













ההצעה למשהו
ה"מדוע" של הפתרון החישובי הזה חשוב ונפוץ ברחבי תחומים רבים.
דמיינו שיש לך מספר דוגמאות של PDF סורקו:
- בהן ללקוחות יש לבחור מספר אפשרויות באופן ידני, להוסיף חתימה/תאריך/מידע ללקוח
- יש לך דפים רבים של מסמכים כתובים שנסורקו ואתה מחפש פתרון שישיג טקסט מהמסמכים האלה
או
- אתה פשוט מחפש דרך סיסמה חיובית של AI שמספקת מנגנון אינטראקטיבי כדי לבדוק מסמכים שאין להם פורמט מבנים
עיסוק במסמכים סורקו/מעורבבים/לא מבנים יכול להיות מסובך, והוצאת מידע חשוב מהם יכולה להיות ידנית, אז פגיעה ומסובכת.
הפתרון למטה משתמש בכח של OCR (זיהוי אופטי תווים) ו LLM (מודלים שפה גדולים) כדי לשיג טקסט מהמסמכים האלה ולבדוק אותם כדי לקבל מידע מבנוי ואמין.
הארכיטקטורה הגבוהה
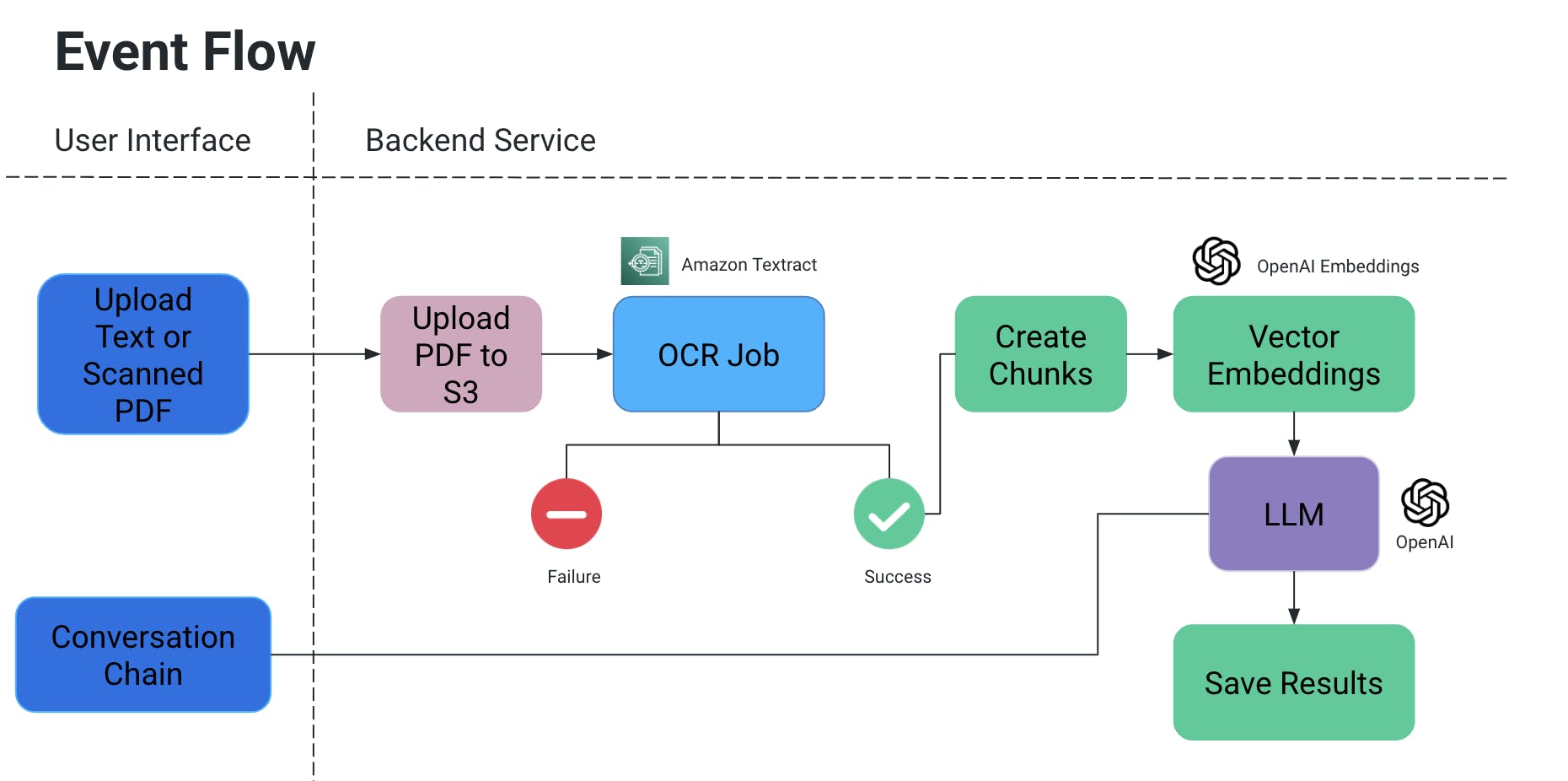
ממשק משתמש
- הממשק מאפשר להעלות PDF/ 文档扫描 (זה יכול להתרחב לסוגים נוספים של מסמכים).
- Streamlit נעשה בשימוש לממשק המשתמש:
- זו רשת פתוחה בפיתוח Python והיא קלה מאוד לשימוש.
- בעקבות השינויים, הם משקפים באפליקציות המופעלות, וזו מערכת בדיקה מהירה.
- התמיכה הקהילתית לStreamlit חזקה וגדלה.
- שרשרת שיחה:
- זה בעיקרון דרשון כדי להכליל בוטות שיענוגות שאומרות שאלות ממשלתיות ומספקות היסטוריית השיחה.
- אנחנו משתמשים בLangChain עבור התחברות עם מודל הAI שאנחנו משתמשים; למטרת הפרוייקט הזה, בדקנו עם OpenAI וMistral AI.
שירות רקע
תהליך אירועים
- המשתמש מעלה PDF/מסמך סרוק, אחר כך הוא נעלה לאחסן S3.
- שירות OCR אחר כך משלוח את הקבצים האלה מאחסן S3ומעבד אותם כדי לקלוט טקסט מהמסמך הזה.
- מקטעים של טקסט מוצרים מהפיצול האלה, ולהם יוצרים עימה הבעות מרובדות.
- עכשיו זה מאוד חשוב מפני שאתה לא רוצה לאבד הקשר כשמחלקים מקטעים: הם יכולים להיות חלקים באמצע משפת, ללא חלק מהפונקציות המשמעות עלולה להיעלם, וכך הלאה.
- אז כדי לתקן את זה, אנחנו יוצרים מקטעים מתערבבים.
- המודל הלשוני הגדול שאנו משתמשים בו לוקח את ההטמעות הללו כקלט ויש לנו שתי פונקציות:
- ייצור פלט ספציפי:
- אם יש לנו סוג ספציפי של מידע שצריך להוציא ממסמכים, אנו יכולים לספק שאילתה בקוד למודל ה-AI, להשיג נתונים ולשמור אותם בפורמט מסודר.
- מנע הזיות של AI על ידי הוספת שאילתות בקוד עם תנאים כדי לא להמציא ערכים מסוימים ולהשתמש רק בהקשר של המסמך.
- אנו יכולים לשמור את זה כקובץ ב-S3/מקומית או לכתוב למסד נתונים.
- שיחה
- כאן אנו מספקים את האפשרות למשתמש הקצה להתחיל שיחה עם AI כדי לקבל מידע ספציפי בהקשר של המסמך.
- ייצור פלט ספציפי:
עבודת OCR
- אנחנו משתמשים בAmazon Textract עבור זיהוי אופטי על המסמכים האלה.
- הוא פועל מצוין עם מסמכים שגם יש בהם טבלאות/טפסים, וכו'.
- אם אתה עובד על פו"ץ הנחישות, תנצל את הרמה החינמית לשרות הזה.
הבעות מובנים וektronים
- דרך מאוד קלה להבין את הטמעת הווקטורים היא לתרגם מילים או משפטים למספרים שמס capture את המשמעות והקשרים של ההקשר הזה
- דמיינו שיש לכם את המילה "טבעת" שהיא תכשיט: במונחים של המילה עצמה, אחד המתאימים הקרובים שלה הוא "שיר". אך במונחים של משמעות המילה, היינו רוצים שהיא תתאים למשהו כמו "תכשיטים", "אצבע", "אבני חן", או אולי משהו כמו "חישוק", "מעגל", וכו'.
- כך כאשר אנו יוצרים הטמעת וקטור של "טבעת", אנו בעצם ממלאים אותה בהרבה מידע על משמעותה וקשריה.
- מידע זה, יחד עם הטמעות הווקטור של מילים/הצהרות אחרות במסמך, מבטיח שהמשמעות הנכונה של המילה "טבעת" בהקשר נבחרת.
- השתמשנו בOpenAIEmbeddings ליצירת הטמעות וקטור.
LLM
- ישנם מספר מודלים גדולים של שפה שניתן להשתמש בהם בסcenario שלנו.
- במונחים של הפרוייקט הזה, ניסויים נעשו עם OpenAI ו-Mistral AI.
- קראו עוד כאן על מפתחים API לOpenAI.
- עבור MistralAI, ניצלה HuggingFace.
השימושים ומבחנים
ביצענו את המבחנים הבאים:
- מילות חתימה וטקסטים ידניים ניצפו בעזרת OCR.
- אפשרויות מושלמות במסמך
- העלאות דיגיטליות על המסמך
- ניתן מפרשת מידע לא מבנוי על מנת לקבל תוכן טבלי (להוסף לקובץ טקסט/DB וכן הלאה)
היעד העתידי
אנחנו יכולים להרחיב את היישומים לפרוייקט הקודם בכדי להשתמש בתמונות, לשלב את המאגרים הדוקמנטריים כמו Confluence/Drive, וכך למצוא מידע שקשור לנושא ספציפי ממקורות רבים, להוסיף מסלול חזק יותר לבחינה יחסית בין שני מסמכים וכך הלאה.
Source:
https://dzone.com/articles/docai-pdfs-scanned-docs-to-structured-data