













Los LLMs realizan el Procesamiento del Lenguaje Natural (NLP) para representar el significado del texto como un vector. Esta representación de las palabras del texto es una incrustación.
El Límite de Tokens: El Mayor Problema en el Apretón de Manos de los LLMs
Actualmente, uno de los mayores problemas con el apretón de manos de los LLMs es el límite de tokens. Cuando se lanzó GPT-3, el límite para la solicitud y la salida combinadas era de 2,048 tokens. Con GPT-3.5, este límite aumentó a 4,096 tokens. Ahora, GPT-4 viene en dos variantes. Una con un límite de 8,192 tokens y otra con un límite de 32,768 tokens, aproximadamente 50 páginas de texto.
Entonces, ¿qué puedes hacer cuando quieras hacer una solicitud con un contexto mayor que este límite? Por supuesto, la única solución es hacer el contexto más corto. Pero, ¿cómo puedes hacerlo más corto y al mismo tiempo tener toda la información relevante? La solución: almacenar el contexto en una base de datos de vectores y encontrar el contexto relevante con una consulta de búsqueda de similitud.
¿Qué Son las Incrustaciones de Vectores?
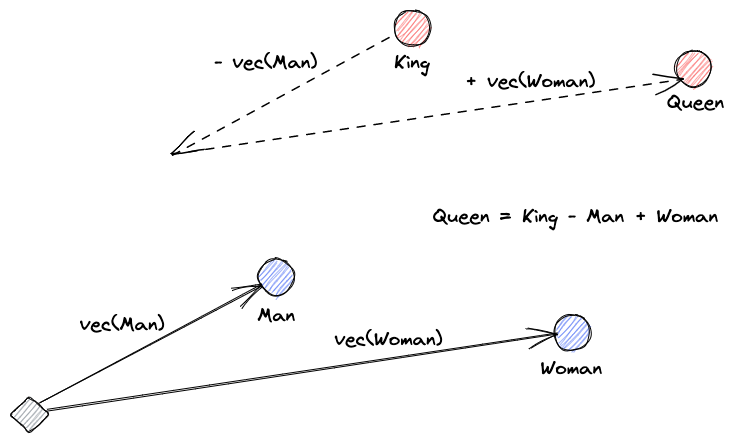
Comencemos explicando qué son las incrustaciones de vectores. La definición de Roy Keynes es: “Las incrustaciones son transformaciones aprendidas para hacer que los datos sean más útiles.” Una red neuronal aprende a transformar el texto en un espacio vectorial que contiene su significado real. Esto es más útil porque puede encontrar sinónimos y las relaciones sintácticas y semánticas entre palabras. Esta visual nos ayuda a entender cómo esos vectores pueden codificar significado:
¿Qué Hacen las Bases de Datos de Vectores?
A vector database stores and indexes vector embeddings. This is useful for the fast retrieval of vectors and looking for similar vectors.
Búsqueda de Similitud
Podemos hallar la similitud de vectores calculando la distancia de un vector a todos los demás vectores. Los vecinos más cercanos serán los resultados más similares al vector de consulta. Así funcionan los índices planos en bases de datos vectoriales. Pero esto no es muy eficiente; en una base de datos grande, esto podría llevar mucho tiempo.
Para mejorar el rendimiento de la búsqueda, podemos intentar calcular la distancia solo para un subconjunto de los vectores. Este enfoque, llamado vecinos más cercanos aproximados (ANN), mejora la velocidad pero sacrifica la calidad de los resultados. Algunos índices ANN populares son Hashing Sensible Localmente (LSH), Small Worlds Navegables Jerárquicos (HNSW) o Índice de Archivo Invertido (IVF).
Integración de Almacenes Vectoriales y LLMs
Para este ejemplo, descargué toda la documentación de Numpy (con más de 2000 páginas) como un PDF desde este URL.
Podemos escribir código Python para transformar el documento de contexto en embeddings y guardarlo en un almacén vectorial. Usaremos LangChain para cargar el documento y dividirlo en trozos, y Faiss (Facebook AI Similarity Search) como base de datos vectorial.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(pages, embeddings)
db.save_local("numpy_faiss_index")Ahora, podemos usar esta base de datos para realizar una consulta de búsqueda de similitud para encontrar páginas que podrían estar relacionadas con nuestro prompt. Luego, usamos los trozos resultantes para llenar el contexto de nuestro prompt. Usaremos LangChain para facilitarlo:
from langchain.vectorstores import FAISS
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from langchain.llms import OpenAI
query = "How to calculate the median of an array"
db = FAISS.load_local("numpy_faiss_index", embeddings)
docs = docsearch.similarity_search(query)
chain = load_qa_with_sources_chain(OpenAI(temperature=0), chain_type="stuff")
chain({"input_documents": docs, "question": query}, return_only_outputs=True)Nuestra pregunta para el modelo es, “¿Cómo calcular la mediana de una matriz?”. A pesar de que el contexto que le damos está muy por encima del límite de tokens, hemos superado esta limitación y obtuvimos una respuesta:
To calculate the median, you can use the numpy.median() function, which takes an input array or object that can be converted to an array and computes the median along the specified axis. The axis parameter specifies the axis or axes along which the medians are computed, and the default is to compute the median along a flattened version of the array. The function returns the median of the array elements.
For example, to calculate the median of an array "arr" along the first axis, you can use the following code:
import numpy as np
median = np.median(arr, axis=0)
This will compute the median of the array elements along the first axis, and return the result in the variable "median".Esta es solo una solución ingeniosa para un problema muy nuevo. A medida que los LLMs continúan evolucionando, tal vez problemas como este se resuelvan sin la necesidad de este tipo de soluciones inteligentes. Sin embargo, estoy seguro de que esta evolución abrirá la puerta a nuevas capacidades que podrían necesitar otras soluciones ingeniosas para los desafíos que puedan plantear.
Source:
https://dzone.com/articles/maximizing-the-potential-of-llms-using-vector-data