













LLMs voeren Natuurlijke Taalverwerking (NLP) uit om de betekenis van de tekst als een vector te representeren. Deze representatie van de woorden in de tekst is een embedding.
Het Tokengrensprobleem: De Grootste Uitdaging bij LLM Prompting
Momenteel is een van de grootste problemen bij LLM prompting de tokengrens. Toen GPT-3 werd uitgebracht, was de limiet voor zowel de prompt als de output gecombineerd 2.048 tokens. Met GPT-3.5 steeg deze limiet naar 4.096 tokens. Nu introduceert GPT-4 twee varianten. Eén met een limiet van 8.192 tokens en een andere met een limiet van 32.768 tokens, ongeveer 50 pagina’s tekst.
Dus, wat kun je doen als je een prompt wilt gebruiken met een context die groter is dan deze limiet? Natuurlijk is de enige oplossing om de context korter te maken. Maar hoe kun je dit doen en tegelijkertijd alle relevante informatie behouden? De oplossing: de context opslaan in een vector database en de relevante context vinden met een similariteitszoekopdracht.
Wat Zijn Vector Embeddings?
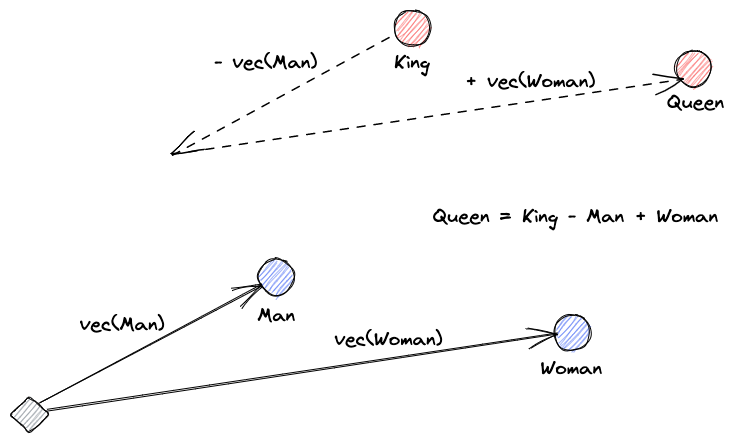
Laten we beginnen met het uitleggen wat vector embeddings zijn. Roy Keynes’ definitie luidt: “Embeddings zijn geleerde transformaties om gegevens nuttiger te maken.” Een neurale netwerk leert de tekst te transformeren in een vectorruimte die de werkelijke betekenis bevat. Dit is nuttiger omdat het synoniemen kan vinden en de syntactische en semantische relaties tussen woorden. Deze afbeelding helpt ons te begrijpen hoe deze vectoren betekenis kunnen coderen:
Wat Doen Vector Databases?
A vector database stores and indexes vector embeddings. This is useful for the fast retrieval of vectors and looking for similar vectors.
Similariteitszoekopdracht
We kunnen de gelijkenis van vectoren bepalen door de afstand van een vector tot alle andere vectoren te berekenen. De dichtstbijzijnde buren zullen de meest vergelijkbare resultaten zijn voor de queryvector. Dit is hoe vlakke indexen in vectordatabases werken. Maar dit is niet erg efficiënt; in een grote database kan dit erg lang duren.
Om de zoekprestaties te verbeteren, kunnen we proberen de afstand alleen voor een subset van de vectoren te berekenen. Deze aanpak, genaamd approximate nearest neighbors (ANN), verbetert de snelheid maar brengt wel een kwaliteitsverlies in de resultaten met zich mee. Enkele populaire ANN-indexen zijn Locally Sensitive Hashing (LSH), Hierarchical Navigable Small Worlds (HNSW), of Inverted File Index (IVF).
Integratie van Vector Stores en LLMs
Voor dit voorbeeld heb ik de volledige Numpy documentatie (met meer dan 2000 pagina’s) als PDF gedownload vanaf deze URL.
We kunnen Python code schrijven om de contextdocumenten om te zetten in embeddings en ze opslaan in een vector store. We zullen LangChain gebruiken om het document te laden en te splitsen in stukjes en Faiss (Facebook AI Similarity Search) als vector database.
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(pages, embeddings)
db.save_local("numpy_faiss_index")Nu kunnen we deze database gebruiken om een gelijkeniszoekopdracht uit te voeren om pagina’s te vinden die wellicht gerelateerd zijn aan onze prompt. Vervolgens gebruiken we de resulterende stukjes om de context van onze prompt te vullen. We zullen LangChain gebruiken om het makkelijker te maken:
from langchain.vectorstores import FAISS
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from langchain.llms import OpenAI
query = "How to calculate the median of an array"
db = FAISS.load_local("numpy_faiss_index", embeddings)
docs = docsearch.similarity_search(query)
chain = load_qa_with_sources_chain(OpenAI(temperature=0), chain_type="stuff")
chain({"input_documents": docs, "question": query}, return_only_outputs=True)Onze vraag aan het model is: “Hoe bereken je de mediaan van een array.” Ondanks dat de context die we het geven veel te groot is voor het tokenlimiet, hebben we deze beperking overwonnen en hebben we een antwoord gekregen:
To calculate the median, you can use the numpy.median() function, which takes an input array or object that can be converted to an array and computes the median along the specified axis. The axis parameter specifies the axis or axes along which the medians are computed, and the default is to compute the median along a flattened version of the array. The function returns the median of the array elements.
For example, to calculate the median of an array "arr" along the first axis, you can use the following code:
import numpy as np
median = np.median(arr, axis=0)
This will compute the median of the array elements along the first axis, and return the result in the variable "median".Dit is slechts één slimme oplossing voor een heel nieuw probleem. Terwijl LLMs zich blijven ontwikkelen, zullen misschien problemen als deze opgelost kunnen worden zonder de noodzaak voor dit soort slimme oplossingen. Toch ben ik ervan overtuigd dat deze evolutie nieuwe mogelijkheden zal openen die andere nieuwe slimme oplossingen kunnen vereisen voor de uitdagingen die ze kunnen meebrengen.
Source:
https://dzone.com/articles/maximizing-the-potential-of-llms-using-vector-data