













En la programación de Python, NumPy y Pandas destacan como dos de las bibliotecas más poderosas para computación numérica y manipulación de datos.
NumPy: La Fundación de la Computación Numérica
NumPy (Numerical Python) proporciona soporte para matrices multidimensionales y una amplia gama de funciones matemáticas, lo que lo hace esencial para la computación científica.
- NumPy es el paquete más fundamental para la computación numérica en Python.
- Una de las razones por las que NumPy es tan importante para cálculos numéricos es que está diseñado para ser eficiente con grandes arreglos de datos. Las razones para esto incluyen:
- Almacena datos internamente en un bloque continuo de memoria, independiente de otros objetos de Python integrados.
- Realiza cálculos complejos en arreglos enteros sin necesidad de bucles “for”.
- El objeto
ndarrayes un arreglo multidimensional eficiente que proporciona operaciones aritméticas rápidas orientadas al arreglo y capacidades flexibles de transmisión. - El objeto
ndarrayde NumPy es un contenedor rápido y flexible para grandes conjuntos de datos en Python. - Los arreglos te permiten almacenar varios elementos del mismo tipo de datos. Son las facilidades alrededor del objeto de arreglo lo que hace a NumPy tan conveniente para realizar operaciones matemáticas y manipulaciones de datos.
Operaciones en NumPy
Creando el arreglo:

Reformando el arreglo:

Rebanando e indexando:

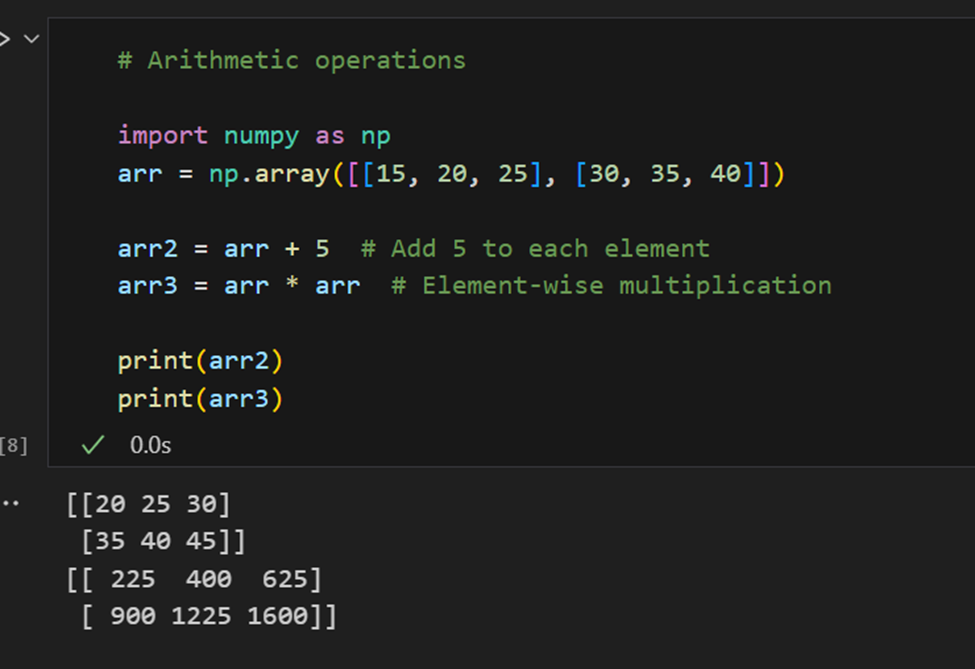
Operaciones aritméticas:
Álgebra lineal:

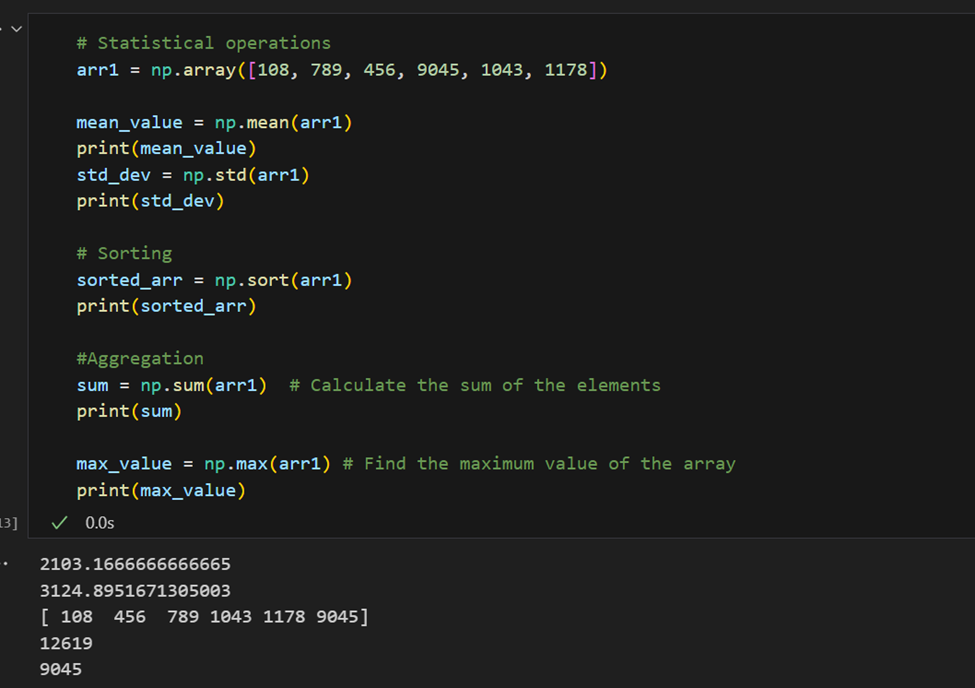
Operaciones estadísticas:
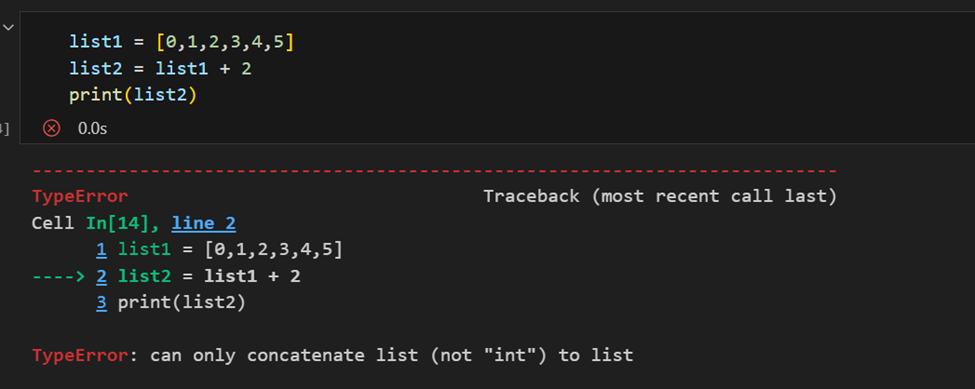
Diferencia entre arreglo NumPy y lista de Python
La diferencia clave entre un arreglo y una lista es que los arreglos están diseñados para manejar operaciones vectorizadas, mientras que una lista de Python no lo está. Esto significa que si aplicas una función, se realiza en cada elemento del arreglo, en lugar de en todo el objeto del arreglo.
Pandas
Pandas se destaca como una de las bibliotecas más potentes para cálculos numéricos y manipulación de datos, lo cual es fundamental para áreas de inteligencia artificial y aprendizaje automático.
Pandas, al igual que NumPy, es una de las bibliotecas de Python más populares. Es una abstracción de alto nivel sobre NumPy de bajo nivel, que está escrito en C puro. Pandas proporciona estructuras de datos de alto rendimiento fáciles de usar y herramientas de análisis de datos. Pandas utiliza dos estructuras principales: data framesy series.
Índices en Series de Pandas
Una serie de Pandas es similar a una lista, pero difiere en que una serie asocia una etiqueta con cada elemento. Esto hace que se asemeje a un diccionario. Si un índice no es proporcionado explícitamente por el usuario, Pandas crea un RangeIndex que va desde 0 hasta N-1. Cada objeto serie también tiene un tipo de datos.
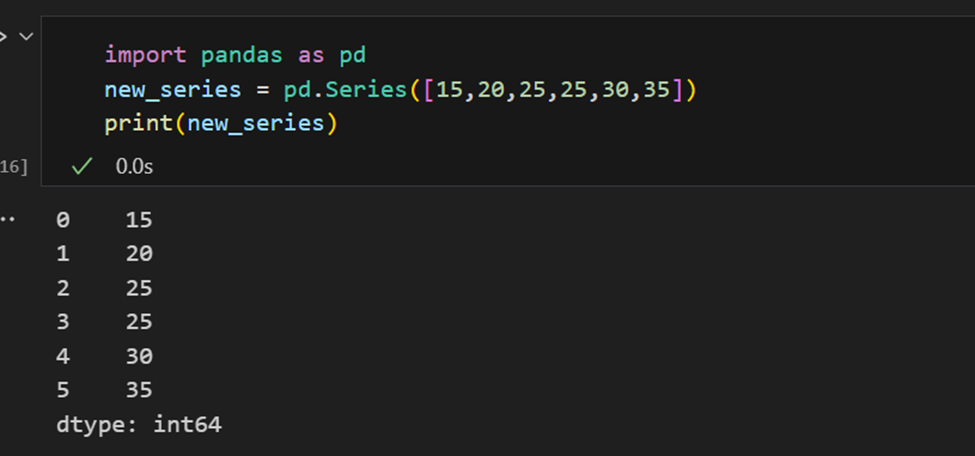
Una serie de Pandas tiene formas de extraer todos los valores de la serie, así como elementos individuales por índice.
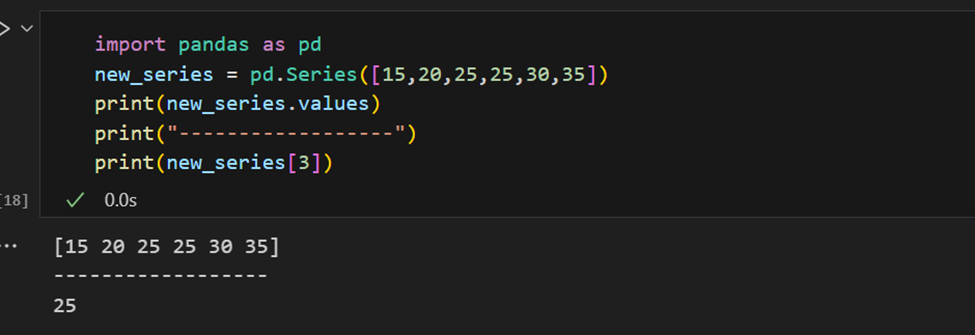
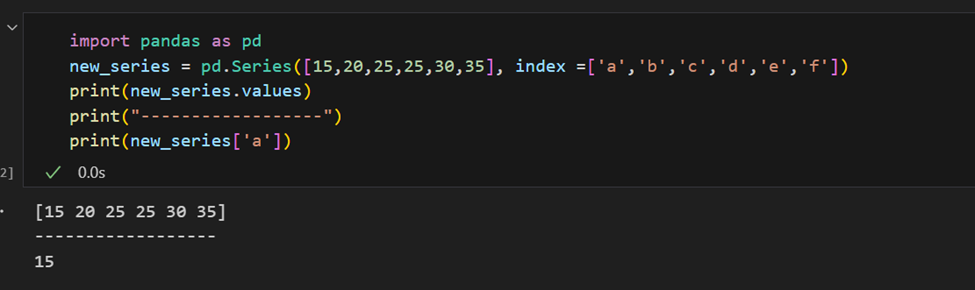
El índice también se puede proporcionar manualmente.
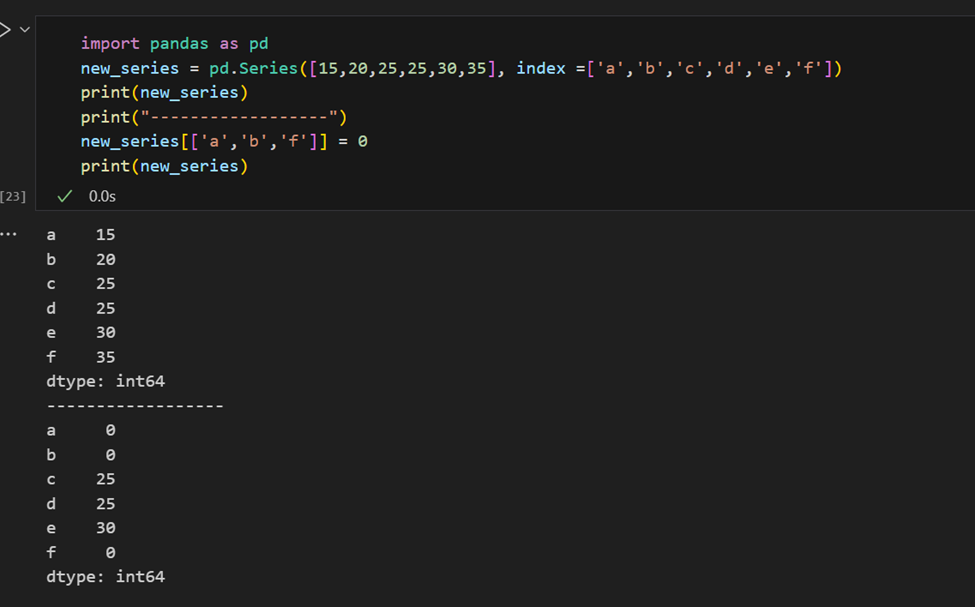
Es fácil recuperar varios elementos de una serie por sus índices o hacer asignaciones grupales.
DataFrames de Pandas
Un DataFrame es una tabla con filas y columnas. Cada columna en un marco de datos es un objeto de serie. Las filas consisten en elementos dentro de las series. Los DataFrames de Pandas ofrecen una amplia gama de operaciones para la manipulación y análisis de datos. Aquí hay un desglose de algunas operaciones comunes:
Operaciones Básicas
Creando DataFrames
- Desde un diccionario:
pd.DataFrame({'col1': [1, 2], 'col2': [3, 4]}) - Desde un archivo CSV:
pd.read_csv('data.csv') - Desde un archivo de Excel:
pd.read_excel('data.xlsx')
Accediendo a los Datos
- Seleccionando columnas:
df['col1'] - Seleccionando filas:
df.loc[0] (por etiqueta de índice), df.iloc[0](por posición de índice) - Corte:
df [0:2] (primeras dos filas), df[['coll', 'col2']](múltiples columnas)
Agregando y Eliminando Columnas/Filas
- Agregando una columna:
df['new_col'] = - Eliminando una columna:
df.drop('coll', axis=1) - Agregando una fila:
df.append({'col1': 7, 'col2': 8}, ignore_index=True) - Eliminando una fila:
df.drop(0)
Filtrado de Datos
- Usando condiciones booleanas:
df [df['col1'] > 2]
Operaciones Matemáticas
- Operaciones aritméticas:
df['col1'] + df['col2'],df * 2, etc. - Funciones de Agregación:
df.sum(),df.mean(),df.max(),df.min(), etc. - Aplicando funciones personalizadas:
df.apply(lambda x: x**2)
Manejo de Datos Faltantes
- Comprobando valores faltantes:
df.isnull() - Eliminando valores faltantes:
df.dropna() - Rellenando valores faltantes:
df.fillna(0)
Combinando y Uniendo DataFrames
- Combinando:
pd.merge(df1, df2, on='key_column') - Uniéndolos:
df1.join(df2, on='key_column')
Agrupando y Agregando
- Agrupando:
df.groupby('col1') - Agregando:
df.groupby('col1').mean()
Operaciones de Series Temporales
- Remuestreo:
df.resample('D').sum()(reducir a frecuencia diaria) - Desplazamiento temporal:
df.shift(1)(desplazar los datos por un período)
Visualización de Datos
Gráficos: df.plot() (gráfico de líneas), df.hist() (histograma), etc.
Ejemplos Complejos de Pandas
1. Aquí tenemos datos de ventas indexados por región y año. Ahora, calculamos el cambio porcentual en las ventas por región.
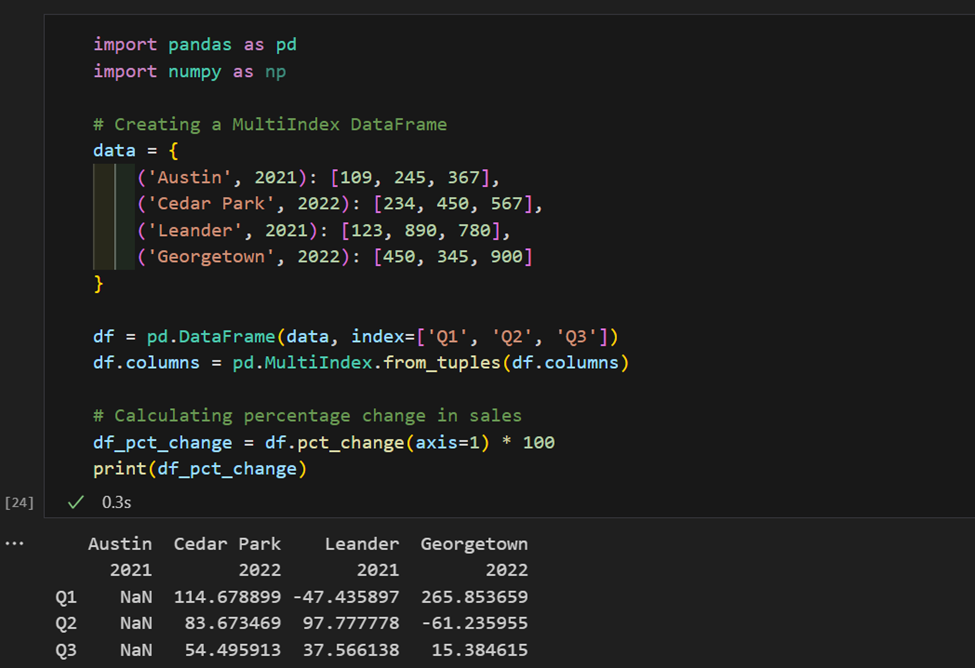
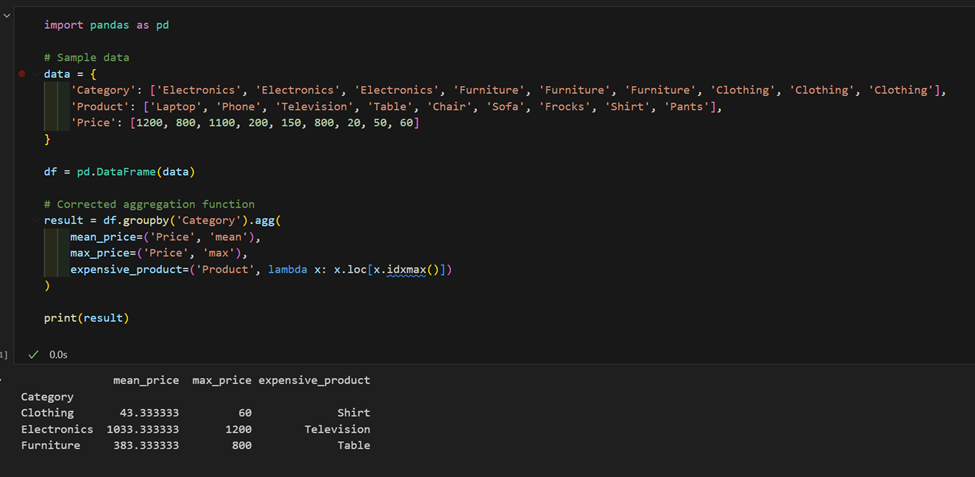
2. Tenemos un conjunto de datos con productos y precios, calculamos el precio promedio por categoría y encontramos el producto más caro en cada una.
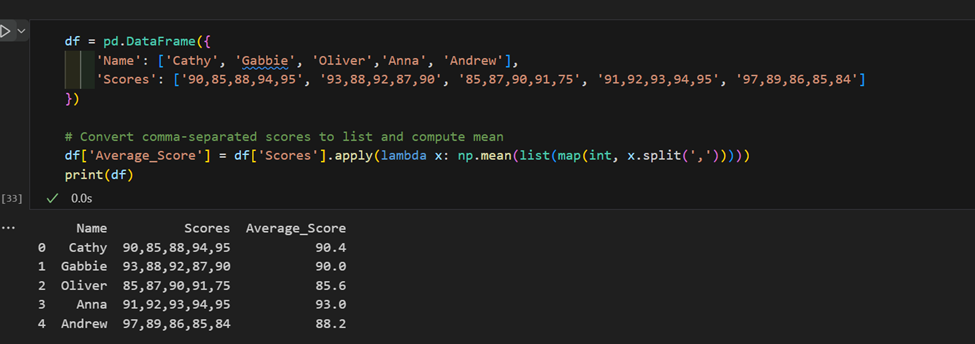
3. Uso complejo de “apply”:
Conclusión
Estas dos bibliotecas, NumPy y Pandas, son ampliamente utilizadas en aplicaciones de la vida real como BFSI (análisis financiero), computación científica, IA y ML, y procesamiento de big data. Estas dos bibliotecas desempeñan un papel crucial en la toma de decisiones basada en datos, desde analizar tendencias críticas del mercado de valores hasta gestionar datos empresariales de ERP a gran escala.
Para principiantes, el siguiente paso es practicar el uso de NumPy y Pandas trabajando en proyectos pequeños, explorando conjuntos de datos y aplicando sus funciones en escenarios del mundo real. Se puede descargar datos de código abierto de GitHub sobre datos financieros, inmobiliarios o de negocios de fabricación general. Con esos datos fuente y estas bibliotecas, se puede crear una historia convincente o un análisis empírico. La experiencia práctica ayudará a solidificar conceptos y preparar a los estudiantes para tareas más avanzadas de ciencia de datos.
En conclusión, tanto NumPy como Pandas son dos bibliotecas de Python esenciales para la manipulación y análisis de datos. Aquí, NumPy proporciona un soporte potente para cálculos numéricos con sus operaciones eficientes de matrices, mientras que Pandas se basa en NumPy para ofrecer estructuras de datos intrínsecas e intuitivas como Series y DataFrame para manipular datos estructurados.
Source:
https://dzone.com/articles/python-libraries-introduction-numpy-pandas