













Stato del problema
Il “perché” di questa soluzione AI è molto importante e presente in molti campi diversi.
Immaginate di avere molti documenti PDF scannerizzati:
- Nei quali i clienti fanno delle scelte manuali, aggiungono firma/data/informazioni del cliente
- Hai molte pagine di documentazione scritta che sono state scannerizzate e vuoi una soluzione che estrae testo da questi documenti
O
- Stai cercando un canale supportato da AI che offra un meccanismo interattivo per interrogare documenti che non hanno un formato strutturato
Lavorare con documenti scannerizzati/miscredenti/non strutturati può essere complesso, e l’estrazione di informazioni cruciali da essi può essere manuale, quindi soggetto a errori e complessa.
La soluzione qui sotto sfrutta il potere dell’OCR (Riconoscimento Ottico dei Caratteri) e degli LLM (Modelli di Linguaggio Larghi) per estrarre testo da questi documenti e interrogarli per ottenere informazioni strutturate di fiducia.
Architettura a alto livello
Interfaccia utente
- L’interfaccia utente consente l’upload di documenti PDF/scansionati (potrebbe essere ulteriormente esteso ad altri tipi di documento).
- Streamlit viene utilizzato per l’interfaccia utente:
- È un framework Python open-source e è estremamente facile da utilizzare.
- Con le modifiche apportate, queste si riflettono nelle app in esecuzione, rendendolo un meccanismo di test veloce.
- La comunità di supporto per Streamlit è piuttosto forte e in crescita.
- Catenatura conversazione:
- Questo è fondamentale per includere chatbot in grado di rispondere a domande successive e fornire cronologia chat.
- Utilizziamo LangChain per l’interfaccia con il modello AI che usiamo; per questo progetto, abbiamo testato OpenAI e Mistral AI.
Servizio Backend
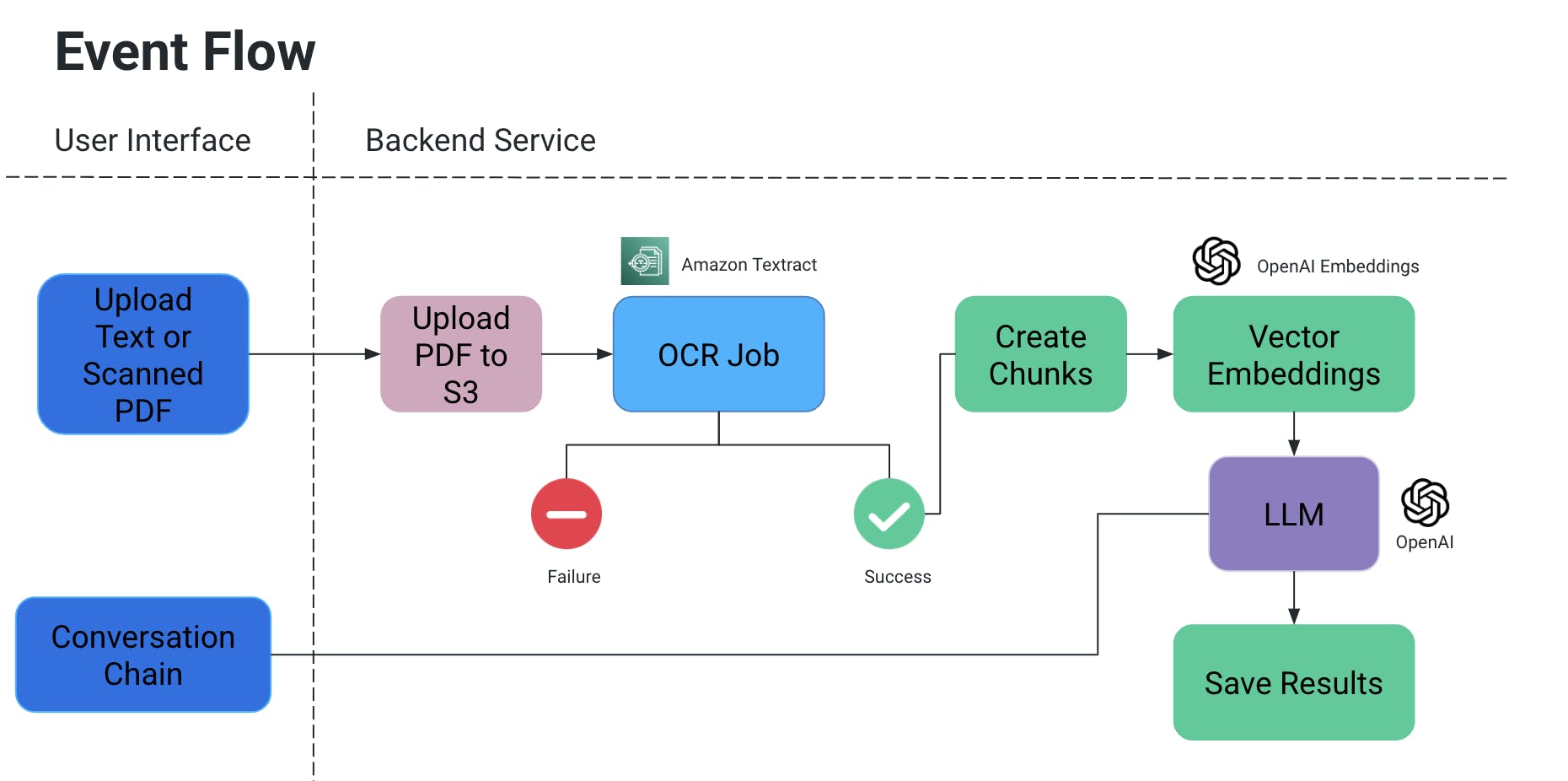
Flusso degli eventi
- L’utente carica un PDF/documento scannerizzato, che viene poi caricato in un bucket S3.
- Un servizio OCR quindi recupera questo file dal bucket S3 e lo processa per estrarre del testo da questo documento.
- Vengono create da questo output pezzi di testo, e per essi vengono create associate embedding vettoriali.
- Ora questo è molto importante perché non si vuole perdere il contesto quando i pezzi vengono divisi: possono essere divisi a metà di una frase, senza alcune punteggiature il significato potrebbe essere perso, ecc.
- Quindi per controbilanciarlo, creiamo pezzi sovrapposti.
- Il modello linguistico di grandi dimensioni che utilizziamo prende in input queste incorporazioni e dispone di due funzionalità:
- Generare un output specifico:
-
Se abbiamo un tipo specifico di informazioni che devono essere estratte dai documenti, possiamo fornire una query in-code al modello AI, ottenere i dati e memorizzarli in un formato strutturato.
- Evitare le allucinazioni dell’IA aggiungendo esplicitamente query in-code con condizioni per non inventare certi valori e usare solo il contesto del documento.
- Possiamo memorizzarlo come file in S3/localmente O scriverlo in un database.
- Chat
- Qui forniamo all’utente finale la possibilità di avviare una chat con l’IA per ottenere informazioni specifiche nel contesto del documento.
- Generare un output specifico:
Oggetto OCR
- Stiamo utilizzando Amazon Textract per la riconoscenza ottica di questi documenti.
- Funziona molto bene con documenti che contengono anche tabelle/moduli, ecc.
- Se state lavorando a un POC, sfruttate la fascia gratuita per questo servizio.
Embedding vettoriali
- Un modo molto semplice per capire le embedded vector è tradurre parole o frasi in numeri che catturino il significato e le relazioni del contesto
- Pensate ad una parola come “anello”, che è un gioiello: in termini della parola stessa, una delle sue corrispondenze più vicine è “canto”. Ma in termini del significato della parola, ci aspetteremmo che corrisponda a qualcosa come “gioielli”, “dito”, “gemma” o forse qualcosa come “cesto”, “cerchio”, ecc.
- Quindi quando creiamo le embedded vector di “anello”, in sostanza ci riempiranno di tonnellate di informazioni sul suo significato e le sue relazioni.
- Queste informazioni, insieme alle embedded vector di altre parole/frasi in un documento, garantiscono che la corretta interpretazione della parola “anello” nel contesto sia scelta.
- Usiamo OpenAIEmbeddings per la creazione di embedded vector.
LLM
- Ci sono molti grandi modelli di linguaggio che possono essere utilizzati per il nostro scenario.
- Nell’ambito di questo progetto, sono stati condotti test con OpenAI e Mistral AI.
- Leggi di più qui sui Collegamenti API per OpenAI.
- Per MistralAI, è stato utilizzato HuggingFace.
Casi d’uso e test
Abbiamo condotto i seguenti test:
- Le firme e le date/testi scritti a mano sono stati letti utilizzando l’OCR.
- Opzioni selezionate a mano nel documento
- Selezioni digitali fatte sopra il documento
- Dati non strutturati parsi per ottenere contenuto tabellare (aggiungere al file di testo/DB, ecc.).
Futuro scope
Possiamo estendere ulteriormente i casi d’uso del progetto precedente per includere le immagini, integrare con i repository di documentazione come Confluence/Drive, ecc., per estrarre informazioni relative a un determinato argomento da fonti multiple, aggiungere un approcio migliore per effettuare l’analisi comparativa tra due documenti, ecc.
Source:
https://dzone.com/articles/docai-pdfs-scanned-docs-to-structured-data