













LLMs通过自然语言处理(NLP)将文本的意义表示为向量,这种文本单词的表示形式称为嵌入。
令牌限制:LLM提示的最大问题
当前,LLM提示面临的最大问题之一是令牌限制。GPT-3发布时,提示和输出的总限制为2,048个令牌。到了GPT-3.5,这一限制增加到4,096个令牌。现在,GPT-4有两种版本,一种限制为8,192个令牌,另一种限制为32,768个令牌,大约相当于50页文本。
那么,当你想要处理一个超出此限制的上下文时,该怎么办呢?当然,唯一的解决方案是缩短上下文。但如何在缩短的同时保留所有相关信息呢?解决方案是:将上下文存储在向量数据库中,并通过相似性搜索查询找到相关上下文。
向量嵌入是什么?
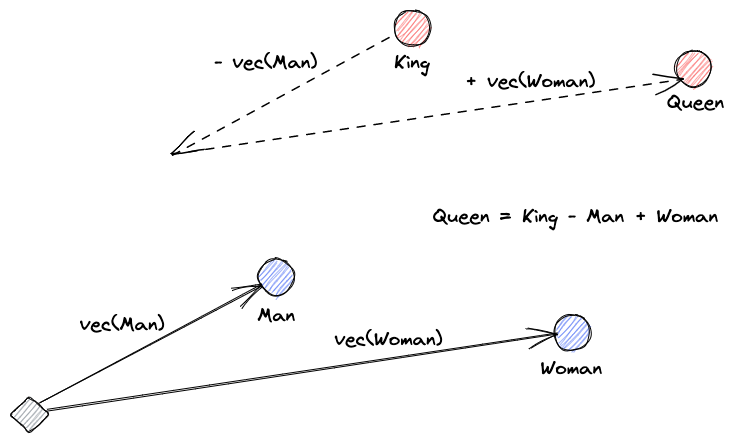
首先,我们来解释什么是向量嵌入。Roy Keynes的定义是:“嵌入是通过学习得到的变换,使数据更具实用性。”神经网络学会将文本转换为包含其实际意义的向量空间。这样做更有用,因为它能找到同义词以及词语之间的句法和语义关系。以下图示有助于我们理解这些向量如何编码意义:
向量数据库的作用是什么?
A vector database stores and indexes vector embeddings. This is useful for the fast retrieval of vectors and looking for similar vectors.
相似性搜索
我们可以通过计算一个向量与所有其他向量的距离来找到向量间的相似度。最接近的邻居将是与查询向量最相似的结果。这就是向量数据库中平面索引的工作原理。但这种方法效率不高;在大型数据库中,这可能需要很长时间。
为了提升搜索性能,我们可以尝试仅计算部分向量的距离。这种方法称为近似最近邻(ANN),虽然加快了速度,但牺牲了结果的质量。一些流行的ANN索引包括局部敏感哈希(LSH)、层次可导航小世界(HNSW)或倒排文件索引(IVF)。
结合向量存储与大型语言模型
以这个例子为例,我从此链接下载了完整的Numpy文档(超过2000页)作为PDF。
我们可以编写Python代码将上下文文档转换为嵌入,并将其保存到向量存储中。我们将使用LangChain加载文档并将其分割成块,使用Faiss(Facebook AI相似性搜索)作为向量数据库。
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("example_data/layout-parser-paper.pdf")
pages = loader.load_and_split()
embeddings = OpenAIEmbeddings()
db = FAISS.from_documents(pages, embeddings)
db.save_local("numpy_faiss_index")现在,我们可以使用这个数据库执行相似性搜索查询,以找到可能与我们的提示相关的页面。然后,我们使用这些块来填充我们提示的上下文。我们将使用LangChain使其更简单:
from langchain.vectorstores import FAISS
from langchain.chains.qa_with_sources import load_qa_with_sources_chain
from langchain.llms import OpenAI
query = "How to calculate the median of an array"
db = FAISS.load_local("numpy_faiss_index", embeddings)
docs = docsearch.similarity_search(query)
chain = load_qa_with_sources_chain(OpenAI(temperature=0), chain_type="stuff")
chain({"input_documents": docs, "question": query}, return_only_outputs=True)我们向模型提出的问题是,“如何计算数组的中位数。”尽管我们提供的上下文远远超出了令牌限制,但我们已经克服了这一限制并得到了答案。
To calculate the median, you can use the numpy.median() function, which takes an input array or object that can be converted to an array and computes the median along the specified axis. The axis parameter specifies the axis or axes along which the medians are computed, and the default is to compute the median along a flattened version of the array. The function returns the median of the array elements.
For example, to calculate the median of an array "arr" along the first axis, you can use the following code:
import numpy as np
median = np.median(arr, axis=0)
This will compute the median of the array elements along the first axis, and return the result in the variable "median".这仅是针对一个全新问题的一种巧妙解决方案。随着大型语言模型(LLMs)的不断进化,或许此类问题将不再需要这样巧妙的解决方法。但我确信,这一进化将开启新的能力之门,而这些新能力可能带来新的挑战,需要其他创新性的解决方案。
Source:
https://dzone.com/articles/maximizing-the-potential-of-llms-using-vector-data