













在我先前關於強調新興趨勢的數據架構的文章中已討論過,數據處理是現代數據架構中的關鍵組件之一。本文討論了在您的數據架構中為了更好的性能而提供的Pandas庫的各種替代方案。
數據處理和數據分析是數據科學和數據工程領域中至關重要的任務。隨著數據集變得越來越大和複雜,傳統工具如pandas在性能和可擴展性方面可能會遇到困難。這促使了多個替代庫的開發,每個都旨在應對數據操作和分析中的具體挑戰。
介紹
以下庫已經成為強大的數據處理工具:
- Pandas – Python中數據操控的傳統工具
- Dask – 擴展pandas以進行大規模、分佈式數據處理
- DuckDB – 用於快速SQL查詢的進程內分析數據庫
- Modin – 具有改進性能的pandas可替代方案
- Polars – 一個建立在 Rust 上的高性能 DataFrame 函式庫
- FireDucks – 一個編譯器加速的 pandas 替代方案
- Datatable – 用於資料操作的高性能函式庫
這些函式庫各自提供獨特的功能和優勢,滿足不同的用例和性能需求。讓我們詳細探索每一個:
Pandas
Pandas 是數據科學社區中一個多才多藝且成熟的函式庫。它提供強大的資料結構(DataFrame 和 Series)和全面的工具進行資料清理和轉換。Pandas 擅長於資料探索和可視化,具有豐富的文檔和社區支持。
然而,它在處理大型數據集時會面臨性能問題,僅限於單線程操作,並且對於大型數據集可能存在較高的內存使用率。Pandas 適用於小到中等大小的數據集(最多幾 GB)以及需要進行大量數據操作和分析的情況。
Dask
Dask 擴展了 pandas 以進行大規模數據處理,提供跨多個 CPU 核心或集群的並行計算和用於大於可用 RAM 的數據集的外部計算。它將 pandas 操作擴展到大數據,並與 PyData 生態系統很好地集成。
然而,Dask 只支持 pandas API 的子集,並且在設置和優化分佈式計算方面可能會變得復雜。它最適用於處理無法放入內存或需要分佈式計算資源的極大數據集。
import dask.dataframe as dd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Dask benchmark
start_time = time.time()
df_dask = dd.from_pandas(df_pandas, npartitions=4)
result_dask = df_dask.groupby('A').sum()
dask_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Dask time: {dask_time:.4f} seconds")
print(f"Speedup: {pandas_time / dask_time:.2f}x")
為了獲得更好的性能,使用 Dask 載入數據時,應該使用
dd.from_dict(data, npartitions=4代替 Pandas dataframedd.from_pandas(df_pandas, npartitions=4)
輸出
Pandas time: 0.0838 seconds
Dask time: 0.0213 seconds
Speedup: 3.93x
DuckDB
DuckDB 是一個處理內部分析數據庫,它使用列矢量化查詢引擎提供快速的分析查詢。它支持帶有額外功能的 SQL,並且沒有外部依賴性,使得設置變得簡單。DuckDB 為分析查詢提供卓越的性能,並且易於與 Python 和其他語言集成。
然而,它不適用於高交易量工作負載,並且具有有限的並發選項。DuckDB 在分析工作負載中表現出色,尤其是在偏好 SQL 查詢時。
import duckdb
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
df = pd.DataFrame(data)
# Pandas benchmark
start_time = time.time()
result_pandas = df.groupby('A').sum()
pandas_time = time.time() - start_time
# DuckDB benchmark
start_time = time.time()
duckdb_conn = duckdb.connect(':memory:')
duckdb_conn.register('df', df)
result_duckdb = duckdb_conn.execute("SELECT A, SUM(B) FROM df GROUP BY A").fetchdf()
duckdb_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"DuckDB time: {duckdb_time:.4f} seconds")
print(f"Speedup: {pandas_time / duckdb_time:.2f}x")
輸出
Pandas time: 0.0898
seconds DuckDB time: 0.1698
seconds Speedup: 0.53x
Modin
Modin旨在成為pandas的即插即用替代方案,利用多個CPU核心以加快執行速度,並在分散系統中擴展pandas操作。採用Modin需要最少的程式碼更改,並具有在多核系統上實現顯著速度提升的潛力。
然而,在某些情況下,Modin在性能上可能有限的提升,並且仍在積極開發中。最適合希望加快現有pandas工作流程而不進行重大程式碼更改的用戶。
import modin.pandas as mpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Modin benchmark
start_time = time.time()
df_modin = mpd.DataFrame(data)
result_modin = df_modin.groupby('A').sum()
modin_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Modin time: {modin_time:.4f} seconds")
print(f"Speedup: {pandas_time / modin_time:.2f}x")
輸出
Pandas time: 0.1186
seconds Modin time: 0.1036
seconds Speedup: 1.14x
Polars
Polars是一個基於Rust構建的高性能DataFrame庫,具有高效的列式內存布局和用於優化查詢計劃的惰性評估API。它為數據處理任務提供卓越的速度和處理大型數據集的擴展能力。
然而,Polars與pandas具有不同的API,需要一些學習,並且可能在處理極大型數據集(超過100 GB)時遇到困難。它非常適合處理中型到大型數據集的數據科學家和工程師,他們將性能放在首位。
import polars as pl
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Polars benchmark
start_time = time.time()
df_polars = pl.DataFrame(data)
result_polars = df_polars.group_by('A').sum()
polars_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Polars time: {polars_time:.4f} seconds")
print(f"Speedup: {pandas_time / polars_time:.2f}x")
輸出
Pandas time: 0.1279 seconds
Polars time: 0.0172 seconds
Speedup: 7.45x
FireDucks
FireDucks完全兼容pandas API,支持多線程執行,並具有用於有效數據流優化的惰性執行。它具有運行時編譯器,優化程式碼執行,比pandas提供顯著的性能改進。FireDucks通過其與pandas API的兼容性和數據操作的自動優化,實現了易於採用。
然而,它相對較新,可能缺乏社區支持並且文檔資料比起更成熟的庫有限。
import fireducks.pandas as fpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# FireDucks benchmark
start_time = time.time()
df_fireducks = fpd.DataFrame(data)
result_fireducks = df_fireducks.groupby('A').sum()
fireducks_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"FireDucks time: {fireducks_time:.4f} seconds")
print(f"Speedup: {pandas_time / fireducks_time:.2f}x")
輸出
Pandas time: 0.0754 seconds
FireDucks time: 0.0033 seconds
Speedup: 23.14x
資料表
資料表是一個高性能的數據操作庫,具有基於列的數據存儲、所有數據類型的本地C實現以及多線程數據處理功能。它在數據處理任務中提供了卓越的速度,高效的內存使用,並且設計用於處理大型數據集(高達100GB)。資料表的API類似於R的data.table。
然而,與pandas相比,它的文檔資料較少,功能也較少,並且不支持Windows。資料表非常適合在單台機器上處理大型數據集,特別是在速度至關重要時。
import datatable as dt
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Datatable benchmark
start_time = time.time()
df_dt = dt.Frame(data)
result_dt = df_dt[:, dt.sum(dt.f.B), dt.by(dt.f.A)]
datatable_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Datatable time: {datatable_time:.4f} seconds")
print(f"Speedup: {pandas_time / datatable_time:.2f}x")
輸出
Pandas time: 0.1608 seconds
Datatable time: 0.0749 seconds
Speedup: 2.15x
性能比較
資料表在涉及大規模數據處理的場景中表現出色,為排序、分組和數據加載等操作提供了顯著的性能改進。其多線程處理能力使其特別適合利用現代多核處理器
結論
總結來說,庫的選擇取決於數據集大小、性能需求和特定用例等因素。雖然 pandas 對於較小的數據集仍然具有多功能性,但像 Dask 和 FireDucks 的替代方案則為大規模數據處理提供了強大的解決方案。DuckDB 在分析查詢中表現出色,Polars 為中型數據集提供高性能,而 Modin 旨在以最少的代碼變更擴展 pandas 的操作。
下方的條形圖顯示了各庫的性能,以 DataFrame 作為比較。數據已進行正規化以顯示百分比。
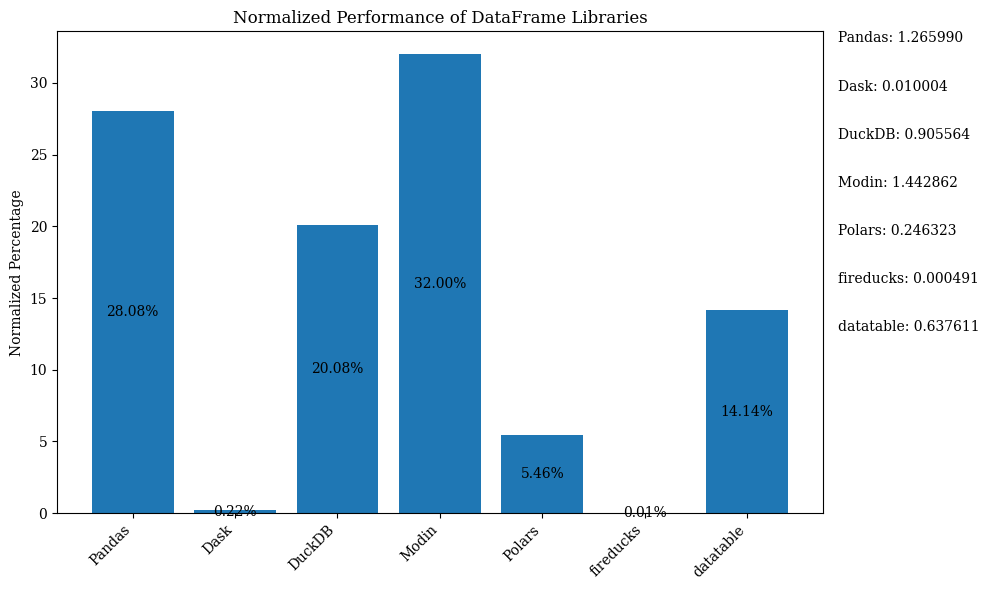
有關顯示上述條形圖的 Python 代碼,請參考 Jupyter Notebook。使用 Google Colab,因為 FireDucks 僅在 Linux 上可用。
比較圖表
| Library | Performance | Scalability | API Similarity to Pandas | Best Use Case | Key Strengths | Limitations |
|---|---|---|---|---|---|---|
| Pandas | 中等 | 低 | N/A(原始) | 小型到中型數據集,數據探索 | 多功能性,豐富的生態系統 | 在大型數據集上速度較慢,單線程 |
| Dask | 高 | 非常高 | 高 | 大型數據集,分佈式計算 | 擴展 pandas 操作,分佈式處理 | 複雜的設置,部分支持 pandas API |
| DuckDB | 非常高 | 中等 | 低 | 分析查詢,基於 SQL 的分析 | 快速的SQL查詢,易於整合 | 不適用於交易型工作負載,並發性有限 |
| Modin | 非常高 | 高 | 非常高 | 加速現有的pandas工作流程 | 易於採用,多核心利用 | 某些情況下改進有限 |
| Polars | 非常高 | 高 | 中等 | 中到大型數據集,性能關鍵 | 速度快,現代API | 學習曲線,處理非常大型數據有困難 |
| FireDucks | 非常高 | 高 | 非常高 | 大型數據集,具有性能的pandas風格API | 自動優化,pandas兼容性 | 更新的庫,社區支持較少 |
| Datatable | 非常高 | 高 | 中等 | 單機上的大型數據集 | 快速處理,高效利用內存 | 功能有限,不支持Windows |
這個表格提供了每個庫的優勢、限制和最佳使用案例的快速概覽,便於在性能、可擴展性和API與pandas的相似性等不同方面進行比較。
Source:
https://dzone.com/articles/modern-data-processing-libraries-beyond-pandas