













LLMs realizam Processamento de Linguagem Natural (NLP) para representar o significado do texto como um vetor. Essa representação das palavras do texto é uma incorporação.
O Limite de Token: O Maior Problema com o Chamado de LLM
Atualmente, um dos maiores problemas com o chamado de LLM é o limite de token. Quando o GPT-3 foi lançado, o limite para o prompt e a saída combinados era de 2.048 tokens. Com o GPT-3.5, esse limite aumentou para 4.096 tokens. Agora, o GPT-4 vem em duas variantes. Uma com um limite de 8.192 tokens e outra com um limite de 32.768 tokens, cerca de 50 páginas de texto.
Então, o que você pode fazer quando desejar fazer um prompt com um contexto maior que esse limite? Claro, a única solução é tornar o contexto mais curto. Mas como você pode torná-lo mais curto e, ao mesmo tempo, ter todas as informações relevantes? A solução: armazenar o contexto em um banco de dados vetorial e encontrar o contexto relevante com uma consulta de busca de similaridade.
O Que São Incorporações Vetoriais?
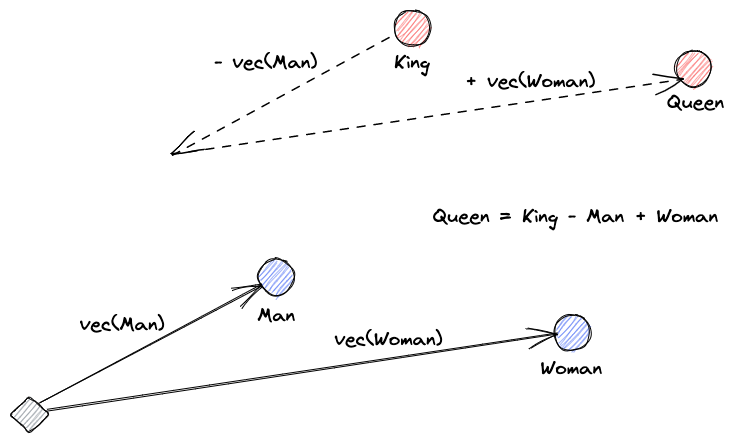
Vamos começar explicando o que são incorporações vetoriais. Definição de Roy Keynes é: “Incorporações são transformações aprendidas para tornar os dados mais úteis.” Uma rede neural aprende a transformar o texto em um espaço vetorial que contém seu significado real. Isso é mais útil porque pode encontrar sinônimos e as relações sintáticas e semânticas entre palavras. Esse visual nos ajuda a entender como esses vetores podem codificar significado:
O Que Fazem os Bancos de Dados Vetoriais?
A vector database stores and indexes vector embeddings. This is useful for the fast retrieval of vectors and looking for similar vectors.
Pesquisa por Similaridade
Podemos encontrar a similaridade entre vetores calculando a distância de um vetor a todos os outros vetores. Os vizinhos mais próximos serão os resultados mais similares ao vetor de consulta. É assim que funcionam os índices planos em bancos de dados vetoriais. Mas isso não é muito eficiente; em um grande banco de dados, isso pode levar muito tempo.
Para melhorar o desempenho da pesquisa, podemos tentar calcular a distância apenas para um subconjunto dos vetores. Essa abordagem, chamada de vizinhos mais próximos aproximados (ANN), melhora a velocidade, mas sacrifica a qualidade dos resultados. Alguns índices ANN populares são Hashing Sensível Localmente (LSH), Mundos Pequenos Hierarquicamente Navegáveis (HNSW) ou Índice de Arquivo Invertido (IVF).
Integrando Lojas Vetoriais e LLMs
Para este exemplo, baixei a documentação completa do Numpy (com mais de 2000 páginas) como um PDF deste URL.
Podemos escrever código Python para transformar o documento de contexto em embeddings e salvá-los em uma loja vetorial. Usaremos o LangChain para carregar o documento e dividi-lo em partes e o Faiss (Facebook AI Similarity Search) como um banco de dados vetorial.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(pages, embeddings)
db.save_local("numpy_faiss_index")Agora, podemos usar este banco de dados para realizar uma consulta de pesquisa de similaridade para encontrar páginas que possam estar relacionadas ao nosso prompt. Em seguida, usamos as partes resultantes para preencher o contexto do nosso prompt. Usaremos o LangChain para facilitar:
from langchain.vectorstores import FAISS
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from langchain.llms import OpenAI
query = "How to calculate the median of an array"
db = FAISS.load_local("numpy_faiss_index", embeddings)
docs = docsearch.similarity_search(query)
chain = load_qa_with_sources_chain(OpenAI(temperature=0), chain_type="stuff")
chain({"input_documents": docs, "question": query}, return_only_outputs=True)Nossa pergunta para o modelo é: “Como calcular a mediana de um array”. Mesmo que o contexto que estamos fornecendo esteja muito além do limite de tokens, superamos essa limitação e obtivemos uma resposta:
To calculate the median, you can use the numpy.median() function, which takes an input array or object that can be converted to an array and computes the median along the specified axis. The axis parameter specifies the axis or axes along which the medians are computed, and the default is to compute the median along a flattened version of the array. The function returns the median of the array elements.
For example, to calculate the median of an array "arr" along the first axis, you can use the following code:
import numpy as np
median = np.median(arr, axis=0)
This will compute the median of the array elements along the first axis, and return the result in the variable "median".Esta é apenas uma solução inteligente para um problema muito novo. À medida que os LLMs continuam evoluindo, talvez problemas como este possam ser resolvidos sem a necessidade de soluções inteligentes deste tipo. No entanto, tenho certeza de que essa evolução abrirá a porta para novas capacidades que poderão exigir outras soluções inteligentes para os desafios que possam trazer.
Source:
https://dzone.com/articles/maximizing-the-potential-of-llms-using-vector-data