













A disponibilidade de VMs é essencial para garantir a continuidade dos negócios. Quando os serviços em execução em VMs críticas para os negócios e missão se tornam indisponíveis, as empresas podem perder dinheiro e a confiança dos clientes. Para restaurar a disponibilidade da VM imediatamente após uma falha, você deve usar técnicas apropriadas de failover.
O failover para uma réplica de VM pode ser parte da recuperação de desastres para restaurar dados e operações com interrupção mínima nos fluxos de trabalho regulares. O processo de failover da VM deve ser descrito no plano de continuidade de negócios e recuperação de desastres (BCDR) de uma organização. Vamos examinar os tipos de failover de VM e casos de uso com mais detalhes.
O que é um Failover?
Failover é o processo de retomar uma máquina virtual (VM) em um sistema secundário (e às vezes em um local secundário) após uma falha do sistema primário. O sistema secundário contém todos os dados necessários para manter as operações comerciais. Um sistema, neste contexto, pode ser um servidor, banco de dados, máquina virtual, etc.
Em ambientes virtuais, existem dois métodos comuns de failover:
- Usando uma réplica de VM (geralmente localizada em outro servidor de virtualização) é usada para executar o failover se uma VM primária falhar
- Usando um cluster de failover (sem necessidade de replicação)
O failover requer menos tempo para restaurar as cargas de trabalho em comparação com a recuperação a partir de um backup e, como resultado, é possível atingir um objetivo de tempo de recuperação (RTO) mais baixo. No entanto, o uso de replicação de VM ou clustering não elimina a necessidade de criar backups de VM. Um backup (geralmente compactado) é útil quando é necessário recuperar dados a partir do ponto de recuperação antigo.
Vamos revisar a terminologia básica de failover de VM para recuperação de desastres baseada em replicação.
Glossário de failover
- Falha: Qualquer problema com hardware ou software como resultado de uma falha do sistema, queda de energia, problemas de rede, ataque de ransomware, etc., que deixa um sistema offline.
- Sistema primário: O sistema que executa operações ao vivo no ambiente de produção.
- Sistema secundário: O sistema redundante de reserva, que é atualizado regularmente com cópias do sistema primário. O sistema secundário pode estar localizado localmente ou em um local remoto.
- Replicação: O processo essencial para preparar o failover de VM. A replicação cria uma cópia exata, ou réplica, da VM primária para um determinado ponto no tempo.
- VM Failback: Failback é o processo de retornar para o sistema primário a partir da VM de réplica após o incidente ser resolvido.
Tipos de Failover
Há três tipos de failover:
- A planned failover is used for scheduled migrations of workloads from one system/site to another. Use cases include performing maintenance on the primary system, electrical works performed at the production site, and expected disaster scenarios. For example, a weather alert about a tornado may require a planned failover to ensure availability.
- Um failover não planejado é um failover realizado quando ocorre uma falha inesperada resultando em uma VM crítica ou em todo o site primário ficando offline. A falha pode ser causada por qualquer número de desastres naturais, acidentes (uma queda de energia), um ataque de malware, ou qualquer outro incidente. Para um failover não planejado, hosts e réplicas devem estar preparados com antecedência.
- A test failover, as the name suggests, is used for testing purposes. Testing scenarios can include rehearsing unplanned failover scenarios to ensure that
A Sequência de Failover
Durante um failover de VM, a sequência de ações e a ordem de inicialização da VM são essenciais para garantir a retomada bem-sucedida dos fluxos de trabalho. Eles devem ser definidos na fase de desenvolvimento do plano de recuperação de desastres da sua organização. A sequência deve capturar as dependências entre diferentes serviços que rodam em VMs diferentes.
Por exemplo, a autenticação para alguns serviços e aplicativos que rodam em VMs podem estar usando o Active Directory, que está rodando em outra VM. Um servidor de banco de dados pode estar rodando na primeira VM, um servidor de aplicativos na segunda e o servidor web na terceira.
A VM com o Servidor Active Directory deve ser iniciada primeiro. Em seguida, as VMs com serviços que usam o Active Directory para autenticação podem ser iniciadas. A VM com o servidor de banco de dados deve ser iniciada antes da VM com o servidor de aplicativos, porque o servidor de aplicativos se conecta ao banco de dados. Uma vez que as VMs com o servidor de banco de dados e o servidor de aplicativos tenham sido iniciadas, a VM com o servidor web pode ser iniciada.
Soluções Principais de Failover
As principais soluções usadas em ambientes virtuais são:
- cluster de failover
- failover usando réplicas de VM
Vamos considerar cada uma delas.
Solução 1. Cluster de Failover
A failover cluster is a group of at least two servers or nodes that are configured to take over workloads when one node is down or unavailable. Clustering is an enterprise-class automated solution that can be used for the most important, business-critical VMs. Microsoft Hyper-V offers a Failover Cluster made up of several Hyper-V hosts. VMware’s equivalent is a High Availability cluster, which is made up of ESXi hosts.
No primeiro diagrama abaixo, você pode ver um cluster no qual ambos os hosts (também chamados de nós) estão funcionando corretamente. As VMs estão sendo executadas nos hosts, e os arquivos das VMs estão localizados em armazenamento compartilhado que é acessível por ambos os hosts.
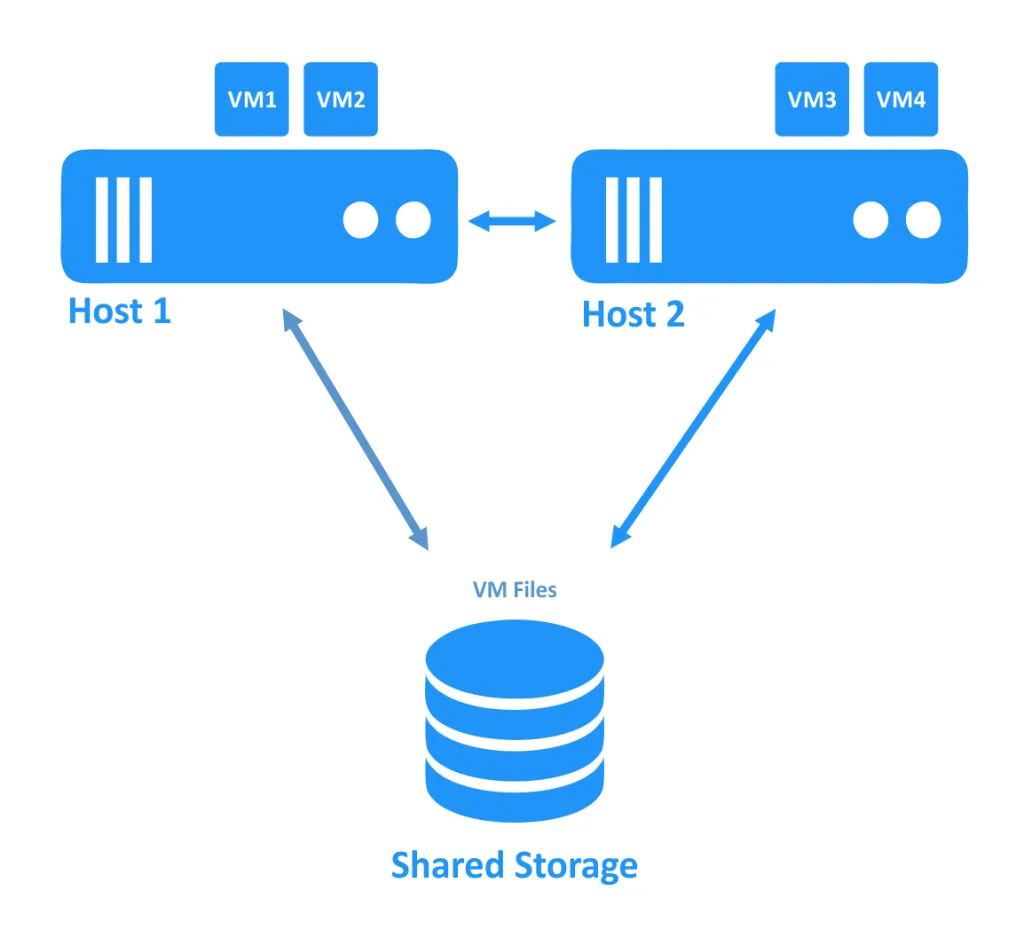
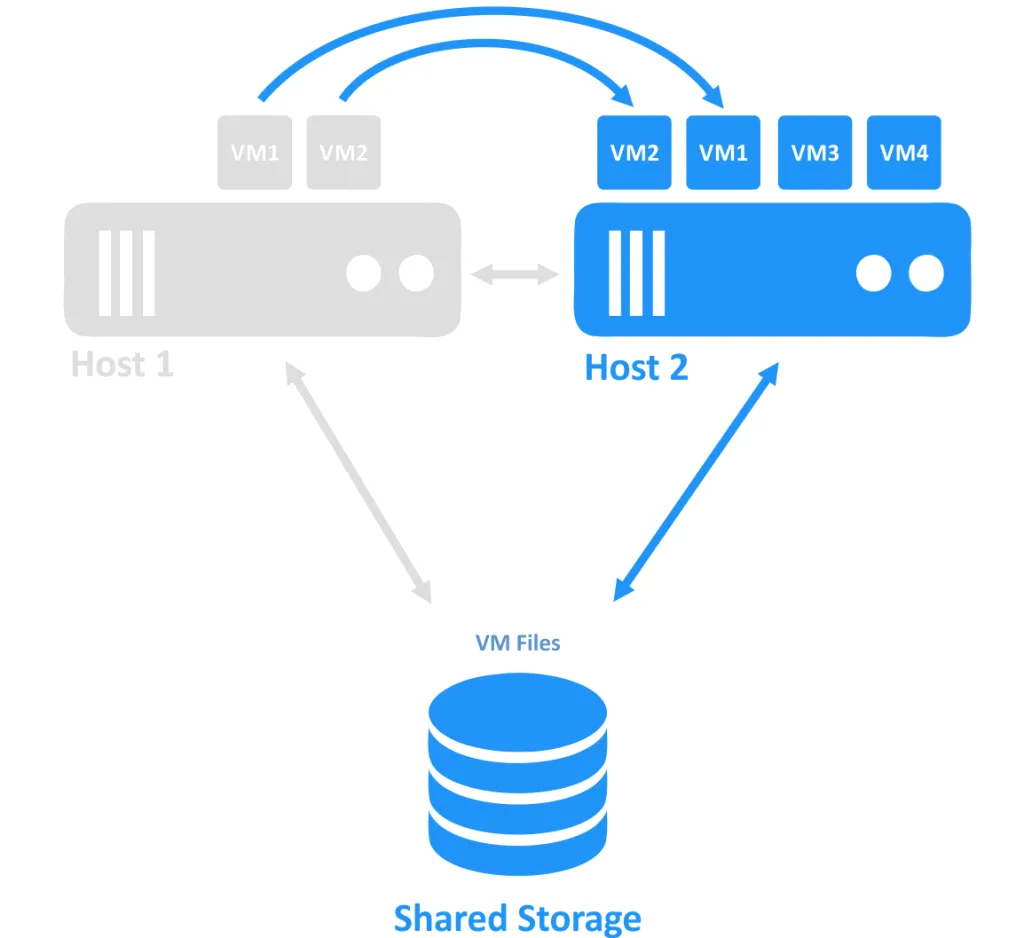
Quando um dos hosts falha, a propriedade da conexão com a VM (que estava sendo executada no nó offline) é transferida para outro nó que ainda está online. Este é o processo de failover. Uma VM altamente disponível pode precisar ser reiniciada.
Requisitos de Cluster de Failover
Os seguintes requisitos devem ser atendidos para construir um cluster de failover:
- Armazenamento compartilhado conectado aos hosts com uma rede dedicada de alta velocidade e baixa latência. Um sistema de arquivos em cluster deve ser usado para garantir que vários hosts possam acessar simultaneamente os dados localizados no armazenamento.
- Os hosts nos quais as VMs estão em execução devem ter o mesmo hardware ou, pelo menos, hardware da mesma família. Os processadores devem suportar os mesmos conjuntos de instruções para garantir compatibilidade para que as VMs sejam executadas corretamente após a migração de um host para outro durante a falha.
- A high-speed redundant network with low latency. There should be multiple, separate cluster networks, that is, a cluster must have different networks for storage, management, VM migration, connection of hosts amongst each other, etc.
Casos de uso
Os clusters de failover são usados para recuperar VMs de falhas de servidor, fornecendo alta disponibilidade para VMs críticas. Se um dos hosts (chamados nós) dentro de um cluster falhar, então as VMs que estavam em execução no host falido migram (failover) para outros hosts saudáveis. Dependendo das configurações, as VMs que foram transferidas podem ser migradas de volta para o host em que estavam em execução antes do incidente, uma vez que a falha for resolvida.
Vantagens
A failover cluster has advantages that provide strong protection:
- A failover cluster provides automatic VM failover. You don’t need to start the failed VMs manually on other hosts.
- Após o failover, você experimenta perda de dados quase zero. O tempo de inatividade geralmente se limita ao tempo necessário para carregar a VM, o sistema operacional (SO) e o software em execução na VM.
- O recurso de Tolerância a Falhas incluído no cluster de Alta Disponibilidade do VMware garante a transferência de VM sem tempo de inatividade e sem perda de dados.
Desvantagens
A failover cluster does not protect against:
- Falha de software de VMs. Bugs de software ou vírus podem causar uma falha no sistema em uma VM.
- Exclusão acidental de arquivos dentro da VM.
- Falha no armazenamento compartilhado. O cluster falha se o armazenamento compartilhado falhar. O armazenamento compartilhado é um componente crucial do cluster; os discos virtuais que pertencem às VMs dentro de um cluster são armazenados no armazenamento compartilhado.
- A disaster that makes the whole physical site unavailable.
Para obter mais informações sobre o que é um cluster de failover, leia o guia completo sobre o agrupamento VMware.
Solução 2. Failover usando réplicas de VM
Failover de VM dependendo de réplicas de VM pode ser executado por aplicativos especializados, que podem replicar as VMs e iniciar as réplicas quando solicitado pelo administrador. Além do software de proteção de dados, você precisa de hosts ESXi ou Hyper-V (dependendo do seu ambiente) que foram preparados com antecedência para executar as réplicas de VM quando as VMs de origem falham.
No diagrama abaixo, você pode ver dois hosts conectados entre si via rede. As VMs estão usando os discos dos hosts. As VMs de origem estão sendo executadas no primeiro host, e as réplicas de VM, que são cópias exatas das VMs de origem em um momento específico, estão localizadas no segundo host em um estado desligado.
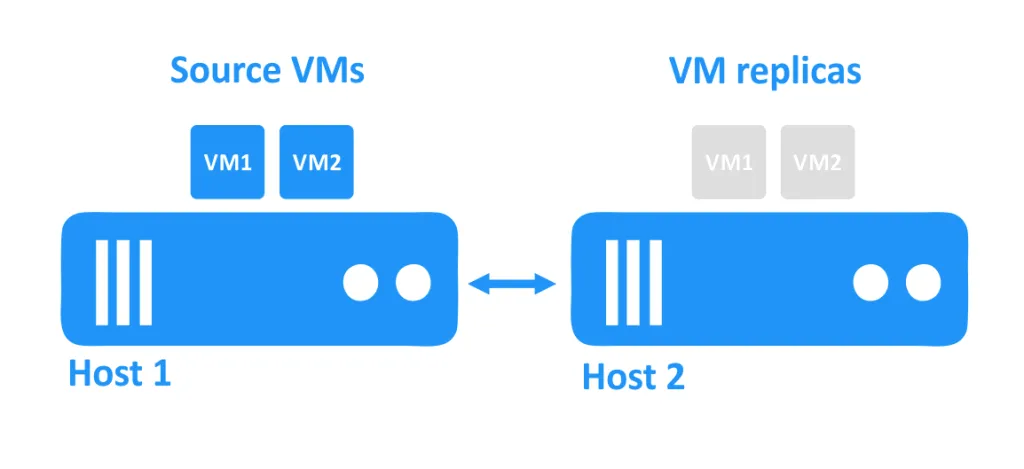
Quando um host cai, as VMs que estavam sendo executadas nesse host também se tornam inacessíveis. As réplicas de VM que estão localizadas em outro host são então ligadas pelo administrador.
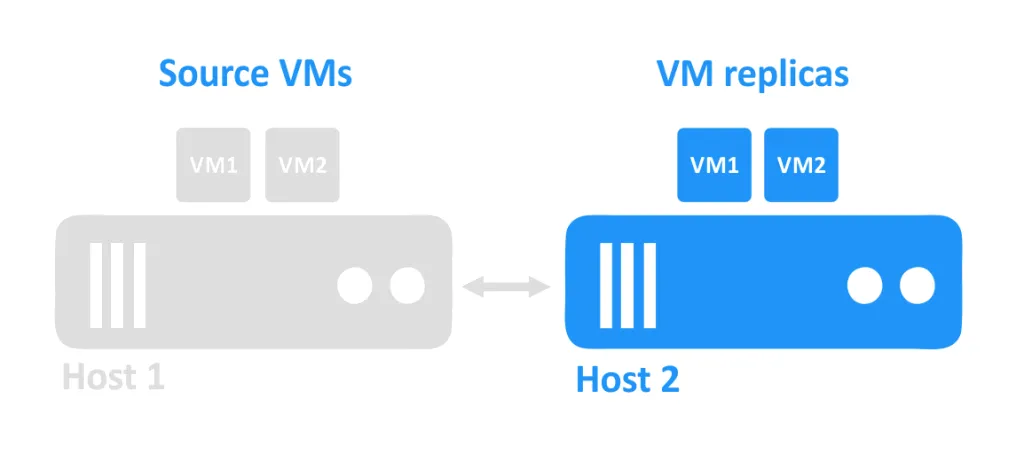
Requisitos de replicação de VM
Os requisitos básicos para a replicação de VM são dois ou mais hosts e uma solução de replicação. Uma VM de origem em execução no primeiro host é replicada para o segundo host. A réplica da VM está localizada no segundo host.
Casos de uso
A falha usando réplicas de VM pode ser usada quando ocorre uma falha de hardware ou software. As falhas de host ESXi ou Hyper-V são exemplos de falhas de hardware. Exemplos de falha de software podem ser atualizações falhadas, bugs de software, ataques de vírus ou exclusão acidental de arquivos por um usuário.
Vantagens
A principal vantagem da falha de VM para uma réplica é a possibilidade de falha para um site remoto. Quando uma réplica de VM está sendo criada, os dados copiados de uma VM de origem podem ser transmitidos por uma conexão de rede (com largura de banda limitada) para um site remoto. O site remoto pode estar localizado em um escritório próximo ou do outro lado do mundo. A réplica da VM também pode estar localizada no site de produção primário.
Desvantagens
A lista de desvantagens para uma falha usando réplicas de VM:
- Há um curto período de inatividade entre uma falha e o início da réplica no segundo host.
- A falha deve ser iniciada manualmente.
- Os dados gravados desde a última replicação podem ser perdidos durante uma falha não planejada. A replicação de VM geralmente não é um processo em tempo real (síncrono), pois a replicação síncrona coloca uma carga significativa nos recursos. A replicação geralmente é realizada em intervalos regulares, dependendo das configurações escolhidas.
- As configurações de rede das VMs devem ser alteradas (com frequência) ao ocorrer a ativação para outro site. As redes das VMs do site remoto podem ser diferentes das redes do site principal. Portanto, os endereços IP também podem ser diferentes e devem ser verificados e alterados juntamente com outras configurações de rede durante a ativação.
Clusterização vs Ativação de VM Baseada em Replicação
| Ativação com clusterização | Ativação usando uma réplica | |
| Propósito | Alta disponibilidade | Recuperação de desastres |
| Proteção contra | Apenas falhas de hardware | Falhas de hardware e software |
| Administração | Iniciado automaticamente | Iniciado manualmente |
| Duração do tempo de inatividade (RTO) | A ativação é mais rápida, portanto o tempo de inatividade da VM é curto (RTO curto) | A ativação leva mais tempo, então o tempo de inatividade da VM é maior |
| Requisitos | Mais requisitos | Menos requisitos |
| Preço da Solução | As soluções de clusterização geralmente são mais caras | As soluções de replicação são mais eficientes em termos de custo |
| Perda de Dados (RPO) | Quase nenhuma perda de dados (RPO muito baixo) | A perda de dados depende da frequência da replicação |
Uso Combinado de Clusters e Réplicas para Failover de VMs
As soluções de failover de cluster e réplica são às vezes vistas como alternativas, mas podem ser usadas para se complementarem. Vamos ver alguns exemplos de como o uso de ambas as soluções de failover pode ajudar a proteger suas VMs contra falhas tanto a nível de servidor quanto de site.
- Exemplo 1: Você pode replicar as VMs em execução dentro de um cluster para um host em um site remoto. Além disso, você pode replicar as VMs em execução em um cluster para outro cluster. Assim, se um host falhar, o cluster de failover mantém essas VMs online. Se o site inteiro sofrer uma interrupção, então você pode fazer failover para as réplicas de VM armazenadas em um site remoto.
- Exemplo 2: Um vírus danifica arquivos dentro de algumas VMs. Um cluster de failover não pode proteger contra tais falhas. Mas se você tiver réplicas de VM com vários pontos de recuperação, você pode restaurar cada VM para um ponto no tempo antes que seus arquivos fossem danificados ou excluídos.
Usando a Solução NAKIVO para Failover Automatizado de VMware VM para Réplica
O NAKIVO Backup & Replication é uma solução de backup e recuperação de desastres que pode proteger VMs em execução dentro de um cluster, replicar VMs, falhar para réplicas e orquestrar sequências complexas de recuperação de desastres. Clusters, bem como hosts ESXi ou Hyper-V autônomos, são suportados como pontos de origem e destino para replicação. A solução rastreia automaticamente o host em que uma VM está residindo para que possa replicar essa VM. Isso é útil porque as VMs podem migrar de um host para outro dentro de um cluster após eventos de failover ou eventos de balanceamento de carga (um cluster geralmente é configurado em conjunto com balanceamento de carga). É por isso que o software que você usa para replicar uma VM de um cluster deve ser capaz de rastrear o host em que a VM está residindo.
A solução NAKIVO pode alterar automaticamente as configurações de rede da VM ao falhar; basta usar os recursos de Mapeamento de Rede e Re-IP ao configurar um trabalho de replicação ou failover.
Vamos considerar um exemplo de Falha Automática de VM (com Mapeamento de Rede e Re-IP) no NAKIVO Backup & Replication. Vamos começar criando uma réplica da VM.
Configurando replicação necessária para failover de VM
No painel de Jobs, clique em Criar > Job de replicação VMware vSphere se você tiver um ambiente virtual VMware. Observe que você pode criar um job de replicação para uma VM Microsoft Hyper-V ou uma instância Amazon EC2 da mesma maneira.
O assistente de job de replicação é iniciado.
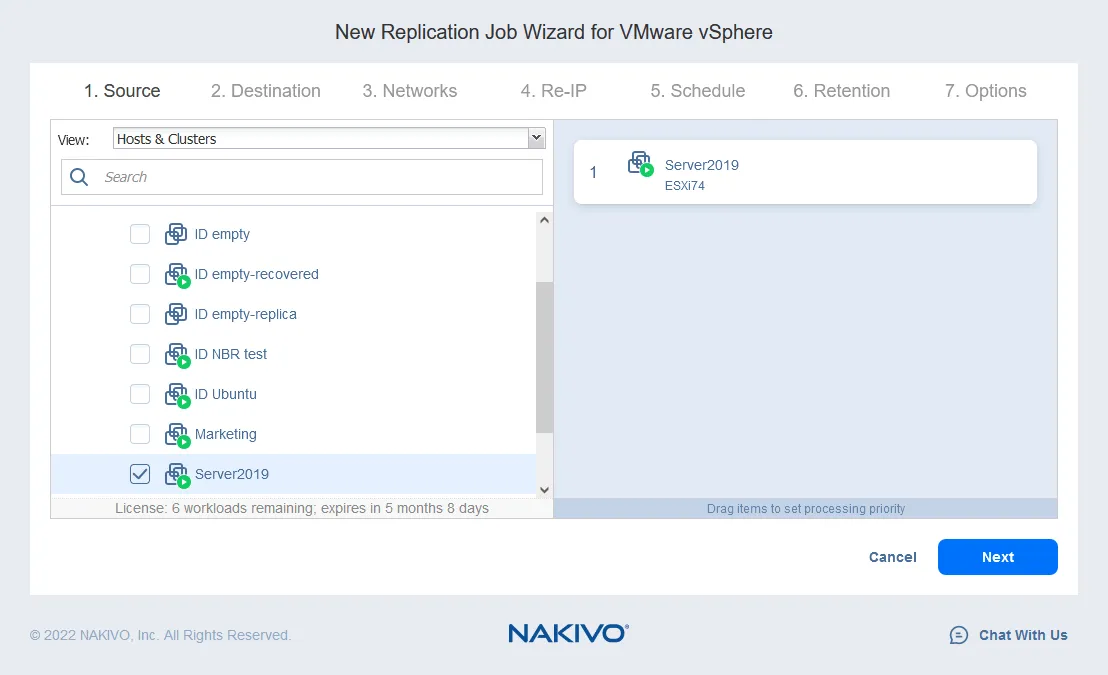
- Selecione as máquinas virtuais que deseja replicar. Neste exemplo, a VM Server2019, que está executando o Windows Server 2019 como sistema operacional convidado, será replicada. Clique em Próximo.
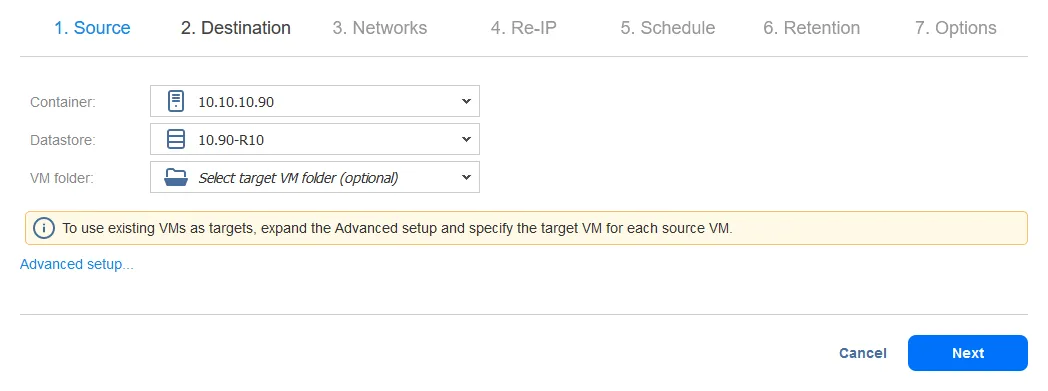
- Selecione um host de destino para a réplica da VM ser executada (10.10.10.90 no nosso caso). Selecione o datastore montado no host selecionado para o local dos arquivos da VM. Clique em Próximo.
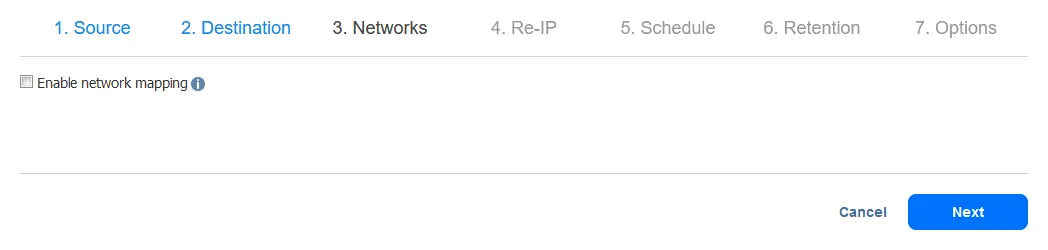
- Você pode configurar o mapeamento de rede e as opções de Re-IP ao configurar um trabalho de replicação ou um trabalho de failover. Neste passo a passo, o mapeamento de rede e o Re-IP serão configurados posteriormente, quando o trabalho de failover for configurado. Assim, você pode pular esta etapa por enquanto e apenas clicar em Próximo.
- A configuração de Re-IP será explicada durante a configuração do trabalho de failover da VM nesta demonstração. Clique em Próximo.
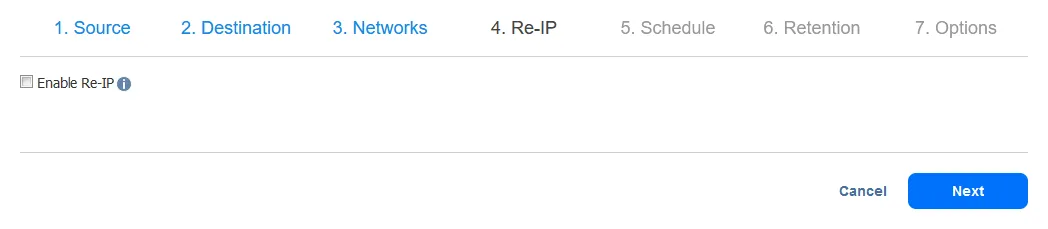
- Selecione suas configurações de agendamento. Clique em Próximo quando terminar.
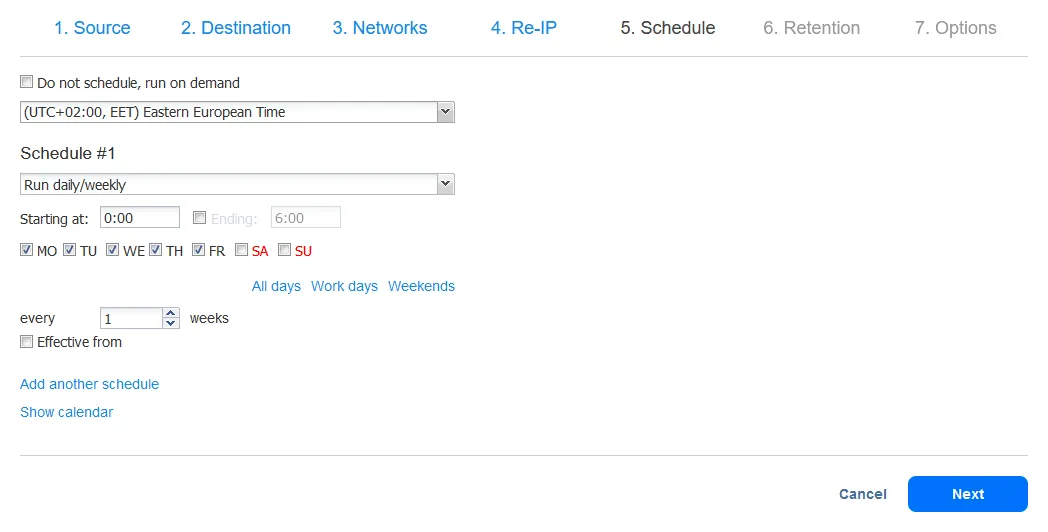
- Defina as configurações de retenção. Lembre-se de que você pode configurar a política de retenção avô-pai-filho nesta etapa. Clique em Próximo.
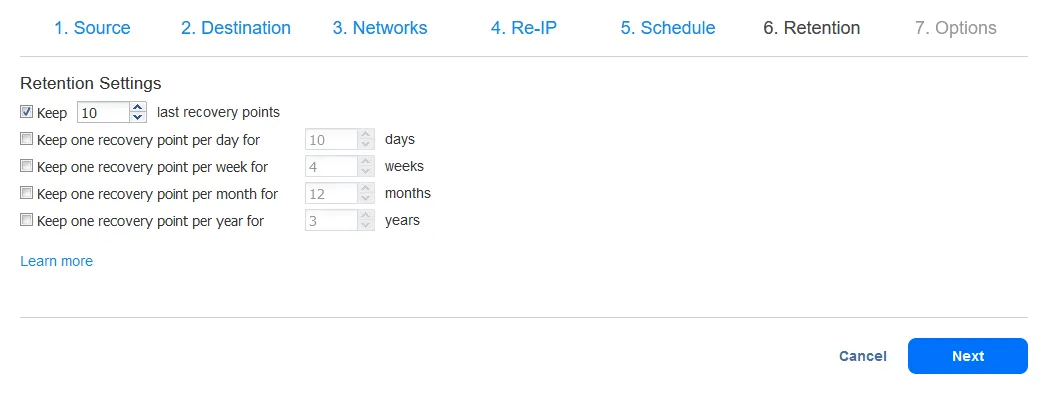
- Selecione as opções de trabalho de replicação e clique em Concluir ou no botão Concluir & Executar. Aguarde enquanto a réplica é criada.
Configurando failover de VM
Agora que você tem uma réplica de VM criada, você pode executar o failover da VM para esta réplica.
Na página inicial do painel de controle, clique em Recuperar > Recuperação Completa do VMware (failover de réplica de VM). O Assistente de Novo Trabalho de Failover será aberto.
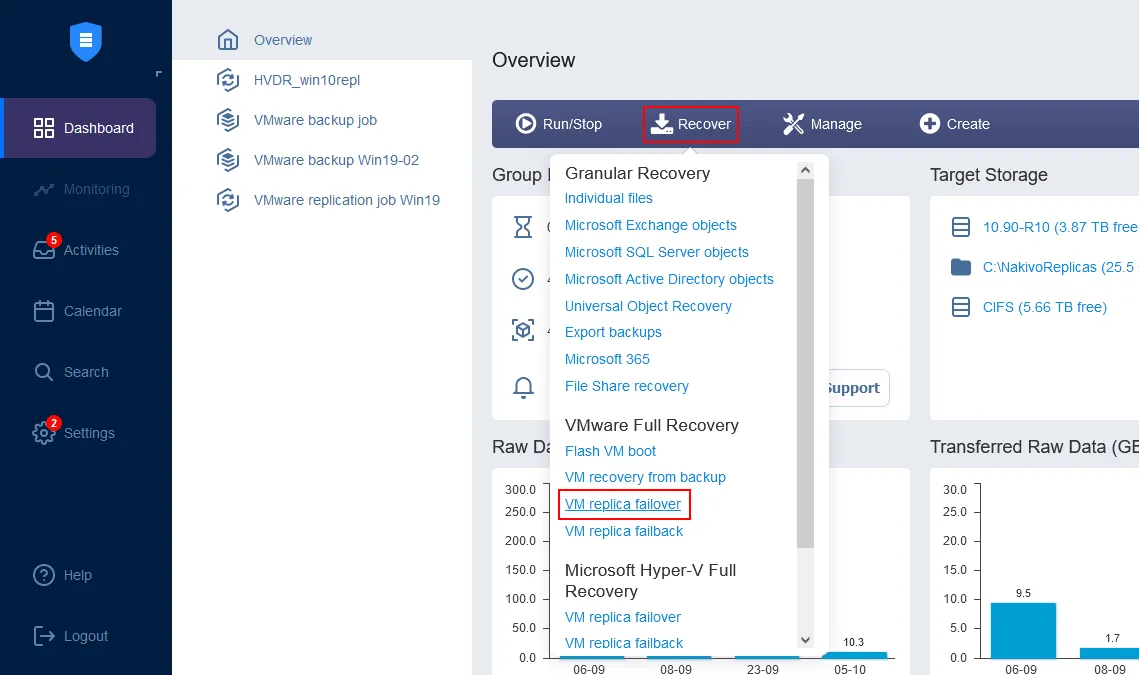
- No painel esquerdo, selecione a réplica de VM a ser usada para o failover. Neste passo a passo, o Server2019-replica, que acabou de ser criado, está selecionado. No painel direito, selecione um ponto de recuperação. O último ponto de recuperação é selecionado por padrão na solução. Clique em Avançar.
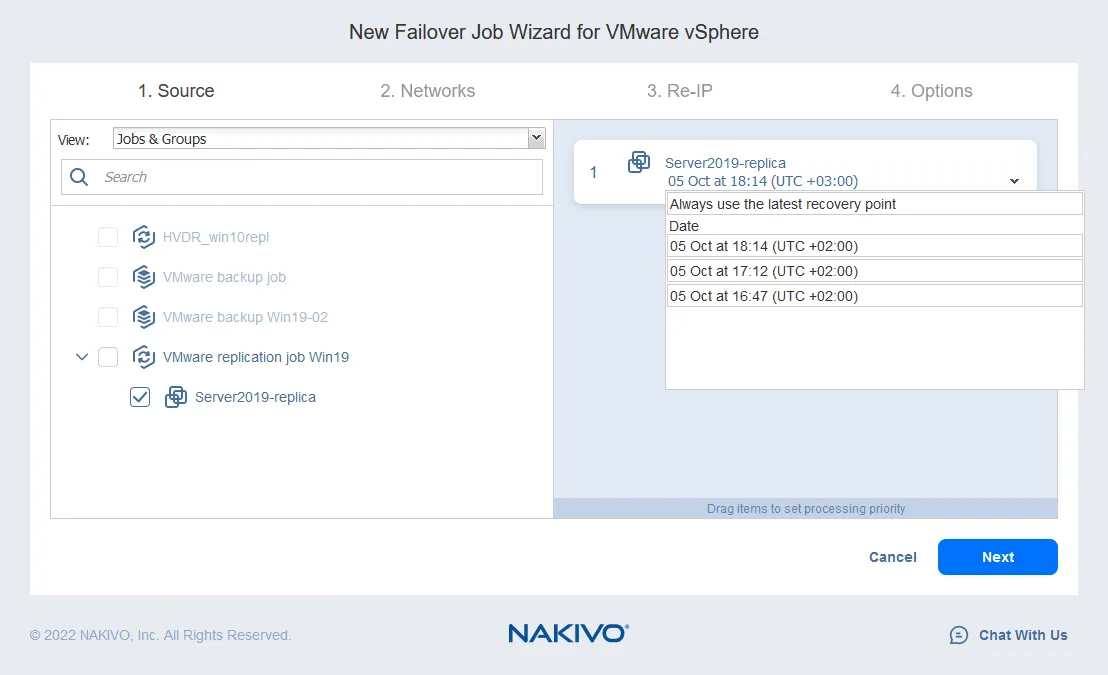
- Mapeamento de Rede ajuda a mudar a rede à qual a VM está conectada. É provável que os hosts ESXi de origem e destino tenham configurações de switch virtual diferentes. Como uma réplica de VM é uma cópia exata da VM de origem, as redes virtuais às quais a VM de origem está conectada são preservadas na réplica da VM.
Geralmente, você deve verificar as configurações de rede de uma réplica de VM e mudar manualmente a rede. O NAKIVO Backup & Replication pode mapear automaticamente a rede de origem para uma rede de destino. Você só precisa configurar o Mapeamento de Rede ao configurar o trabalho de replicação ou failover.
- Para habilitar o Mapeamento de Rede, marque a caixa de seleção. Se você já criou uma regra de mapeamento de rede, pode clicar em Adicionar mapeamento existente. Se não houver regras de mapeamento de rede, clique em Criar novo mapeamento.
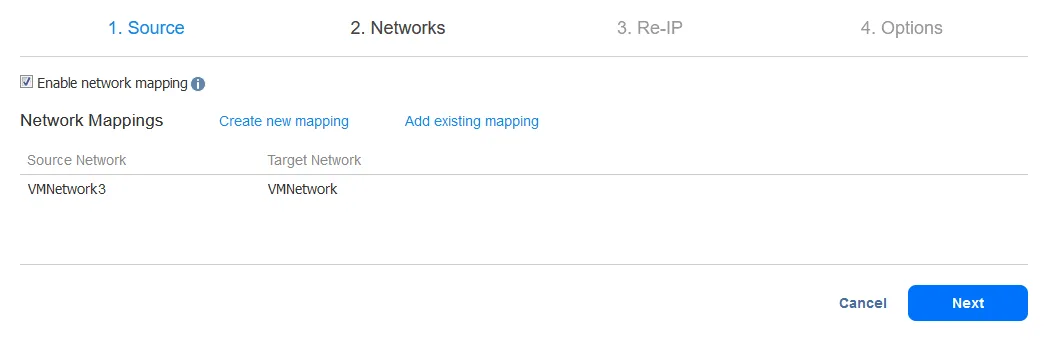
-
Para criar uma nova regra de mapeamento de rede, selecione a rede de origem e a rede de destino. A rede de origem é a rede à qual a VM de origem está conectada. A rede de destino é a rede à qual a réplica da VM deve ser conectada.
Nota: O nome da rede da VM não é o mesmo que o endereço IP ou o endereço de rede.
Clique em Salvar para salvar a regra de mapeamento de rede e, em seguida, clique em Próximo para prosseguir na configuração.
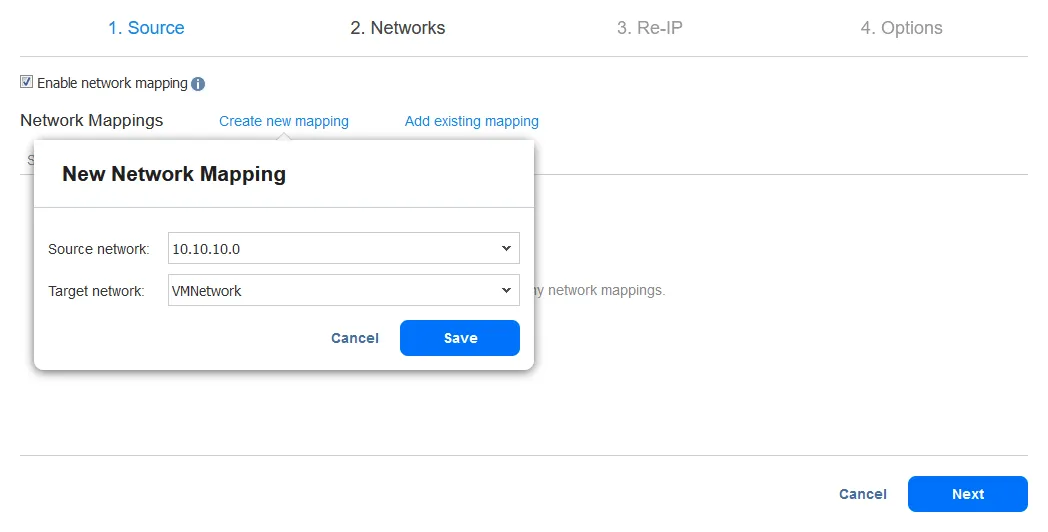
- O recurso Re-IP permite que você altere as configurações de IP da réplica de VM. Pode ser usado para endereços IP estáticos. Marque a caixa de seleção Ativar Re-IP se desejar habilitar esta opção e, em seguida, crie uma regra Re-IP ou adicione uma regra existente. Clique em Criar nova regra se não houver regras criadas anteriormente. Um menu pop-up aparecerá.
- As configurações da VM de origem são o endereço IP e a máscara de rede que precisam ser alterados.
-
As configurações de destino são as configurações a serem aplicadas à réplica da VM quando ocorrer o failover. Neste exemplo, o caractere [*] cobre o último octeto. O [*] significa qualquer número de 1 a 254. Se os endereços IP de origem forem, por exemplo, 10.10.10.1, 10.10.10.96 e 10.10.10.222, os endereços de destino seriam 192.168.10.1, 192.168.10.96 e 192.168.10.222, respectivamente. O último octeto do endereço IP é preservado.
Clique em Salvar para salvar sua regra Re-IP e continuar.
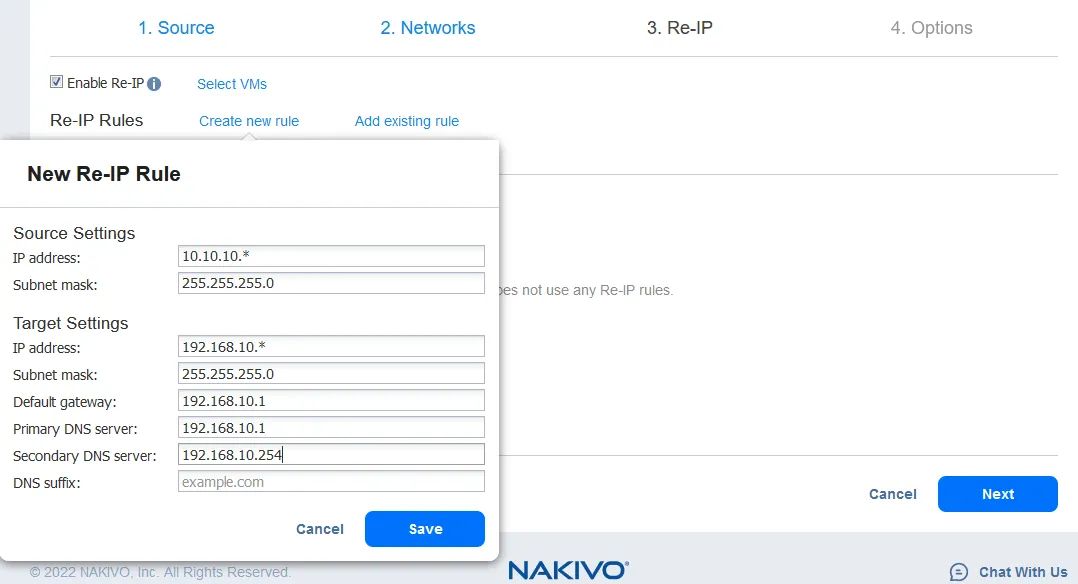
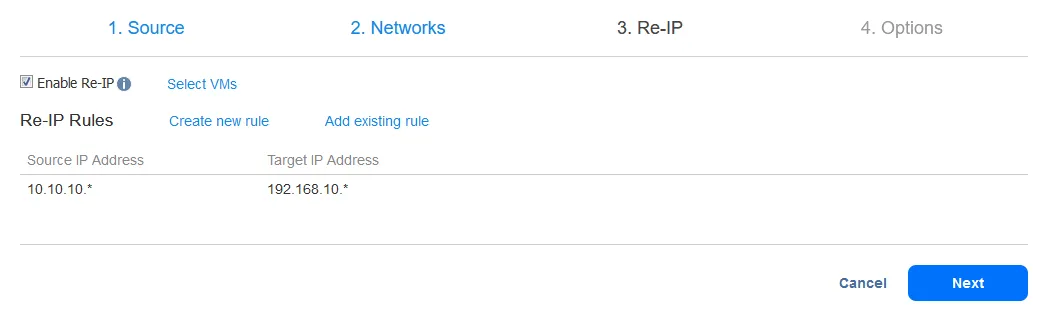
Após adicionar a regra Re-IP, sua tela deve se parecer com esta:
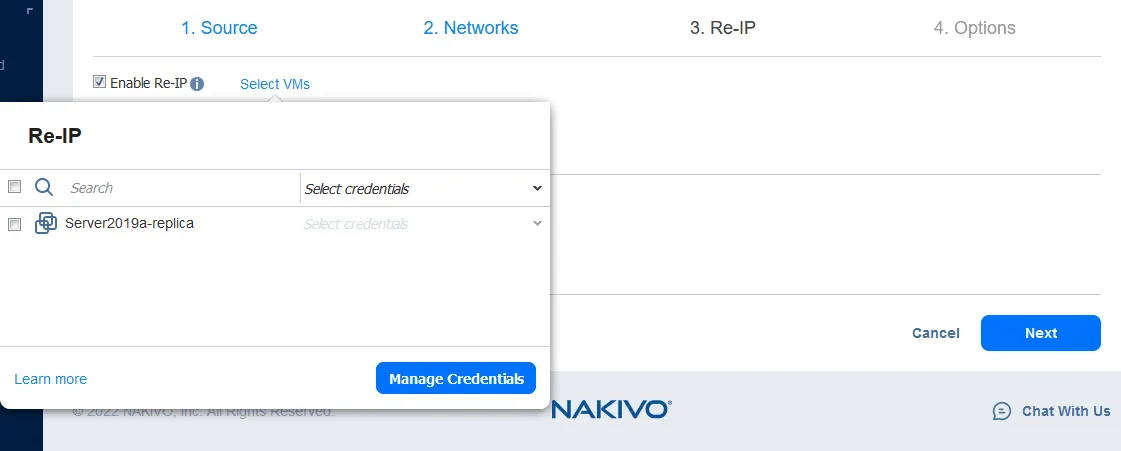
Agora selecione as VMs para as quais as regras Re-IP devem ser aplicadas. O trabalho de failover neste exemplo contém apenas uma réplica de VM, então selecione a única caixa de seleção.
Em seguida, selecione as credenciais para cada VM. Clique em Gerenciar credenciais > Adicionar credenciais para adicionar novas credenciais. As credenciais adicionadas podem ser selecionadas na lista suspensa.
Nota: As credenciais são necessárias para que o NAKIVO Backup & Replication acesse as configurações de rede do sistema operacional dentro da VM e aplique o script que altera essas configurações. As Ferramentas VMware devem estar instaladas nas VMs do VMware vSphere, e os Serviços de Integração Hyper-V devem estar instalados nas VMs do Microsoft Hyper-V.
Quando você configurou todas essas configurações, clique em Próximo.
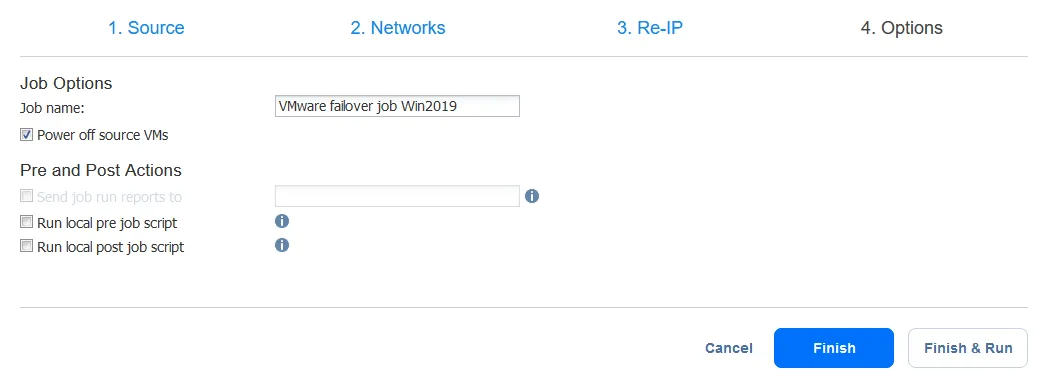
Agora, configure as opções do trabalho de failover de VM. Você pode selecionar a caixa de seleção Desligar VMs de origem. Pode ser útil para evitar conflitos de endereços IP se as VMs de origem e de réplica usarem a mesma rede ou tiverem os mesmos endereços IP. Depois de configurar todas as opções, clique em Concluir e Executar.
Aguarde até que o trabalho de failover de VM seja concluído.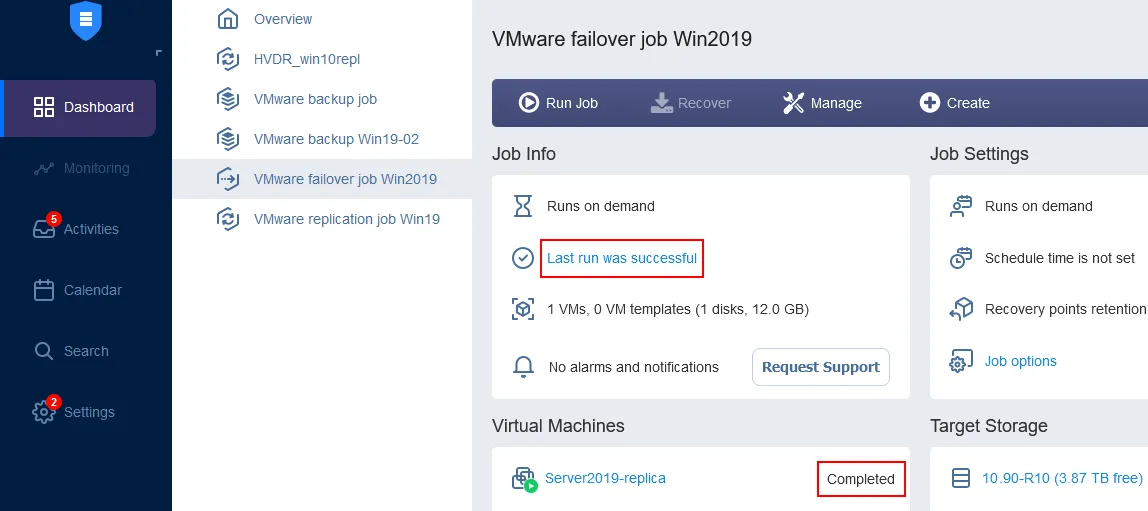
Agora você pode garantir que a réplica de VM esteja em execução. Vá para Configuração > Inventário e clique no botão Atualizar Todos</ - Para habilitar o Mapeamento de Rede, marque a caixa de seleção. Se você já criou uma regra de mapeamento de rede, pode clicar em Adicionar mapeamento existente. Se não houver regras de mapeamento de rede, clique em Criar novo mapeamento.