













LLMs nutzen die Natursprachverarbeitung (NLP), um die Bedeutung eines Textes als Vektor darzustellen. Diese Darstellung der Wörter des Textes ist eine Einbettung.
Die Token-Begrenzung: Das größte Problem bei LLM-Prompts
Derzeit ist eines der größten Probleme bei LLM-Prompts die Token-Begrenzung. Als GPT-3 veröffentlicht wurde, betrug die Begrenzung sowohl für den Prompt als auch für die Ausgabe zusammen 2.048 Tokens. Bei GPT-3.5 erhöhte sich diese Begrenzung auf 4.096 Tokens. Nun kommt GPT-4 in zwei Varianten. Eine mit einer Begrenzung von 8.192 Tokens und eine andere mit einer Begrenzung von 32.768 Tokens, was ungefähr 50 Seiten Text entspricht.
Also, was kann man tun, wenn man einen Prompt mit einem Kontext größer als diese Begrenzung möchte? Natürlich ist die einzige Lösung, den Kontext kürzer zu gestalten. Aber wie kann man ihn kürzer gestalten und gleichzeitig alle relevanten Informationen behalten? Die Lösung: den Kontext in einer Vektordatenbank speichern und den relevanten Kontext mit einer Ähnlichkeitssuche abfragen.
Was sind Vektoreinbettungen?
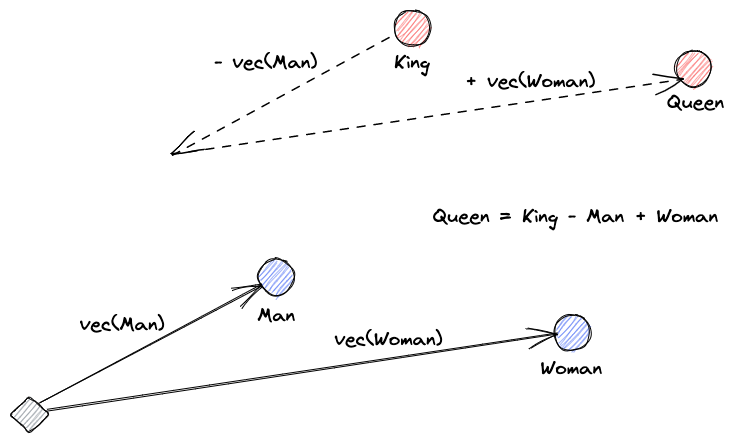
Beginnen wir mit der Erklärung, was Vektoreinbettungen sind. Roy Keynes‘ Definition lautet: „Einbettungen sind gelernte Transformationen, um Daten nützlicher zu machen.“ Ein neuronales Netz lernt, den Text in einen Vektorraum zu transformieren, der seine tatsächliche Bedeutung enthält. Dies ist nützlicher, da es Synonyme finden und die syntaktische und semantische Beziehung zwischen Wörtern erkennen kann. Diese Visualisierung hilft uns zu verstehen, wie diese Vektoren Bedeutung kodieren können:
Was tun Vektordatenbanken?
A vector database stores and indexes vector embeddings. This is useful for the fast retrieval of vectors and looking for similar vectors.
Ähnlichkeitssuche
Wir können die Ähnlichkeit von Vektoren ermitteln, indem wir den Abstand eines Vektors zu allen anderen Vektoren berechnen. Die nächsten Nachbarn werden die am ähnlichsten zu dem Suchvektor sein. So funktionieren flache Indizes in Vektor-Datenbanken. Dies ist jedoch nicht sehr effizient; in einer großen Datenbank kann dies sehr lange dauern.
Um die Suchleistung zu verbessern, können wir versuchen, den Abstand nur für eine Teilmenge der Vektoren zu berechnen. Dieser Ansatz, genannt approximative nächste Nachbarn (ANN), verbessert die Geschwindigkeit, verzichtet aber auf die Qualität der Ergebnisse. Einige beliebte ANN-Indizes sind Lokal Sensitives Hashing (LSH), Hierarchische Navigierbare Kleine Welten (HNSW) oder Inverted File Index (IVF).
Integration von Vektor-Speichern und LLMs
Für dieses Beispiel habe ich die gesamte Numpy-Dokumentation (über 2000 Seiten) als PDF von diesem URL heruntergeladen.
Wir können Python-Code schreiben, um das Kontextdokument in Embeddings zu transformieren und in einem Vektor-Speicher zu speichern. Wir werden LangChain verwenden, um das Dokument zu laden und in Abschnitte zu unterteilen, und Faiss (Facebook AI Similarity Search) als Vektor-Datenbank.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(pages, embeddings)
db.save_local("numpy_faiss_index")Jetzt können wir diese Datenbank verwenden, um eine Ähnlichkeitssuchabfrage durchzuführen, um Seiten zu finden, die möglicherweise mit unserem Prompt verwandt sind. Anschließend verwenden wir die resultierenden Abschnitte, um den Kontext unseres Prompts zu füllen. Wir werden LangChain verwenden, um das zu erleichtern:
from langchain.vectorstores import FAISS
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from langchain.llms import OpenAI
query = "How to calculate the median of an array"
db = FAISS.load_local("numpy_faiss_index", embeddings)
docs = docsearch.similarity_search(query)
chain = load_qa_with_sources_chain(OpenAI(temperature=0), chain_type="stuff")
chain({"input_documents": docs, "question": query}, return_only_outputs=True)Unsere Frage an das Modell lautet: „Wie wird der Median eines Arrays berechnet.“ Obwohl der Kontext, den wir ihm geben, weit über dem Token-Limit liegt, haben wir diese Einschränkung überwunden und eine Antwort erhalten:
To calculate the median, you can use the numpy.median() function, which takes an input array or object that can be converted to an array and computes the median along the specified axis. The axis parameter specifies the axis or axes along which the medians are computed, and the default is to compute the median along a flattened version of the array. The function returns the median of the array elements.
For example, to calculate the median of an array "arr" along the first axis, you can use the following code:
import numpy as np
median = np.median(arr, axis=0)
This will compute the median of the array elements along the first axis, and return the result in the variable "median".Das ist nur eine clevere Lösung für ein ganz neues Problem. Wenn LLMs sich weiterentwickeln, werden vielleicht Probleme wie dieses ohne die Notwendigkeit solcher cleveren Lösungen gelöst werden. Ich bin jedoch sicher, dass diese Evolution neue Möglichkeiten eröffnen wird, die für die Herausforderungen, die sie mit sich bringen könnten, andere neue clevere Lösungen erfordern könnten.
Source:
https://dzone.com/articles/maximizing-the-potential-of-llms-using-vector-data