













بيان المشكلة
ال”لماذا” لهذه الحلول التي تتمتع بالذكاء هو شيء مهم جدا و من الواضح في مجالات متعددة.
تخيل أن لديك عدة مستندات PDF مسحوقة:
- حيث يقوم الزبائن ببعض الاختيارات اليدوية وإضافة توقيع/تاريخ/معلومات الزبين
- لديك صفحات عديدة من المستندات الكتابية التي تم مسحها وتود حلول تحصل على النص من هذه الوثائق
أو
- أنت ببساطة تبحث عن ممر مساعد على التعرف والتواصل التي تمتلك دعم من تقنية المخترع التي لا تمتلك تنظيم بنياتي
التعامل مع هذه الوثائق المسحوقة/مزودة بالتكوينات/غير البنياتية قد يكون صعباً واستخراج المعلومات الحيوية منها قد يكون باليد البشرية وقد يكون معتبراً ومؤلماً.
الحلول التالية تستغل القوة من تكنولوجيا OCR (تعرف الحروف بالفحص الضوئي) والنماذج الكبيرة (النماذج اللغوية الكبيرة) لحصول النص من هذه الوثائق وتساءل عنها لحصول على معلومات منظمة وموثوقة.
الهيكل العام
الواجهة المستخدم.
- تسمح لواجهة المستخدم بتحميل المستندات الشفرية PDF / المستندات المسحوقة (يمكن توسيعها إلى أنواع أخرى من المستندات أيضًا).
- Streamlit يتم استخدامه لواجهة المستخدم:
- إنه إطار برمجيات بريدي مفتوح المصدر وهو سهل الاستخدام للغاية.
- وكلما يتم إجراء تغييرات، يمكن رؤيتها في التطبيقات الجارية، مما يجعل هذا النموذج للاختبار السريع.
- يوجد دعم جيد وينمو من قبل مجموعة المتعاونين لـ Streamlit.
- سلسلة المحادثة:
- هذا بالأساس من المطلوب لتضمين البوتس والتي يمكنها إجابة أسئلة تتبعة وتوفير تاريخ المحادثة.
- نستخدم LangChain للتواصل مع النموذج التعلمي الذي نستخدمه؛ ولغرض هذا المشروع قمنا بتجربته مع OpenAI وMistral AI.
خدمة الجانب الخلفي
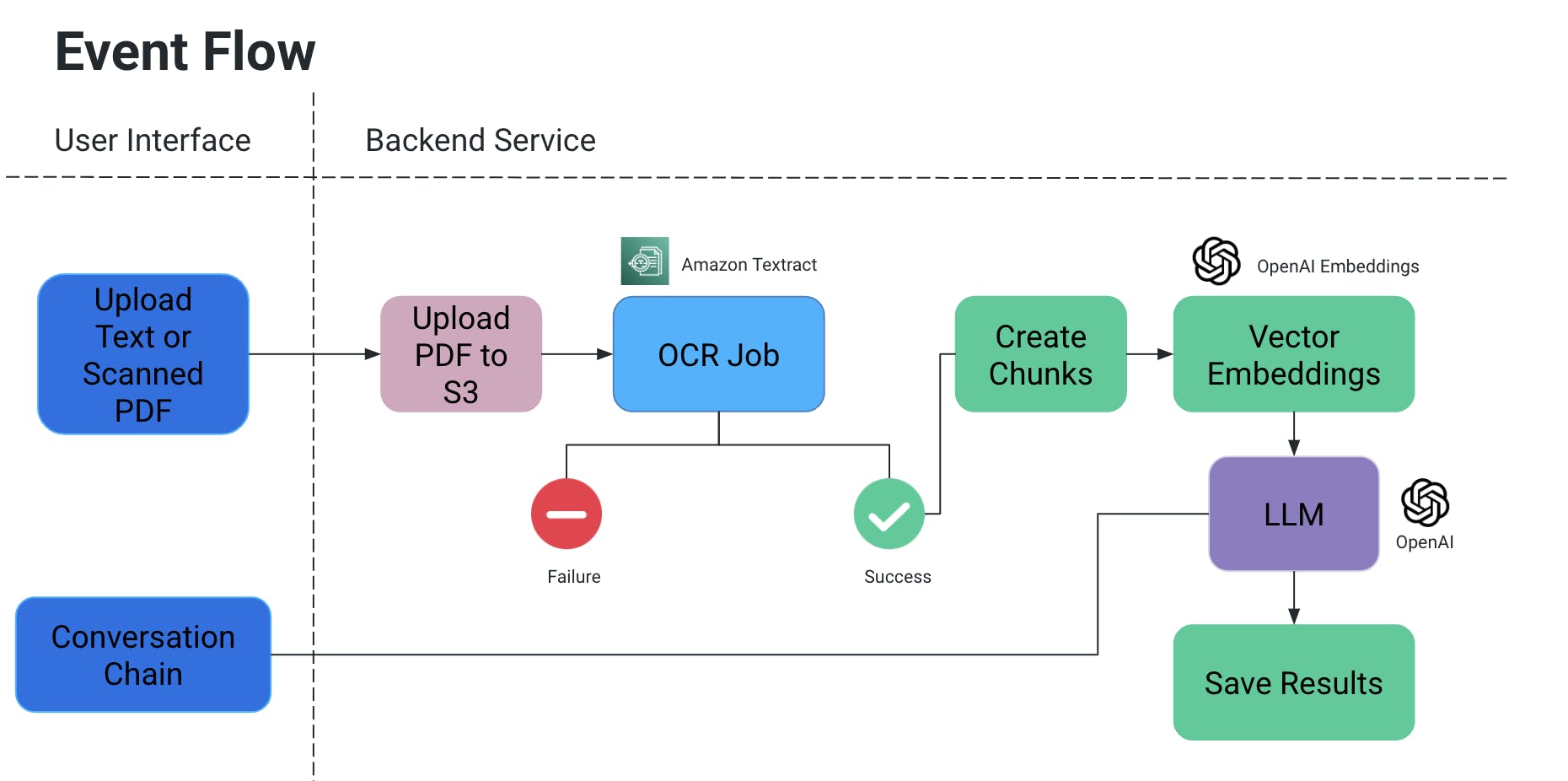
تدفق الأحداث
- يقوم المستخدم بتحميل مستند PDF/مسح ما يتم بعدها تحميله إلى حزمة S3.
- يتم بعدها استعادة هذا الملف من حزمة S3 بواسطة خدمة OCR وتم معالجته لتسحق النص من هذا المستند.
- يتم إنشاء أجزاء من النص من خلال الخروج السابق، ويتم إنشاء توامي المبدأ لهم.
- هذا مهم جدا لأنك لا تريد أن تخسر السياق حين تنقسم الأجزاء: قد ينقسم في النص في منتصف الجملة ، ومن دون بعض التعبيرات قد يخسر معنى الجملة، وهكذا.
- لذلك نقوم بإنشاء أجزاء تتتالية معهم.
- نموذج اللغة الكبير الذي نستخدمه يأخذ هذه التضمينات كمدخلات ولدينا وظيفتان:
- توليد مخرجات محددة:
- إذا كان لدينا نوع محدد من المعلومات التي تحتاج إلى استخراجها من الوثائق، يمكننا تقديم استعلام في الكود لنموذج الذكاء الاصطناعي، الحصول على البيانات، وتخزينها في تنسيق منظم.
- تجنب هلوسات الذكاء الاصطناعي من خلال إضافة استعلامات في الكود بشكل صريح مع شروط لعدم اختراع قيم معينة واستخدام فقط سياق الوثيقة.
- يمكننا تخزينها كملف في S3/محليًا أو الكتابة إلى قاعدة بيانات.
- الدردشة
- هنا نوفر وسيلة للمستخدم النهائي لبدء دردشة مع الذكاء الاصطناعي للحصول على معلومات محددة في سياق الوثيقة.
- توليد مخرجات محددة:
وظيفة OCR
- نستخدم Amazon Textract للتعرف الضوئي على هذه المستندات.
- هي تعمل جيدًا مع المستندات التي تحتوي أيضًا على جداول/ورقات وهلم جرا.
- إذا كان عملك على مختبر تجريبي، استخدم الدرجة المجانية لهذه الخدمة.
تركيزات ال vectores
- فإن أساسية جداً لفهم تكرارات المجموعات هي ترجمة الكلمات أو العبارات إلى أرقام تلتقط معانيها وعلاقاتها في هذا السياق
- تخيل أنك لديك كلمة “خاتم” وهي مجسم جمالي: من ناحية الكلمة بحد ذاتها، أحد أقرب التطابقات لها هو “الغناء”. ومن ناحية معنى الكلمة، نريد أن يتطابق مع شيء مثل “الجواهرة”, “الإصبع”, “الجواهر الصناعية”، أو ربما شيء مثل “الحلقة”, “الدائرة”, وهلم جرا.
-
وهكذا حينما نخلق تكرارات المجموعات لـ “الخاتم”, نحن بالأساس نملأه بالعديد من المعلومات حول معناه وعلاقاته.
هذه المعلومات، مجاناً بجانب تكرارات المجموعات للكلمات الأخرى/العبارات في المستند، تضمن اختيار المعنى الصحيح لكلمة “الخاتم” في السياق. - أستخدمنا OpenAIEmbeddings لخلق تكرارات المجموعات.
LLM
- هناك مختلف نماذج كبيرة لللغة التي يمكن استخدامها في هذه الحالة.
- في إطار هذه المشروع، قمنا بالتختبر مع OpenAI و Mistral AI.
- قراءة المزيد هنا عن أسماك البرمجيات ل OpenAI.
- ل MistralAI، تم استخدام HuggingFace.
الحالات والتختبرات
قمنا بالتختبر التالي:
- قامنا بقراءة التوقيعات والتاريخات/النصوص المكتوبة بواسطة OCR.
- خيارات منخرطة يدويًا في المستند
- الاختيارات الرقمية التي تم إنجازها فوق المستند
- تحليل البيانات الغير منظمة لحصول على محتويات جدولية (إضافة إلى الملف النصي/قاعدة البيانات وهكذا)
النطاق المستقبلي
يمكننا توسيع حالة استخدام المشروع الأعلى لتضمين الصور والاندماج مع مستودعات المساعدات مثل Confluence / Drive وما إلى ذلك لتسحب المعلومات التي تخص موضوع مع المصادر المتعددة وإضافة مسار أقوى للتقارن المتقدم بين م document من مصادر مختلفة وهكذا.
Source:
https://dzone.com/articles/docai-pdfs-scanned-docs-to-structured-data