













問題陈述
此 AI 解決方案的「為什麼」非常重要,並在多個領域中普遍存在。
想像你有多個扫瞄的 PDF 文档:
- 客戶進行一些手動選擇,加入签名/日期/客戶信息
- 你有多頁 scanning 後的書面文件,並希望找到一個解決方案以從這些文件中獲取文字
或
- 你正在尋找一個由 AI 支撐的途徑,提供一個互動性機制以查詢沒有結構化格式的文件
處理這些scan/混杂/非結構化文件可能會很棘手,並且從中提取重要信息可能會是手動操作,因此易於出錯且麻煩。
以下的解決方案充分利用 OCR (光学字符認識) 和 LLM (大語言模型) 的力量,以從這些文件中獲取文字並查詢它們以獲得結構化的可信信息。
高层次結構
用戶界面
- 用戶介面允許上傳 PDF/掃描文件(它可以進一步擴展到其他文件類型)。
- Streamlit 正在被利用於用戶介面:
- 它是一個開源的 Python 框架,非常容易使用。
- 當進行更改時,它們反映在運行中的应用程序中,使這成为一个快速的測試机制。
- Streamlit 的社區支持相對強劲且在不斷增長。
- 對話鏈:
- 這实际上是必要的,以便整合可以回答追蹤問題和提供聊天歷史的聊天机器人。
- 我們利用 LangChain 來與我們使用的 AI 模型接口;對於這個項目,我們已經測試了 OpenAI 和 Mistral AI。
後端服務
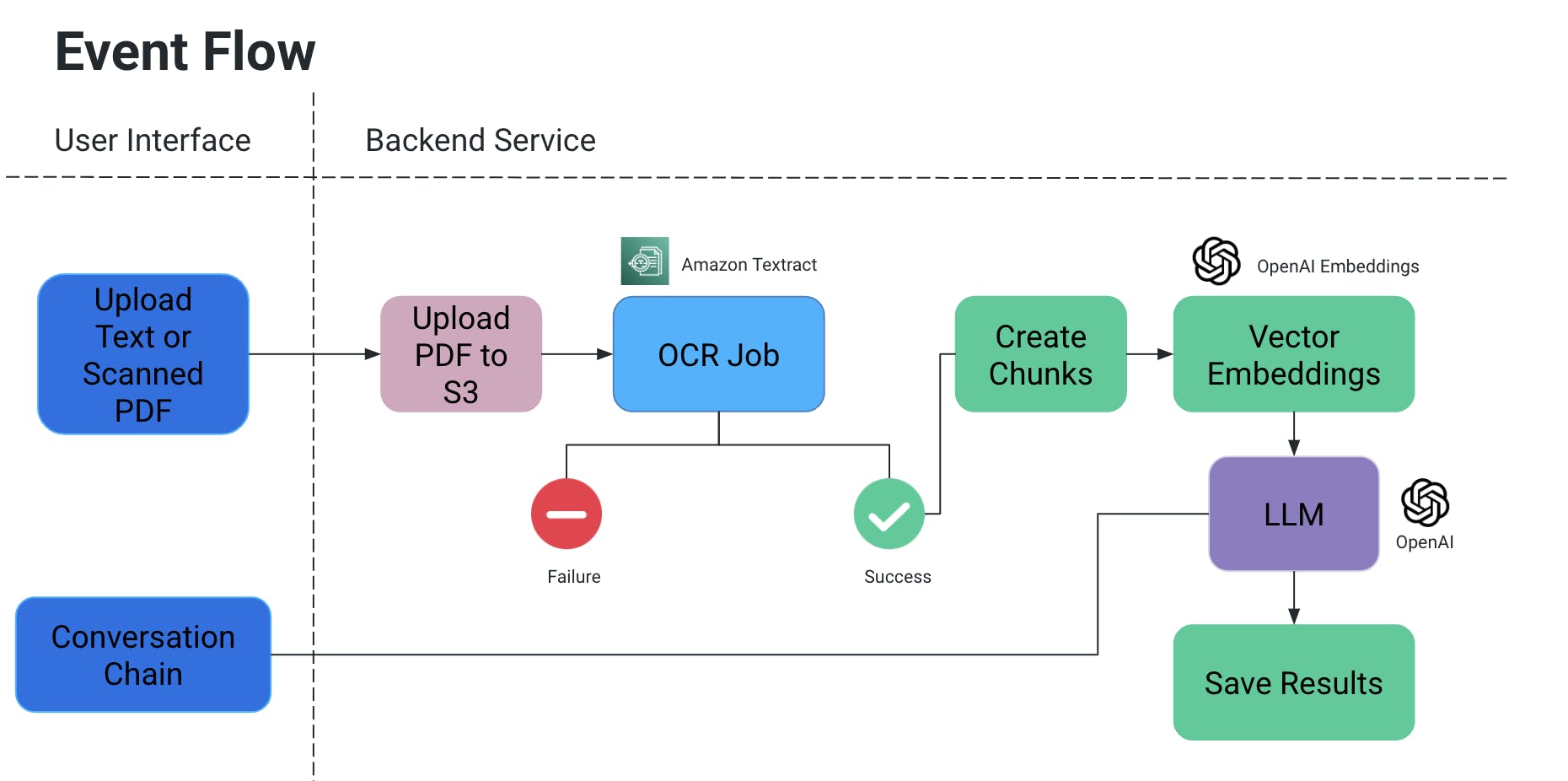
事件流程
- 用戶上傳 PDF/扫瞄文件,該文件然後会上傳至 S3 存儲桶。
- 然後 OCR 服務從 S3 存儲桶 取出該文件並處理,從該文件中提取文本。
- 從上述輸出中創建文本片段,並為它們創建相應的向量嵌入。
- 這非常重要,因為當文本片段被分割時,您不希望丢失上下文:它們可能會在句子中間分割,如果没有某些標點符號,可能會丢失意義,等等。
- 因此,為了解決這個問題,我們創建重叠的文本片段。
- 我們使用的超大語言模型將這些嵌入作為輸入,我們有两个功能:
- 生成特定輸出:
- 如果我們需要從文件中提取特定種類的資訊,我們可以在AI模型中提供代碼中的查詢,取得數據,並以結構化格式存儲。
- 通過显式地添加带有条件的代碼查询,避免AI虚构某些值,只使用文件的上下文。
- 我們可以将其作為S3/本地文件存儲,或寫入數據庫。
- 聊天
- 這裡為最終用戶提供與AI聊天 Initialize a chat with AI to obtain specific information in the context of the document.
- 生成特定輸出:
OCR工作
- 我們使用Amazon Textract对这些文件进行光学识别。
- 它非常适合那些还有表格/表格等文档。
- 如果正在做一个POC,请利用这个服务的免费层。
向量嵌入
- 非常簡單的方法來理解向量嵌入(vector embeddings)就是將詞語或句子翻譯成數字,這些數字捕捉了該情境下的意義和關係
- 想像你有一個詞語”ring”,它是一種裝飾品:從詞語本身來說,它的一個近似詞是”sing”。但從詞語的意義來說,我們可能會希望它與”jewelry”(珠寶)、”finger”(手指)、”gemstones”(宝石)等詞語匹配,或者 perhaps 像”hoop”、”circle”(圓圈)等詞語。
- 因此當我們創建”ring”的向量嵌入時,我們基本上是在填滿關於其意義和關係的大量信息。
- 這些信息,连同文中其他詞語/句子的向量嵌入,確保了在特定情境中”ring”的正确意義被選擇。
- 我們使用了OpenAIEmbeddings來創建向量嵌入。
LLM
- 對於我們的場景,有多个大型的語言模型可以使用。
- 在這個项目中,已經進行了 OpenAI 和 Mistral AI 的測試。
- 在 這裡 閱讀更多關於 OpenAI 的 API 匙牌信息。
- 對於 MistralAI,我們使用了 HuggingFace。
應用案例和測試
我們進行了以下測試:
- 使用 OCR 閱讀签名的手寫日期/文字。
- 在文件中手選的選項
- 在文件上所做的数码選擇
- 解析非結構化數據以獲得表格內容(添加到文本文件/數據庫等)
未來範圍
我們可以進一步扩大上述项目的使用案例,以整合圖像,與文件儲存的系統如Confluence/Drive等結合,從多個來源提取有關特定主題的信息,增加進行兩份文件比較的更强渠道等。
Source:
https://dzone.com/articles/docai-pdfs-scanned-docs-to-structured-data