













Énoncé du problème
La raison d’être de cette solution AI est très importante et prévalente dans de multiples domaines.
Imaginez-vous avoir plusieurs documents PDF scannés :
- Où les clients font certaines sélections manuelles, ajoutent une signature/des dates/des informations clients
- Vous avez plusieurs pages de documentation écrite qui ont été scannées et recherchez une solution qui permet d’extraire du texte de ces documents
OU
- Vous cherchez simplement une voie soutenue par une IA qui offre un mécanisme interactif pour interroger les documents qui n’ont pas un format structuré
Traiter des documents scannés/mixtes/non structurés peut être compliqué, et l’extraction d’informations cruciales de ceux-ci pourrait être manuelle, ce qui est donc sujet à erreur et encombrant.
La solution ci-dessous utilise la puissance de l’OCR (Reconnaissance des caractères optiques) et des LLM (Grandes modèles de langue) afin d’extraire du texte de tels documents et de les interroger pour obtenir des informations structurées et de confiance.
Architecture de haut niveau
Interface utilisateur
- L’interface utilisateur permet la téléchargement de documents PDF/scannés (il peut être étendu à d’autres types de documents également).
- Streamlit est utilisé pour l’interface utilisateur :
- Il s’agit d’un framework Python open source et est extrêmement facile à utiliser.
- Lorsque des modifications sont effectuées, elles se reflètent dans les applications en cours d’exécution, ce qui permet une rapide mécanisme de test.
- La communauté de soutien pour Streamlit est assez forte et croît.
- Chaîne de conversation :
- Cela est essentiel pour intégrer des chatbots qui peuvent répondre à des questions ultérieures et fournir l’historique du chat.
- Nous utilisons LangChain pour l’interface avec le modèle d’IA que nous utilisons ; pour ce projet, nous avons testé avec OpenAI et Mistral AI.
Service arrière-plan
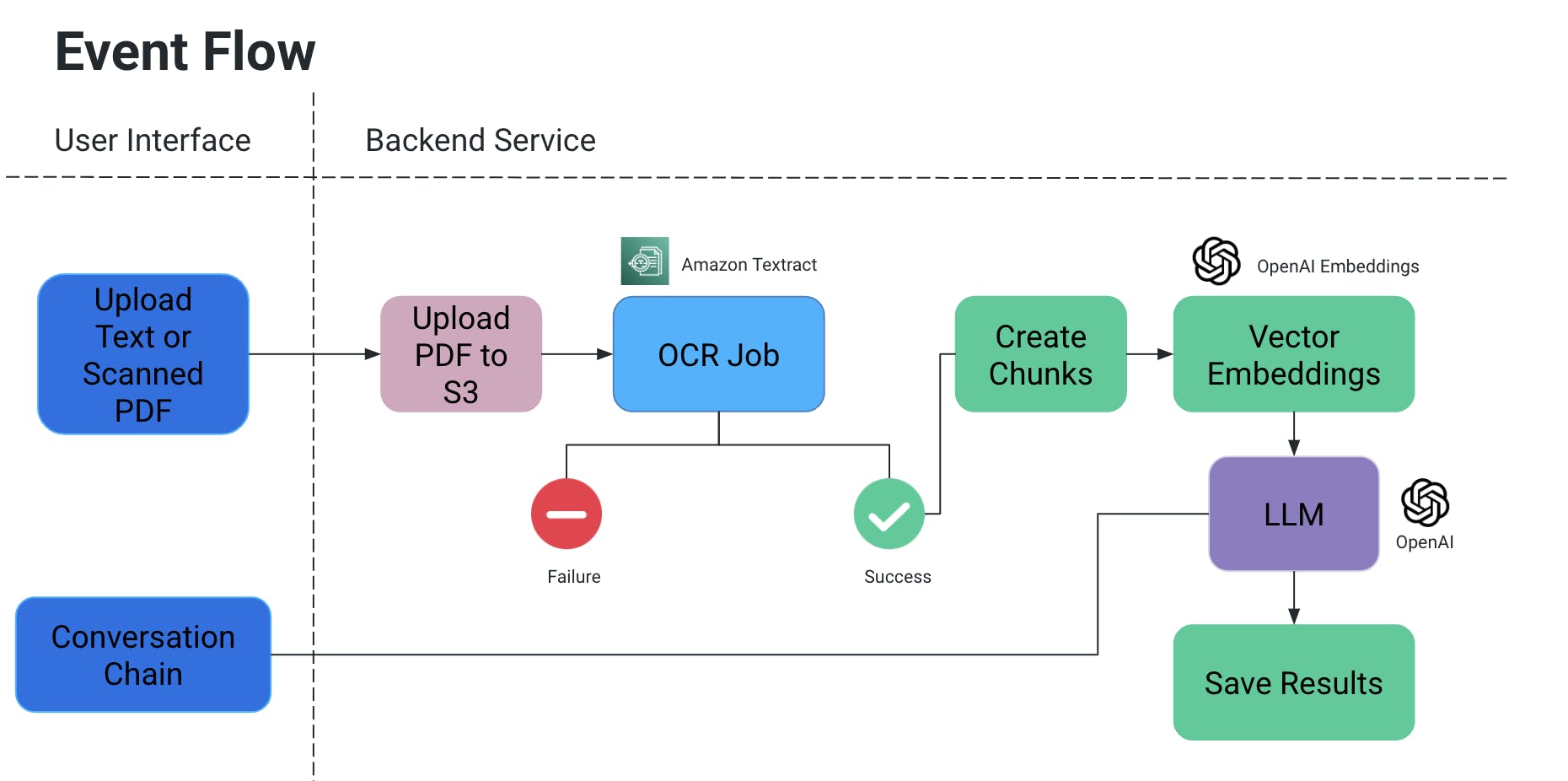
Flux des événements
- L’utilisateur télécharge un document PDF/scanner, qui est ensuite téléchargé dans un compartiment S3.
- Un service OCR récupère ensuite ce fichier de l’S3 bucket et le traite pour extraire du texte de ce document.
- Des morceaux de texte sont créés à partir de l’output ci-dessus, et des embeddings vectoriels associés sont créés pour eux.
- Maintenant, ceci est très important parce que vous ne voulez pas que le contexte soit perdu lorsque les morceaux sont divisés : ils pourraient être divisés au milieu de la phrase, sans certaines ponctuations, le sens pourrait être perdu, etc.
- Ainsi, pour contrer cela, nous créons des morceaux superposés.
- Le grand modèle linguistique que nous utilisons prend ces enchâssements en entrée et nous disposons de deux fonctionnalités :
- Générer une sortie spécifique :
- Si nous avons un type d’information spécifique qui doit être extrait des documents, nous pouvons fournir une requête en code au modèle d’IA, obtenir des données et les stocker dans un format structuré.
- Éviter les hallucinations de l’IA en ajoutant explicitement des requêtes en code avec des conditions pour ne pas inventer certaines valeurs et utiliser uniquement le contexte du document.
- Nous pouvons le stocker sous forme de fichier dans S3/localement OU écrire dans une base de données.
- Chat
- Ici, nous donnons la possibilité à l’utilisateur final d’initier un chat avec l’IA pour obtenir des informations spécifiques dans le contexte du document.
- Générer une sortie spécifique :
Travail de reconnaissance optique
- Nous utilisons Amazon Textract pour la reconnaissance optique de ces documents.
- Cela fonctionne très bien avec les documents qui contiennent également des tableaux/formulaires, etc.
- Si vous travaillez sur un POC, profitez du niveau gratuit pour ce service.
Vector Embeddings
- Une manière très simple pour comprendre les embeddings vectoriels est de traduire les mots ou les phrases en numéros qui capturent le sens et les relations du contexte
- Envisagez que vous avez le mot « anneau », qui est un ornement : en termes du mot même, l’un de ses matches proches est « chanter ». Cependant, en termes du sens du mot, nous voudrions qu’il corresponde à quelque chose comme « joyau », « doigt », « pierre précieuse » ou peut-être quelque chose comme « harnais », « cercle », etc.
- Ainsi, lorsque nous créons l’embedding vectoriel de « anneau », nous remplissons essentiellement avec plein d’information sur son sens et ses relations.
- Cette information, ainsi que les embeddings vectoriels d’autres mots/phrases dans un document, assure que le sens correct du mot « anneau » dans le contexte est choisi.
- Nous avons utilisé OpenAIEmbeddings pour créer les embeddings vectoriels.
LLM
- Il existe plusieurs grands modèles de langage qui peuvent être utilisés pour notre scénario.
- Dans le cadre de ce projet, des tests ont été effectués avec OpenAI et Mistral AI.
- Lire plus ici sur les clés API pour OpenAI.
- Pour MistralAI, HuggingFace a été utilisé.
Cas d’utilisation et tests
Nous avons effectué les tests suivants :
- Les signatures et les dates/textes manuscrits ont été lus à l’aide de l’OCR.
- Des options sélectionnées à la main dans le document
- Des sélections numériques effectuées au dessus du document
- Le parsing de données non structurées pour obtenir du contenu tabulaire (ajouter à fichier de texte/BDD, etc.)
Portée future
Nous pouvons améliorer davantage les cas d’utilisation du projet précédent en incorporant des images, en intégrant avec des magasins de documentation tels que Confluence ou Drive, etc., afin de tirer de l’information sur un sujet spécifique de multiples sources, en ajoutant une voie plus robuste pour la comparaison entre deux documents, etc.
Source:
https://dzone.com/articles/docai-pdfs-scanned-docs-to-structured-data