













LLMs는 자연어 처리(NLP)를 통해 텍스트의 의미를 벡터로 표현합니다. 이렇게 텍스트의 단어들을 표현한 것이 임베딩입니다.
토큰 제한: LLM 프롬프팅의 가장 큰 문제
현재 LLM 프롬프팅의 가장 큰 문제 중 하나는 토큰 제한입니다. GPT-3가 출시될 당시, 프롬프팅과 출력의 합계 토큰 제한은 2,048개였습니다. GPT-3.5에서는 이 제한이 4,096개로 늘어났습니다. 이제 GPT-4는 두 가지 변형으로 나오는데, 하나는 8,192개의 토큰 제한이고 다른 하나는 약 50페이지 분량의 32,768개의 토큰 제한입니다.
이 제한을 초과하는 컨텍스트로 프롬프팅을 하고 싶을 때 어떻게 할 수 있을까요? 당연히 유일한 해결책은 컨텍스트를 더 짧게 만드는 것입니다. 하지만 어떻게 줄이면서 모든 관련 정보를 포함시킬 수 있을까요? 해결책: 컨텍스트를 벡터 데이터베이스에 저장하고 유사도 검색 쿼리로 관련 컨텍스트를 찾습니다.
벡터 임베딩이 무엇인가?
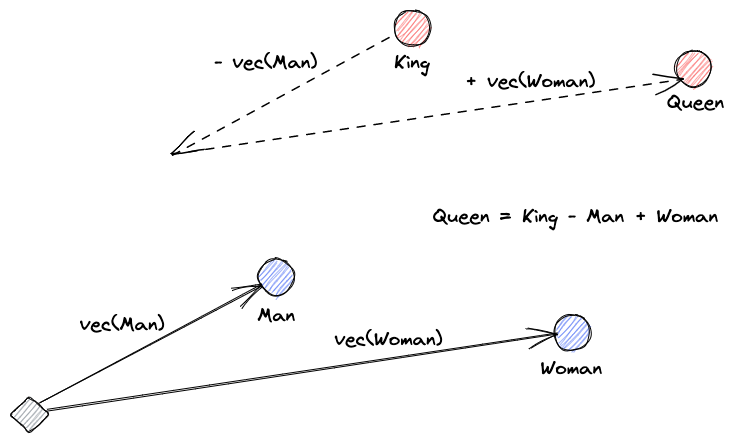
벡터 임베딩이 무엇인지 설명하겠습니다. 로이 키엔스의 정의는: “임베딩은 데이터를 더 유용하게 만들기 위한 학습된 변환이다.” 신경망은 텍스트를 실제 의미를 담고 있는 벡터 공간으로 변환하는 것을 학습합니다. 이 시각적 도움말은 이러한 벡터들이 어떻게 의미를 인코딩할 수 있는지 이해하는 데 도움이 됩니다:
벡터 데이터베이스는 무엇을 하는가?
A vector database stores and indexes vector embeddings. This is useful for the fast retrieval of vectors and looking for similar vectors.
유사도 검색
벡터들 간의 유사성을 찾기 위해 한 벡터와 다른 모든 벡터 간의 거리를 계산할 수 있습니다. 가장 가까운 이웃은 쿼리 벡터와 가장 유사한 결과가 될 것입니다. 이것이 벡터 데이터베이스에서 플랫 인덱스가 작동하는 방식입니다. 그러나 이것은 매우 비효율적입니다; 큰 데이터베이스에서는 이것이 매우 오랜 시간이 걸릴 수 있습니다.
검색 성능을 개선하기 위해 벡터들 중 일부에 대해서만 거리를 계산해볼 수 있습니다. 이러한 접근 방식은 근사 최근접 이웃(ANN)이라고 하며, 속도는 향상시키지만 결과의 품질은 희생합니다. 인기 있는 ANN 인덱스로는 국소적 민감 해싱(LSH), 계층적 탐색 가능한 소용량 세상(HNSW), 또는 역 파일 인덱스(IVF)가 있습니다.
벡터 스토어와 LLMs 통합
이 예제에서는 URL에서 전체 Numpy 문서(2000페이지 이상)를 PDF로 다운로드했습니다.
파이썬 코드를 작성하여 컨텍스트 문서를 임베딩으로 변환하고 벡터 스토어에 저장할 수 있습니다. 문서를 로드하고 청크로 분할하기 위해 LangChain을 사용하고 Faiss(Facebook AI Similarity Search)를 벡터 데이터베이스로 사용할 것입니다.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(pages, embeddings)
db.save_local("numpy_faiss_index")이제 이 데이터베이스를 사용하여 쿼리와 관련된 페이지를 찾기 위해 유사성 검색 쿼리를 수행할 수 있습니다. 그런 다음 결과 청크를 사용하여 우리의 프롬프트 컨텍스트를 채울 수 있습니다. LangChain을 사용하여 이를 더 쉽게 만들 수 있습니다:
from langchain.vectorstores import FAISS
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from langchain.llms import OpenAI
query = "How to calculate the median of an array"
db = FAISS.load_local("numpy_faiss_index", embeddings)
docs = docsearch.similarity_search(query)
chain = load_qa_with_sources_chain(OpenAI(temperature=0), chain_type="stuff")
chain({"input_documents": docs, "question": query}, return_only_outputs=True)모델에 대한 질문은 “어떻게 배열의 중앙값을 계산하나요?”입니다. 주어진 컨텍스트가 토큰 제한을 훨씬 초과하지만, 이 제한을 극복하여 답변을 얻었습니다.
To calculate the median, you can use the numpy.median() function, which takes an input array or object that can be converted to an array and computes the median along the specified axis. The axis parameter specifies the axis or axes along which the medians are computed, and the default is to compute the median along a flattened version of the array. The function returns the median of the array elements.
For example, to calculate the median of an array "arr" along the first axis, you can use the following code:
import numpy as np
median = np.median(arr, axis=0)
This will compute the median of the array elements along the first axis, and return the result in the variable "median".이것은 매우 새로운 문제에 대한 단지 한 가지 현명한 해결책일 뿐입니다. LLM이 계속해서 진화하면서, 아마도 이와 같은 문제들은 이런 종류의 현명한 해결책 없이도 해결될 수 있을 것입니다. 하지만, 이러한 진화가 새로운 능력을 열어 줄 것이며, 그것이 가져올 도전에 대해 다른 새로운 현명한 해결책이 필요해질 것이라는 것을 확신합니다.
Source:
https://dzone.com/articles/maximizing-the-potential-of-llms-using-vector-data