













Доступность виртуальных машин (VM) является важным условием для обеспечения бизнес-продолжительности. Когда услуги, работающие на ключевых для бизнеса и миссии виртуальных машинах, становятся недоступными, компании могут потерять деньги и доверие клиентов. Чтобы немедленно восстановить доступность VM после отказа, следует использовать соответствующие методы аварийного переключения.
Переключение на реплику VM может быть частью восстановления после катастрофы для восстановления данных и операций с минимальным нарушением обычных рабочих процессов. Процесс аварийного переключения VM должен быть описан в системе бизнес-продолжительности и восстановления после катастрофы (BCDR) организации. Давайте подробнее рассмотрим типы и сценарии использования аварийного переключения VM.
Что такое аварийное переключение?
Аварийное переключение – это процесс возобновления работы виртуальной машины (VM) на вторичной системе (а иногда и во вторичном местоположении) после отказа основной системы. Вторичная система содержит все необходимые данные для поддержания бизнес-операций. Система в этом контексте может быть сервером, базой данных, виртуальной машиной и т. д.
В виртуальных средах существуют два распространенных метода аварийного переключения:
- Использование реплики VM (обычно расположенной на другом виртуализационном сервере) используется для выполнения аварийного переключения в случае отказа первичной VM
- Использование кластера аварийного переключения (без необходимости репликации)
Отказоустойчивость требует меньше времени на восстановление рабочих нагрузок по сравнению с восстановлением из резервной копии, и, следовательно, вы можете достичь более низкого времени достижения цели по восстановлению (RTO). Однако использование репликации ВМ или кластеризации не устраняет необходимости создания резервных копий ВМ. Резервная копия (обычно сжатая) полезна, когда вам нужно восстановить данные из старой точки восстановления.
Давайте рассмотрим основные термины отказоустойчивости ВМ для восстановления после катастрофы на основе репликации.
Глоссарий отказоустойчивости
- Отказ: Любая проблема с аппаратным или программным обеспечением в результате сбоя системы, отключения питания, проблем с сетью, атаки вымогательского программного обеспечения и т. д., которая выводит систему из строя.
- Основная система: Система, выполняющая живые операции в производственной среде.
- Вторичная система: Резервная стендбай-система, которая регулярно обновляется копиями основной системы. Вторичная система может находиться на месте или в удаленном месте.
- Репликация: Основной процесс для подготовки к отказоустойчивости ВМ. Репликация создает точную копию, то есть реплику, основной ВМ на определенный момент времени.
- Возврат к основной системе: Возврат к основной системе после устранения инцидента.
Типы отказов
Существует три типа отказов:
- A planned failover is used for scheduled migrations of workloads from one system/site to another. Use cases include performing maintenance on the primary system, electrical works performed at the production site, and expected disaster scenarios. For example, a weather alert about a tornado may require a planned failover to ensure availability.
- Неплановый переключение – это переключение, выполненное при неожиданном сбое, приводящем к отключению критической ВМ или всего основного сайта. Сбой может быть вызван любым из ряда естественных бедствий, несчастных случаев (отключение питания), атаки вредоносного ПО или любого другого инцидента. Для непланового переключения хосты и реплики должны быть подготовлены заранее.
- A test failover, as the name suggests, is used for testing purposes. Testing scenarios can include rehearsing unplanned failover scenarios to ensure that
Последовательность переключения
Во время переключения ВМ последовательность действий и порядок запуска ВМ являются важными для успешного возобновления рабочих процессов. Они должны быть определены на этапе разработки плана восстановления после катастрофы вашей организации. Последовательность должна учитывать зависимости между различными службами, работающими на различных ВМ.
Например, аутентификация для некоторых служб и приложений, работающих на ВМ, может использовать Active Directory, который запущен на другой ВМ. Сервер баз данных может работать на первой ВМ, сервер приложений на второй, а веб-сервер на третьей.
ВМ с сервером Active Directory должен быть запущен первым. Затем можно запускать ВМ с услугами, которые используют Active Directory для аутентификации. ВМ с сервером базы данных должен быть запущен перед ВМ с сервером приложений, потому что сервер приложений подключается к базе данных. После запуска ВМ с сервером базы данных и сервером приложений можно запустить ВМ с веб-сервером.
Основные решения по аварийному переключению
Основные решения, используемые в виртуальных средах:
- кластеризация с переключением
- аварийное переключение с использованием реплик ВМ
Рассмотрим каждое из них.
Решение 1. Кластеризация с переключением
A failover cluster is a group of at least two servers or nodes that are configured to take over workloads when one node is down or unavailable. Clustering is an enterprise-class automated solution that can be used for the most important, business-critical VMs. Microsoft Hyper-V offers a Failover Cluster made up of several Hyper-V hosts. VMware’s equivalent is a High Availability cluster, which is made up of ESXi hosts.
На первой диаграмме ниже вы можете видеть кластер, в котором оба хоста (также называемые узлами) функционируют правильно. ВМ работают на хостах, а файлы ВМ расположены на общем хранилище, к которому имеют доступ оба хоста.
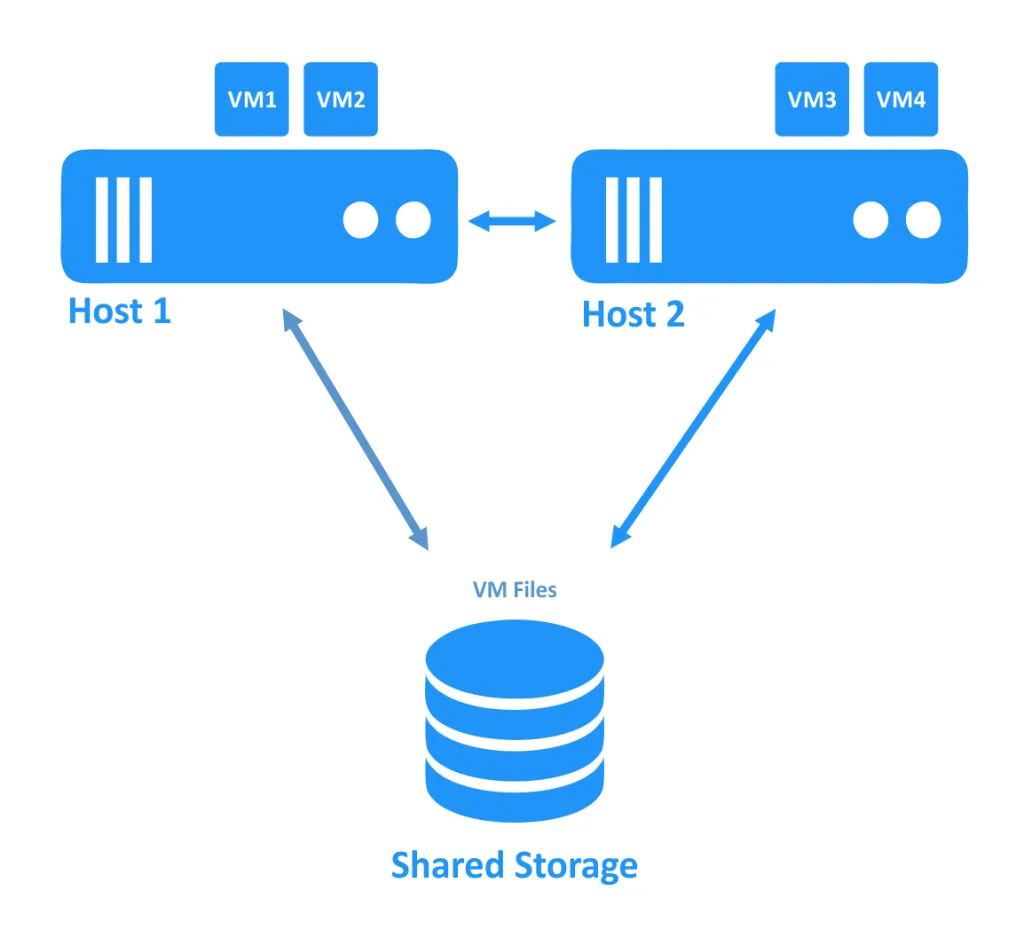
Когда один из хостов выходит из строя, владение соединением с ВМ (которая работала на отключенном узле) передается другому узлу, который все еще онлайн. Это процесс аварийного переключения. ВМ с высокой доступностью может потребоваться перезапуск.
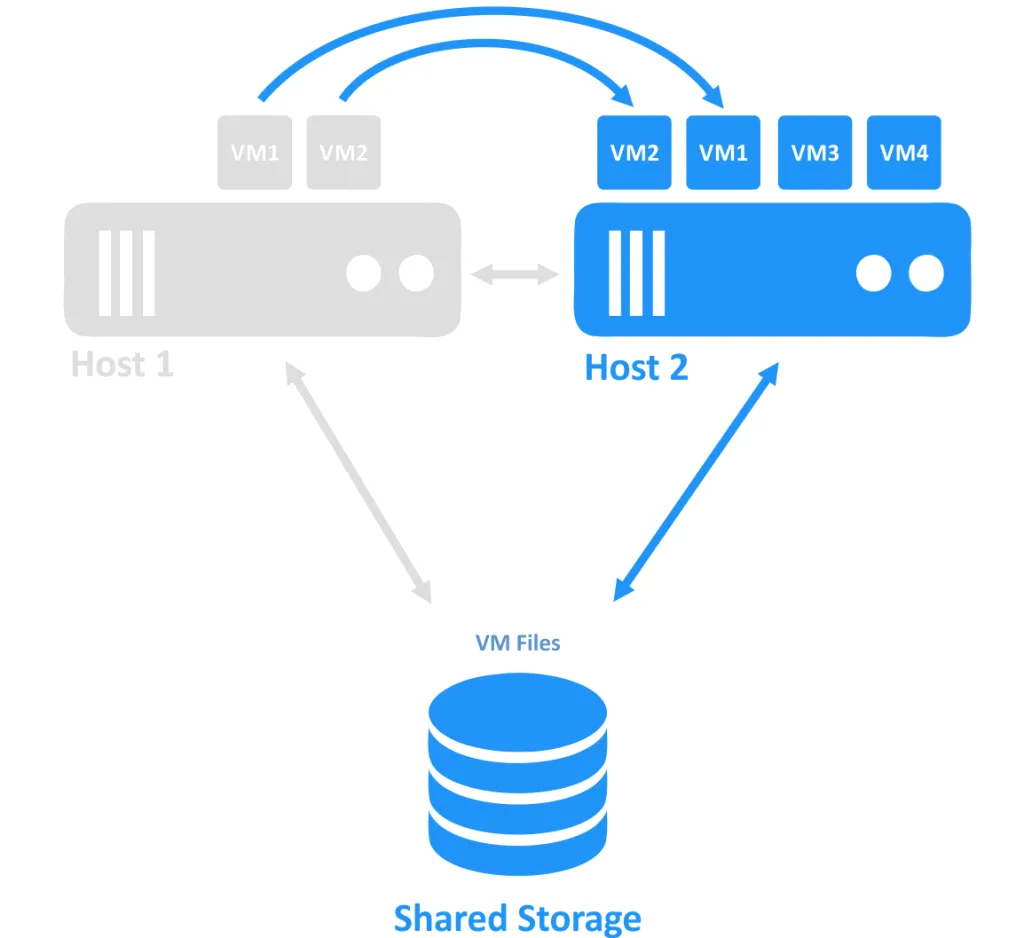
Требования к кластеризации с переключением
Для построения кластера с переключением должны быть выполнены следующие требования:
- Общее хранилище, подключенное к хостам по выделенной высокоскоростной сети с низкой задержкой. Для обеспечения возможности одновременного доступа нескольких хостов к данным, расположенным на хранилище, должна использоваться кластерная файловая система.
- Хосты, на которых работают виртуальные машины, должны иметь одинаковое оборудование или, по крайней мере, оборудование одного семейства. Процессоры должны поддерживать одинаковые наборы инструкций, чтобы обеспечить совместимость для правильной работы виртуальных машин после их миграции с одного хоста на другой во время переключения.
- A high-speed redundant network with low latency. There should be multiple, separate cluster networks, that is, a cluster must have different networks for storage, management, VM migration, connection of hosts amongst each other, etc.
Варианты использования
Кластеры переключения используются для восстановления виртуальных машин после сбоя сервера, обеспечивая высокую доступность для критически важных виртуальных машин. Если один из хостов (которые называются узлами) в кластере выходит из строя, то виртуальные машины, работавшие на вышедшем из строя хосте, мигрируют (переключаются) на другие здоровые хосты. В зависимости от ваших настроек, виртуальные машины, которые были переключены, могут быть перемещены обратно на хост, на котором они работали до инцидента, как только сбой будет устранен.
Преимущества
A failover cluster has advantages that provide strong protection:
- A failover cluster provides automatic VM failover. You don’t need to start the failed VMs manually on other hosts.
- При переключении вы почти не теряете данные. Время простоя обычно ограничивается временем загрузки виртуальной машины, операционной системы (ОС) и программного обеспечения, работающего на виртуальной машине.
- Функция Отказоустойчивость, включенная в кластер высокой доступности VMware, обеспечивает переключение виртуальных машин без простоев и потерь данных.
Недостатки
A failover cluster does not protect against:
- Сбой программного обеспечения в виртуальных машинах. Ошибки программного обеспечения или вирусы могут вызвать сбой системы в виртуальной машине.
- Случайное удаление файлов внутри виртуальной машины.
- Сбой общего хранилища. Кластер выходит из строя, если выходит из строя общее хранилище. Общее хранилище является ключевым компонентом кластера; виртуальные диски, принадлежащие виртуальным машинам внутри кластера, хранятся в общем хранилище.
- A disaster that makes the whole physical site unavailable.
Для получения дополнительной информации о том, что такое кластеризация с аварийным переключением, прочтите полное руководство по кластеризации VMware.
Решение 2. Аварийное переключение с использованием реплик виртуальных машин
Аварийное переключение виртуальных машин на основе реплик виртуальных машин может быть выполнено специализированными приложениями, которые могут реплицировать виртуальные машины и запускать реплики по запросу администратора. Помимо программного обеспечения для защиты данных, вам понадобятся хосты ESXi или Hyper-V (в зависимости от вашей среды), которые заранее подготовлены для запуска реплик виртуальных машин в случае сбоя исходных виртуальных машин.
На диаграмме ниже вы можете видеть два хоста, соединенных друг с другом через сеть. Виртуальные машины используют диски хостов. Исходные виртуальные машины работают на первом хосте, а реплики виртуальных машин, которые являются точными копиями исходных виртуальных машин на определенный момент времени, находятся на втором хосте в выключенном состоянии.
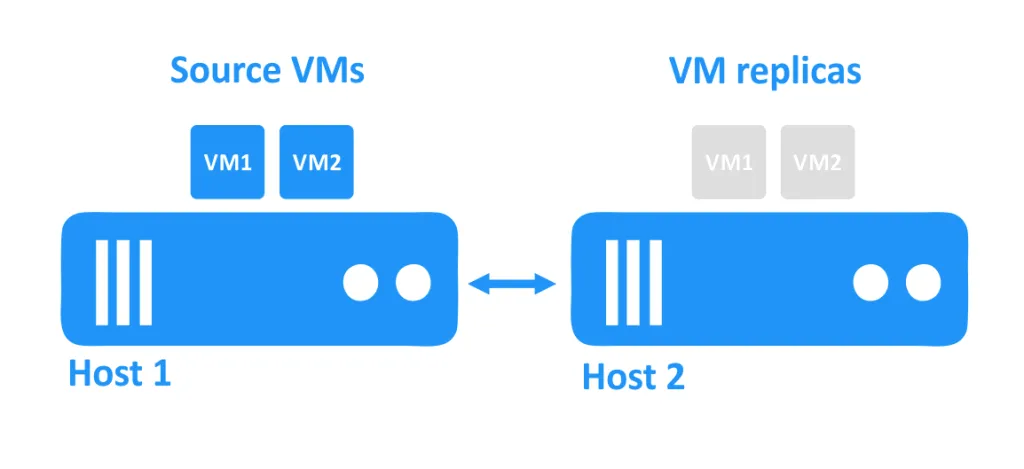
Когда один хост выходит из строя, виртуальные машины, работавшие на этом хосте, также становятся недоступными. Реплики виртуальных машин, находящиеся на другом хосте, затем включаются администратором.
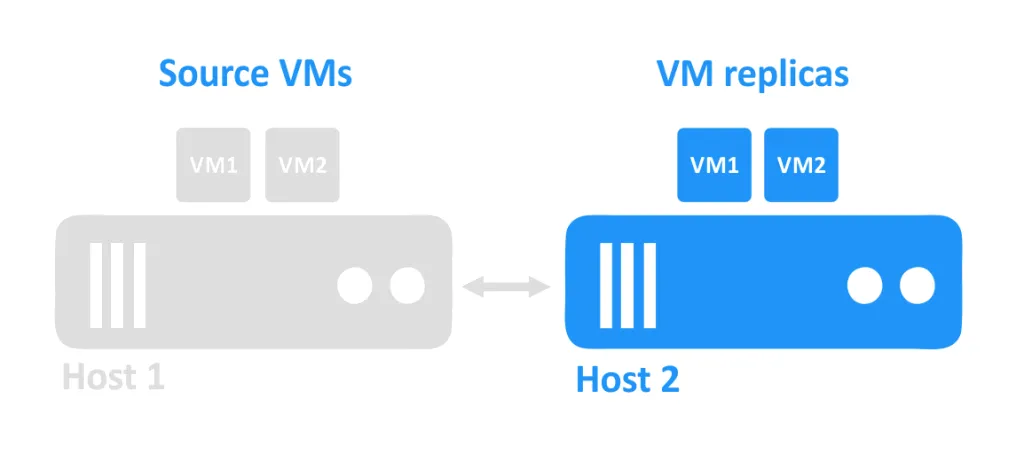
Требования к репликации виртуальных машин
Основные требования к репликации ВМ – это два или более узла и решение по репликации. Исходная ВМ, работающая на первом узле, реплицируется на второй узел. Реплика ВМ находится на втором узле.
Сценарии использования
Переключение на резервные копии ВМ может использоваться при отказах аппаратного или программного обеспечения. Отказы узлов ESXi или Hyper-V являются примером аппаратного сбоя. Примерами программного сбоя могут быть неудачные обновления, программные ошибки, вирусные атаки или случайное удаление файлов пользователем.
Преимущества
Основное преимущество переключения на резервную копию ВМ – это возможность переключения на удаленный сайт. При создании реплики ВМ данные, скопированные с исходной ВМ, могут быть переданы по сетевому соединению (с ограниченной полосой пропускания) на удаленный сайт. Удаленный сайт может находиться в соседнем офисе или на другом конце света. Реплика ВМ также может располагаться на основном производственном сайте.
Недостатки
Список недостатков переключения на резервные копии ВМ:
- Существует короткий период простоя между отказом и запуском реплики на втором узле.
- Переключение должно быть инициировано вручную.
- Данные, записанные с момента последней репликации, могут быть потеряны во время непланового переключения. Репликация ВМ часто не является процессом реального времени (синхронным), так как синхронная репликация создает значительную нагрузку на ресурсы. Репликация обычно производится через регулярные временные интервалы в зависимости от выбранных настроек.
- Настройки сети виртуальных машин должны (часто) изменяться при переключении на другой сайт. Сети виртуальных машин удаленного сайта могут отличаться от сетей основного сайта. Следовательно, IP-адреса также могут быть разными и должны быть проверены и изменены вместе с другими сетевыми настройками во время переключения.
Кластеризация против переключения виртуальных машин на основе репликации
| Переключение с кластеризацией | Переключение с использованием реплики | |
| Цель | Высокая доступность | Восстановление после катастрофы |
| Защита от | Только отказов оборудования | Отказов оборудования и программного обеспечения |
| Администрирование | Запускается автоматически | Запускается вручную |
| Продолжительность простоя (RTO) | Переключение происходит быстрее, поэтому простой виртуальной машины короткий (короткий RTO) | Переключение занимает больше времени, поэтому простой виртуальной машины длительный |
| Требования | Больше требований | Меньше требований |
| Цена решения | Решения на основе кластеризации обычно дороже | Решения на основе репликации более экономичны |
| Потеря данных (RPO) | Почти нулевая потеря данных (очень низкий RPO) | Потеря данных зависит от частоты репликации |
Совместное использование кластеров и реплик для отказоустойчивости виртуальных машин
Решения по отказоустойчивости кластеров и реплик иногда рассматриваются как альтернативы, но их можно использовать для дополнения друг друга. Давайте рассмотрим несколько примеров того, как использование обеих решений по отказоустойчивости может помочь защитить ваши виртуальные машины от отказов как на уровне сервера, так и на уровне сайта.
- Пример 1: Вы можете реплицировать виртуальные машины, работающие внутри кластера, на хост на удаленном сайте. Более того, вы можете реплицировать виртуальные машины, работающие внутри одного кластера, в другой кластер. Таким образом, если хост выйдет из строя, отказоустойчивый кластер сохранит работоспособность этих виртуальных машин. Если весь сайт переживет нарушение, то вы сможете переключиться на реплики виртуальных машин, хранящиеся на удаленном сайте.
- Пример 2: Вирус повредил файлы внутри некоторых виртуальных машин. Отказоустойчивый кластер не может защитить от таких сбоев. Но если у вас есть реплики виртуальных машин с несколькими точками восстановления, вы можете восстановить каждую виртуальную машину до момента времени до повреждения или удаления их файлов.
Использование решения NAKIVO для автоматического отказоустойчивого восстановления виртуальных машин VMware на реплику
NAKIVO Backup & Replication – это решение для резервного копирования и аварийного восстановления, которое может защищать виртуальные машины, работающие в кластере, реплицировать виртуальные машины, переключаться на реплики и оркестрировать сложные последовательности аварийного восстановления. Кластеры, а также автономные хосты ESXi или Hyper-V поддерживаются в качестве исходных и конечных точек для репликации. Решение автоматически отслеживает хост, на котором находится виртуальная машина, чтобы реплицировать эту виртуальную машину. Это полезно, потому что виртуальные машины могут мигрировать с одного хоста на другой в пределах кластера после аварийных событий или событий балансировки нагрузки (кластер обычно настраивается в сочетании с балансировкой нагрузки). Поэтому программное обеспечение, которое вы используете для репликации виртуальной машины из кластера, должно уметь отслеживать хост, на котором находится виртуальная машина.
Решение NAKIVO может автоматически изменять настройки сети виртуальной машины при аварийном переключении; просто используйте функции Network Mapping и Re-IP при настройке задания репликации или аварийного переключения.
Рассмотрим пример Автоматического переключения виртуальной машины (с Network Mapping и Re-IP) в NAKIVO Backup & Replication. Начнем с создания реплики виртуальной машины.
Настроим репликацию, необходимую для аварийного переключения виртуальной машины
На панели управления заданиями нажмите Создать > Задание репликации VMware vSphere, если у вас есть виртуальная среда VMware. Обратите внимание, что вы можете создать задание репликации для виртуальной машины Microsoft Hyper-V или экземпляра Amazon EC2 таким же образом.
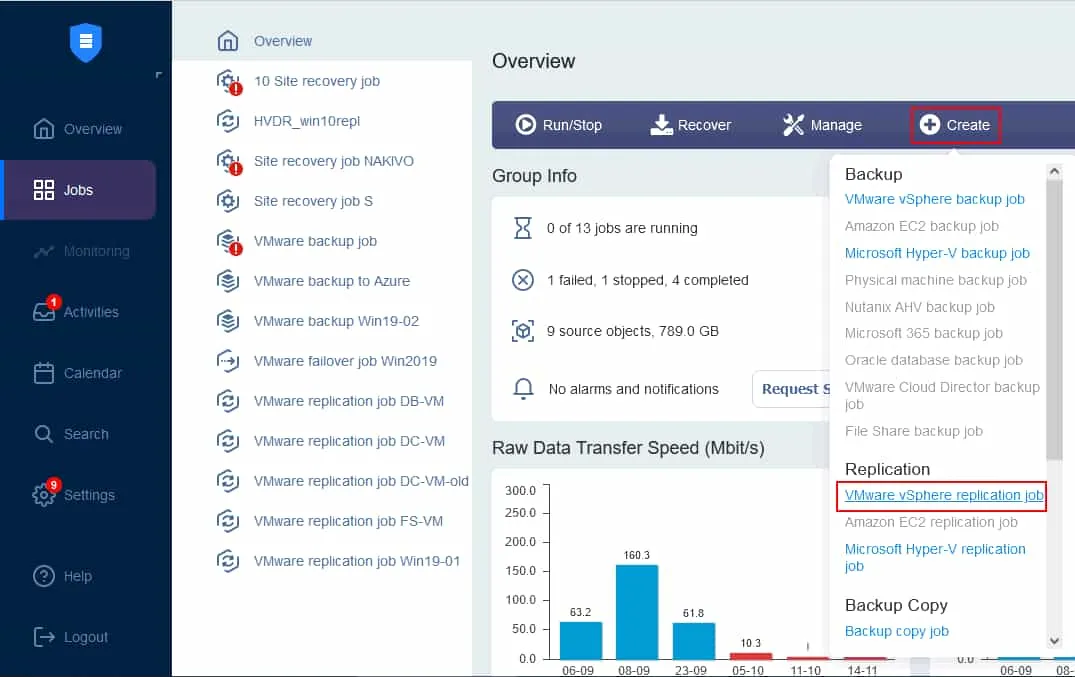
Запущен мастер задания репликации.
- Выберите виртуальные машины, которые вы хотите реплицировать. В этом примере виртуальная машина Server2019, на которой запущена операционная система Windows Server 2019 в качестве гостевой, будет реплицирована. Нажмите Далее.
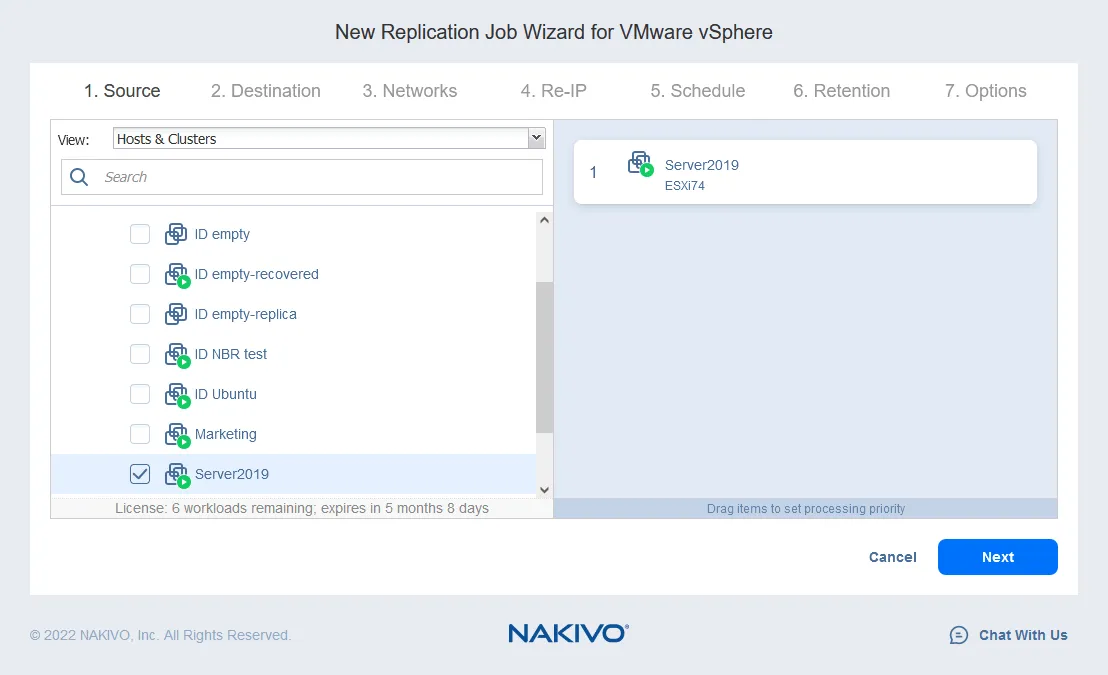
- Выберите хост назначения для запуска реплики виртуальной машины (10.10.10.90 в нашем случае). Выберите хранилище данных, примонтированное к выбранному хосту для размещения файлов виртуальной машины. Нажмите Далее.
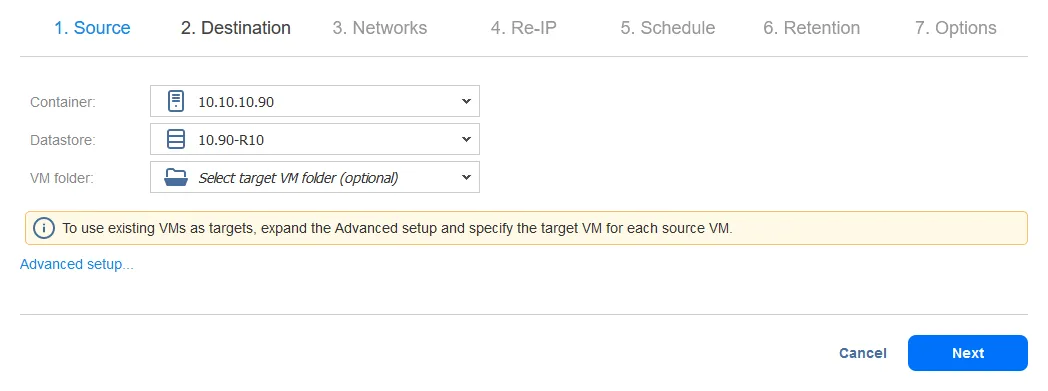
- Вы можете настроить сопоставление сети и параметры Re-IP при настройке задания репликации или задания переключения на резервный режим. В этом руководстве сопоставление сети и Re-IP будут настроены позже, при настройке задания переключения на резервный режим. Таким образом, вы можете пропустить этот шаг на данный момент и просто нажать Далее.
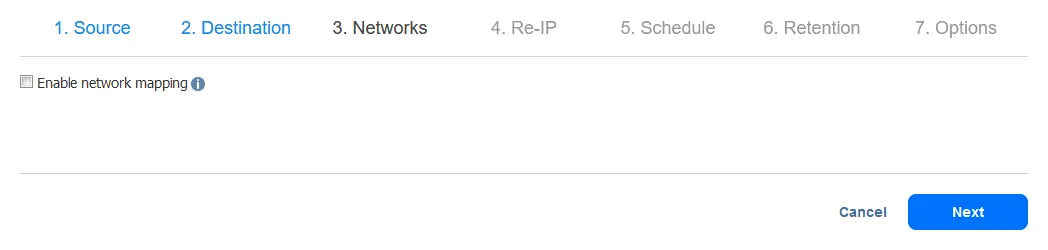
- Перенастройка IP будет объяснена во время настройки задания аварийного переключения виртуальной машины в этом руководстве. Нажмите Далее.
- Выберите настройки планирования. Нажмите Далее, когда закончите.
- Установите настройки удержания. Помните, что вы можете настроить политику удержания “дед-отец-сын” на этом этапе. Нажмите Далее.
- Выберите параметры задания репликации и нажмите кнопку Завершить или кнопку Завершить и запустить. Подождите, пока будет создана реплика.
Настройка аварийного восстановления ВМ
Теперь, когда у вас есть созданная реплика ВМ, вы можете выполнить аварийное восстановление ВМ на эту реплику.
На домашней странице в панели инструментов щелкните Восстановление > Полное восстановление VMware (аварийное восстановление реплики ВМ). Откроется Мастер нового задания аварийного восстановления.
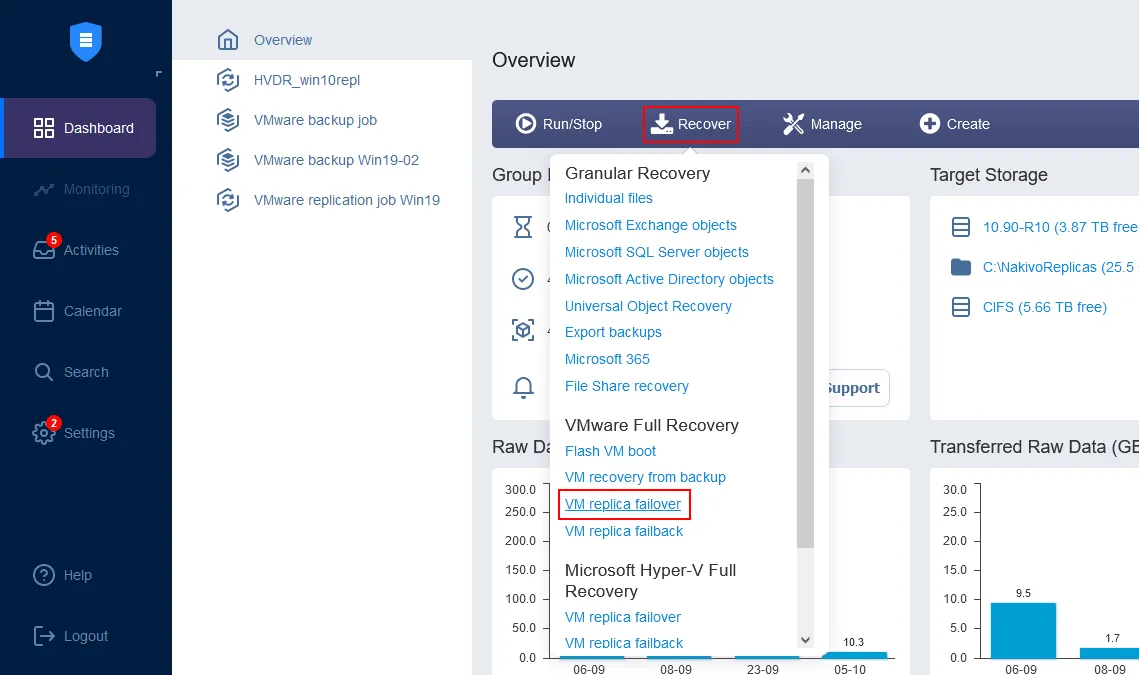
- В левой панели выберите реплику ВМ для использования при аварийном восстановлении. В этом руководстве выбрана Server2019-replica, которая была только что создана. В правой панели выберите точку восстановления. По умолчанию в решении выбрана последняя точка восстановления. Щелкните Далее.
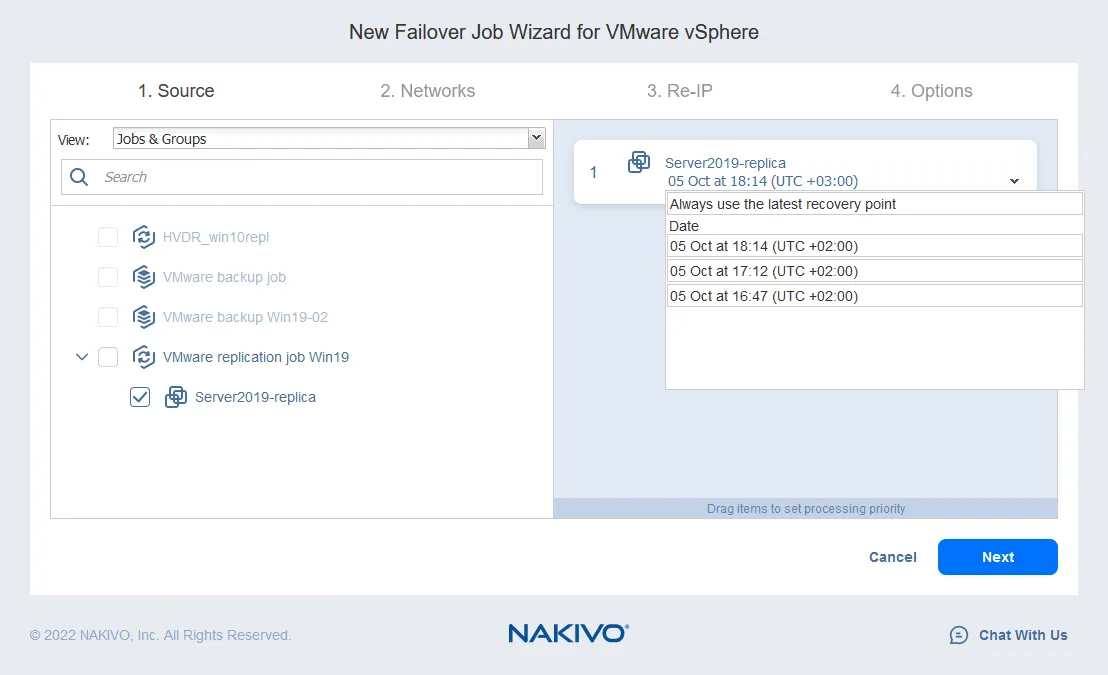
- Картирование сети помогает вам изменить сеть, к которой подключена виртуальная машина. Исходный и целевой хосты ESXi, вероятно, имеют разные настройки виртуального коммутатора. Поскольку реплика виртуальной машины является точной копией исходной виртуальной машины, виртуальные сети, к которым подключена исходная виртуальная машина, сохраняются в реплике виртуальной машины.
Как правило, вы должны проверить настройки сети реплики виртуальной машины и вручную изменить сеть. NAKIVO Backup & Replication может автоматически сопоставить исходную сеть с целевой сетью. Вам просто нужно настроить Картирование сети при настройке задания репликации или переключения на резервный канал.
- Для включения Картирования сети установите флажок. Если вы ранее создали правило картирования сети, вы можете нажать Добавить существующее сопоставление. Если нет правил картирования сети, нажмите Создать новое сопоставление.
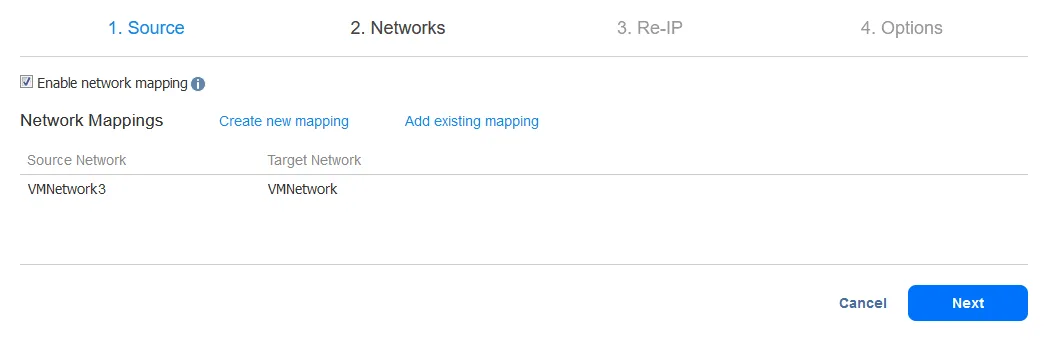
-
Чтобы создать новое правило картирования сети, выберите исходную сеть и целевую сеть. Исходная сеть – это сеть, к которой подключена исходная виртуальная машина. Целевая (целевая) сеть – это сеть, к которой должна быть подключена реплика виртуальной машины.
Примечание: Имя сети виртуальной машины не совпадает с IP-адресом или сетевым адресом.
Нажмите Сохранить, чтобы сохранить правило картирования сети, а затем нажмите Далее, чтобы продолжить настройку.
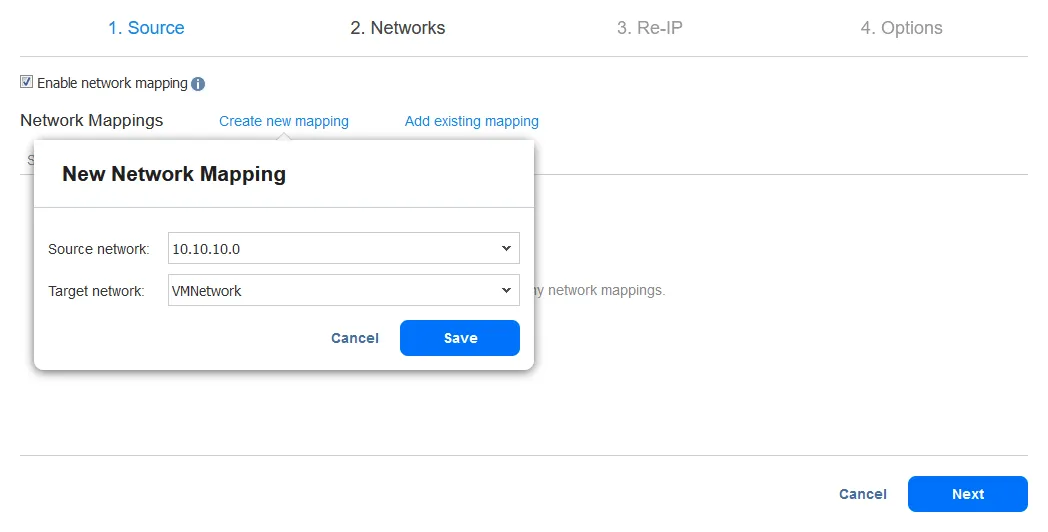
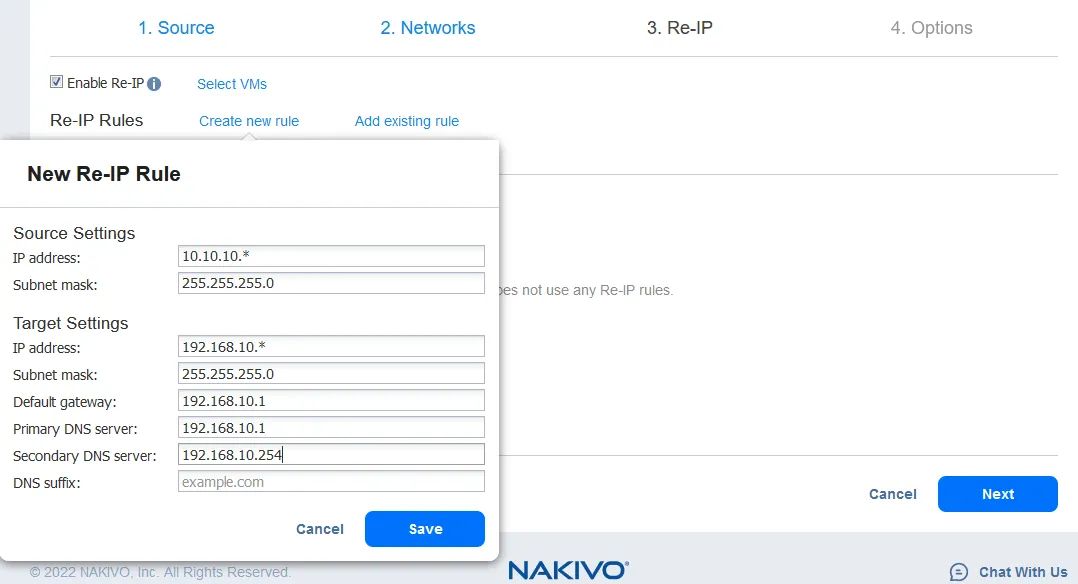
- Функция Re-IP позволяет изменить настройки IP реплики виртуальной машины. Она может использоваться для статических IP-адресов. Установите флажок Включить Re-IP, если хотите включить эту опцию, а затем создайте правило Re-IP или добавьте существующее правило. Нажмите Создать новое правило, если ранее правила не были созданы. Появится всплывающее меню.
- Для включения Картирования сети установите флажок. Если вы ранее создали правило картирования сети, вы можете нажать Добавить существующее сопоставление. Если нет правил картирования сети, нажмите Создать новое сопоставление.
- Настройки исходной виртуальной машины – это IP-адрес и сетевая маска, которые необходимо изменить.
Целевые настройки – это настройки, которые должны применяться для реплики виртуальной машины при переключении на резервный канал. В этом примере символ [*] покрывает последний октет. [*] означает любое число от 1 до 254. Если исходные IP-адреса, например, 10.10.10.1, 10.10.10.96 и 10.10.10.222, то целевые адреса будут соответственно 192.168.10.1, 192.168.10.96 и 192.168.10.222. Последний октет IP-адреса сохраняется.
Нажмите Сохранить, чтобы сохранить правило Re-IP и продолжить.
После добавления правила Re-IP ваш экран должен выглядеть так: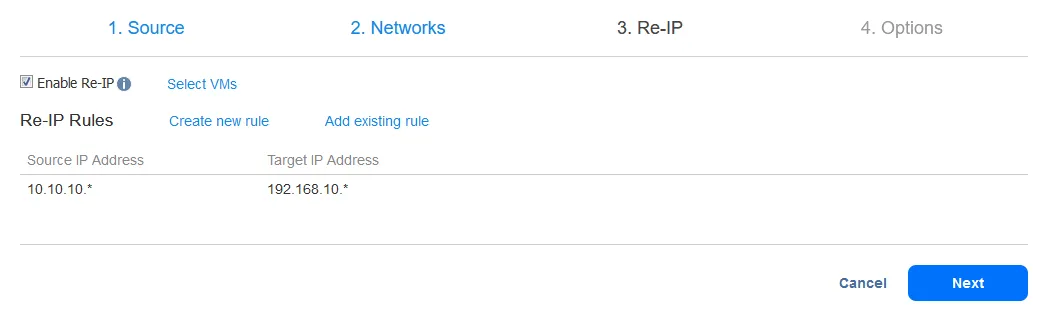
Теперь выберите виртуальные машины, для которых должны применяться правила Re-IP. В этом примере задание переключения на резервный канал содержит только одну реплику виртуальной машины, поэтому выберите один флажок.
Затем выберите учетные данные для каждой виртуальной машины. Нажмите Управление учетными данными > Добавить учетные данные, чтобы добавить новые учетные данные. Добавленные учетные данные можно выбрать из выпадающего списка.
Примечание: Учетные данные необходимы для доступа к настройкам сети операционной системы внутри виртуальной машины и примен