













Die Verfügbarkeit von VMs ist entscheidend für die Sicherstellung der Geschäftskontinuität. Wenn die Dienste, die auf geschäfts- und missionskritischen VMs ausgeführt werden, nicht verfügbar sind, können Unternehmen Geld verlieren und das Vertrauen der Kunden verlieren. Um die Verfügbarkeit von VMs unmittelbar nach einem Ausfall wiederherzustellen, sollten geeignete Failover-Techniken verwendet werden.
Failover zu einer VM-Replik kann Teil des Notfallwiederherstellungsprozesses sein, um Daten und Operationen mit minimaler Unterbrechung der regulären Arbeitsabläufe wiederherzustellen. Der VM-Failover-Prozess sollte in einem Business Continuity und Disaster Recovery (BCDR) Plan der Organisation beschrieben werden. Lassen Sie uns die VM-Failover-Typen und Anwendungsfälle genauer betrachten.
Was ist ein Failover?
Failover ist der Prozess, eine virtuelle Maschine (VM) auf einem sekundären System (und manchmal an einem sekundären Standort) nach einem Ausfall des primären Systems wiederherzustellen. Das sekundäre System enthält alle benötigten Daten, um die Geschäftsabläufe aufrechtzuerhalten. Ein System kann in diesem Zusammenhang ein Server, eine Datenbank, eine virtuelle Maschine usw. sein.
In virtuellen Umgebungen gibt es zwei gängige Failover-Methoden:
- Verwendung einer VM-Replik (normalerweise auf einem anderen Virtualisierungsserver), um Failover durchzuführen, wenn eine primäre VM ausfällt
- Verwendung eines Failover-Clusters (keine Replikation erforderlich)
Failover erfordert weniger Zeit, um Workloads im Vergleich zur Wiederherstellung aus einem Backup wiederherzustellen, und Sie können daher ein niedrigeres Wiederherstellungszeitziel (RTO) erreichen. Die Verwendung von VM-Replikation oder Clustering entfernt jedoch nicht die Notwendigkeit, VM-Backups zu erstellen. Ein Backup (normalerweise komprimiert) ist nützlich, wenn Sie Daten aus dem alten Wiederherstellungspunkt wiederherstellen müssen.
Lassen Sie uns die grundlegenden VM-Failover-Begriffe für die replikationsbasierte Katastrophenwiederherstellung durchgehen.
Fehlerwörterbuch
- Fehler: Jedes Problem mit Hardware oder Software als Folge eines Systemabsturzes, eines Stromausfalls, Netzwerkproblemen, eines Ransomware-Angriffs usw., das ein System offline nimmt.
- Primärsystem: Das System, das Live-Betrieb in der Produktionsumgebung ausführt.
- Sekundärsystem: Das redundante Standby-System, das regelmäßig mit Kopien des Primärsystems aktualisiert wird. Das Sekundärsystem kann sich lokal oder an einem entfernten Ort befinden.
- Replikation: Der wesentliche Prozess zur Vorbereitung auf den VM-Failover. Die Replikation erstellt eine genaue Kopie, das heißt, eine Replica des primären VMs zu einem bestimmten Zeitpunkt.
- VM Failback: Failback ist der Prozess des Wechsels zurück zum Primärsystem von der Replica-VM, nachdem der Vorfall gelöst ist.
Failover-Typen
Es gibt drei Arten von Failover:
- A planned failover is used for scheduled migrations of workloads from one system/site to another. Use cases include performing maintenance on the primary system, electrical works performed at the production site, and expected disaster scenarios. For example, a weather alert about a tornado may require a planned failover to ensure availability.
- Ein ungeplanter Failover ist ein Failover, der durchgeführt wird, wenn ein unerwarteter Ausfall auftritt, der dazu führt, dass eine kritische VM oder der gesamte primäre Standort offline geht. Der Ausfall kann durch eine beliebige Anzahl von Naturkatastrophen, Unfällen (einen Stromausfall), einen Malware-Angriff oder ein anderes Ereignis verursacht werden. Für einen ungeplanten Failover sollten Hosts und Replikas im Voraus vorbereitet sein.
- A test failover, as the name suggests, is used for testing purposes. Testing scenarios can include rehearsing unplanned failover scenarios to ensure that
Die Failover-Sequenz
Während eines VM-Failovers sind die Failover-Sequenz von Aktionen und die Startreihenfolge der VMs entscheidend für eine erfolgreiche Wiederaufnahme der Arbeitsabläufe. Sie müssen bereits in der Entwicklungsphase des Disaster-Recovery-Plans Ihrer Organisation definiert sein. Die Sequenz sollte die Abhängigkeiten zwischen verschiedenen Diensten erfassen, die auf verschiedenen VMs ausgeführt werden.
Zum Beispiel könnte die Authentifizierung für einige Dienste und Anwendungen, die auf VMs ausgeführt werden, Active Directory verwenden, das auf einer anderen VM läuft. Ein Datenbankserver könnte auf der ersten VM laufen, ein Anwendungsserver auf der zweiten und der Webserver auf der dritten.
Die VM mit dem Active Directory-Server muss zuerst gestartet werden. Dann können die VMs mit Diensten, die Active Directory zur Authentifizierung verwenden, gestartet werden. Die VM mit dem Datenbankserver muss vor der VM mit dem Anwendungsserver gestartet werden, da der Anwendungsserver eine Verbindung zur Datenbank herstellt. Sobald die VMs mit dem Datenbankserver und dem Anwendungsserver gestartet wurden, kann die VM mit dem Webserver gestartet werden.
Hauptausfallsicherungslösungen
Die Hauptlösungen, die in virtuellen Umgebungen verwendet werden, sind:
- Ausfallsicherung durch Clusterung
- Ausfallsicherung durch Verwendung von VM-Repliken
Lassen Sie uns jede davon betrachten.
Lösung 1: Failover-Clustering
A failover cluster is a group of at least two servers or nodes that are configured to take over workloads when one node is down or unavailable. Clustering is an enterprise-class automated solution that can be used for the most important, business-critical VMs. Microsoft Hyper-V offers a Failover Cluster made up of several Hyper-V hosts. VMware’s equivalent is a High Availability cluster, which is made up of ESXi hosts.
Im ersten Diagramm unten sehen Sie einen Cluster, in dem beide Hosts (auch als Knoten bezeichnet) ordnungsgemäß funktionieren. Die VMs werden auf Hosts ausgeführt, und die VM-Dateien befinden sich auf einem gemeinsam genutzten Speicher, der von beiden Hosts aus erreichbar ist.
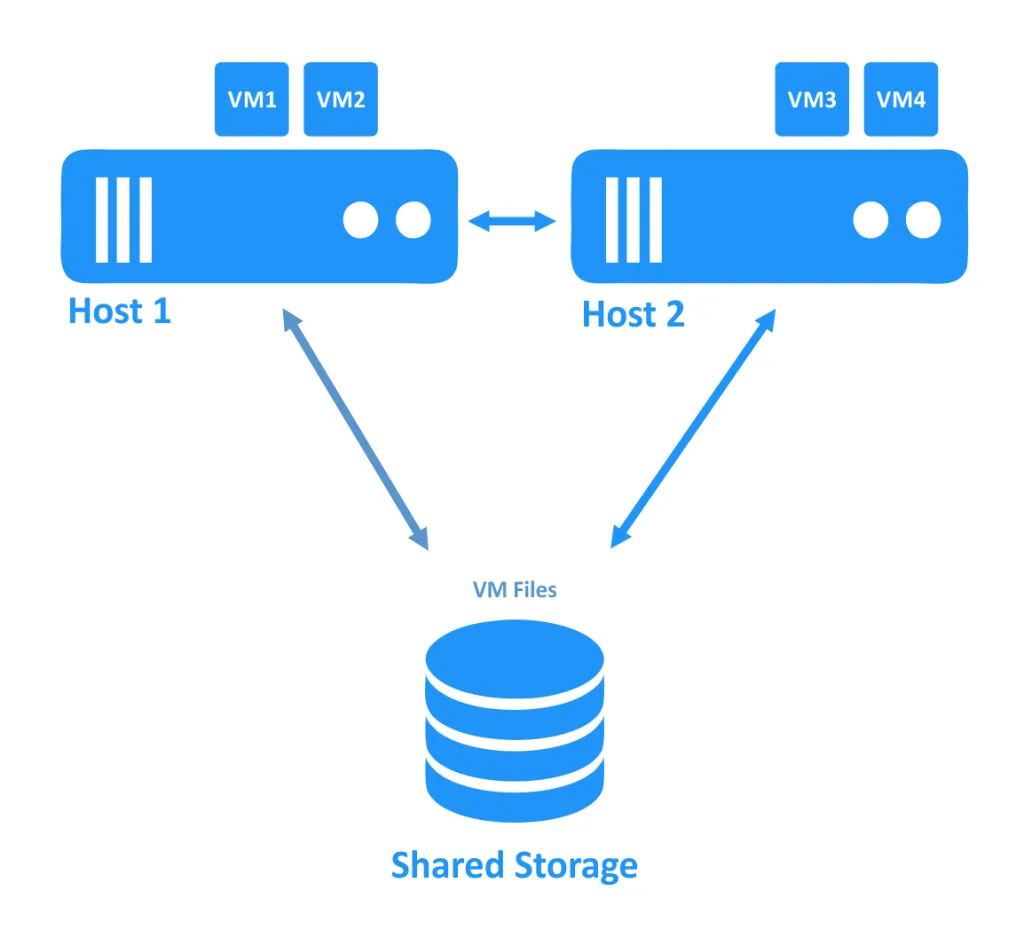
Wenn einer der Hosts ausfällt, wird die Verbindung zur VM (die auf dem offline geschalteten Knoten ausgeführt wurde) auf einen anderen Knoten übertragen, der noch online ist. Dies ist der Failover-Prozess. Eine hochverfügbare VM muss möglicherweise neu gestartet werden.
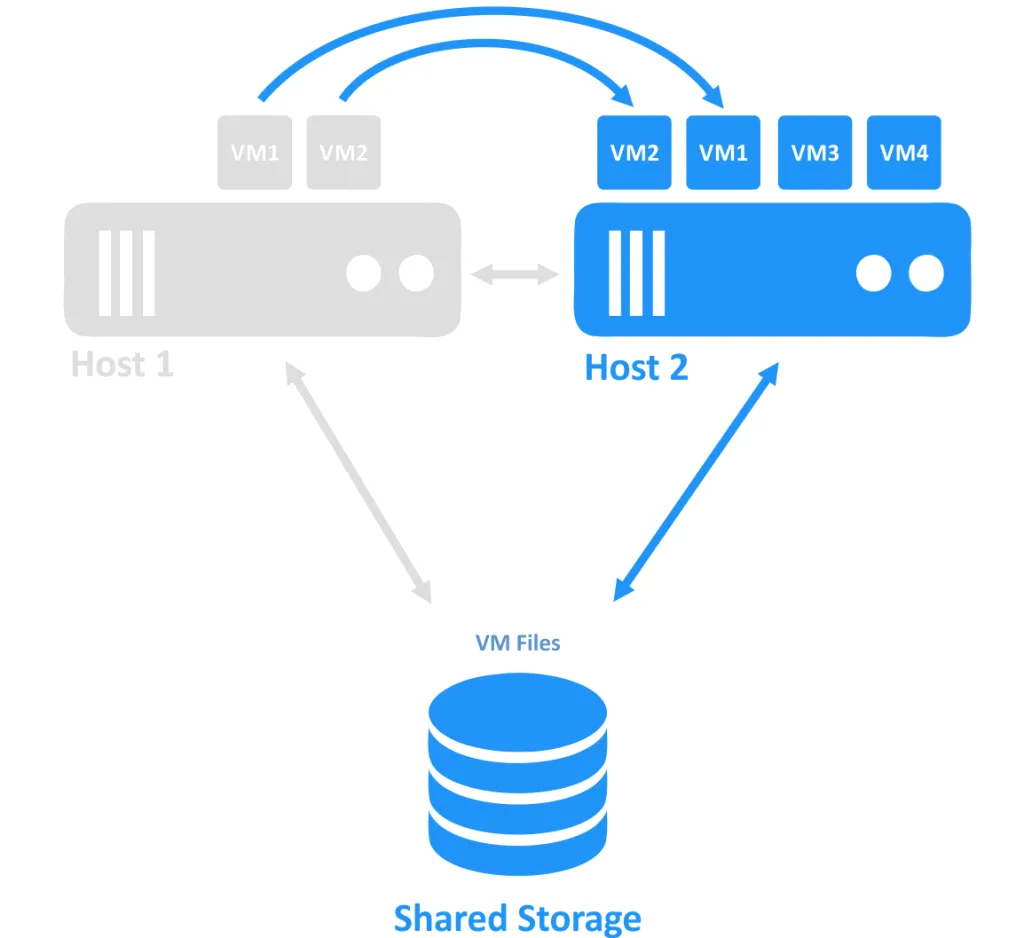
Anforderungen an die Failover-Clustering
Die folgenden Anforderungen müssen erfüllt sein, um einen Failover-Cluster zu erstellen:
- Geteilte Speicherung verbunden mit den Hosts über eine dedizierte Hochgeschwindigkeitsnetzwerks mit niedriger Latenz. Ein clustertypisches Dateisystem muss verwendet werden, um sicherzustellen, dass mehrere Hosts gleichzeitig auf die auf dem Speicher befindlichen Daten zugreifen können.
- Die Hosts, auf denen die VM’s laufen, müssen dieselbe Hardware haben oder zumindest Hardware der gleichen Familie. Die Prozessoren müssen dieselben Instruktions集 unterstützen, um sicherzustellen, dass die Kompatibilität besteht, wenn die VM’s nach einem Failover von einem Host zu einem anderen Host migrieren.
- A high-speed redundant network with low latency. There should be multiple, separate cluster networks, that is, a cluster must have different networks for storage, management, VM migration, connection of hosts amongst each other, etc.
Anwendungsfälle
Failover-Cluster werden verwendet, um VM’s bei Serverfehler zu erholen, um eine hohe Verfügbarkeit für kritische VM’s zu bieten. Wenn einer der Hosts (die als Knoten bezeichnet werden) innerhalb eines Clusters versagt, dann migrieren (übernehmen) die VM’s, die auf dem fehlgeschlagenen Host liefen, auf andere funktionstüchtige Hosts. Je nach Ihren Einstellungen können die übernommenen VM’s nach Behebung des Problems zu dem Host zurück migriert werden, auf dem sie vor dem Ereignis liefen.
Vorteile
A failover cluster has advantages that provide strong protection:
- A failover cluster provides automatic VM failover. You don’t need to start the failed VMs manually on other hosts.
- Beim Failover erleidet man eine nahezu Null Datenverluste. Die Downtime ist normalerweise auf die Zeit beschränkt, die es dauert, um die VM, das Betriebssystem (OS) und die auf der VM laufenden Software zu laden.
- Das Fehler Toleranz Feature, das im VMware High Availability Cluster enthalten ist, gewährleistet eine VM Failover ohne Downtime und ohne Datenverlust.
Nachteile
A failover cluster does not protect against:
- Softwarefehler von VMs. Softwarefehler oder Viren können einen Systemabsturz in einer VM verursachen.
- Versehentliches Löschen von Dateien innerhalb der VM.
- Fehler beim gemeinsam genutzten Speicher. Der Cluster fällt aus, wenn der gemeinsam genutzte Speicher ausfällt. Der gemeinsam genutzte Speicher ist eine wichtige Komponente des Clusters; die virtuellen Festplatten, die zu den VMs innerhalb eines Clusters gehören, werden auf dem gemeinsam genutzten Speicher gespeichert.
- A disaster that makes the whole physical site unavailable.
Weitere Informationen darüber, was ein Failover-Cluster ist, finden Sie in der vollständigen Anleitung zum VMware-Clustering.
Lösung 2. Failover unter Verwendung von VM-Repliken
Ein auf VM-Repliken basierender VM-Failover kann von spezialisierten Anwendungen ausgeführt werden, die die VMs replizieren und die Repliken starten können, wenn der Administrator dazu auffordert. Neben der Datensicherungssoftware benötigen Sie ESXi- oder Hyper-V-Hosts (abhängig von Ihrer Umgebung), die im Voraus vorbereitet wurden, um die VM-Repliken auszuführen, wenn die Quell-VMs ausfallen.
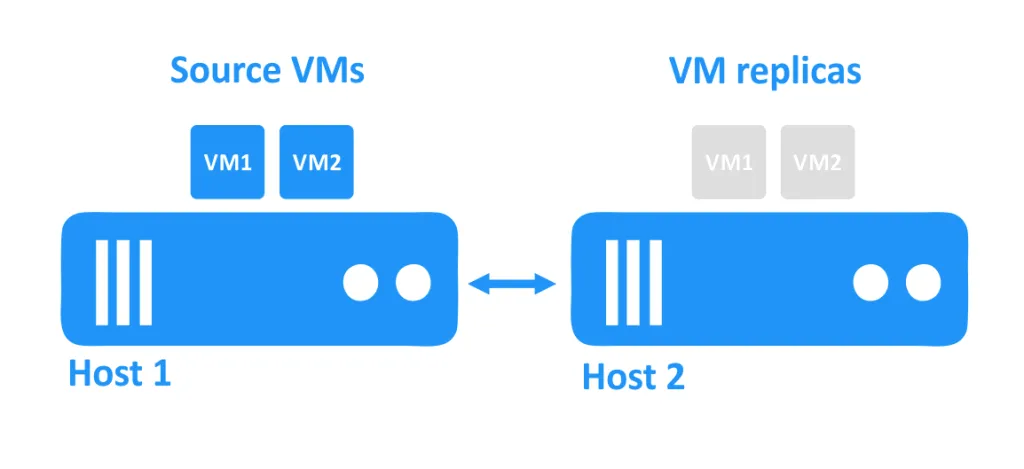
In der folgenden Abbildung können Sie sehen, dass zwei Hosts über das Netzwerk miteinander verbunden sind. Die VMs verwenden die Festplatten der Hosts. Die Quell-VMs werden auf dem ersten Host ausgeführt, und die VM-Repliken, die exakte Kopien der Quell-VMs zu einem bestimmten Zeitpunkt sind, befinden sich im ausgeschalteten Zustand auf dem zweiten Host.
Wenn ein Host ausfällt, sind die auf diesem Host ausgeführten VMs auch nicht erreichbar. Die VM-Repliken, die sich auf einem anderen Host befinden, werden dann vom Administrator eingeschaltet.
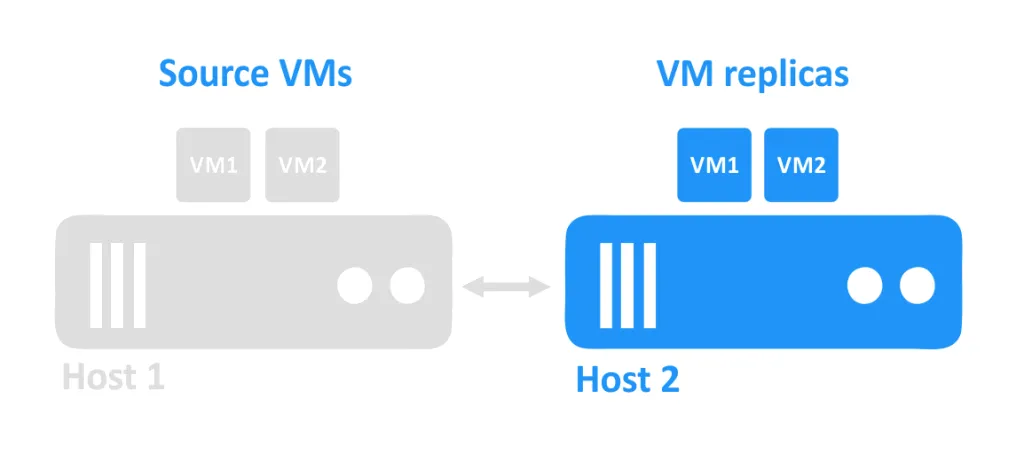
VM-Replikationsanforderungen
Die grundlegenden Anforderungen für die VM-Replikation sind zwei oder mehr Hosts und eine Replikationslösung. Eine Quell-VM, die auf dem ersten Host läuft, wird auf den zweiten Host repliziert. Die VM-Replik befindet sich auf dem zweiten Host.
Anwendungsfälle
Die Failover-Nutzung von VM-Replikationen kann bei Hardware- oder Softwarefehlern eingesetzt werden. Ausfälle von ESXi- oder Hyper-V-Hosts sind Beispiele für Hardwarefehler. Beispiele für Softwarefehler sind fehlgeschlagene Updates, Softwarefehler, Virenangriffe oder versehentliche Löschung von Dateien durch einen Benutzer.
Vorteile
Der Hauptvorteil eines VM-Failovers zu einer Replik ist die Möglichkeit eines Failovers zu einem entfernten Standort. Bei der Erstellung einer VM-Replik wird die von einer Quell-VM kopierte Daten über eine Netzwerkverbindung (mit begrenzter Bandbreite) an einen entfernten Standort übertragen. Der entfernte Standort kann sich in einem nahegelegenen Büro oder auf der anderen Seite der Welt befinden. Die VM-Replik kann sich auch am primären Produktionsstandort befinden.
Nachteile
Die Liste der Nachteile für einen Failover mit VM-Replikationen:
- Es gibt eine kurze Ausfallzeit zwischen einem Ausfall und dem Start der Replik auf dem zweiten Host.
- Der Failover muss manuell eingeleitet werden.
- Die seit der letzten Replikation geschriebenen Daten können bei einem ungeplanten Failover verloren gehen. Die VM-Replikation ist oft kein Echtzeitprozess (synchron), da die synchrone Replikation eine erhebliche Belastung der Ressourcen darstellt. Die Replikation wird in der Regel in regelmäßigen Zeitintervallen je nach gewählten Einstellungen durchgeführt.
- Die Netzwerkeinstellungen von VMs müssen bei einem Failover auf ein anderes Standort geändert werden. Die VM-Netzwerke auf dem Remote-Standort können sich von den Netzwerken auf dem primären Standort unterscheiden. Daher könnten auch die IP-Adressen unterschiedlich sein und müssen zusammen mit den anderen Netzwerkeinstellungen während des Failovers überprüft und geändert werden.
Clustering vs Replikation-basierter VM-Failover
| Failover mit Clustering | Failover mit Replikation | |
| Zweck | High Availability | Datenbankenverteidigung |
| Gegen | Nur Hardwarefehler | Hardware- und Softwarefehler |
| Verwaltung | Automatisch gestartet | Manuell gestartet |
| Downtime-Dauer (RTO) | Schneller Failover, somit kürzerer VM-Downtime (kurze RTO) | Längerer Failover, somit längerer VM-Downtime |
| Anforderungen | Mehr Anforderungen | Weniger Anforderungen |
| Lösungspreis | Clustering-Lösungen sind meist teurer | Replikationslösungen sind kostengünstiger |
| Datenverlust (RPO) | Näher bei Null-Datenverlust (sehr niedriger RPO) | Datenverlust hängt von der Häufigkeit der Replikation ab |
Kombinierte Nutzung von Clustern und Replikaten für VM-Failover
Cluster und Replikat-Failover-Lösungen werden manchmal als Alternativen betrachtet, aber sie können sich gegenseitig ergänzen. Lassen Sie uns einige Beispiele sehen, wie die gleichzeitige Nutzung beider Failover-Lösungen helfen kann, Ihre VMs sowohl gegen Serverfehler als auch gegen Störungen auf Standortebene zu schützen.
- Beispiel 1:Sie können VMs, die innerhalb eines Clusters ausgeführt werden, auf einem Rechner an einem entfernten Standort replizieren. Darüber hinaus können Sie VMs, die innerhalb eines Clusters ausgeführt werden, auf einem anderen Cluster replizieren. Dadurch bleiben die VMs online, wenn ein Rechner fehlschlägt, und der Failover-Cluster sie betreut. Wenn der gesamte Standort einen Stromausfall erlebt, können Sie auf die VM-Replikate, die auf einem entfernten Standort gespeichert sind, failoverten.
- Beispiel 2:Ein Virus beschädigt Dateien innerhalb einiger VMs. Ein Failover-Cluster kann solche Fehler nicht schützen. Aber wenn Sie VM-Replikate mit mehreren Wiederherstellungspunkten haben, können Sie jeden VM auf einen Zeitpunkt vor der Beschädigung oder Löschung ihrer Dateien zurückversetzen.
Verwendung der NAKIVO-Lösung für den automatischen VMware-VM-Failover auf Replikat
NAKIVO Backup & Replication ist eine Backup- und Disaster-Recovery-Lösung, die VMs schützen kann, die in einem Cluster ausgeführt werden, VMs replizieren, zu Repliken ausfallen und komplexe DR-Sequenzen orchestrieren kann. Cluster sowie eigenständige ESXi- oder Hyper-V-Hosts werden als Quell- und Zielpunkte für die Replikation unterstützt. Die Lösung verfolgt automatisch den Host, auf dem eine VM gehostet wird, damit sie diese VM replizieren kann. Dies ist nützlich, da VMs nach Failover-Ereignissen oder Lastausgleichsereignissen von einem Host zu einem anderen in einem Cluster migrieren können (ein Cluster ist normalerweise in Verbindung mit dem Lastausgleich konfiguriert). Aus diesem Grund muss die Software, die Sie für die Replikation einer VM aus einem Cluster verwenden, in der Lage sein, den Host zu verfolgen, auf dem die VM gehostet wird.
Die NAKIVO-Lösung kann die VM-Netzwerkeinstellungen automatisch bei einem Failover ändern. Verwenden Sie einfach die Funktionen für Network Mapping und Re-IP beim Konfigurieren eines Replikations- oder Failover-Jobs.
Betrachten wir ein Beispiel für einen automatisierten VM-Failover (mit Netzwerkzuordnung und Re-IP) in NAKIVO Backup & Replication. Wir beginnen damit, eine VM-Replik zu erstellen.
Konfigurieren der für den VM-Failover erforderlichen Replikation
Auf dem Jobs-Dashboard klicken Sie auf Erstellen > VMware vSphere Replikationsjob, wenn Sie eine VMware-Umgebung verwenden. Beachten Sie, dass Sie auf die gleiche Weise einen Replikationsjob für eine Microsoft Hyper-V-VM oder eine Amazon EC2-Instanz erstellen können.
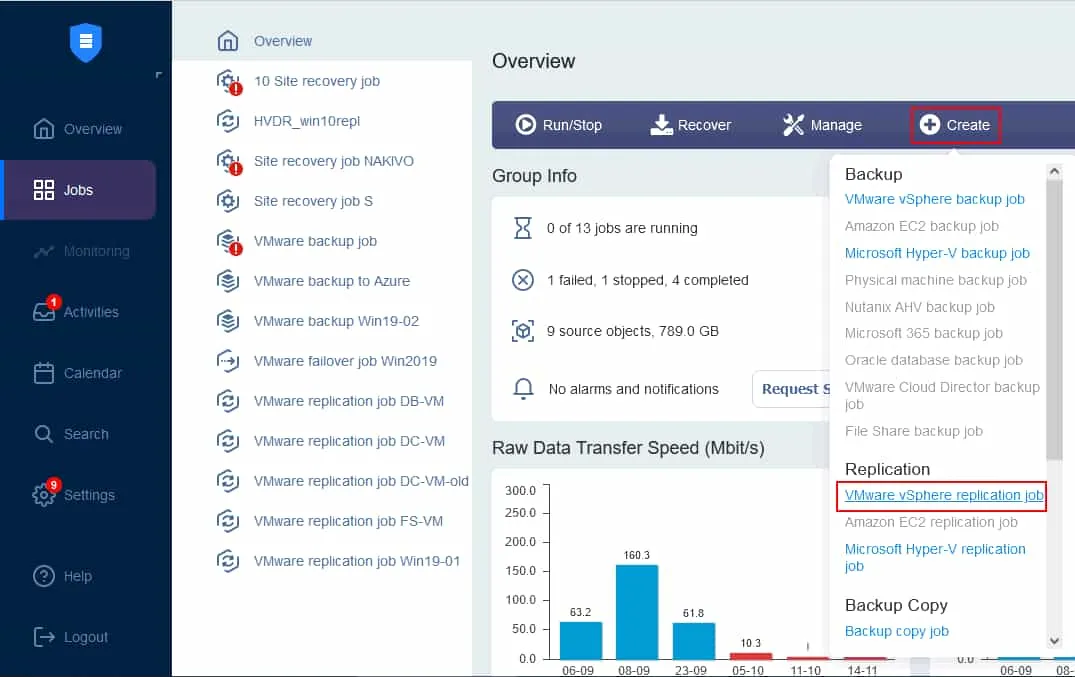
Der Replikations-Job-Assistent wird gestartet.
- Wählen Sie die virtuellen Maschinen aus, die Sie replizieren möchten. In diesem Beispiel wird die Server2019 VM, die das Betriebssystem Windows Server 2019 als Gastbetriebssystem ausführt, repliziert. Klicken Sie auf Weiter.
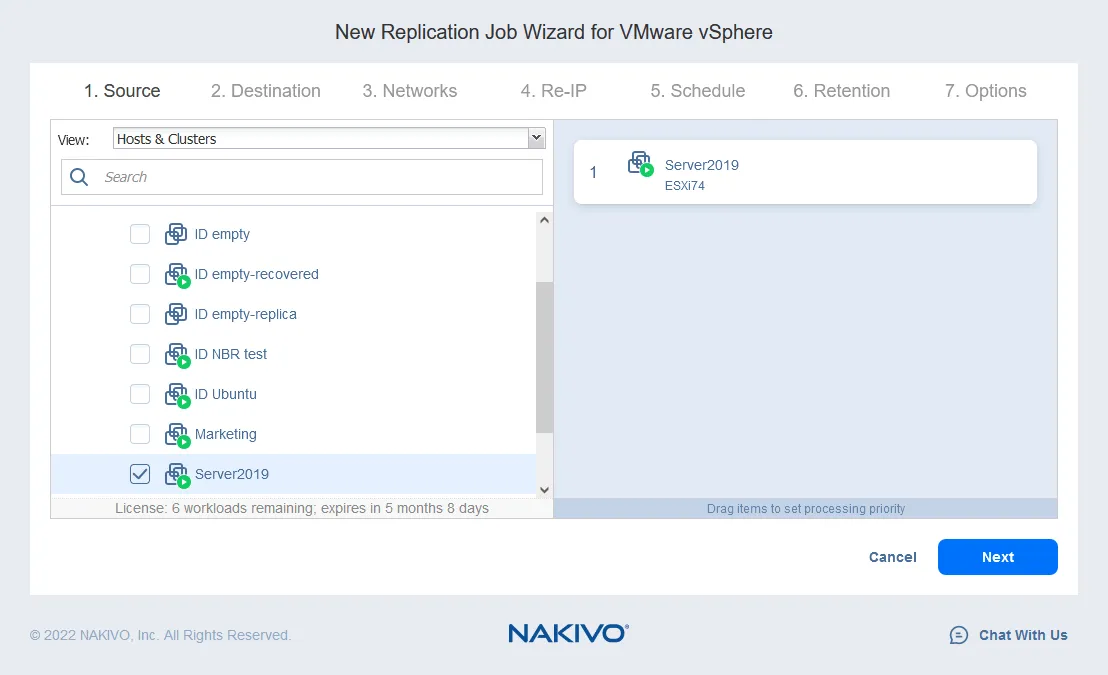
- Wählen Sie einen Zielhost für die VM-Replikation aus, auf dem die VM-Replikat ausgeführt werden soll (10.10.10.90 in unserem Fall). Wählen Sie das Datenstore, das dem ausgewählten Host für die Platzierung der VM-Dateien zugeordnet ist. Klicken Sie auf Weiter.
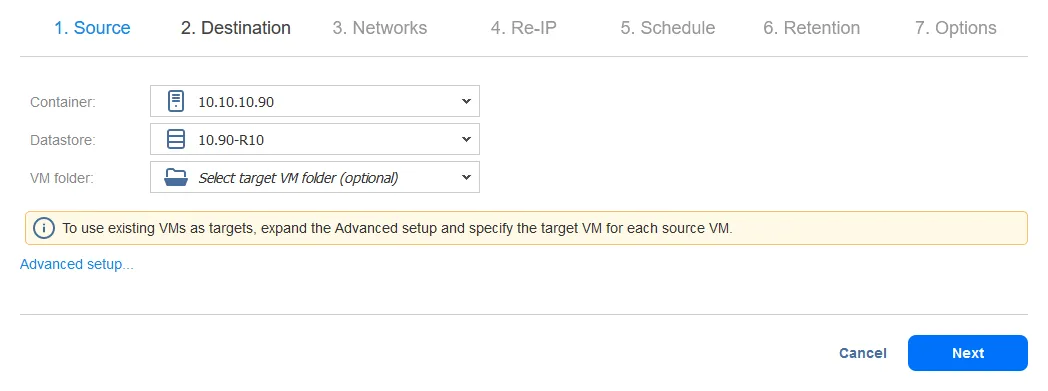
- Sie können Netzwerkzuordnung und Re-IP-Optionen beim Konfigurieren eines Replikationsauftrags oder eines Failover-Auftrags festlegen. In diesem Durchlauf werden Netzwerkzuordnung und Re-IP später konfiguriert, wenn der Failover-Auftrag konfiguriert wird. Sie können diesen Schritt daher vorerst überspringen und einfach auf Weiter klicken.
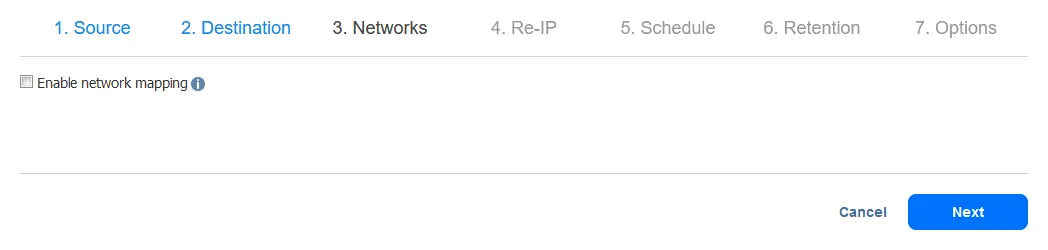
- Die Re-IP-Konfiguration wird während der Konfiguration des VM-Failover-Jobs in diesem Leitfaden erläutert. Klicken Sie auf Weiter.
- Wählen Sie Ihre Zeitplanungseinstellungen aus. Klicken Sie auf Weiter, wenn Sie fertig sind.
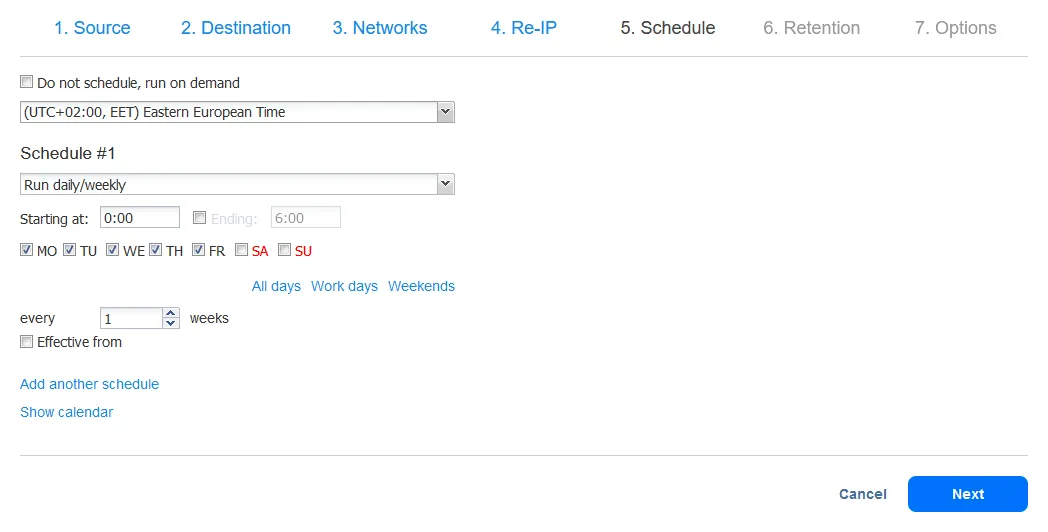
- Legen Sie die Aufbewahrungseinstellungen fest. Denken Sie daran, dass Sie die Großvater-Vater-Sohn-Aufbewahrungsrichtlinie in diesem Schritt einrichten können. Klicken Sie auf Weiter.
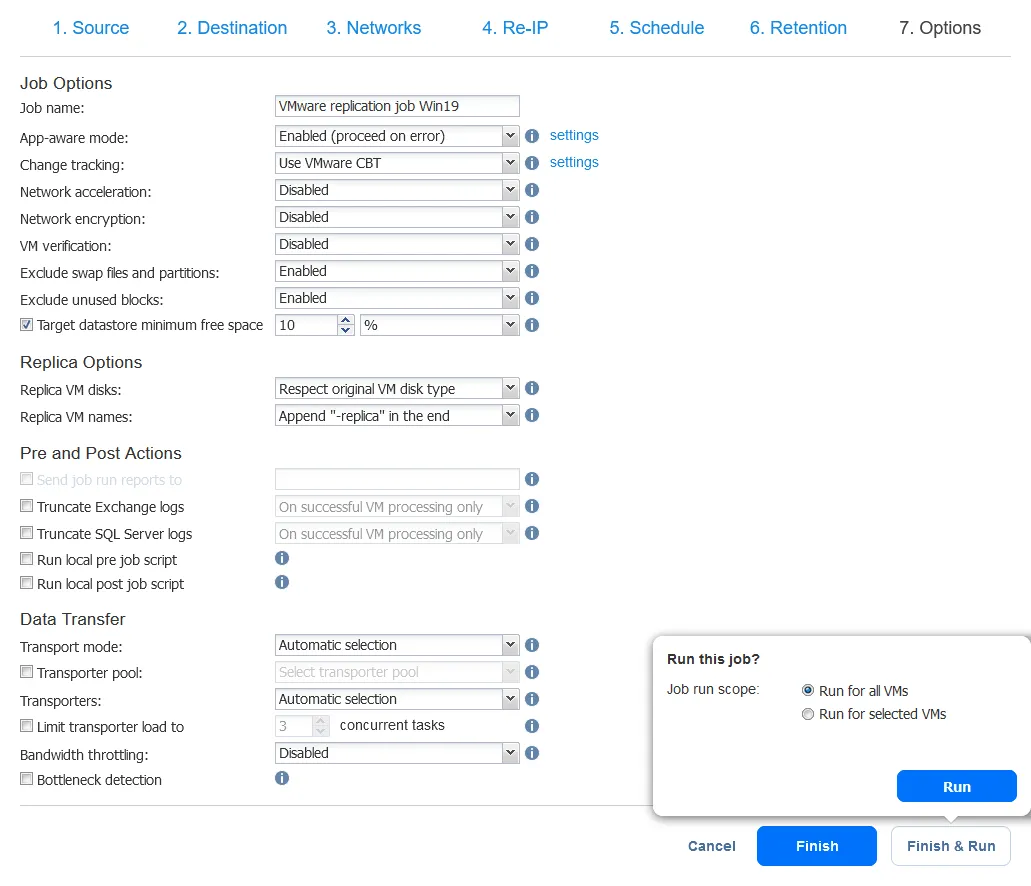
- Wählen Sie die Optionen für die Replikationsaufgabe aus und klicken Sie auf Fertigstellen oder auf den Knopf Fertigstellen & Ausführen. Warten Sie, während die Replikation erstellt wird.
VM-Failover einrichten
Nachdem Sie eine VM-Replikation erstellt haben, können Sie auf diese Replikation einen VM-Failover durchführen.
Auf der Startseite im Dashboard klicken Sie auf Wiederherstellen> VMware Vollwiederherstellung (VM-Replikations-Failover). Der Neue Failover-Aufgabenassistent wird geöffnet.
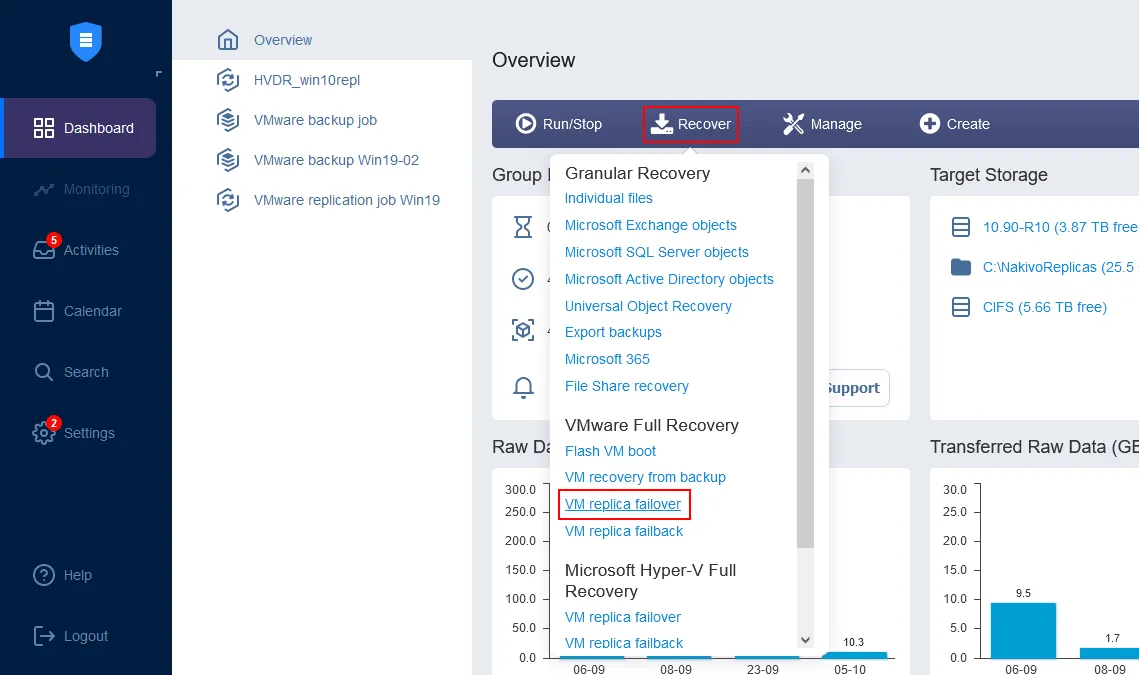
- Legen Sie im linken Bereich die VM-Replikation fest, die für den Failover verwendet werden soll. In dieser Übersicht wird die soeben erstellte Server2019-replica ausgewählt.Wählen Sie im rechten Bereich einen Wiederherstellungspunkt. In der Lösung ist der letzte Wiederherstellungspunkt standardmäßig ausgewählt. Klicken Sie auf Weiter.
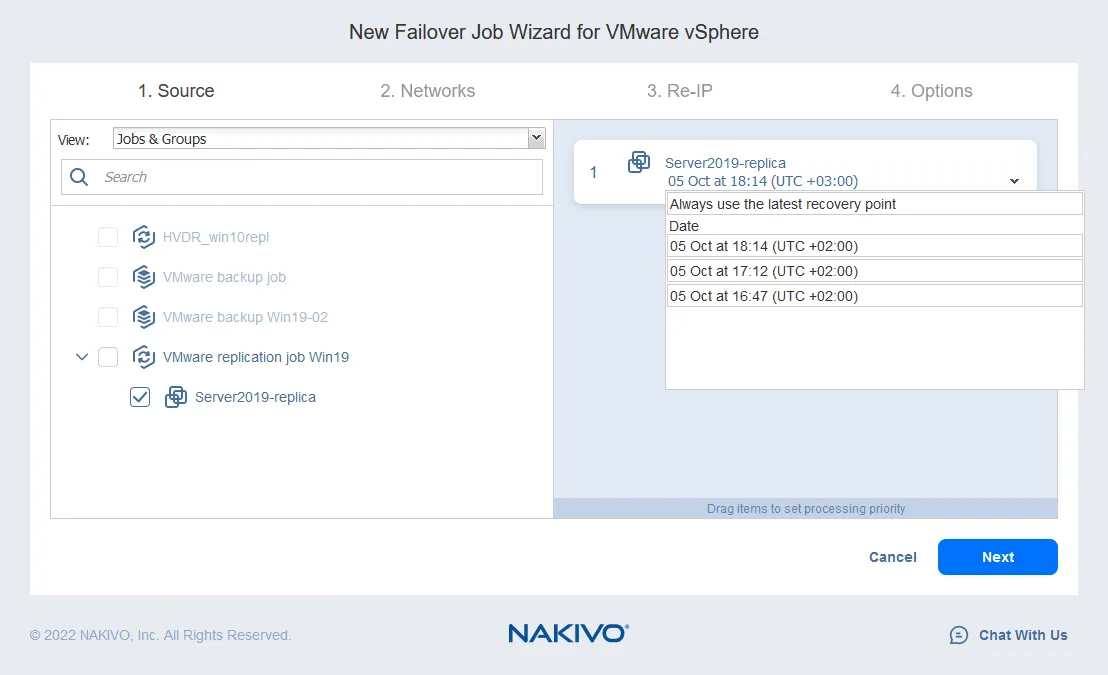
- Netzwerkmapping hilft Ihnen, das Netzwerk zu ändern, mit dem die VM verbunden ist. Die Quell- und Ziel-ESXi-Hosts haben wahrscheinlich unterschiedliche virtuelle Switch-Einstellungen. Da eine VM-Replikat eine exakte Kopie der Quell-VM ist, werden die virtuellen Netzwerke, mit denen die Quell-VM verbunden ist, im VM-Replikat beibehalten.
Im Allgemeinen sollten Sie die Netzwerkeinstellungen eines VM-Replikats überprüfen und manuell das Netzwerk ändern. NAKIVO Backup & Replication kann das Quellnetzwerk automatisch auf ein Zielnetzwerk abbilden. Sie müssen nur das Netzwerkmapping einrichten, wenn Sie den Replikations- oder Failover-Job konfigurieren.
- Um das Netzwerkmapping zu aktivieren, wählen Sie das Kontrollkästchen aus. Wenn Sie zuvor eine Netzwerkzuordnungsregel erstellt haben, können Sie auf Vorhandene Zuordnung hinzufügen klicken. Wenn keine Netzwerkzuordnungsregeln vorhanden sind, klicken Sie auf Neues Mapping erstellen.
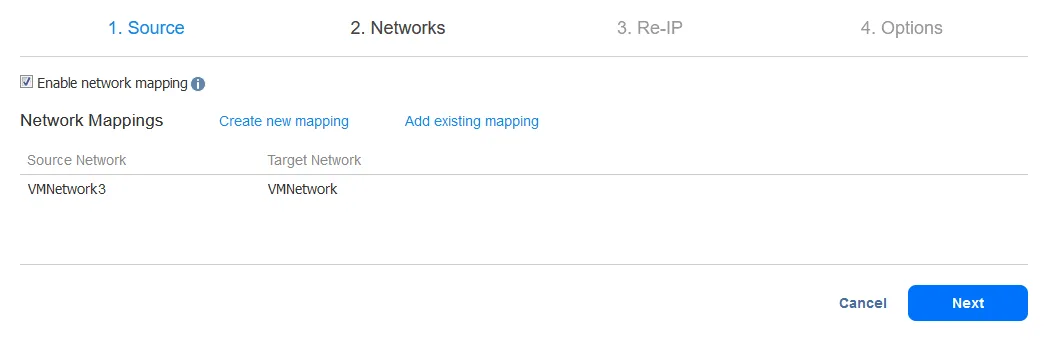
-
Um eine neue Netzwerkzuordnungsregel zu erstellen, wählen Sie das Quellnetzwerk und das Zielnetzwerk aus. Das Quellnetzwerk ist das Netzwerk, mit dem die Quell-VM verbunden ist. Das Zielnetzwerk ist das Netzwerk, mit dem das VM-Replikat verbunden sein soll.
Hinweis: Der Name des VM-Netzwerks ist nicht dasselbe wie die IP-Adresse oder Netzwerkadresse.
Klicken Sie auf Speichern, um die Netzwerkzuordnungsregel zu speichern, und klicken Sie dann auf Weiter, um die Konfiguration fortzusetzen.
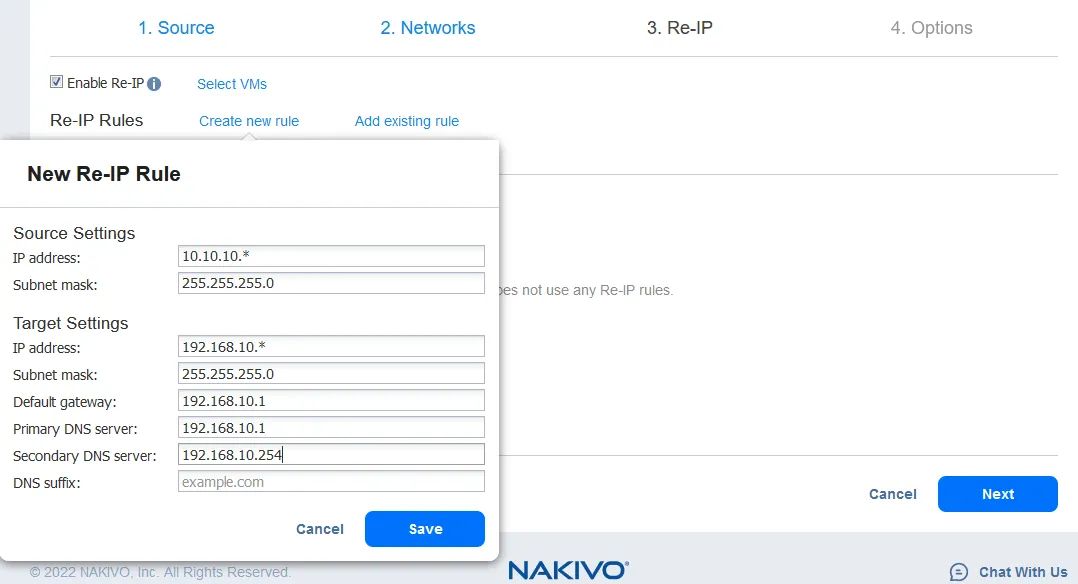
- Die Re-IP-Funktion ermöglicht es Ihnen, die IP-Einstellungen des VM-Replikats zu ändern. Sie kann für statische IP-Adressen verwendet werden. Wählen Sie das Kontrollkästchen Re-IP aktivieren aus, wenn Sie diese Option aktivieren möchten, und erstellen Sie dann eine Re-IP-Regel oder fügen Sie eine vorhandene Regel hinzu. Klicken Sie auf Neue Regel erstellen, wenn zuvor keine Regeln erstellt wurden. Es erscheint ein Popup-Menü.
- Die Quell-VM-Einstellungen sind die IP-Adresse und die Netzwerkmaske, die geändert werden müssen.
-
Die Ziel-Einstellungen sind die Einstellungen, die für das VM-Replikat angewendet werden sollen, wenn ein Failover auftritt. In diesem Beispiel deckt das [*]-Zeichen das letzte Oktett ab. Das [*] bezeichnet eine beliebige Zahl von 1 bis 254. Wenn die Quell-IP-Adressen beispielsweise 10.10.10.1, 10.10.10.96 und 10.10.10.222 sind, wären die Zieladressen entsprechend 192.168.10.1, 192.168.10.96 und 192.168.10.222. Das letzte Oktett der IP-Adresse wird beibehalten.
Klicken Sie auf Speichern, um Ihre Re-IP-Regel zu speichern und fortzufahren.
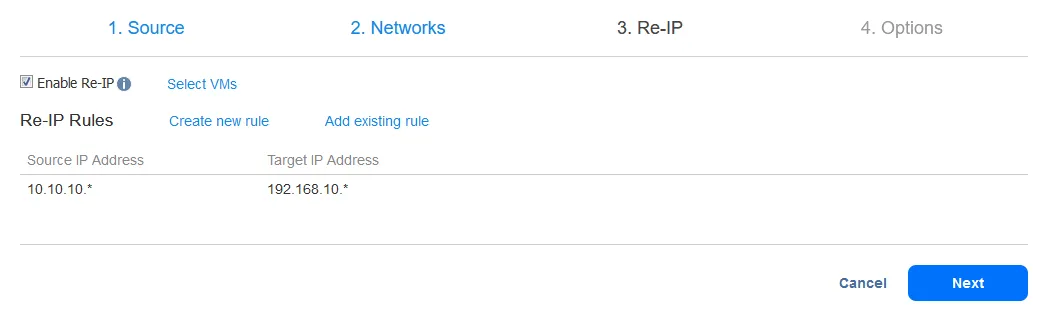
Nachdem Sie die Re-IP-Regel hinzugefügt haben, sollte Ihr Bildschirm so aussehen:
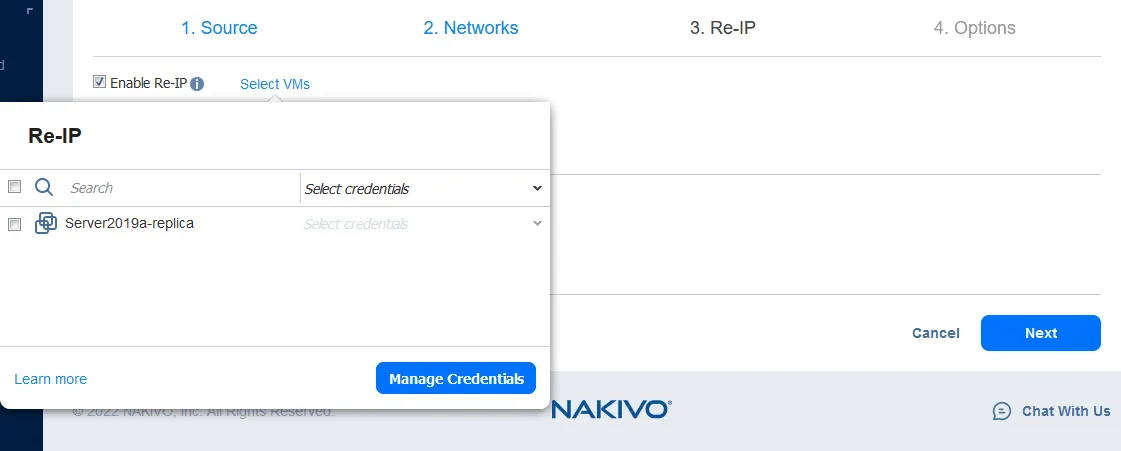
Wählen Sie nun die VMs aus, für die die Re-IP-Regeln angewendet werden sollen. Der Failover-Job in diesem Beispiel enthält nur ein VM-Replikat, also wählen Sie das entsprechende Kontrollkästchen aus.
Wählen Sie dann die Anmeldeinformationen für jede VM aus. Klicken Sie auf Anmeldeinformationen verwalten > Anmeldeinformationen hinzufügen, um neue Anmeldeinformationen hinzuzufügen. Die hinzugefügten Anmeldeinformationen können aus der Dropdown-Liste ausgewählt werden.
Hinweis: Die Anmeldeinformationen werden von NAKIVO Backup & Replication benötigt, um auf die Netzwerkeinstellungen des Betriebssystems innerhalb der VM zuzugreifen und das Skript anzuwenden, das diese Einstellungen ändert. VMware Tools müssen auf VMware vSphere-VMs installiert sein, und Hyper-V Integration Services müssen auf Microsoft Hyper-V-VMs installiert sein.
Wenn Sie alle diese Einstellungen konfiguriert haben, klicken Sie auf Weiter.
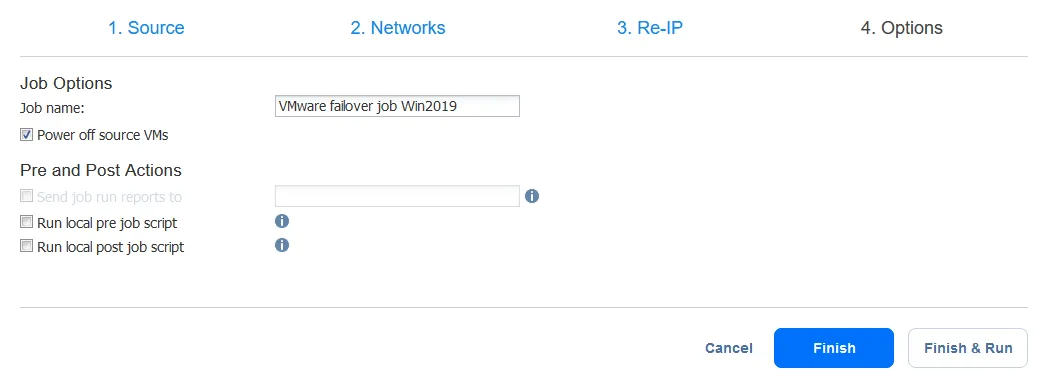
- Konfigurieren Sie nun die Optionen für den VM-Failover-Job. Sie können das Kontrollkästchen Quell-VMs ausschalten auswählen. Dies kann nützlich sein, um Konflikte bei IP-Adressen zu verhindern, wenn sowohl Quell- als auch Replikat-VMs dasselbe Netzwerk verwenden oder dieselben IP-Adressen haben. Nachdem Sie alle Optionen konfiguriert haben, klicken Sie auf Beenden & Ausführen.
Warten Sie, bis der VM-Failover-Job abgeschlossen ist.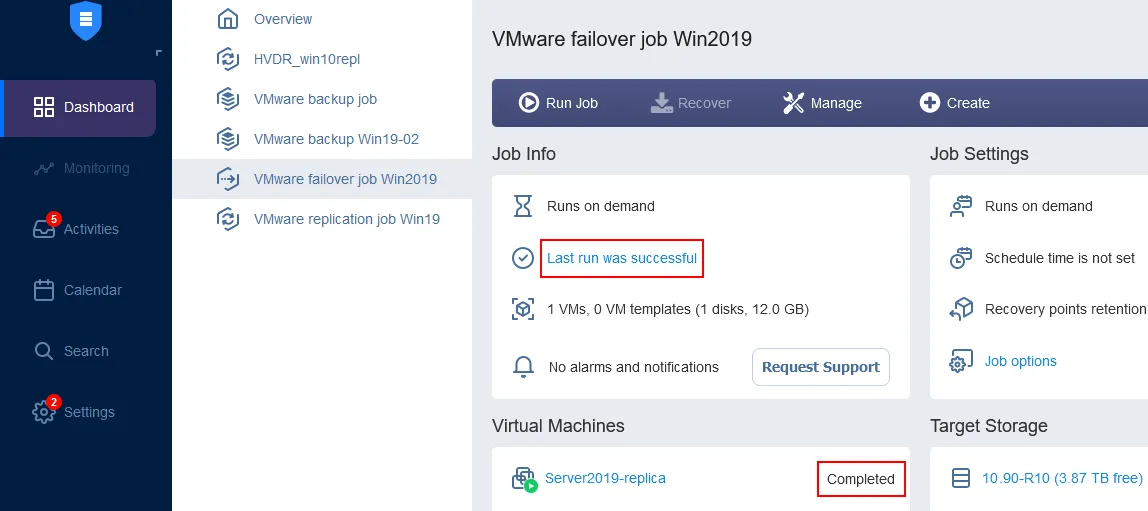
Jetzt können Sie sicherstellen, dass das VM-Replikat läuft. Gehen Sie zu Konfiguration > Bestand und klicken Sie auf die Schaltfläche Alle aktualisieren. Nach der Aktualisierung können Sie sehen, dass die VM Server2019-replica bereits auf dem Ziel-ESXi-Host läuft. Sie können auch die Anmeldeinformationen, Netzwerkzuordnungsregeln und Re-IP-Regeln von dieser Seite (der Bestand-Seite) aus verwalten.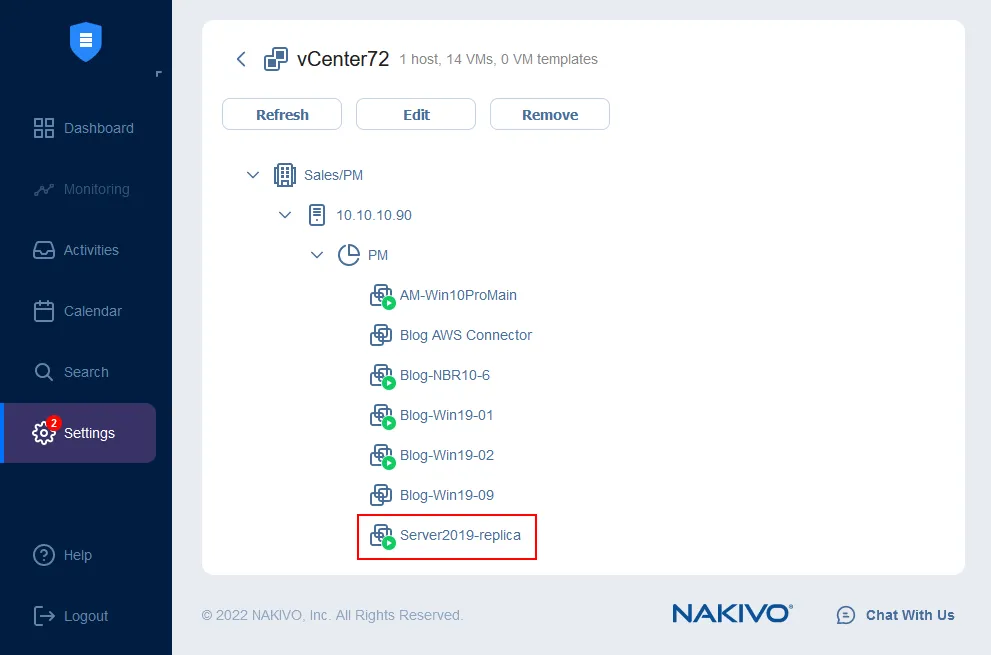
Fazit
VM-Failover ist nützlich für Katastrophenszenarien mit vielen virtuellen Maschinen oder zur Wiederherstellung auch einer VM, um die operative Kontinuität und hohe Verfügbarkeit sicherzustellen. Es ist jedoch wichtig zu verstehen, dass jeder Notfallwiederherstellungsplan mit einer soliden Backup-Strategie für eine zuverlässigere und effizientere Datensicherung verbunden sein sollte.
Erwägen Sie den Einsatz von NAKIVO Backup & Replication, einer schnellen, zuverlässigen und erschwinglichen VM-Schutzlösung, um VMs mithilfe der Failover-zu-Replika-Methode zu schützen. Die Lösung unterstützt auch Backup und granulare Wiederherstellung für virtuelle, physische, Cloud- und SaaS-U
- Um das Netzwerkmapping zu aktivieren, wählen Sie das Kontrollkästchen aus. Wenn Sie zuvor eine Netzwerkzuordnungsregel erstellt haben, können Sie auf Vorhandene Zuordnung hinzufügen klicken. Wenn keine Netzwerkzuordnungsregeln vorhanden sind, klicken Sie auf Neues Mapping erstellen.