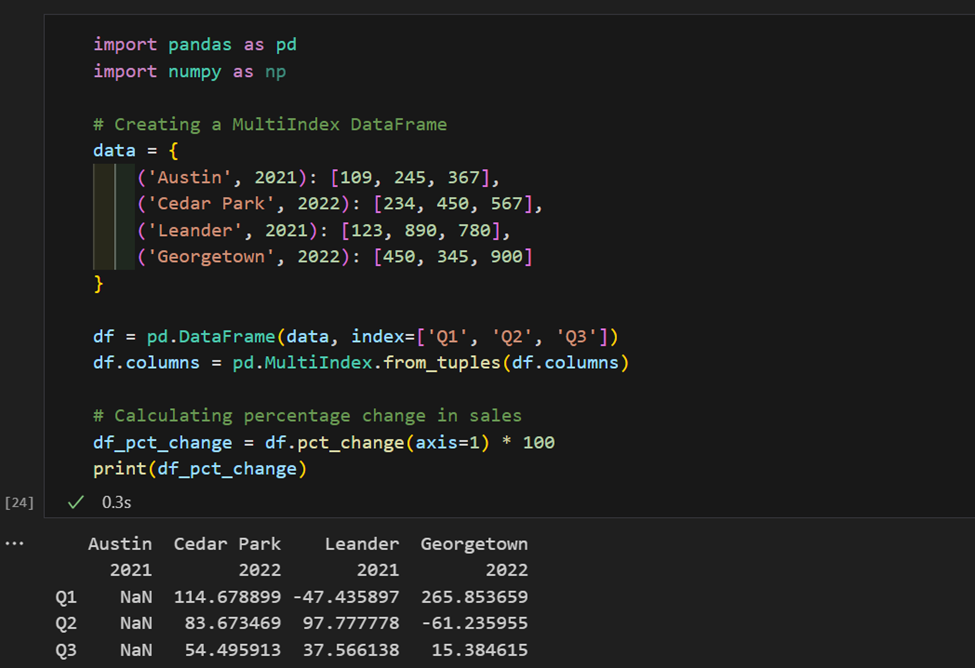
1. Ici, nous avons des données de vente indexées par région et par année. Maintenant, nous calculons le changement en pourcentage des ventes par région.
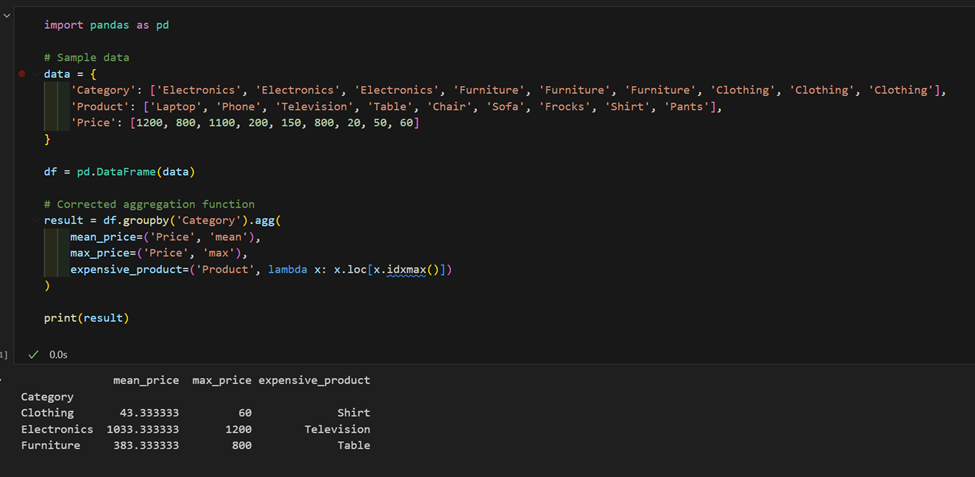
2. Nous disposons d’un ensemble de données avec des produits et des prix, calculons le prix moyen par catégorie et trouvons le produit le plus cher dans chacune.
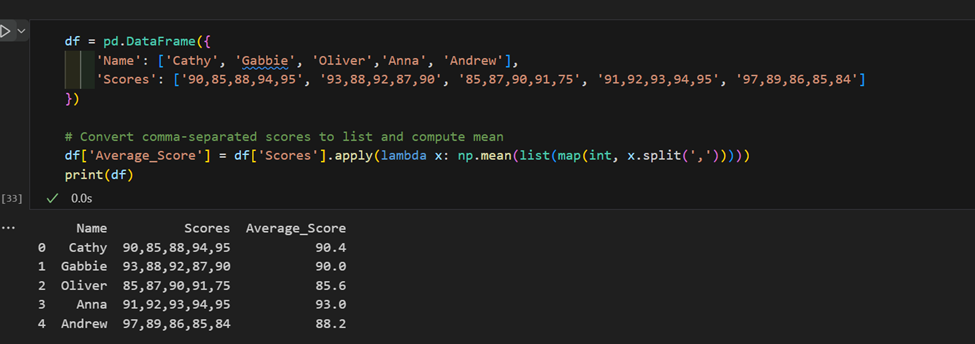
3. Utilisation complexe de « apply »:
Conclusion
Ces deux bibliothèques, NumPy et Pandas, sont largement utilisées dans des applications de la vie réelle telles que la BFSI (analyse financière), le calcul scientifique, l’IA et l’apprentissage automatique, et le traitement de données volumineuses. Ces deux bibliothèques jouent un rôle crucial dans la prise de décisions basée sur les données, de l’analyse des tendances critiques du marché boursier à la gestion de données commerciales ERP à grande échelle.
Pour les débutants, la prochaine étape consiste à pratiquer l’utilisation de NumPy et Pandas en travaillant sur de petits projets, en explorant des ensembles de données, et en appliquant leurs fonctions dans des scénarios du monde réel. On peut télécharger des données open-source depuis GitHub sur les données financières, immobilières ou générales de l’industrie manufacturière. Avec ces données sources et ces bibliothèques, on peut créer une histoire convaincante ou une analyse empirique. L’expérience pratique aidera à solidifier les concepts et à préparer les apprenants à des tâches plus avancées en science des données.
En conclusion, à la fois NumPy et Pandas sont deux bibliothèques Python essentielles pour la manipulation et l’analyse des données. NumPy fournit un support puissant pour les calculs numériques avec ses opérations de tableau efficaces, tandis que Pandas s’appuie sur NumPy pour offrir des structures de données intrinsèques et intuitives comme Series et DataFrame pour la manipulation de données structurées.
Source:
https://dzone.com/articles/python-libraries-introduction-numpy-pandas