













Общее заявление
“Почему” данного решения AI очень важно и широко распространено по всем областям.
Представьте, у вас есть несколько сканированных PDF-документов:
- Где клиенты делают некоторые ручные выборы, добавляют подпись/даты/информацию о клиенте
- У вас есть много страниц письменной документации, сканированных и хотите решение, которое extrahuет текст из этих документов
Или
- Вы просто ищете AI-поддержанный путь, который предоставляет интерактивный механизм для запроса документов, не имеющих структурированного формата
Деaling с такими сканированными/смешанными/неструктурированными документами может быть трудно, и извлечение важной информации из них может быть ручным, следовательно, склонным к ошибкам и сложным.
Решение ниже использует силу OCR (оптическое распознавание символов) и LLM (большие языковые модели), чтобы extrahuить текст из таких документов и запросить их, чтобы получить структурированную доверительную информацию.
Высокоуровневая архитектура
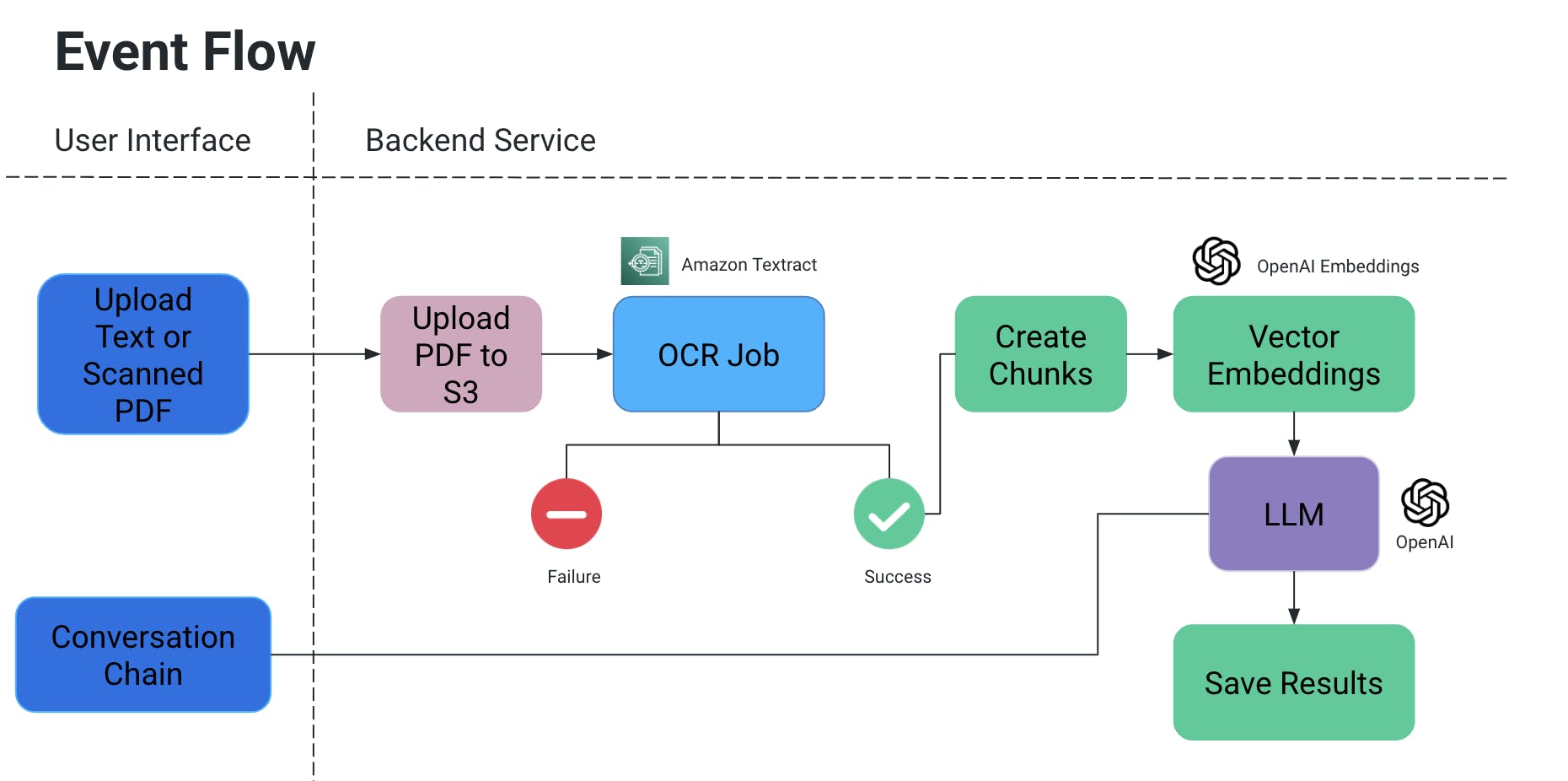
Интерфейс пользователя
- Интерфейс позволяет загружать PDF/сканированные документы (он может быть дополнительно расширен для других типов документов).
- Streamlit используется для интерфейса пользователя:
- Данный open-source Python Framework очень удобен в использовании.
- По мере внесения изменений, они отражаются в запущенных приложениях, делая этот механизм быстрой тестовой платформой.
- Сообществом поддержки Streamlit набирается сила и растет.
- Последовательность разговора:
- Это по существу обязательно, чтобы включить чатботы, способные отвечать на следующие вопросы и предоставлять историю чата.
- Мы используем LangChain для взаимодействия с используемым нами AI моделью; в целях данного проекта мы испытали OpenAI и Mistral AI.
backend service
流通事件
- 用户上传 PDF/扫描文档,然后将其上传到 S3 存储桶中。
- 然后 OCR 服务从 S3 存储桶 检索此文件并处理以从中提取文本。
- 从上述输出创建文本块,并为它们创建相关向量嵌入。
- 现在这非常重要,因为当文本块被分割时,您不希望失去上下文:它们可能会在句子中间被分割,如果没有一些标点符号,可能会失去意义,等等。
- 因此,为了抵消这一点,我们创建了重叠的文本块。
- Большая языковая модель, которую мы используем, принимает эти вкрапления в качестве входных данных, и у нас есть две функции:
- Генерировать специфический вывод:
- Если у нас есть конкретный вид информации, которую нужно извлечь из документов, мы можем предоставить запрос в коде к модели ИИ, получить данные и сохранить их в структурированном формате.
- Избежать галлюцинаций ИИ можно, явно добавив в код запросы с условиями, чтобы не подставлять определенные значения и использовать только контекст документа.
- Мы можем хранить его как файл в S3/локально или записывать в базу данных.
- Чат
- Здесь мы предоставляем конечному пользователю возможность инициировать чат с ИИ для получения конкретной информации в контексте документа.
- Генерировать специфический вывод:
Задание OCR
- Мы используем Amazon Textract для оптического распознавания этих документов.
- Он работает отлично с документами, также содержащими таблицы/формы и т. д.
- Если вы работаете над PoC, используйте бесплатный уровень для этого сервиса.
Векторные эмбеддинги
- Довольно простой способ понять векторные嵌入 (векторные представления) заключается в том, чтобы транслировать слова или предложения в числа, которые捕获 контекстное значение и взаимоотношения
- Представьте, у вас есть слово “кольцо”, которое является украшением: по смыслу этого самого слова, одним из ближайших соответствий является “песня”. Но с учетом значения слова, мы хотели бы, чтобы оно соответствовало чему-то вроде “ювелирных изделий”, “пальца”, “бриллиантов” или, возможно, чему-то вроде “ромба”, “кольцо”, и т. д.
- Таким образом, когда мы создаем векторное представление для “кольца”, в сущности мы заполняем его множеством информации о его значении и взаимоотношениях.
- Эта информация, вместе с векторными представлениями других слов/предложений в документе, обеспечивает выбор правильного значения слова “кольцо” в контексте.
- Мы использовали OpenAIEmbeddings для создания векторных представлений.
LLM
- Есть многочисленные крупные языковые модели, которые можно использовать в нашем сценарии.
- В рамках этого проекта были проведены тесты с OpenAI и Mistral AI.
- Прочитайте больше здесь о API-ключах для OpenAI.
- Для MistralAI использовалась HuggingFace.
Применения и тесты
Мы выполнили следующие тесты:
- Сигнатуры и рукописные даты/тексты были считаны с использованием OCR.
- Руками выбранные опции в документе
- Цифровые выделения, сделанные на документе
- Неструктурированные данные разбиты для получения табличного содержимого (добавить в текстовый файл/БД и т. д.)
Плановый объем
Мы можем далее расширить возможности указанного выше проекта, включив поддержку изображений, интегрируя с документационными хранениями, такими как Confluence/Drive и т.д., для извлечения информации о конкретной теме из множества источников, добавив более сильный вариант для сравнительного анализа двух документов и т.д.
Source:
https://dzone.com/articles/docai-pdfs-scanned-docs-to-structured-data