













問題声明
このAIソリューションの「なぜ」は、さまざまな分野で非常に重要で普遍的です。
いくつかのスキャンされたPDF文書を想象してください:
- 顧客が手動で選択を行い、签名/日付/顧客情報を追加しています。
- スキャンされた本文档の多页を持っていて、これらの文書からテキストを取得したいソリューションを探しています
または
- 结构化されていない文書に対してインタラクティブな Mechanismを提供するAIサポートされた道を探しています
このようなスキャンされた/混合された/非構造化された文書を取り扱うことは厄介事です。そして、重要な情報を取り出すことは手動で行われ、誤差が発生しやすく、手間がかかります。
以下のソリューションは、OCR(光学文字認識)とLLM(大規模言語モデル)の力を利用して、これらの文書からテキストを取得し、構造化された信頼性のある情報を取得するためにクエリを行います。
高层次のアーキテクチャ
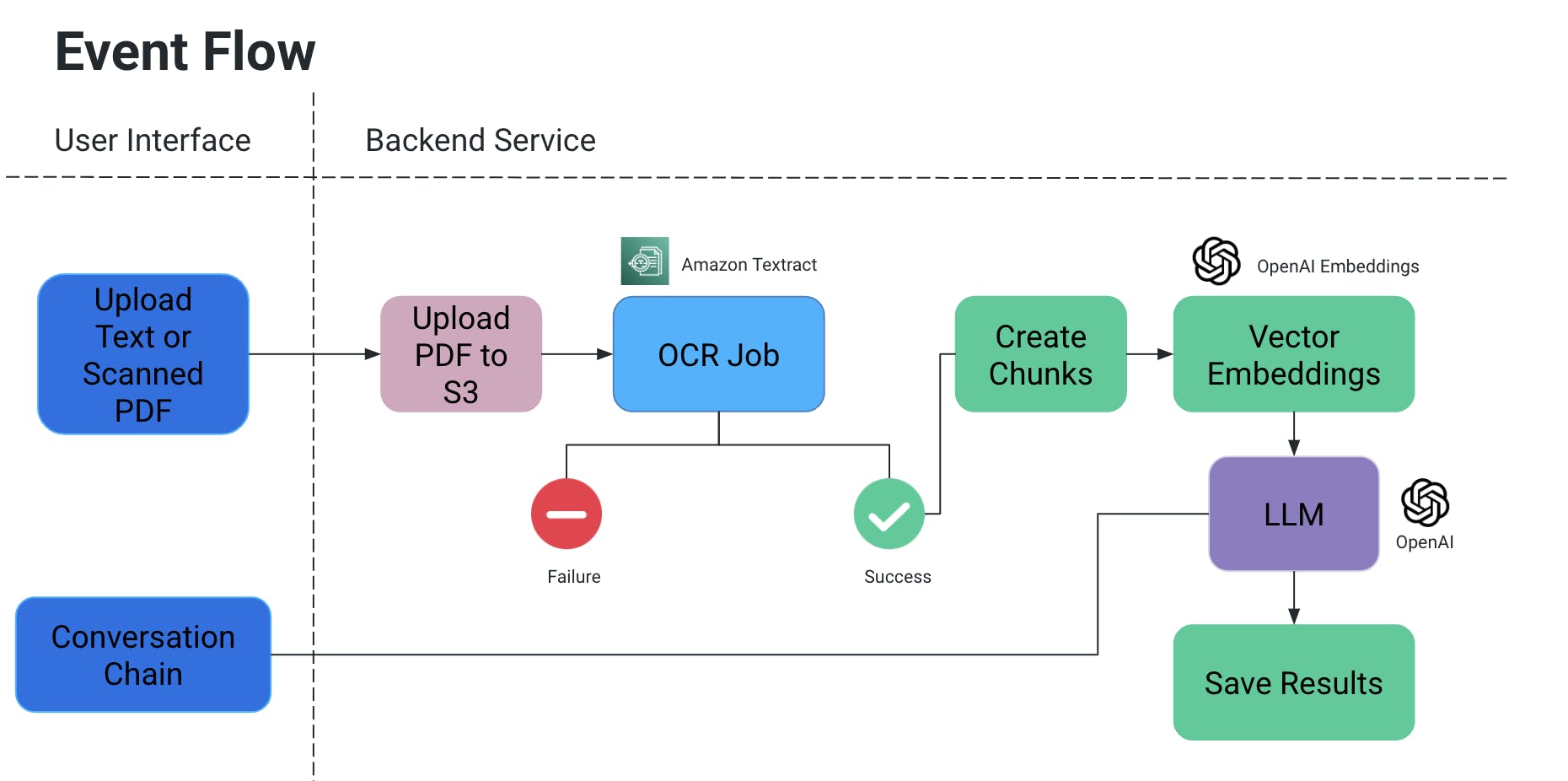
ユーザーインターフェース
- UIにてPDFやスキャンされた文書をアップロードすることができ、さらに他の文書タイプにも拡張することが可能です。
- StreamlitをUIに利用しています。
- これはオープンソースのPythonフレームワークで、非常に簡単に使用できます。
- 変更が行われるたびに、実行中のアプリに反映され、これは迅速なテスト手法になります。
- Streamlitのコミュニティサポートは相当に強力で、成長しています。
- 会話チェーン:
- これは、フォローアップ質問に答えるチャットボットと、チャット履歴を提供することが基本的に必要です。
- 私たちは、AIモデルとのインターフェースにLangChainを利用しています;このプロジェクトの目的では、OpenAIとMistral AIでテストを行いました。
バックエンドサービス
イベントの流れ
- ユーザーがPDFまたはスキャンした文書をアップロードすると、それがS3バケットにアップロードされます。
- 次に、OCRサービスがこのファイルをS3バケットから取得し、文書からテキストを抽出するために処理します。
- 上記の出力からテキストのチャンクが作成され、それに関連するベクトル埋め込みが作成されます。
- これは非常に重要です。なぜなら、チャンクが分割されるときにコンテキストが失われてはいけないからです:文の途中で分割される可能性があり、句読点がないと意味が失われることがあります。
- それに対抗するために、重複するチャンクを作成します。
-
- 特定の出力を生成する:
- 文書から特定の種類の情報を抽出する必要がある場合、AIモデルにコード内のクエリを提供し、データを取得し、構造化された形式で保存することができます。
- AIの幻覚を防止するために、特定の値を捏造することはなく、文書のコンテキストだけを使用するように条件付きのコード内のクエリを明示的に追加します。
- S3/ローカルにファイルとして保存したり、データベースに書き込んだりできます。
- チャット
- ここで、最終的なユーザーが文書のコンテキストで特定の情報を得るために、AIとチャットを開始する手段を提供します。
- 特定の出力を生成する:
OCRジョブ
- 私たちは、Amazon Textractをこれらの文書の光学認識に使用しています。
- これは、テーブル/フォームなども含まれる文書にも優れています。
- POCを行う場合、このサービスを無料のテイラーで利用してください。
ベクターエンブeddings
- ベクトル嵌入(ベクトルエンブeddings)を理解する非常に簡単な方法は、語句を数値に翻訳することで、このコンテキストの意味と関係を捕らえることです。
- 例えば、「指輪」というアクセサリーとしての語句を考えてみましょう。語句自体において、近い意味の語は「sing」になるかもしれません。しかし、語句の意味においては、「ジュエリー」、「指先」、「宝石」など、または「ホープ」、「円环」などになることを望んでいます。
- したがって、私たちが「ring」のベクトル嵌入を作成する時、基本的にはそれに関連した意味や関係の多くの情報を埋め込んでいます。
- この情報と、文档内の他の語句のベクトル嵌入をともに持つことで、コンテキストの中で「ring」という語句の正しい意味が選ばれるようにします。
- 私たちはOpenAIEmbeddingsを使用してベクトル嵌入を作成しました。
LLM
- 私たちのシーンに适用できる多くの大規模な言語モデルがあります。
- このプロジェクトの範囲で、OpenAIとMistral AIでのテストが行われました。
- OpenAIのAPIキーについての詳細はここを参照してください。
- MistralAIについては、HuggingFaceを利用しました。
使用例とテスト
以下のテストを行いました:
- 署名と手写きの日付/テキストをOCRを使用して読み取りました。
- 文書内の手選択されたオプション
- 文書上で行われたデジタル選択
- 非構造化データを解析して表形式のコンテンツを取得しました(テキストファイル/DBに追加など)。
将来の范囲
私たちは、上記のプロジェクトの使用例をさらに拡張することができます。画像を取り込んだり、Confluence/Driveなどの文書管理ツールと統合したり、特定のトピックに関する情報を複数の源から抽出したり、2つの文書間の比較分析をより強力にするための方法を追加したりできます。
Source:
https://dzone.com/articles/docai-pdfs-scanned-docs-to-structured-data