













介紹
機器學習是人工智慧(AI)的一個子領域。機器學習的一般目標是理解數據的結構,並將該數據擬合到可被人理解和利用的模型中。
儘管機器學習是計算機科學的一個領域,但它與傳統的計算方法有所不同。在傳統計算中,算法是計算機使用的一組明確編程的指令,用於計算或解決問題。相反,機器學習算法允許計算機對數據輸入進行訓練,並使用統計分析來輸出落在特定範圍內的值。因此,機器學習使計算機能夠根據樣本數據建立模型,以自動化基於數據輸入的決策過程。
今天的任何技術用戶都受益於機器學習。人臉識別技術使社交媒體平台能夠幫助用戶標記和分享朋友的照片。光學字符識別(OCR)技術將文字圖像轉換為可移動類型。由機器學習驅動的推薦引擎根據用戶的喜好建議下一部要觀看的電影或電視節目。依賴機器學習進行導航的自動駕駛汽車可能很快就會面向消費者。
機器學習是一個不斷發展的領域。因此,在使用機器學習方法或分析機器學習過程的影響時,需要考慮一些問題。
在這個教程中,我們將探討監督學習和非監督學習這兩種常見的機器學習方法,以及機器學習中常用的算法方法,包括k最近鄰算法、決策樹學習和深度學習。我們將探討在機器學習中最常用的編程語言,並提供每種語言的一些優點和缺點。此外,我們還將討論機器學習算法所固有的偏見,並考慮在構建算法時應該牢記的一些事項,以防止這些偏見。
機器學習方法
在機器學習中,任務通常被分為廣泛的類別。這些類別是基於學習方式或反饋給開發系統的學習方式。
兩種最廣泛使用的機器學習方法是監督學習,它根據人類標記的示例輸入和輸出數據來訓練算法,以及非監督學習,它提供了沒有標記數據的算法,以使其能夠在輸入數據中找到結構。讓我們更詳細地探討這些方法。
監督式學習
在監督式學習中,計算機被提供了帶有所需輸出的示例輸入。此方法的目的是通過比較其實際輸出與“教授”的輸出以查找錯誤並相應地修改模型來“學習”算法。因此,監督式學習使用模式來預測額外未標記數據上的標籤值。
例如,使用監督式學習,算法可能被餵入標有魚的鯊魚圖像數據和標有水的海洋圖像數據。通過在此數據上進行訓練,監督式學習算法應該能夠稍後將未標記的鯊魚圖像識別為魚,未標記的海洋圖像識別為水。
A common use case of supervised learning is to use historical data to predict statistically likely future events. It may use historical stock market information to anticipate upcoming fluctuations, or be employed to filter out spam emails. In supervised learning, tagged photos of dogs can be used as input data to classify untagged photos of dogs.
非監督式學習
在非監督式學習中,數據是未標記的,因此學習算法被留給找出其輸入數據的共同特點。由於未標記數據比標記數據更豐富,因此促進非監督式學習的機器學習方法尤其有價值。
無監督學習的目標可能僅僅是在數據集中發現隱藏的模式,但它也可能具有特徵學習的目標,這使得計算機可以自動發現分類原始數據所需的表示。
無監督學習通常用於交易數據。您可能有一個包括客戶及其購買的大型數據集,但作為人類,您可能無法理解從客戶檔案和其購買類型中可以獲得哪些相似屬性。將此數據提供給無監督學習算法後,可以確定特定年齡段的女性購買無香皂的可能是懷孕,因此可以針對這個目標群體進行與懷孕和嬰兒產品相關的營銷活動,以增加其購買量。
在沒有告知“正確”答案的情況下,無監督學習方法可以查看更廣泛且看似不相關的複雜數據,以潛在意義的方式將其組織起來。無監督學習通常用於異常檢測,包括欺詐信用卡交易以及推薦系統推薦下一步該購買什麼產品。在無監督學習中,未標記的狗照片可以作為輸入數據,供算法找出相似之處並將狗照片分類在一起。
方法
作為一個領域,機器學習與計算統計密切相關,因此具備統計學知識對於理解和利用機器學習算法是有用的。
對於那些可能沒有學過統計學的人來說,首先定義相關性和回歸可能是有幫助的,因為它們是用於研究量化變數之間關係的常用技術。相關性是衡量兩個未被指定為依賴或獨立的變數之間關聯的一種方法。回歸在基本層面上用於檢查一個依賴變數和一個獨立變數之間的關係。因為回歸統計可以用於當獨立變數已知時預測依賴變數,所以回歸能夠進行預測。
機器學習的方法不斷發展。就我們的目的而言,我們將介紹一些在撰寫時正在使用的熱門方法。
k-nearest neighbor
k最近鄰算法是一種可以用於分類和回歸的模式識別模型。通常縮寫為k-NN,k-最近鄰中的k是一個正整數,通常很小。在分類或回歸中,輸入將包括空間內的k個最接近的訓練示例。
我們將專注於k-NN分類。在這種方法中,輸出是類別成員資格。這將把一個新對象分配給其k個最近鄰中最常見的類別。在k = 1的情況下,將對象分配給單個最近鄰的類別。
讓我們看一個 k-最近鄰的例子。在下面的圖表中,有藍色的菱形物件和橘色的星形物件。這些屬於兩個不同的類別:菱形類和星形類。

當一個新物件被添加到空間中 – 在這個例子中是一個綠色的心形 – 我們希望機器學習算法將心形分類到某一類。

當我們選擇 k = 3 時,該算法將找到綠色心形的三個最近鄰,以便將其分類為菱形類或星形類。
在我們的圖表中,綠色心形的三個最近鄰是一個菱形和兩個星形。因此,該算法將以星形類來分類心形。
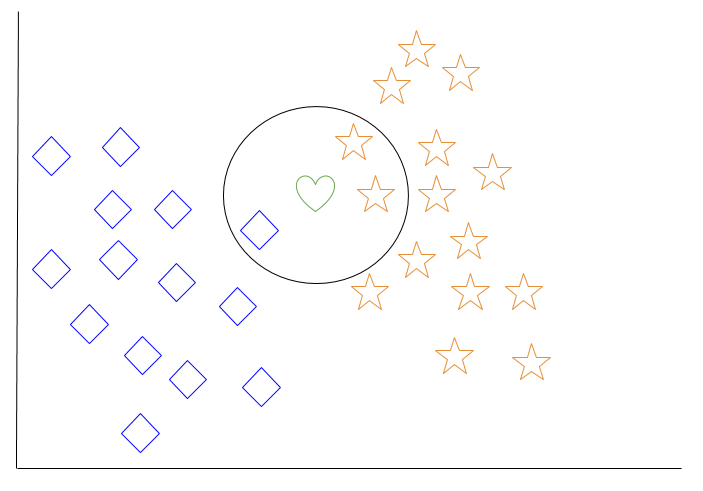
在機器學習算法中,k-最近鄰被認為是一種“懶惰學習”,因為在對系統進行查詢之前,不會超出訓練數據的泛化。
決策樹學習
在一般用途中,決策樹用於直觀表示決策並顯示或通知決策製定。在機器學習和數據挖掘中,決策樹被用作預測模型。這些模型將有關數據的觀察映射到有關數據目標值的結論。
決策樹學習的目標是創建一個模型,該模型將根據輸入變量預測目標的值。
在預測模型中,通過觀察確定的數據屬性由分支表示,而關於數據目標值的結論則表示在葉子中。
在“學習”樹時,源數據根據屬性值測試被劃分為子集,並在每個派生子集上遞歸地重複進行該測試。一旦節點上的子集具有與其目標值相等的值,遞歸過程將完成。
讓我們來看一個關於各種條件的例子,這些條件可以決定某人是否應該去釣魚。這包括天氣條件以及氣壓條件。
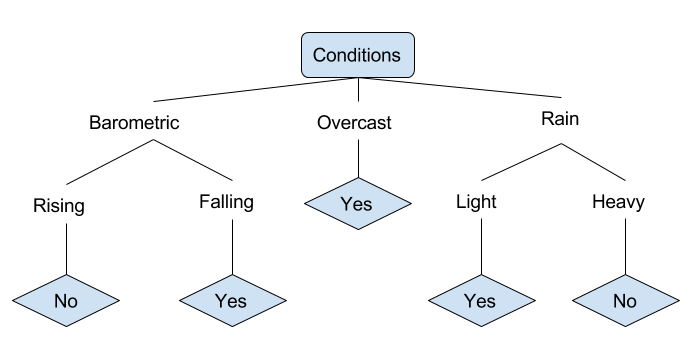
在上面簡化的決策樹中,通過將示例通過樹分類到適當的葉子節點來進行分類。然後返回與特定葉子相關聯的分類,這在這種情況下可能是是或否。該樹根據一天的條件是否適合去釣魚來對其進行分類。
A true classification tree data set would have a lot more features than what is outlined above, but relationships should be straightforward to determine. When working with decision tree learning, several determinations need to be made, including what features to choose, what conditions to use for splitting, and understanding when the decision tree has reached a clear ending.
深度學習
深度學習試圖模仿人類大腦如何將光和聲音刺激轉化為視覺和聽覺。深度學習架構受生物神經網絡的啟發,由硬件和GPU組成的人工神經網絡具有多個層次。
深度學習使用一系列非線性處理單元層,以提取或轉換數據的特徵(或表示)。一層的輸出作為後續層的輸入。在深度學習中,算法可以是監督的,用於分類數據,也可以是無監督的,用於執行模式分析。
在當前使用和開發的機器學習算法中,深度學習吸收了大多數數據,並且在一些認知任務中已經能夠超越人類。由於這些特性,深度學習已成為人工智能領域具有重大潛力的一種方法。
從深度學習方法中,計算機視覺和語音識別都取得了顯著進展。IBM Watson是一個利用深度學習的系統的著名例子。
編程語言
在選擇專攻機器學習的語言時,您可能希望考慮當前工作廣告中列出的技能,以及各種語言中可用於機器學習流程的庫。
Python是最受歡迎的語言之一,用於機器學習,因為有許多可用的框架,包括TensorFlow、PyTorch和Keras。作為一種具有可讀性語法並且能夠用作腳本語言的語言,Python證明了在預處理數據和直接處理數據方面都是強大且直觀的。scikit-learn機器學習庫是建立在幾個現有的Python包之上的,這些Python開發人員可能已經熟悉,即NumPy、SciPy和Matplotlib。
要開始使用Python,您可以閱讀我們的教程系列“如何在Python 3中編碼”,或者專門閱讀“如何使用scikit-learn在Python中構建機器學習分類器”或“如何在Python 3和PyTorch中執行神經風格轉移”。
Java廣泛應用於企業編程,通常由同時從事機器學習企業級前端桌面應用程序開發的開發人員使用。通常不是新手程序員想要學習機器學習的首選,但是對於具有Java開發背景的人來說,將其應用於機器學習是受青睞的。在工業機器學習應用方面,Java通常比Python更多地用於網絡安全,包括在網絡攻擊和欺詐檢測等用例中。
Java的機器學習庫包括Deeplearning4j,一個為Java和Scala編寫的開源和分佈式深度學習庫;MALLET(MAchine Learning for LanguagE Toolkit)可用於文本的機器學習應用,包括自然語言處理、主題建模、文檔分類和聚類;以及Weka,一系列用於數據挖掘任務的機器學習算法。
C++ is the language of choice for machine learning and artificial intelligence in game or robot applications (including robot locomotion). Embedded computing hardware developers and electronics engineers are more likely to favor C++ or C in machine learning applications due to their proficiency and level of control in the language. Some machine learning libraries you can use with C++ include the scalable mlpack, Dlib offering wide-ranging machine learning algorithms, and the modular and open-source Shark.
人類偏見
雖然數據和計算分析可能讓我們認為我們正在接收客觀信息,但事實並非如此;基於數據並不意味著機器學習的輸出是中立的。人類偏見在數據收集、整理方面發揮作用,最終影響了決定機器學習如何與該數據互動的算法。
例如,如果人們將“魚”作為訓練算法的數據提供圖像,而這些人壓倒性地選擇了金魚的圖像,計算機可能不會將鯊魚歸類為魚。這將導致對鯊魚作為魚的偏見,而鯊魚將不被計算為魚。
當使用歷史照片作為科學家的訓練數據時,計算機可能無法正確分類也是有色人種或女性的科學家。事實上,最近的同行評審研究表明,人工智能和機器學習程序展示了與種族和性別偏見相似的人類偏見。例如,參見“從語料庫中自動推導出的語義包含類人的偏見”和“男人也喜歡購物:使用語料庫級別約束減少性別偏見放大”[PDF]。
隨著機器學習在商業中的應用越來越廣泛,未被發現的偏見可能會使系統性問題得以持續,這可能會阻礙人們獲得貸款的資格,不會被展示高薪工作機會的廣告,或者無法獲得當天送達的選擇。
因為人類的偏見可能會對其他人產生負面影響,所以非常重要的是意識到這一點,並且努力盡可能地消除它。朝著這個目標努力的一種方式是確保有多樣化的人參與項目,並且多樣化的人進行測試和審查。其他人呼籲規範性第三方監督和審核算法,構建可以檢測偏見的替代系統,以及倫理審查作為數據科學項目規劃的一部分。提高對偏見的認識,注意我們自己的無意識偏見,並在我們的機器學習項目和流程中結構性地推動公平性,可以有助於在這個領域打擊偏見。

結論
本教程回顧了機器學習的一些用例,該領域使用的常見方法和流行方法,適合的機器學習編程語言,並且還涵蓋了在算法中複製無意識偏見方面需要注意的一些事項。
由於機器學習是一個不斷創新的領域,重要的是要記住算法、方法和途徑將繼續變化。
除了閱讀我們的教程《如何使用scikit-learn在Python中構建機器學習分類器》或《如何使用Python 3和PyTorch執行神經風格轉移》,您還可以通過閱讀我們的 數據分析 教程來了解更多有關在科技行業中處理數據的知識。
Source:
https://www.digitalocean.com/community/tutorials/an-introduction-to-machine-learning