













正如我之前关于强调新兴趋势的数据架构的文章所讨论的那样,数据处理是现代数据架构中的关键组成部分之一。本文讨论了在数据架构中为了更好的性能而替代Pandas库的各种选择。
数据处理和数据分析是数据科学和数据工程领域中至关重要的任务。随着数据集变得越来越大和复杂,传统工具如pandas在性能和可扩展性方面可能会遇到困难。这导致了几种替代库的开发,每种库都旨在解决数据操作和分析中的特定挑战。
介绍
以下库已经成为强大的数据处理工具:
- Pandas – Python中数据操作的传统得力工具
- Dask – 为大规模、分布式数据处理扩展了pandas
- DuckDB – 用于快速SQL查询的内置分析型数据库
- Modin – 具有改进性能的pandas即插即用替代方案
- Polars – 基于 Rust 的高性能 DataFrame 库
- FireDucks – 作为 pandas 的编译加速替代品
- Datatable – 一个用于数据操控的高性能库
这些库各自提供独特的功能和优势,满足不同的使用场景和性能需求。让我们详细探讨每一个:
Pandas
Pandas 是数据科学社区中一个多功能且成熟的库。它提供强大的数据结构(DataFrame 和 Series)以及全面的数据清理和转换工具。Pandas 在数据探索和可视化方面表现出色,拥有丰富的文档和社区支持。
然而,它在处理大数据集时面临性能问题,局限于单线程操作,并且在处理大数据集时可能会消耗大量内存。Pandas 非常适合小到中等规模的数据集(最多几 GB),以及需要进行广泛数据操作和分析的场景。
Dask
Dask 扩展了 pandas,以支持大规模数据处理,提供跨多个 CPU 核心或集群的并行计算,以及对超出可用内存的超大数据集的外存计算。它将 pandas 操作扩展到大数据,并与 PyData 生态系统良好集成。
然而,Dask 仅支持 pandas API 的一个子集,并且在设置和优化分布式计算时可能会比较复杂。它最适合处理无法放入内存或需要分布式计算资源的极大数据集。
import dask.dataframe as dd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Dask benchmark
start_time = time.time()
df_dask = dd.from_pandas(df_pandas, npartitions=4)
result_dask = df_dask.groupby('A').sum()
dask_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Dask time: {dask_time:.4f} seconds")
print(f"Speedup: {pandas_time / dask_time:.2f}x")
为了获得更好的性能,使用 Dask 加载数据,采用
dd.from_dict(data, npartitions=4替代 Pandas 数据框dd.from_pandas(df_pandas, npartitions=4)
输出
Pandas time: 0.0838 seconds
Dask time: 0.0213 seconds
Speedup: 3.93x
DuckDB
DuckDB 是一个内嵌的分析数据库,使用列式向量化查询引擎提供快速的分析查询。它支持 SQL 及附加功能,并且没有外部依赖,使得设置简单。DuckDB 在分析查询方面提供了卓越的性能,并且能够与 Python 及其他语言轻松集成。
然而,它不适合高交易量的工作负载,且并发选项有限。DuckDB 在分析工作负载中表现出色,特别是在偏好使用 SQL 查询时。
import duckdb
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
df = pd.DataFrame(data)
# Pandas benchmark
start_time = time.time()
result_pandas = df.groupby('A').sum()
pandas_time = time.time() - start_time
# DuckDB benchmark
start_time = time.time()
duckdb_conn = duckdb.connect(':memory:')
duckdb_conn.register('df', df)
result_duckdb = duckdb_conn.execute("SELECT A, SUM(B) FROM df GROUP BY A").fetchdf()
duckdb_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"DuckDB time: {duckdb_time:.4f} seconds")
print(f"Speedup: {pandas_time / duckdb_time:.2f}x")
输出
Pandas time: 0.0898
seconds DuckDB time: 0.1698
seconds Speedup: 0.53x
Modin
Modin旨在成为pandas的即插即用替代品,利用多个CPU核心实现更快的执行,并在分布式系统中扩展pandas操作。它需要最少的代码更改即可采用,并在多核系统上提供显著的速度提升潜力。
然而,Modin在某些场景下可能性能提升有限,并且仍在积极开发中。它最适合希望在不进行重大代码更改的情况下加速现有pandas工作流程的用户。
import modin.pandas as mpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Modin benchmark
start_time = time.time()
df_modin = mpd.DataFrame(data)
result_modin = df_modin.groupby('A').sum()
modin_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Modin time: {modin_time:.4f} seconds")
print(f"Speedup: {pandas_time / modin_time:.2f}x")
输出
Pandas time: 0.1186
seconds Modin time: 0.1036
seconds Speedup: 1.14x
Polars
Polars是一个高性能的DataFrame库,基于Rust构建,具有内存高效的列式内存布局和懒惰求值API以优化查询规划。它在数据处理任务中提供卓越的速度,并具备处理大数据集的可扩展性。
然而,Polars的API与pandas不同,需要一些学习,并可能在处理极大数据集(超过100GB)时遇到困难。它非常适合优先考虑性能的数据科学家和工程师,他们处理中到大型数据集。
import polars as pl
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Polars benchmark
start_time = time.time()
df_polars = pl.DataFrame(data)
result_polars = df_polars.group_by('A').sum()
polars_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Polars time: {polars_time:.4f} seconds")
print(f"Speedup: {pandas_time / polars_time:.2f}x")
输出
Pandas time: 0.1279 seconds
Polars time: 0.0172 seconds
Speedup: 7.45x
FireDucks
FireDucks提供与pandas API的完全兼容性、多线程执行和懒惰执行,以优化数据流效率。它具有一个运行时编译器,优化代码执行,相较于pandas提供显著的性能提升。由于与pandas API的兼容性以及数据操作的自动优化,FireDucks易于采用。
然而,与更成熟的库相比,它相对较新,可能拥有较少的社区支持和有限的文档。
import fireducks.pandas as fpd
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# FireDucks benchmark
start_time = time.time()
df_fireducks = fpd.DataFrame(data)
result_fireducks = df_fireducks.groupby('A').sum()
fireducks_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"FireDucks time: {fireducks_time:.4f} seconds")
print(f"Speedup: {pandas_time / fireducks_time:.2f}x")
输出
Pandas time: 0.0754 seconds
FireDucks time: 0.0033 seconds
Speedup: 23.14x
Datatable
Datatable 是一个高性能的数据处理库,具有面向列的数据存储、所有数据类型的原生 C 实现以及多线程数据处理。它在数据处理任务中提供了卓越的速度、高效的内存使用,并且设计用于处理大型数据集(最大可达 100 GB)。Datatable 的 API 类似于 R 的 data.table。
然而,它的文档不如 pandas 完善,功能较少,并且不兼容 Windows。Datatable 非常适合在单台机器上处理大型数据集,特别是在速度至关重要的情况下。
import datatable as dt
import pandas as pd
import time
# Sample data
data = {'A': range(1000000), 'B': range(1000000, 2000000)}
# Pandas benchmark
start_time = time.time()
df_pandas = pd.DataFrame(data)
result_pandas = df_pandas.groupby('A').sum()
pandas_time = time.time() - start_time
# Datatable benchmark
start_time = time.time()
df_dt = dt.Frame(data)
result_dt = df_dt[:, dt.sum(dt.f.B), dt.by(dt.f.A)]
datatable_time = time.time() - start_time
print(f"Pandas time: {pandas_time:.4f} seconds")
print(f"Datatable time: {datatable_time:.4f} seconds")
print(f"Speedup: {pandas_time / datatable_time:.2f}x")
输出
Pandas time: 0.1608 seconds
Datatable time: 0.0749 seconds
Speedup: 2.15x
性能比较
Datatable 在处理大规模数据时表现出色,为排序、分组和数据加载等操作提供了显著的性能提升。其多线程处理能力使其在利用现代多核处理器方面特别有效。
结论
总之,库的选择取决于数据集大小、性能要求和特定用例等因素。虽然 pandas 在较小的数据集上仍然具有多功能性,但像 Dask 和 FireDucks 这样的替代方案为大规模数据处理提供了强大的解决方案。DuckDB 在分析查询中表现出色,Polars 为中型数据集提供高性能,而 Modin 旨在以最小的代码更改扩展 pandas 操作。
下面的条形图展示了这些库的性能,使用 DataFrame 进行比较。数据经过归一化处理,以显示百分比。
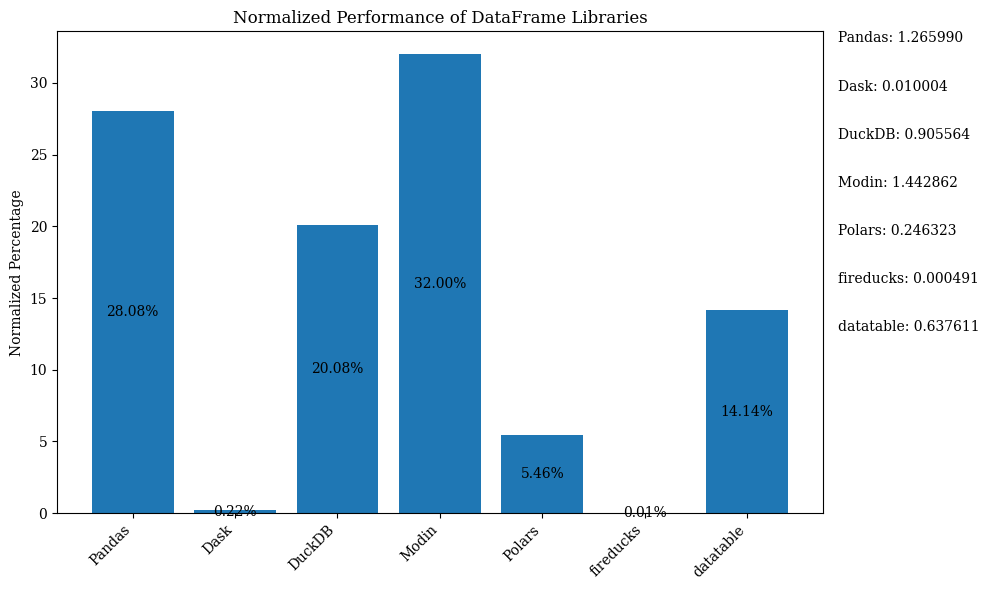
有关显示上述条形图的 Python 代码(使用归一化数据),请参考 Jupyter Notebook。使用 Google Colab,因为 FireDucks 仅在 Linux 上可用。
比较图表
| Library | Performance | Scalability | API Similarity to Pandas | Best Use Case | Key Strengths | Limitations |
|---|---|---|---|---|---|---|
| Pandas | 中等 | 低 | 不适用(原始) | 小到中型数据集,数据探索 | 多功能性,丰富的生态系统 | 在大型数据集上较慢,单线程 |
| Dask | 高 | 非常高 | 高 | 大型数据集,分布式计算 | 扩展 pandas 操作,分布式处理 | 复杂的设置,部分 pandas API 支持 |
| DuckDB | 非常高 | 中等 | 低 | 分析查询,基于 SQL 的分析 | 快速的 SQL 查询,易于集成 | 不适用于事务工作负载,有限的并发性 |
| Modin | 高 | 高 | 非常高 | 加速现有的 pandas 工作流 | 易于采用,多核利用 | 某些场景下改进有限 |
| Polars | 非常高 | 高 | 适中 | 中到大规模数据集,性能关键 | 卓越的速度,现代 API | 学习曲线,处理非常大数据时困难 |
| FireDucks | 非常高 | 高 | 非常高 | 大数据集,类似 pandas 的 API 具有性能 | 自动优化,pandas 兼容性 | 较新的库,社区支持较少 |
| Datatable | 非常高 | 高 | 适中 | 单机上的大数据集 | 快速处理,高效内存使用 | 功能有限,不支持 Windows |
此表提供了每个库的优势、限制和最佳用例的快速概述,便于在性能、可扩展性和与 pandas API 相似性等不同方面进行轻松比较。
Source:
https://dzone.com/articles/modern-data-processing-libraries-beyond-pandas