













ビジネスの継続性を確保するために、VMの可用性は重要です。ビジネスやミッションクリティカルなVMで実行されているサービスが利用できなくなると、企業はお金と顧客の信頼を失う可能性があります。障害発生後すぐにVMの可用性を復元するためには、適切なフェイルオーバー技術を使用する必要があります。
VMレプリカへのフェイルオーバーは、災害復旧の一部であり、通常のワークフローに最小限の影響でデータと操作を復元することができます。VMフェイルオーバーのプロセスは、組織のビジネス継続性および災害復旧(BCDR)に記載されるべきです。では、より詳細にVMフェイルオーバーのタイプとユースケースを見てみましょう。
フェイルオーバーとは何ですか?
フェイルオーバーとは、プライマリシステムの障害発生後に、セカンダリシステム(場合によってはセカンダリロケーション)で仮想マシン(VM)を再開するプロセスです。セカンダリシステムにはビジネスオペレーションを維持するために必要なすべてのデータが含まれています。ここでのシステムとは、サーバー、データベース、仮想マシンなどを指します。
仮想環境では、2つの一般的なフェイルオーバーメソッドがあります:
- VMレプリカの使用(通常、別の仮想化サーバーに配置されています)は、プライマリVMが失敗した場合にフェイルオーバーを実行するために使用されます
- フェイルオーバークラスターの使用(レプリケーションは不要)
フェイルオーバーは、バックアップからの復旧よりもワークロードを復元する時間が短くなり、その結果、より低い復旧時間目標(RTO)を達成できます。ただし、VM レプリケーションまたはクラスタリングを使用しても、VM バックアップを作成する必要がなくなるわけではありません。バックアップ(通常は圧縮されています)は、古い復旧ポイントからデータを復元する必要がある場合に便利です。
レプリケーションベースの災害復旧のための基本的なVMフェイルオーバー用語について説明しましょう。
フェイルオーバーグロッサリー
- 障害:システムのクラッシュ、停電、ネットワークの問題、ランサムウェア攻撃などによるハードウェアまたはソフトウェアの問題。
- プライマリシステム:本番環境でライブオペレーションを実行しているシステム。
- セカンダリシステム:定期的にプライマリシステムのコピーで更新される冗長なスタンバイシステム。セカンダリシステムは、オンプレミスまたはリモートの場所に配置されることがあります。
- レプリケーション:VMフェイルオーバーの準備のための必須プロセス。レプリケーションは、特定の時点のプライマリVMの正確なコピー、すなわちレプリカを作成します。
- VMフェイルバック:フェイルバックは、インシデントが解決された後にレプリカVMからプライマリシステムに戻るプロセスです。
フェイルオーバータイプ
フェイルオーバーには3つのタイプがあります:
- A planned failover is used for scheduled migrations of workloads from one system/site to another. Use cases include performing maintenance on the primary system, electrical works performed at the production site, and expected disaster scenarios. For example, a weather alert about a tornado may require a planned failover to ensure availability.
- 未計画のフェイルオーバーは、予期せぬ障害が発生し、重要なVMまたはプライマリサイト全体がオフラインになった場合に実行されるフェイルオーバーです。障害は自然災害、事故(停電)、マルウェア攻撃、またはその他の事故によって引き起こされる可能性があります。未計画のフェイルオーバーでは、ホストとレプリカは事前に準備されている必要があります。
- A test failover, as the name suggests, is used for testing purposes. Testing scenarios can include rehearsing unplanned failover scenarios to ensure that
フェイルオーバーのシーケンス
VMのフェイルオーバー中、アクションのフェイルオーバーシーケンスとVMの起動順序は、ワークフローの成功した再開を保証するために重要です。これらは、組織の災害復旧計画の開発段階で定義される必要があります。シーケンスには、異なるVMで実行されるさまざまなサービス間の依存関係を捉える必要があります。
たとえば、VMで実行される一部のサービスとアプリケーションの認証は、別のVMで実行されているActive Directoryを使用している場合があります。データベースサーバーは最初のVMで実行され、アプリケーションサーバーは2番目で実行され、Webサーバーは3番目で実行される可能性があります。
Active Directoryサーバーを使用するサービスを持つVMは、最初に起動する必要があります。次に、認証にActive Directoryを使用するサービスを持つVMが起動できます。アプリケーションサーバーのVMはデータベースサーバーのVMよりも先に起動する必要があります。なぜなら、アプリケーションサーバーはデータベースに接続するからです。データベースサーバーとアプリケーションサーバーのVMが起動した後、WebサーバーのVMを起動できます。
メインフェイルオーバーソリューション
仮想環境で使用される主要なソリューションは次のとおりです:
- フェイルオーバークラスタリング
- VMレプリカを使用したフェイルオーバー
それぞれを考えてみましょう。
ソリューション1. フェイルオーバークラスタリング
A failover cluster is a group of at least two servers or nodes that are configured to take over workloads when one node is down or unavailable. Clustering is an enterprise-class automated solution that can be used for the most important, business-critical VMs. Microsoft Hyper-V offers a Failover Cluster made up of several Hyper-V hosts. VMware’s equivalent is a High Availability cluster, which is made up of ESXi hosts.
最初の図では、両方のホスト(ノードとも呼ばれます)が正常に機能しているクラスターが表示されます。VMはホスト上で実行され、VMファイルは両方のホストからアクセスできる共有ストレージに配置されています。
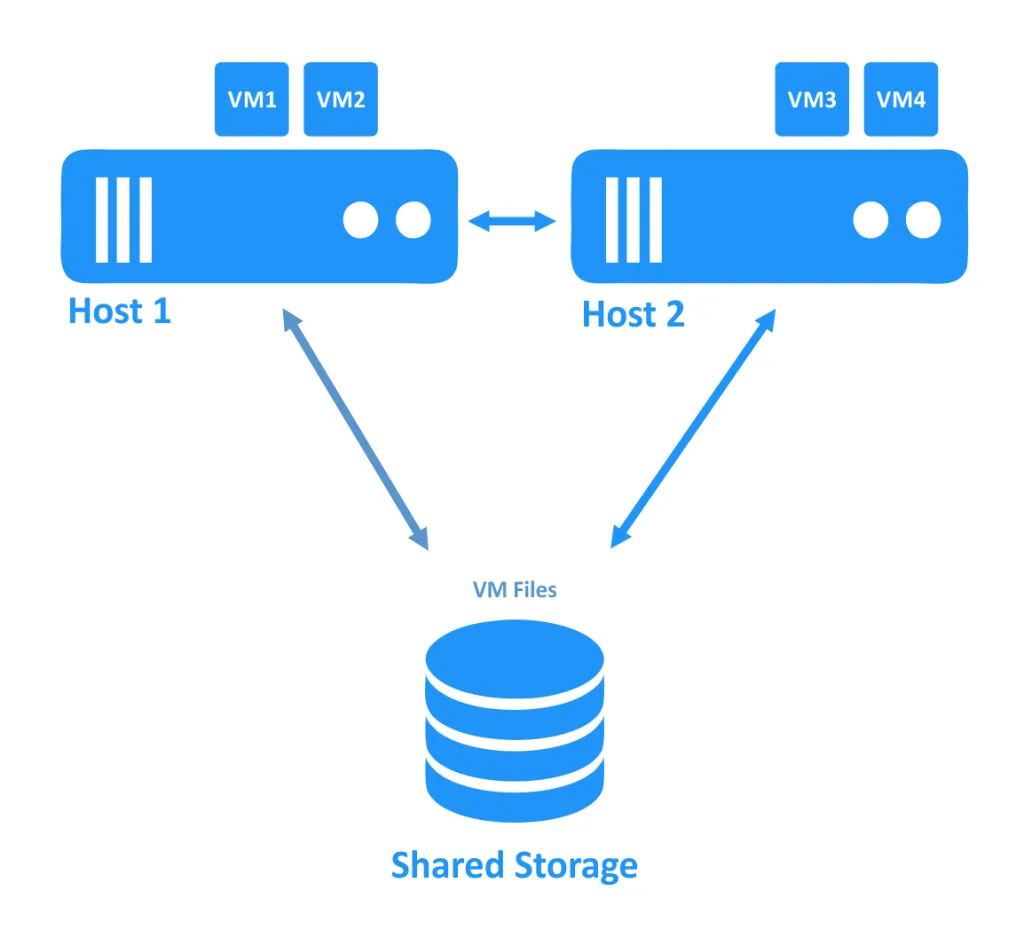
ホストの1つがダウンしたとき、オフラインのノードで実行されていたVMへの接続の所有権が、オンラインの別のノードに移動されます。これがフェイルオーバープロセスです。高可用性のVMは再起動が必要な場合があります。
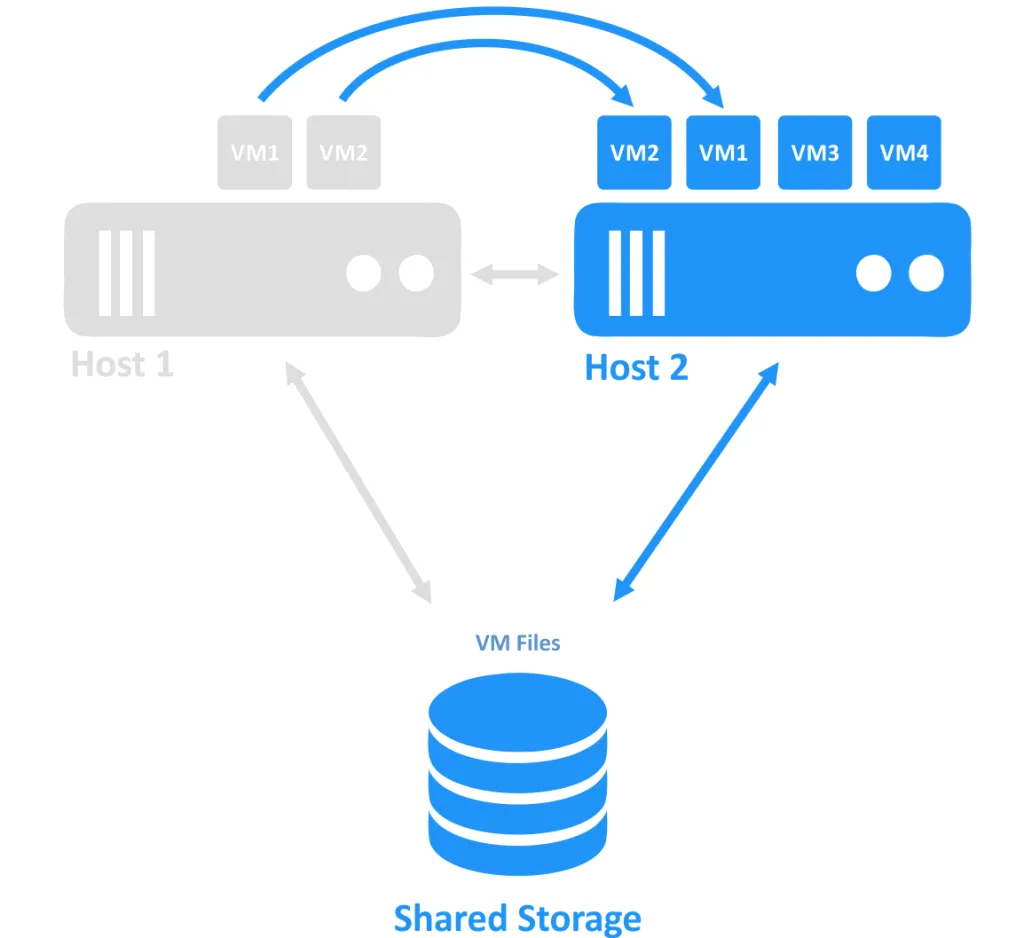
フェイルオーバークラスタリングの要件
フェイルオーバークラスタを構築するには、次の要件を満たす必要があります:
- 共有ストレージは、低遅延の専用高速ネットワークに接続されたホストに接続されます。複数のホストが同時にストレージ上のデータにアクセスできるように、クラスタ化されたファイルシステムを使用する必要があります。
- 仮想マシンが実行されているホストは、同じハードウェア、または少なくとも同じファミリーのハードウェアを持っている必要があります。プロセッサは、フェイルオーバー中に1つのホストから別のホストに移行した後にVMが適切に実行されるための互換性を確保するために、同じ命令セットをサポートする必要があります。
- A high-speed redundant network with low latency. There should be multiple, separate cluster networks, that is, a cluster must have different networks for storage, management, VM migration, connection of hosts amongst each other, etc.
ユースケース
フェイルオーバークラスタは、サーバの障害からVMを回復し、重要なVMの高可用性を提供するために使用されます。クラスタ内のノードの1つが障害を起こした場合、障害が発生したホストで実行されていたVMは、他の正常なホストに移行(フェイルオーバー)します。設定に応じて、障害が解消されると、フェイルオーバーしたVMは通常、障害が発生する前に実行されていたホストに再移行することができます。
利点
A failover cluster has advantages that provide strong protection:
- A failover cluster provides automatic VM failover. You don’t need to start the failed VMs manually on other hosts.
- フェイルオーバー時に、データ損失はほぼゼロです。ダウンタイムは通常、VM、オペレーティングシステム(OS)、およびVMで実行されているソフトウェアの読み込みにかかる時間に制限されます。
- VMware High Availabilityクラスタに含まれるフォールト トレランス機能は、ダウンタイムやデータ損失なしでVMのフェイルオーバーを保証します。
欠点
A failover cluster does not protect against:
- VMのソフトウェア障害。ソフトウェアのバグやウイルスによって、VM内でシステムクラッシュが発生する可能性があります。
- VM内のファイルの誤削除。
- 共有ストレージの障害。共有ストレージが障害を起こすと、クラスターも障害を起こします。共有ストレージはクラスターの重要な構成要素であり、クラスター内のVMに属する仮想ディスクは共有ストレージに保存されています。
- A disaster that makes the whole physical site unavailable.
フェイルオーバークラスターについての詳細情報は、VMwareクラスタリングに関する完全ガイドを参照してください。
ソリューション2。VMレプリカを使用したフェイルオーバー
VMレプリカに依存したVMフェイルオーバーは、管理者の指示に従ってVMを複製し、レプリカを起動できる専用アプリケーションによって実行されます。データ保護ソフトウェアに加えて、ソースVMが障害を起こしたときにVMレプリカを実行するために事前に準備されたESXiまたはHyper-Vホスト(環境に応じて)が必要です。
以下の図では、ネットワークを介して互いに接続された2つのホストが表示されています。VMはホストのディスクを使用しています。ソースVMは最初のホストで実行され、特定の時点でのソースVMの正確なコピーであるVMレプリカは、電源がオフになっている状態で2番目のホストに配置されています。
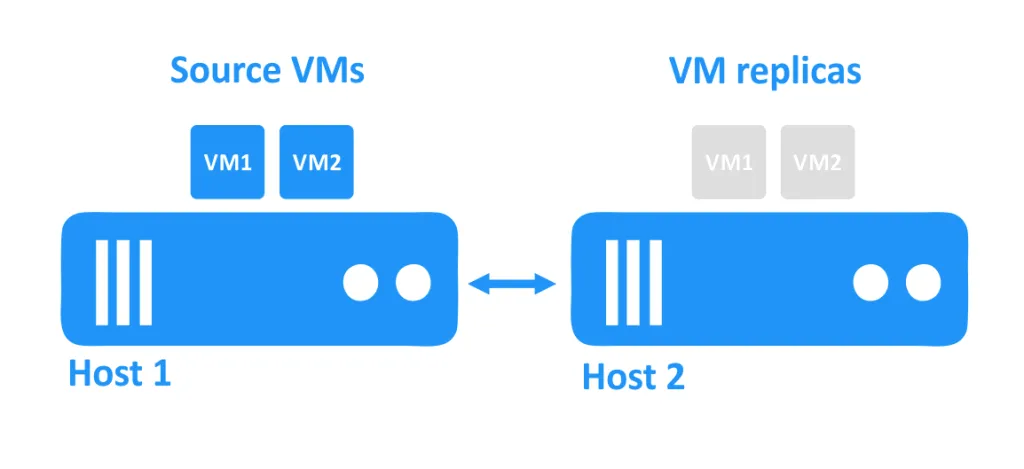
1つのホストがダウンすると、そのホストで実行されていたVMにもアクセスできなくなります。別のホストにあるVMレプリカは、管理者によって電源が入れられます。
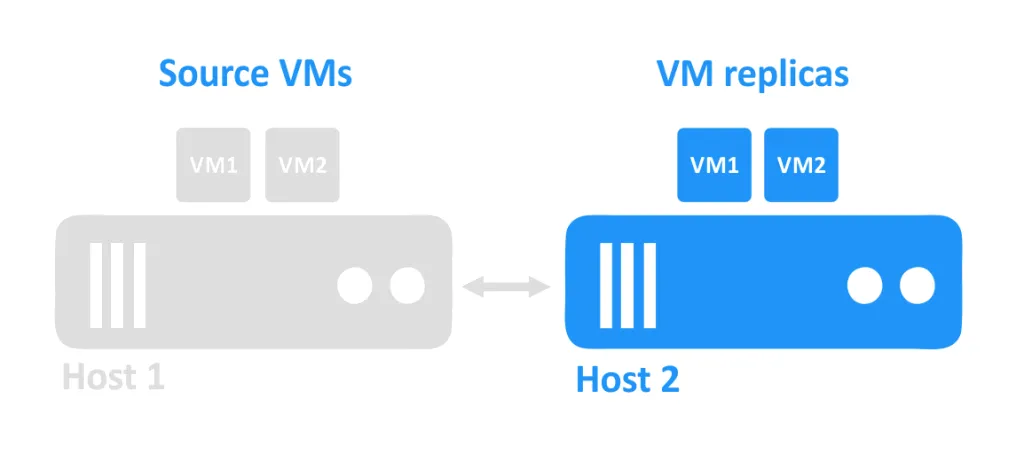
VMレプリケーションの要件
VMレプリケーションの基本要件は2つ以上のホストとレプリケーションソリューションです。最初のホストで実行されているソースVMは、2番目のホストにレプリケーションされます。VMレプリカは2番目のホストにあります。
ユースケース
VMレプリカを使用したフェイルオーバーは、ハードウェアまたはソフトウェアの障害が発生した場合に使用できます。ESXiまたはHyper-Vホストの障害はハードウェアの障害の例です。ソフトウェアの障害の例には、失敗したアップデート、ソフトウェアのバグ、ウイルス攻撃、またはユーザーによるファイルの誤削除が挙げられます。
利点
VMフェイルオーバーの主な利点は、リモートサイトへのフェイルオーバーの可能性です。VMレプリカが作成されている間、ソースVMからコピーされたデータは、ネットワーク接続(帯域幅制限付き)を介してリモートサイトに送信されることができます。リモートサイトは近くのオフィスにあるか、世界の反対側にあるかもしれません。VMレプリカは、通常、プライマリプロダクションサイトにも配置される場合があります。
欠点
VMレプリカを使用したフェイルオーバーの欠点の一覧:
- 障害と2番目のホストでのレプリカの開始との間に短いダウンタイムがあります。
- フェイルオーバーは手動で開始する必要があります。
- 前回のレプリケーション以降に書き込まれたデータは、計画外のフェイルオーバー中に失われる可能性があります。VMレプリケーションは、リアルタイム(同期)ではないことが多く、同期レプリケーションはリソースに大きな負荷をかけるためです。レプリケーションは通常、選択した設定に応じて定期的な時間間隔で実行されます。
- VMのネットワーク設定は、別のサイトにフェイルオーバーする際によく変更される必要があります。リモートサイトのVMネットワークは、プライマリサイトのネットワークと異なる場合があります。したがって、IPアドレスも異なる可能性があり、フェイルオーバー時に他のネットワーク設定と一緒に確認および変更する必要があります。
クラスタリング vs レプリケーションベースのVMフェイルオーバー
| クラスタリングによるフェイルオーバー | レプリカを使用したフェイルオーバー | |
| 目的 | 高可用性 | 災害復旧 |
| 保護対象 | ハードウェア障害のみ | ハードウェアおよびソフトウェア障害 |
| 管理 | 自動起動 | 手動起動 |
| ダウンタイム期間(RTO) | フェイルオーバーが速く、したがってVMのダウンタイムが短い(短いRTO) | フェイルオーバーに時間がかかり、したがってVMのダウンタイムが長い |
| 要件 | より多くの要件 | より少ない要件 |
| ソリューション価格 | クラスタリングソリューションは通常、より高価です | レプリケーションソリューションは費用対効果が高い |
| データ損失(RPO) | ほぼゼロのデータ損失(非常に低いRPO) | データ損失はレプリケーションの頻度に依存する |
クラスターとレプリカの組み合わせによるVMフェイルオーバー
クラスターとレプリカのフェイルオーバー解決策は、時には代替手段と見なされることがありますが、お互いを補完するために使用することができます。両方のフェイルオーバー解決策を使用することで、サーバーレベルおよびサイトレベルの障害に対してVMを保護する方法の例を見てみましょう。
- 例1:クラスター内で実行されているVMをリモートサイトのホストにレプリケートすることができます。さらに、1つのクラスター内で実行されているVMを別のクラスターにレプリケートすることもできます。したがって、ホストが障害を起こした場合、フェイルオーバークラスターはこれらのVMをオンラインの状態に保ちます。サイト全体に障害が発生した場合は、リモートサイトに保存されているVMレプリカにフェイルオーバーできます。
- 例2:ウイルスがいくつかのVM内のファイルを破損させた場合、フェイルオーバークラスターではそのような障害を保護することはできません。しかし、複数のリカバリーポイントを持つVMレプリカがある場合、各VMをファイルが破損または削除される前の時点に復元することができます。
VMware VMフェイルオーバー用のNAKIVOソリューションを使用する
NAKIVO Backup&Replicationは、クラスタ内で実行されているVMを保護し、VMを複製し、レプリカにフェイルオーバーし、複雑なDRシーケンスをオーケストレートできるバックアップおよび災害復旧ソリューションです。クラスタだけでなく、スタンドアロンのESXiまたはHyper-Vホストも、レプリケーションのソースおよび宛先ポイントとしてサポートされています。このソリューションは、VMが存在するホストを自動的に追跡するため、そのVMを複製できます。これは、VMがフェイルオーバーイベントまたは負荷分散イベント(クラスタは通常、負荷分散と共に構成されます)の後に、クラスタ内のホストから別のホストに移行する可能性があるため便利です。そのため、クラスタからVMを複製するために使用するソフトウェアは、VMが存在するホストを追跡できる必要があります。
NAKIVOソリューションは、フェイルオーバー時にVMのネットワーク設定を自動的に変更できます。レプリケーションまたはフェイルオーバージョブを構成する際に、ネットワークマッピングおよびRe-IP機能を使用してください。
NAKIVO Backup&Replicationにおける自動VMフェイルオーバー(ネットワークマッピングおよびRe-IPを使用)の例を考えてみましょう。まず、VMレプリカを作成します。
VMフェイルオーバーに必要なレプリケーションの構成
ジョブダッシュボードで、作成をクリック>VMware vSphereレプリケーションジョブ(VMware仮想環境を使用している場合)。Microsoft Hyper-V VMまたはAmazon EC2インスタンスのためのレプリケーションジョブも同様に作成できることに注意してください。
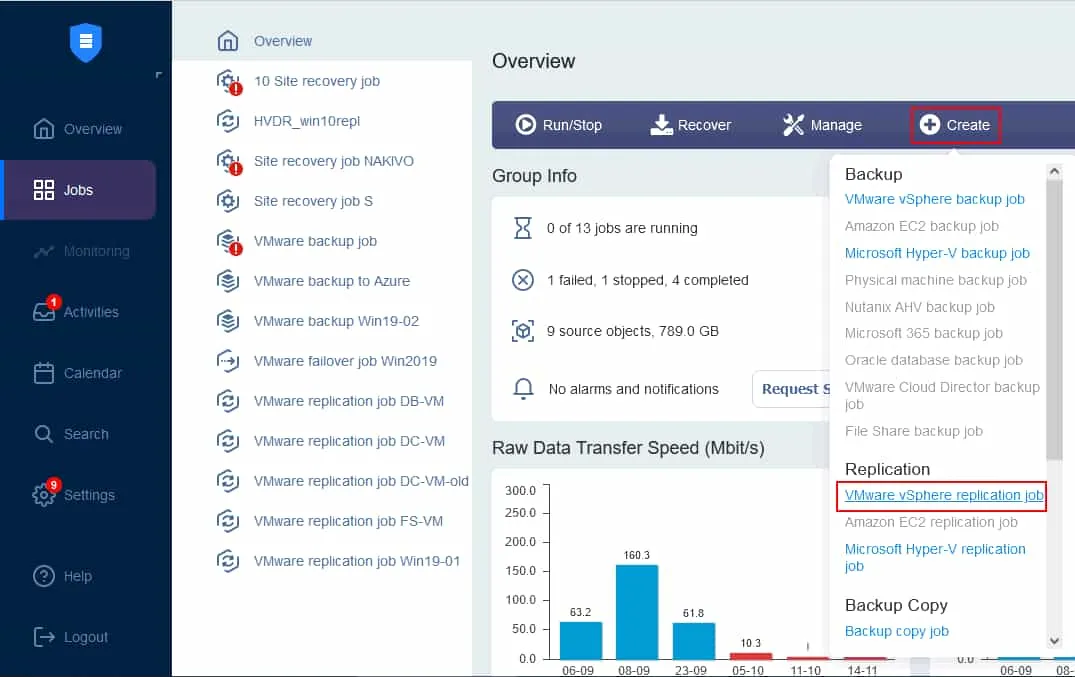
レプリケーションジョブウィザードが起動されます。
- 仮想マシンのレプリケーションを行いたいマシンを選択してください。この例では、ゲストオペレーティングシステムとしてWindows Server 2019を実行しているServer2019 VMがレプリケートされます。 次へをクリックしてください。
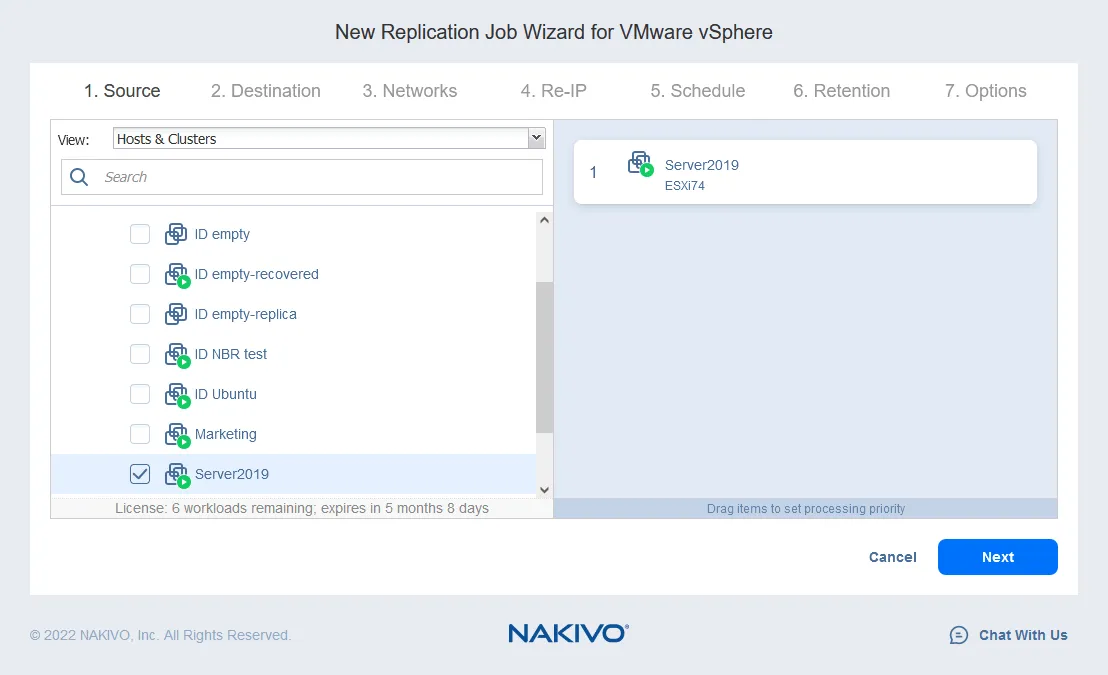
- VMレプリカが実行される宛先ホストを選択します(私たちの場合は10.10.10.90)。選択したホストにマウントされたデータストアを選択して、VMファイルの配置場所を選択します。 次へをクリックしてください。
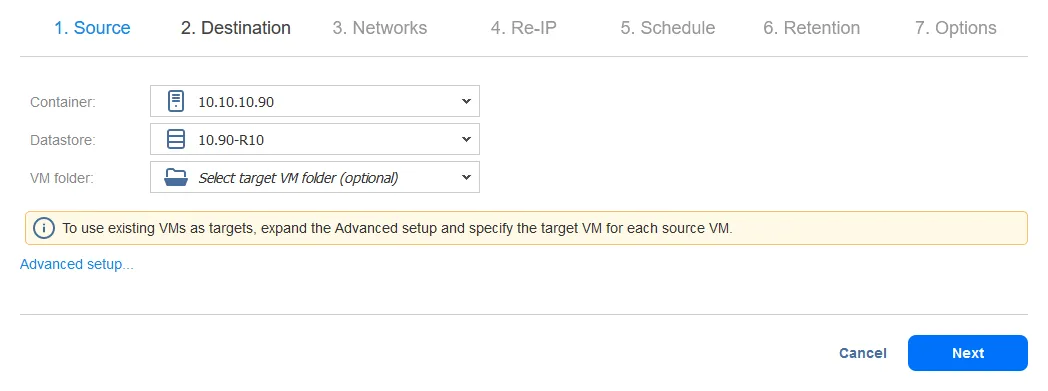
- レプリケーションジョブまたはフェイルオーバージョブを構成する際にネットワークマッピングとRe-IPオプションを設定できます。この手順では、ネットワークマッピングとRe-IPは後でフェイルオーバージョブが構成される際に設定されます。したがって、このステップは一旦スキップして、次へをクリックしてください。
- VMフェイルオーバージョブの構成中に、IPの再構成方法がこの手順で説明されます。次へをクリックしてください。
- スケジューリング設定を選択してください。完了したら次へをクリックしてください。
- 保持設定を設定してください。このステップで祖父-父-子の保持ポリシーを設定できることを覚えておいてください。次へをクリックしてください。
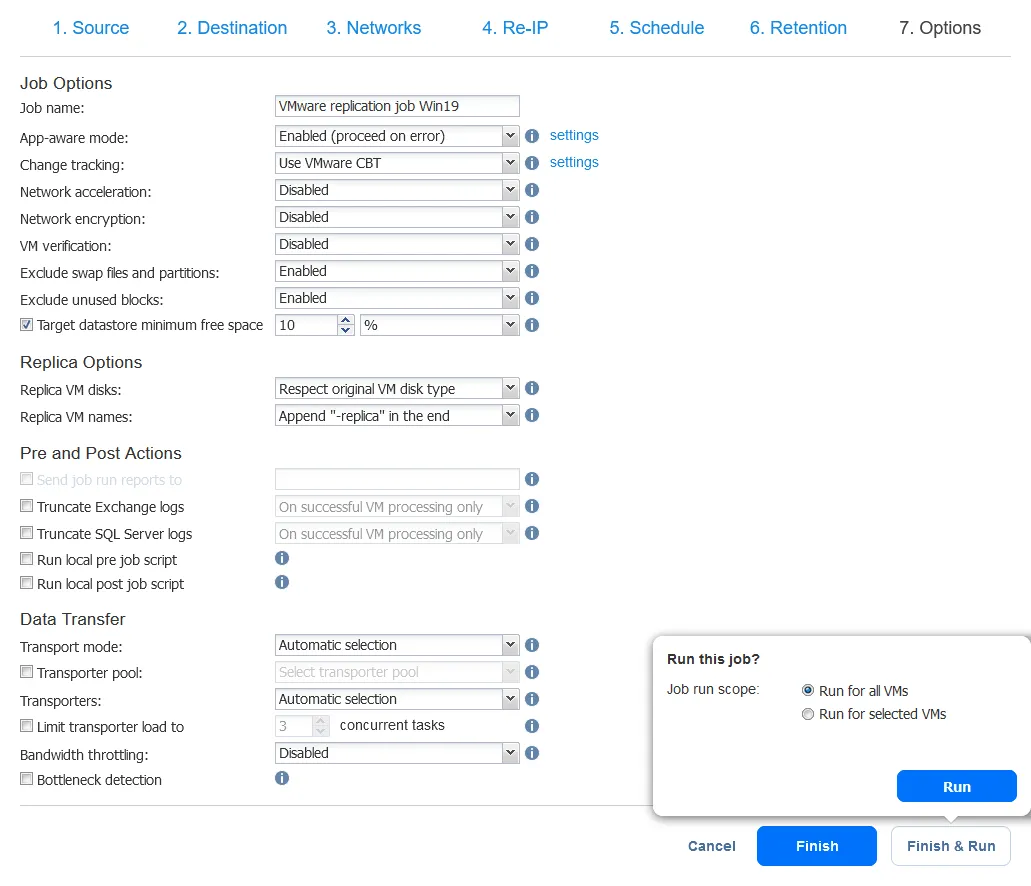
- レプリケーションジョブオプションを選択し、完了または完了&実行ボタンをクリックします。レプリカが作成されるのを待ちます。
VMフェイルオーバーの構成
VMレプリカが作成されたので、このレプリカへのVMフェイルオーバーを実行できます。
ダッシュボードのホームページで、リカバリ>VMwareフルリカバリ(VMレプリカフェイルオーバー)をクリックします。 新しいフェイルオーバージョブウィザードが開きます。
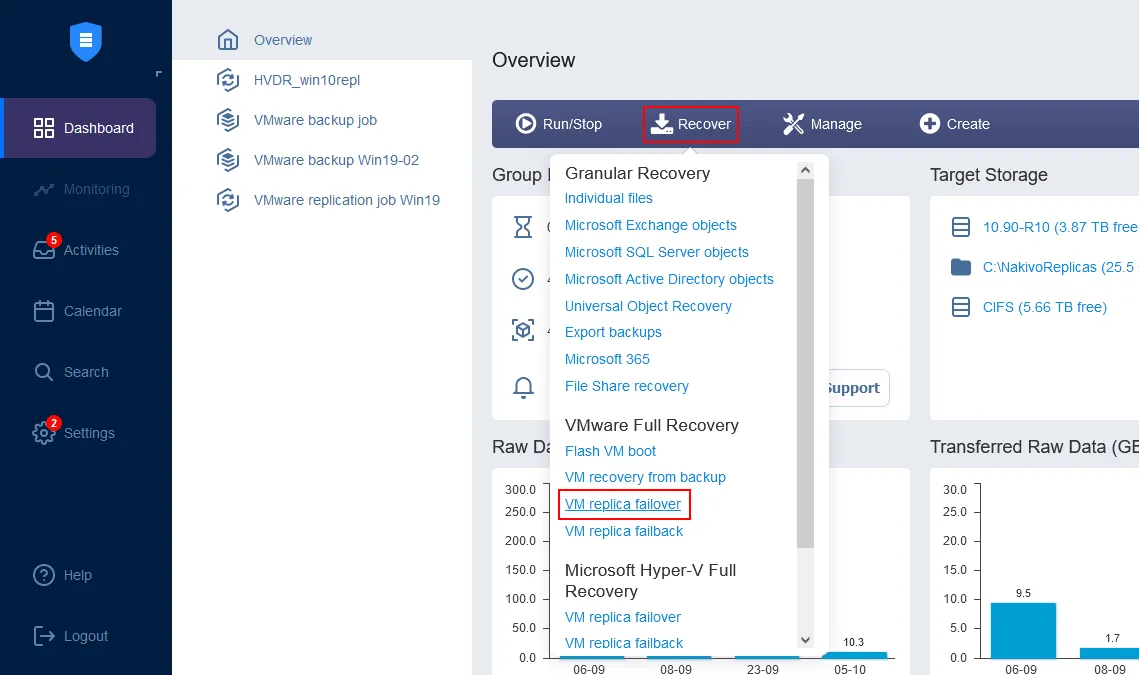
- 左ペインで、フェイルオーバーに使用するVMレプリカを選択します。この手順では、たった今作成されたServer2019-replicaが選択されています。右ペインで、リカバリポイントを選択します。ソリューションでは、最新のリカバリポイントがデフォルトで選択されています。 次へ をクリックします。
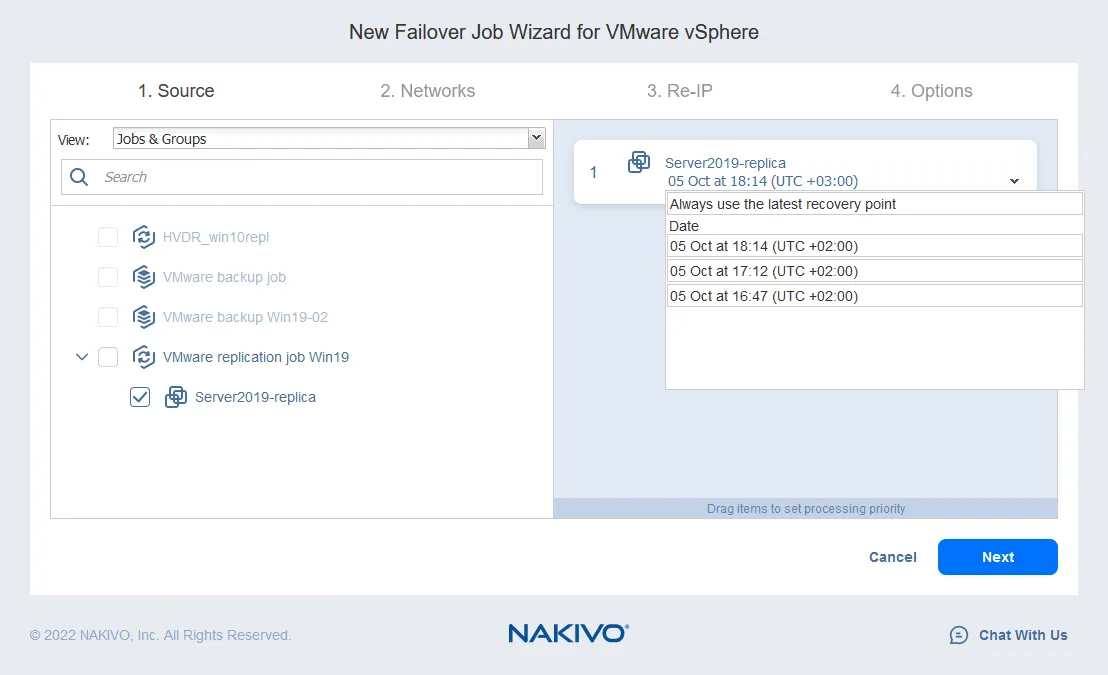
- ネットワークマッピングは、VMが接続されているネットワークを変更するのに役立ちます。ソースとなるESXiホストと宛先のESXiホストはおそらく異なる仮想スイッチの設定を持っています。VMレプリカはソースVMの正確なコピーであるため、ソースVMが接続されている仮想ネットワークはVMレプリカに保持されます。
通常、VMレプリカのネットワーク設定を確認し、手動でネットワークを変更する必要があります。NAKIVO Backup & Replicationでは、ソースネットワークを宛先ネットワークに自動的にマッピングできます。レプリケーションまたはフェイルオーバージョブを構成する際に、ネットワークマッピングを設定するだけです。
- ネットワークマッピングを有効にするには、チェックボックスを選択します。以前にネットワークマッピングルールを作成した場合は、既存のマッピングを追加をクリックできます。ネットワークマッピングルールがない場合は、新しいマッピングを作成をクリックします。
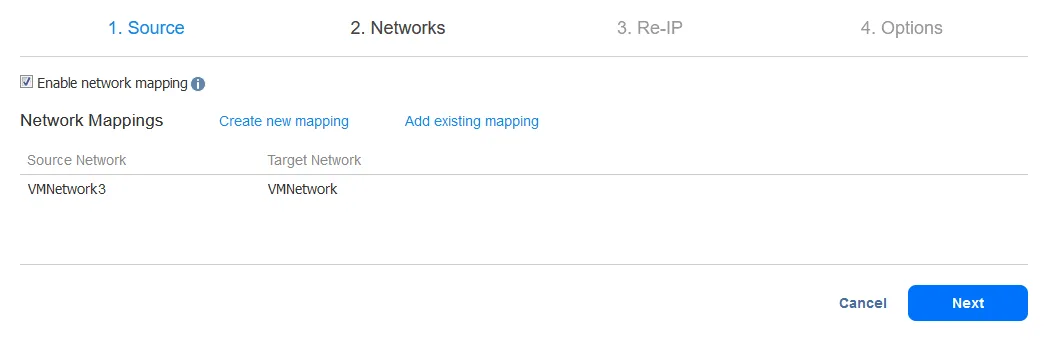
-
新しいネットワークマッピングルールを作成するには、ソースネットワークと宛先ネットワークを選択します。ソースネットワークはソースVMが接続されているネットワークです。宛先(ターゲット)ネットワークはVMレプリカが接続されるネットワークです。
注意: VMネットワークの名前はIPアドレスまたはネットワークアドレスと同じではありません。
保存をクリックしてネットワークマッピングルールを保存し、次へをクリックして構成を進めます。
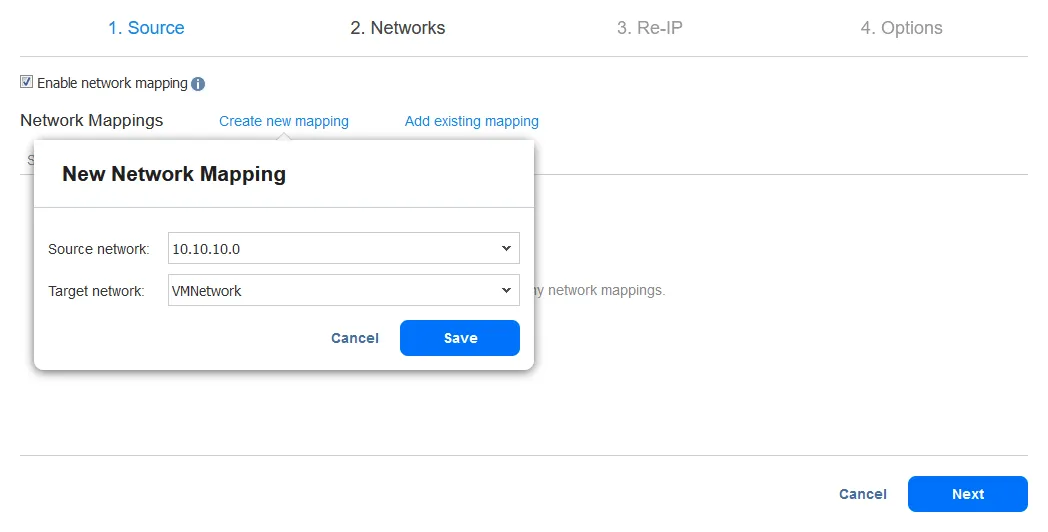
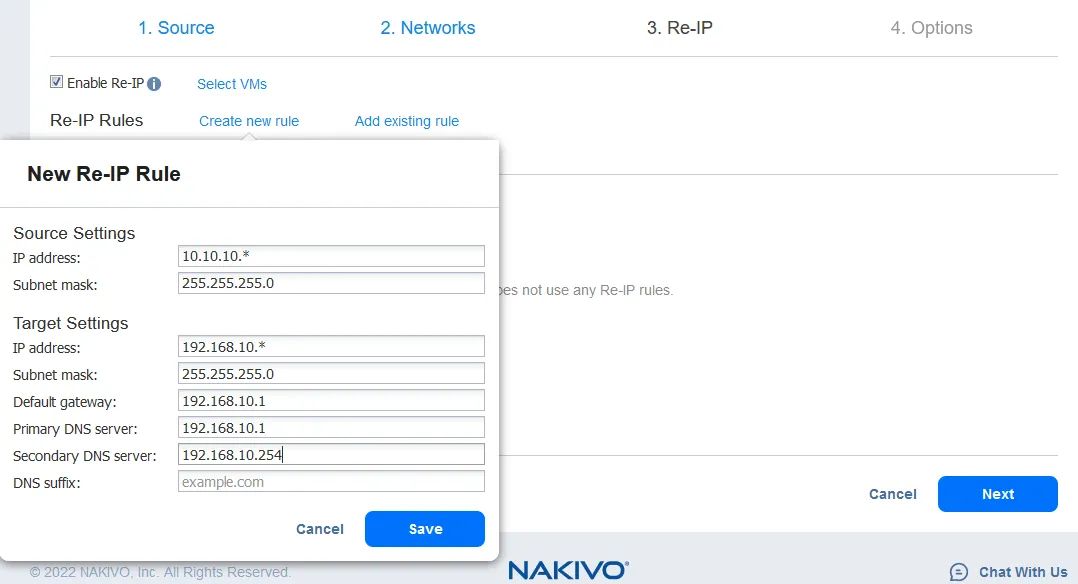
- Re-IP機能は、VMレプリカのIP設定を変更することができます。静的IPアドレスに使用できます。Re-IPを有効にするチェックボックスを選択してこのオプションを有効にし、次にRe-IPルールを作成するか、既存のルールを追加します。以前にルールが作成されていない場合は、新しいルールを作成をクリックします。ポップアップメニューが表示されます。
- ネットワークマッピングを有効にするには、チェックボックスを選択します。以前にネットワークマッピングルールを作成した場合は、既存のマッピングを追加をクリックできます。ネットワークマッピングルールがない場合は、新しいマッピングを作成をクリックします。
- ソースVMの設定は変更する必要のあるIPアドレスとネットワークマスクです。
ターゲット設定は、フェイルオーバーが発生した場合にVMレプリカに適用される設定です。この例では、[*]文字が最後のオクテットをカバーします。[*]は1から254までの任意の数を示します。たとえば、ソースIPアドレスが10.10.10.1、10.10.10.96、および10.10.10.222の場合、宛先アドレスはそれぞれ192.168.10.1、192.168.10.96、および192.168.10.222になります。IPアドレスの最後のオクテットは保持されます。
保存をクリックしてRe-IPルールを保存し、進みます。
Re-IPルールを追加した後、画面は以下のようになります: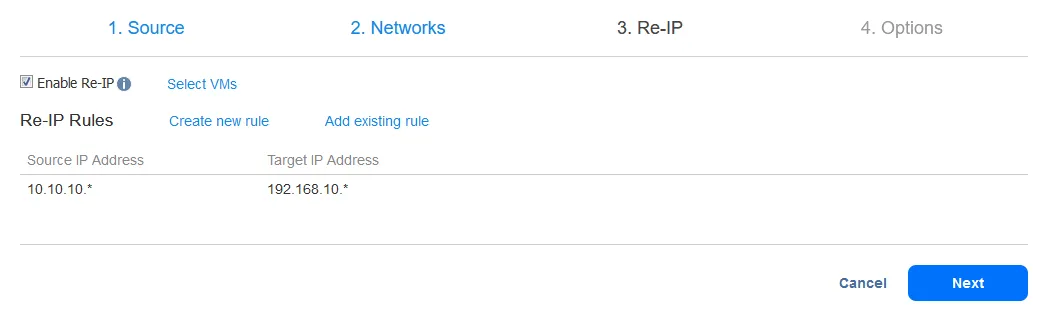
今度は、Re-IPルールを適用するVMを選択します。この例のフェイルオーバージョブにはVMレプリカが1つだけ含まれているため、1つのチェックボックスを選択します。
その後、各VMの資格情報を選択します。資格情報の管理をクリックして資格情報を追加し、新しい資格情報を追加します。追加された資格情報はドロップダウンリストから選択できます。
注意: 資格情報は、NAKIVO Backup