













LLMs используют Natural Language Processing (NLP) для представления смысла текста в виде вектора. Это представление слов текста является встраиванием.
Ограничение Токенов: Самая большая проблема с подсказками LLM
В настоящее время одна из самых больших проблем с подсказками LLM – это ограничение токенов. Когда был выпущен GPT-3, лимит для как подсказки, так и вывода вместе составлял 2048 токенов. С GPT-3.5 этот лимит увеличился до 4096 токенов. Теперь GPT-4 выпускается в двух вариантах. Один с лимитом 8192 токенов и другой с лимитом 32768 токенов, около 50 страниц текста.
Итак, что вы можете сделать, если вам нужно создать подсказку с контекстом больше этого лимита? Конечно, единственное решение – сделать контекст короче. Но как можно сделать его короче, сохраняя при этом все релевантные сведения? Решение: хранить контекст в векторной базе данных и находить релевантный контекст с помощью поиска похожести запроса.
Что Такое Векторные Встраивания?
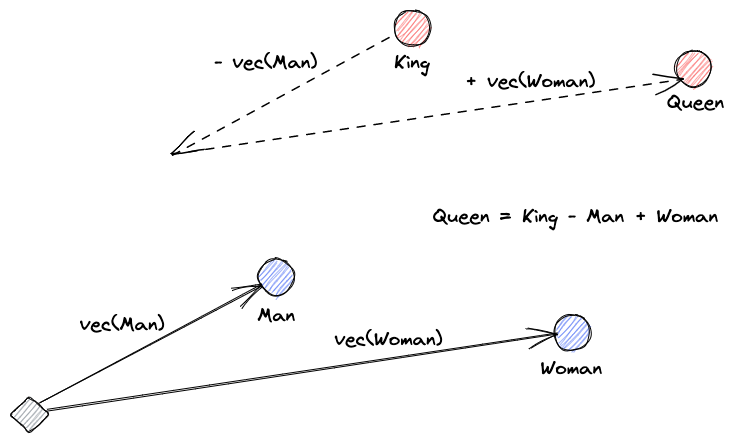
Давайте начнем с объяснения, что такое векторные встраивания. Определение Роя Кейнса гласит: “Встраивания – это обученные преобразования, чтобы сделать данные более полезными.” Нейронная сеть учится преобразовывать текст в векторное пространство, которое содержит его фактический смысл. Это более полезно, поскольку может находить синонимы и синтаксические и семантические отношения между словами. Этот визуальный помогает нам понять, как эти векторы могут кодировать смысл:
Что делают Векторные Базы Данных?
A vector database stores and indexes vector embeddings. This is useful for the fast retrieval of vectors and looking for similar vectors.
Поиск похожести
Мы можем определить сходство векторов, вычислив расстояние вектора от всех других векторов. Ближайшие соседи будут самыми похожими результатами на запрос вектора. Так работают плоские индексы в векторных базах данных. Но это не очень эффективно; в большой базе данных это может занять очень много времени.
Чтобы улучшить производительность поиска, мы можем попытаться вычислить расстояние только для подмножества векторов. Этот подход, называемый приближенными ближайшими соседями (ANN), улучшает скорость, но жертвует качеством результатов. Некоторые популярные индексы ANN – это Локальное Чувствительное Хэширование (LSH), Иерархическая Навигация Малых Миров (HNSW) или Инвертированный Файловый Индекс (IVF).
Интеграция Векторных Магазинов и LLMs
Для этого примера я скачал всю документацию Numpy (с более чем 2000 страниц) в формате PDF по этому URL.
Мы можем написать код на Python, чтобы преобразовать контекстный документ в вложения и сохранить их в векторном магазине. Мы будем использовать LangChain для загрузки документа и разделения его на фрагменты, а Faiss (Facebook AI Similarity Search) в качестве векторной базы данных.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(pages, embeddings)
db.save_local("numpy_faiss_index")Теперь мы можем использовать эту базу данных для выполнения запроса поиска похожести, чтобы найти страницы, которые могут быть связаны с нашим запросом. Затем мы используем полученные фрагменты для заполнения контекста нашего запроса. Мы будем использовать LangChain, чтобы сделать это проще:
from langchain.vectorstores import FAISS
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from langchain.llms import OpenAI
query = "How to calculate the median of an array"
db = FAISS.load_local("numpy_faiss_index", embeddings)
docs = docsearch.similarity_search(query)
chain = load_qa_with_sources_chain(OpenAI(temperature=0), chain_type="stuff")
chain({"input_documents": docs, "question": query}, return_only_outputs=True)Нашей задачей для модели является “Как вычислить медиану массива”. Несмотря на то, что контекст, который мы ей даем, далеко превышает лимит токенов, мы преодолели это ограничение и получили ответ:
To calculate the median, you can use the numpy.median() function, which takes an input array or object that can be converted to an array and computes the median along the specified axis. The axis parameter specifies the axis or axes along which the medians are computed, and the default is to compute the median along a flattened version of the array. The function returns the median of the array elements.
For example, to calculate the median of an array "arr" along the first axis, you can use the following code:
import numpy as np
median = np.median(arr, axis=0)
This will compute the median of the array elements along the first axis, and return the result in the variable "median".Это всего лишь одно остроумное решение для совсем новой проблемы. По мере развития LLMs, возможно, проблемы такого рода будут решаться без необходимости в подобных остроумных решениях. Однако я уверен, что это эволюция откроет дверь для новых возможностей, которые могут потребовать других новых остроумных решений для преодоления вызовов, которые они могут принести.
Source:
https://dzone.com/articles/maximizing-the-potential-of-llms-using-vector-data