













Enunciado do Problema
A “razão” desta solução AI é muito importante e prevalente em vários campos.
Imagine que você tem vários documentos PDFscanados:
- Onde os clientes fazem algumas seleções manuais, adicionam assinatura/data/informação do cliente
- Você tem várias páginas de documentação escrita que foram scanadas e procura uma solução que obtenha texto destes documentos
OU
- Você está simplesmente procurando uma alternativa com suporte de IA que forneça um mecanismo interativo para consultar documentos que não possuem um formato estruturado
Lidar com documentos scanados/misturados/não estruturados pode ser complicado, e extrair informações cruciales deles pode ser manual, portanto, propenso a erros e custoso.
A solução abaixo explora o poder de OCR (Reconhecimento Óptico de Caracteres) e LLM (Modelos de Linguagem Grande) para obter texto de documentos destes e consultá-los para obter informação estruturada de confiança.
Arquitetura de Alta Camada
Interface de Usuário
- A interface de usuário permite o upload de documentos PDF/scanner (pode ser expandido para outros tipos de documentos também).
- Streamlit está sendo aproveitado para a interface de usuário:
- É um framework Python aberto e muito fácil de usar.
- Ao realizar as mudanças, elas refletem nas aplicações em execução, tornando isso um mecanismo de teste rápido.
- A comunidade de suporte para Streamlit é razoavelmente forte e está crescendo.
- Cadeia de conversa:
- Isso é essencial para incorporar chatbots que podem responder a perguntas subsequentes e fornecer histórico de chat.
- Nós aproveitamos LangChain para interagir com o modelo de IA que usamos; para o propósito deste projeto, testamos com OpenAI e Mistral AI.
Serviço de Backend
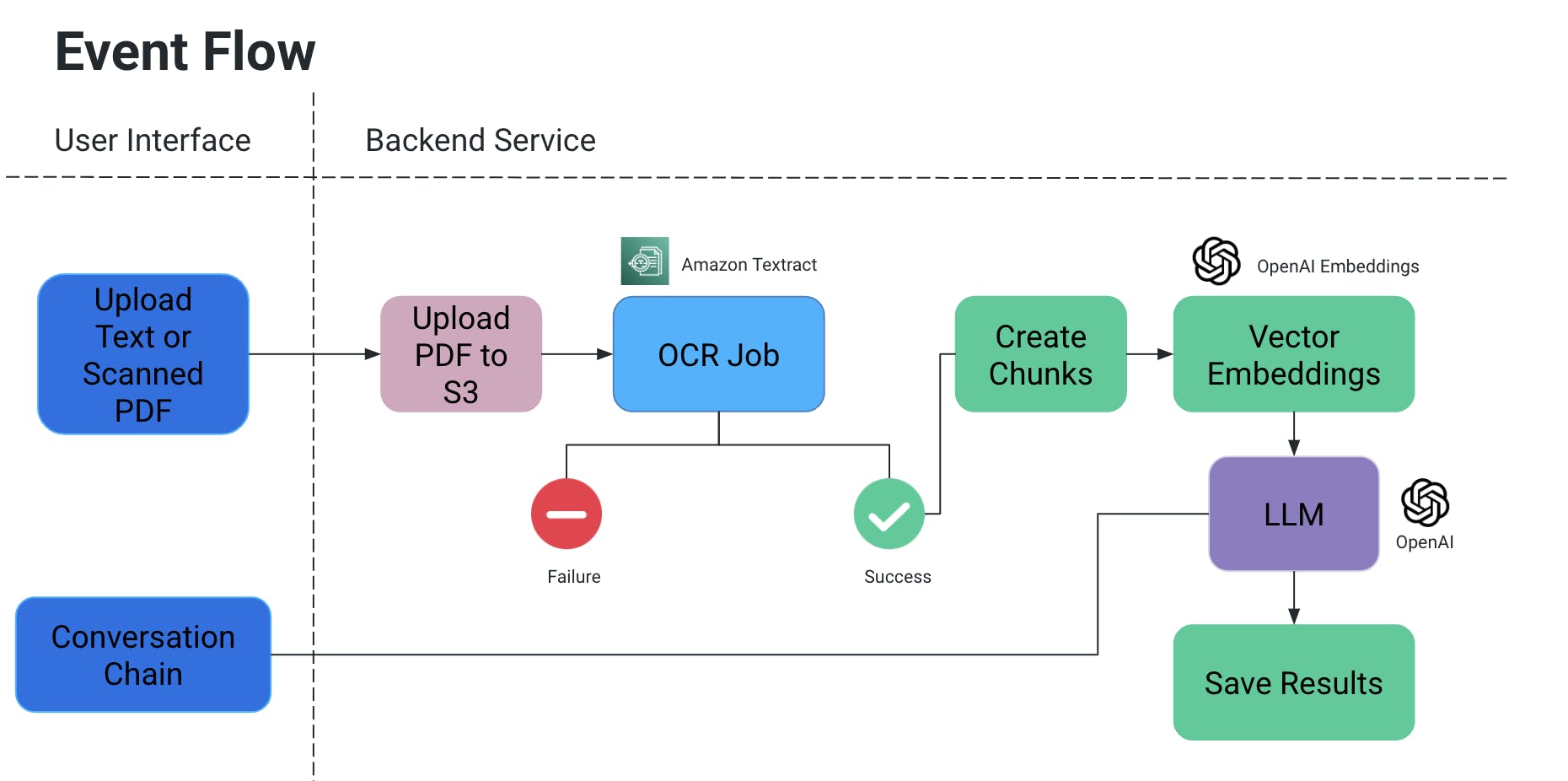
Fluxo de Eventos
- O usuário carrega um arquivo PDF/documento digitalizado, que é então carregado para uma camada S3.
- Um serviço OCR então recupera este arquivo de camada S3 e processa-o para extrair texto deste documento.
- Os pedaços de texto são criados a partir da saída acima e são associados a representações vetoriais embutidas deles.
- Agora isso é muito importante, pois você não quer perder o contexto quando os pedaços são divididos: eles podem ser divididos no meio de uma frase, sem algumas pausas o significado poderia ser perdido, etc.
- Então, para contrabalançá-lo, criamos pedaços superpostos.
- O grande modelo de linguagem que usamos recebe esses embeddings como entrada e temos duas funcionalidades:
- Gerar saída específica:
- Se tivermos um tipo específico de informação que precisa ser extraída de documentos, podemos fornecer uma consulta no código para o modelo de IA, obter os dados e armazená-los em um formato estruturado.
- Avoid AI hallucinations adicionando explicitamente consultas no código com condições para não inventar certos valores e usar apenas o contexto do documento.
- Podemos armazená-lo como um arquivo no S3/localmente OU gravar em um banco de dados.
- Chat
- Aqui fornecemos a opção para o usuário final iniciar um chat com a IA para obter informações específicas no contexto do documento.
- Gerar saída específica:
Tarefa de OCR
- Nós estamos usando Amazon Textract para reconhecimento óptico nestes documentos.
- Ele funciona muito bem com documentos que também têm tabelas/formulários, etc.
- Se estiver trabalhando em um POC, aproveite a camada gratuita para este serviço.
Embeddings Vetoriais
- Uma maneira muito fácil de entender as representações vetoriais é traduzir palavras ou frases em números que capturam o significado e as relações desse contexto
- Imagine que você tem a palavra “anel”, que é um adornamento: em relação à própria palavra, uma de suas correspondências próximas é “sing”. Mas em relação ao significado da palavra, nós gostaríamos que fosse semelhante a coisas como “jóias”, “dedo”, “pedras preciosas”, ou talvez coisas como “hóptero”, “círculo”, etc.
- Portanto, quando criamos a representação vetorial de “anel”, basicamente estamos preenchendo com montes de informações sobre seu significado e relações.
- Essa informação, juntamente com as representações vetoriais de outras palavras/frases em um documento, garante que o significado correto da palavra “anel” no contexto é selecionado.
- Nós usamos OpenAIEmbeddings para criar representações vetoriais.
LLM
- Existem múltiplos modelos de linguagem grande que podem ser usados para nosso cenário.
- No âmbito deste projeto, realizou-se testes com OpenAI e Mistral AI.
- Leia mais aqui sobre as Chaves de API para OpenAI.
- Para MistralAI, foi aproveitado HuggingFace.
Casos de Uso e Testes
Realizamos os seguintes testes:
- Leitura de assinaturas e datas/textos escritos à mão usando OCR.
- Opções selecionadas à mão no documento
- Seleções digitais feitas acima do documento
- Parse de dados não estruturados para obter conteúdo tabular (adicionar ao arquivo de texto/BD, etc.)
Scope futuro
Podemos expandir ainda mais os casos de uso para o projeto acima para incorporar imagens, integrar com armazenamentos de documentação como Confluence/Drive, etc., para extrair informações relativas a um tópico específico de várias fontes, adicionar uma avenida mais forte para fazer análise comparativa entre dois documentos, etc.
Source:
https://dzone.com/articles/docai-pdfs-scanned-docs-to-structured-data