













LLMs透過自然語言處理(NLP)將文本的意義表示為向量,這種文本單詞的表示形式即為嵌入。
令牌限制:LLM提示的最大問題
目前,LLM提示面臨的最大問題之一是令牌限制。GPT-3推出時,提示與輸出的總令牌限制為2,048個。到了GPT-3.5,這一限制提升至4,096個令牌。如今,GPT-4提供兩種版本,一種限制為8,192個令牌,另一種則為32,768個令牌,約相當於50頁文本。
那麼,當您需要處理的上下文超過此限制時,該如何是好?當然,唯一的解決方案是縮短上下文。但如何在縮短的同時保留所有相關信息呢?解決之道:將上下文存儲於向量數據庫中,並通過相似性搜索查詢找到相關上下文。
向量嵌入是什麼?
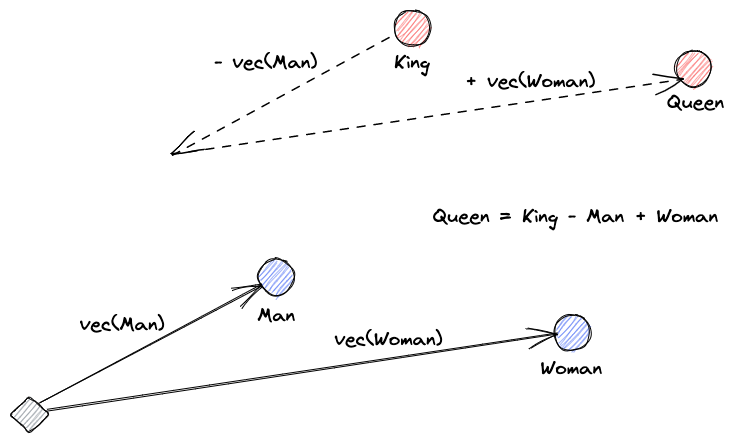
首先,讓我們解釋向量嵌入的概念。Roy Keynes的定義是:“嵌入是學習到的轉換,使數據更具實用性。”神經網絡學會將文本轉換為包含其實際意義的向量空間。這更具實用性,因為它能夠找到同義詞以及單詞間的語法和語義關係。以下圖解有助於我們理解這些向量如何編碼意義:
向量數據庫的作用是什麼?
A vector database stores and indexes vector embeddings. This is useful for the fast retrieval of vectors and looking for similar vectors.
相似性搜索
透過計算一個向量與所有其他向量之間的距離,我們可以找出向量之間的相似度。最接近的鄰近向量將是與查詢向量最相似的結果。這就是向量資料庫中平面索引的工作原理。但這種方法效率不高;在大型資料庫中,這可能需要很長時間。
為了提升搜尋效能,我們可以嘗試僅計算部分向量的距離。這種方法稱為近似最近鄰(Approximate Nearest Neighbors, ANN),雖然加快了速度,但犧牲了結果的品質。一些流行的ANN索引包括局部敏感哈希(LSH)、分層可導航小世界(HNSW)或倒排文件索引(IVF)。
整合向量儲存與大型語言模型
在此範例中,我從此網址下載了整個Numpy文件(超過2000頁)的PDF。
我們可以編寫Python程式碼,將上下文文件轉換為嵌入並保存到向量儲存中。我們將使用LangChain來載入文件並將其分割成塊,以及使用Faiss(Facebook AI相似性搜尋)作為向量資料庫。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(pages, embeddings)
db.save_local("numpy_faiss_index")現在,我們可以使用這個資料庫來執行相似性搜尋查詢,以找到可能與我們的提示相關的頁面。然後,我們使用這些結果塊來填充我們提示的上下文。我們將使用LangChain使其更簡單:
from langchain.vectorstores import FAISS
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from langchain.llms import OpenAI
query = "How to calculate the median of an array"
db = FAISS.load_local("numpy_faiss_index", embeddings)
docs = docsearch.similarity_search(query)
chain = load_qa_with_sources_chain(OpenAI(temperature=0), chain_type="stuff")
chain({"input_documents": docs, "question": query}, return_only_outputs=True)我們向模型提出的問題是,“如何計算陣列的中位數。”即使我們提供的上下文遠超過令牌限制,我們已經克服了這一限制並得到了答案:
To calculate the median, you can use the numpy.median() function, which takes an input array or object that can be converted to an array and computes the median along the specified axis. The axis parameter specifies the axis or axes along which the medians are computed, and the default is to compute the median along a flattened version of the array. The function returns the median of the array elements.
For example, to calculate the median of an array "arr" along the first axis, you can use the following code:
import numpy as np
median = np.median(arr, axis=0)
This will compute the median of the array elements along the first axis, and return the result in the variable "median".這僅是針對一個極新問題的巧妙解決方案。隨著大型語言模型(LLMs)的不斷進化,或許類似問題將來能夠無需此類巧妙對策便得以解決。但我確信,這種演變將開啟新能力之門,這些新能力可能會帶來新的挑戰,需要其他新的巧妙解決方案。
Source:
https://dzone.com/articles/maximizing-the-potential-of-llms-using-vector-data