













De beschikbaarheid van VM’s is essentieel voor het waarborgen van de bedrijfscontinuïteit. Wanneer de services die draaien op bedrijfs- en missiekritieke VM’s niet beschikbaar zijn, kunnen bedrijven geld verliezen en het vertrouwen van klanten verliezen. Om de beschikbaarheid van VM’s onmiddellijk na een storing te herstellen, moet u geschikte failover-technieken gebruiken.
Failover naar een VM-replica kan deel uitmaken van rampenherstel om gegevens en operaties te herstellen met minimale verstoring van reguliere workflows. Het VM-failoverproces moet worden beschreven in de bedrijfscontinuïteit en rampenherstel (BCDR) van een organisatie. Laten we de soorten VM-failover en gebruiksscenario’s eens nader bekijken.
Wat is failover?
Failover is het proces waarbij een virtuele machine (VM) wordt hervat op een secundair systeem (en soms op een secundaire locatie) na een storing van het primaire systeem. Het secundaire systeem bevat alle benodigde gegevens om de bedrijfsvoering te handhaven. Een systeem in deze context kan een server, database, virtuele machine, enz. zijn.
In virtuele omgevingen zijn er twee veelvoorkomende failover-methoden:
- Het gebruik van een VM-replica (meestal gelegen op een andere virtualisatieserver) wordt gebruikt om failover uit te voeren als een primaire VM mislukt
- Het gebruik van een failover-cluster (geen replicatie vereist)
Failover vereist minder tijd om taken terug te zetten in vergelijking met herstel van een back-up, waardoor u een lager doelstelling voor herstelduur (RTO) kunt behalen. Echter, het gebruik van VM-replicatie of clustering verwijdert niet de behoefte aan het maken van VM-back-ups. Een back-up (meestal gecomprimeerd) is handig als u gegevens moet herstellen vanaf de oude herstelpunt.
Laten we de basistermijnen voor VM-failover over replicatie-gebaseerde katastrofherstel doorlopen.
Glossarium voor failover
- Fout:Elke problemen met hardware of software als gevolg van een systeemstoring, stroomuitval, netwerkproblemen, crypto-aanval, enzovoort, die een systeem offline brengt.
- Primair systeem:Het systeem dat live-operaties uitvoert in de productieomgeving.
- Secundair systeem:Het redundante stand-by systeem, dat regelmatig kopieën van het primaire systeem bijwerkt. Het secundaire systeem kan op de locatie of op een afgelegen locatie gehost worden.
- Replicatie:Het essentiële proces om voorbereid op VM-failover. Replicatie maakt een exacte kopie, dus een replica, van het primaire VM voor een bepaald punt in de tijd.
- VM Failback: Failback is het proces van terugkeren naar het primaire systeem vanuit de replica VM nadat het incident is opgelost.
Failovertypen
Er zijn drie typen van failover:
- A planned failover is used for scheduled migrations of workloads from one system/site to another. Use cases include performing maintenance on the primary system, electrical works performed at the production site, and expected disaster scenarios. For example, a weather alert about a tornado may require a planned failover to ensure availability.
- Een ongeplande failover is een failover die wordt uitgevoerd wanneer er een onverwachte storing optreedt waardoor een kritieke VM of de gehele primaire locatie offline gaat. De storing kan worden veroorzaakt door een aantal natuurlijke rampen, ongelukken (een stroomstoring), een malware-aanval of enig ander incident. Voor een ongeplande failover moeten hosts en replica’s van tevoren zijn voorbereid.
- A test failover, as the name suggests, is used for testing purposes. Testing scenarios can include rehearsing unplanned failover scenarios to ensure that
De failoversequentie
Tijdens een VM-failover zijn de failoversequentie van acties en de opstartvolgorde van VM’s essentieel om een succesvolle hervatting van workflows te waarborgen. Ze moeten worden gedefinieerd in de ontwikkelingsfase van het rampenherstelplan van uw organisatie. De sequentie moet de afhankelijkheden tussen verschillende services die op verschillende VM’s draaien vastleggen.
Zo kan bijvoorbeeld de authenticatie voor sommige services en applicaties die op VM’s draaien, gebruikmaken van Active Directory, dat op een andere VM draait. Een databaseserver kan op de eerste VM draaien, een applicatieserver op de tweede en de webserver op de derde.
De VM met de Active Directory-server moet eerst worden gestart. Vervolgens kunnen de VM’s met services die Active Directory gebruiken voor authenticatie worden gestart. De VM met de databaseserver moet worden gestart voordat de VM met de toepassingsserver wordt gestart, omdat de toepassingsserver verbinding maakt met de database. Zodra de VM’s met de databaseserver en de toepassingsserver zijn gestart, kan de VM met de webserver worden gestart.
Belangrijkste Oplossingen voor Uitval
De belangrijkste oplossingen die worden gebruikt in virtuele omgevingen zijn:
- failover-clustering
- failover met behulp van VM-replica’s
Laten we ze elk overwegen.
Oplossing 1. Failover-clustering
A failover cluster is a group of at least two servers or nodes that are configured to take over workloads when one node is down or unavailable. Clustering is an enterprise-class automated solution that can be used for the most important, business-critical VMs. Microsoft Hyper-V offers a Failover Cluster made up of several Hyper-V hosts. VMware’s equivalent is a High Availability cluster, which is made up of ESXi hosts.
In het eerste diagram hieronder zie je een cluster waarin beide hosts (ook wel nodes genoemd) correct functioneren. De VM’s worden uitgevoerd op hosts en de VM-bestanden bevinden zich op gedeelde opslag die toegankelijk is voor beide hosts.
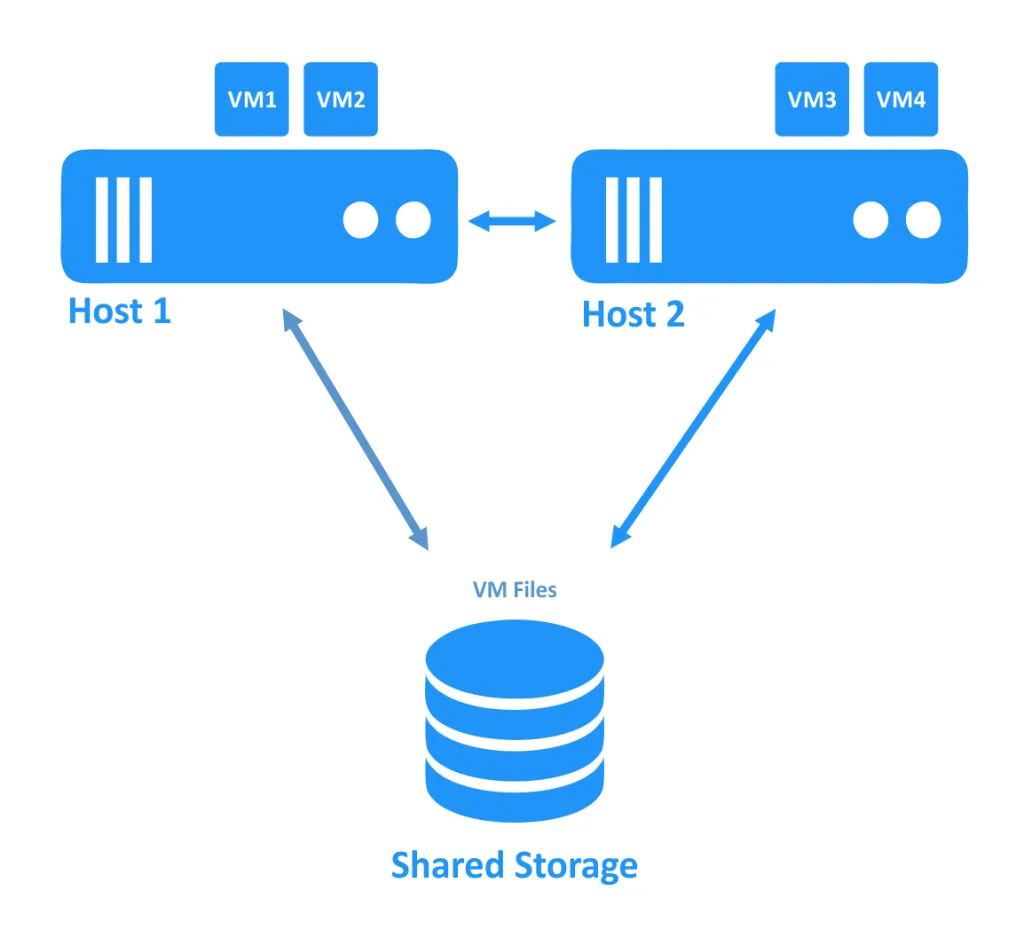
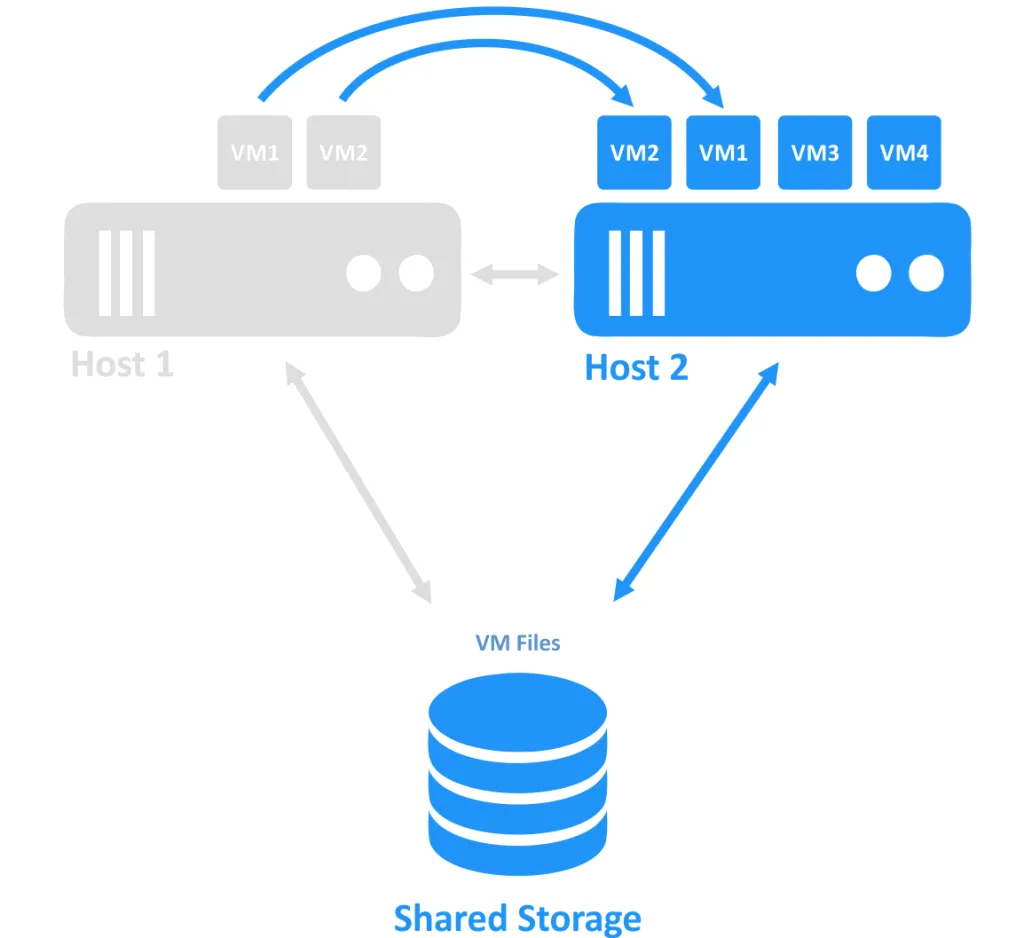
Wanneer een van de hosts uitvalt, wordt het eigendom van de verbinding met de VM (die werd uitgevoerd op de offline node) overgedragen naar een andere node die nog online is. Dit is het failoverproces. Een zeer beschikbare VM moet mogelijk opnieuw worden opgestart.
Vereisten voor failover-clustering
Om een failover-cluster te bouwen, moeten de volgende vereisten worden voldaan:
- Gedeelde opslag verbonden met de hosts via een toegewijd hoogwaardig netwerk met lage latentie. Er moet een geclusterd bestandssysteem worden gebruikt om ervoor te zorgen dat meerdere hosts gelijktijdig toegang kunnen krijgen tot de gegevens die op de opslag zijn opgeslagen.
- De hosts waarop de VM’s draaien, moeten dezelfde hardware hebben of op zijn minst hardware van dezelfde familie. De processoren moeten dezelfde instructiesets ondersteunen om compatibiliteit te garanderen, zodat de VM’s na migratie van de ene host naar de andere tijdens failover correct kunnen worden uitgevoerd.
- A high-speed redundant network with low latency. There should be multiple, separate cluster networks, that is, a cluster must have different networks for storage, management, VM migration, connection of hosts amongst each other, etc.
Gebruikssituaties
Failover-clusters worden gebruikt om VM’s te herstellen bij serverstoringen en bieden hoge beschikbaarheid voor kritieke VM’s. Als een van de hosts (die knooppunten worden genoemd) binnen een cluster uitvalt, migreren (failover) de VM’s die op de defecte host draaiden naar andere gezonde hosts. Afhankelijk van uw instellingen kunnen de overgezette VM’s na oplossing van de storing weer worden gemigreerd naar de host waarop ze voor het incident draaiden.
Voordelen
A failover cluster has advantages that provide strong protection:
- A failover cluster provides automatic VM failover. You don’t need to start the failed VMs manually on other hosts.
- Bij failover is er bijna geen dataverlies. De downtime is meestal beperkt tot de tijd die nodig is om de VM, het besturingssysteem (OS) en de software die op de VM draait, te laden.
- De Fault Tolerance-functie die is inbegrepen in de VMware High Availability-cluster zorgt voor VM-failover zonder downtime en zonder dataverlies.
Nadelen
A failover cluster does not protect against:
- Softwarestoring van VM’s. Softwarefouten of virussen kunnen een systeemcrash veroorzaken in een VM.
- Per ongeluk verwijderen van bestanden binnen de VM.
- Gedeelde opslagstoring. De cluster faalt als de gedeelde opslag faalt. De gedeelde opslag is een cruciaal onderdeel van de cluster; de virtuele schijven die toebehoren aan de VM’s binnen een cluster worden opgeslagen op de gedeelde opslag.
- A disaster that makes the whole physical site unavailable.
Voor meer informatie over wat een failover-cluster is, lees de complete gids over VMware clustering.
Oplossing 2. Failover met behulp van VM-replica’s
VM-failover die vertrouwt op VM-replica’s kan worden uitgevoerd door gespecialiseerde toepassingen, die de VM’s kunnen repliceren en de replica’s kunnen starten wanneer de beheerder dat aangeeft. Naast dataprotectiesoftware heeft u ESXi- of Hyper-V-hosts nodig (afhankelijk van uw omgeving) die van tevoren zijn voorbereid om de VM-replica’s uit te voeren wanneer de bron-VM’s falen.
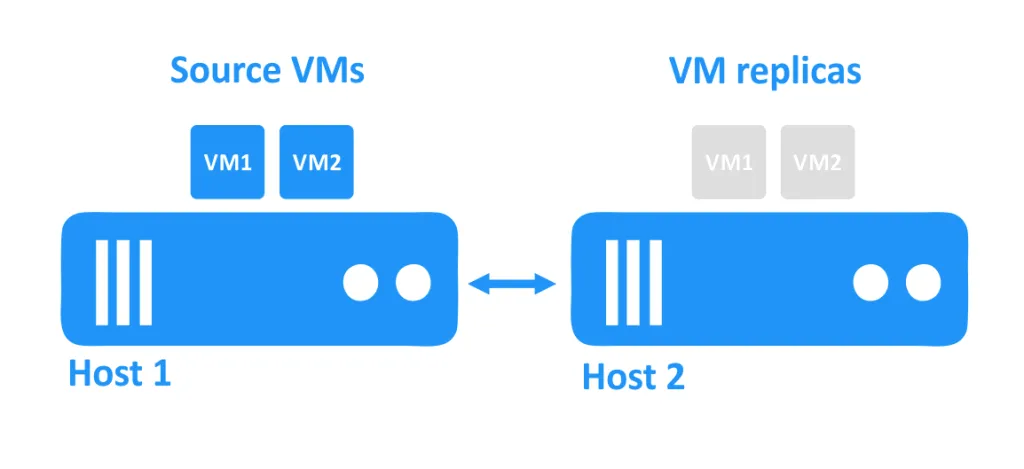
In het onderstaande diagram ziet u twee hosts die met elkaar verbonden zijn via het netwerk. De VM’s gebruiken de schijven van de hosts. De bron-VM’s draaien op de eerste host, en de VM-replica’s, die exacte kopieën zijn van de bron-VM’s op een bepaald tijdstip, bevinden zich op de tweede host in een uitgeschakelde staat.
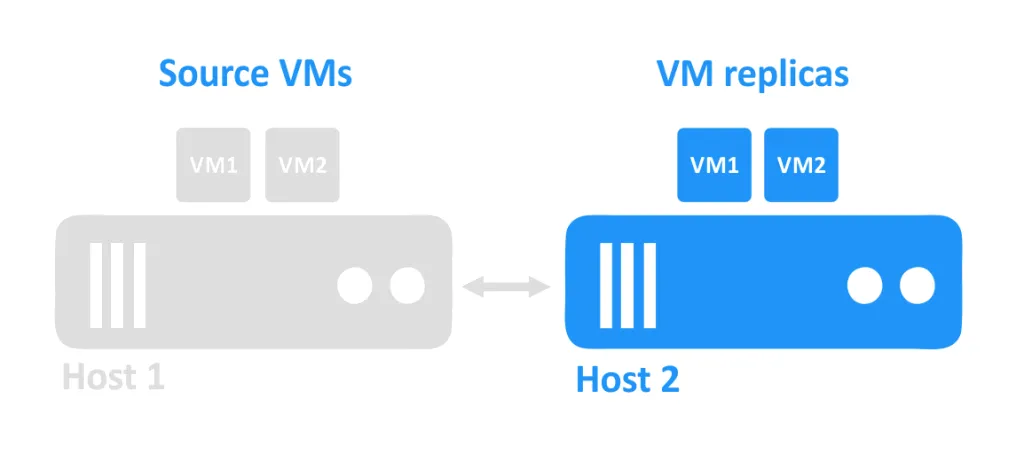
Wanneer een host uitvalt, worden de VM’s die op die host draaiden ook onbereikbaar. De VM-replica’s die zich op een andere host bevinden, worden vervolgens door de beheerder ingeschakeld.
VM-replicatievereisten
De basisvereisten voor virtuele machine (VM) replicatie zijn twee of meer hosts en een replicatiesolution. Een bron VM die draait op het eerste host wordt geredigeerd naar het tweede host. De VM-kopie bevindt zich op het tweede host.
Gebruiksgevallen
Failover met behulp van VM-kopieën kan worden gebruikt bij hardware- of softwarefouten. Een ESXi of Hyper-V hostfout is een voorbeeld van hardwarefout. Voorbeelden van softwarefouten kunnen zijn mislukte updates, software bugs, virusaanvallen of het per ongeluk verwijderen van bestanden door een gebruiker.
Voordelen
Het voordeel van VM-failover naar een kopie is de mogelijkheid van failover naar een externe locatie. Wanneer een VM-kopie wordt gemaakt, wordt de gegevens van de bron VM via een netwerkverbinding (met beperkte bandbreedte) naar een externe locatie verzonden. De externe locatie kan een dichtbijgelegen kantoor of op de andere kant van de wereld zijn. De VM-kopie kan ook op het primaire productiesite zijn geplaatst.
Nadelen
De lijst met nadelen voor een failover met behulp van VM-kopieën:
- Er is een korte periode van downtime tussen een fout en het opstarten van de kopie op het tweede host.
- Failover moet handmatig worden ingesteld.
- De gegevens die sinds de laatste replicatie zijn geschreven, kunnen verloren gaan tijdens een ongeplande failover. VM-replicatie is vaak geen echte tijdproces (synchronisch), aangezien synchronische replicatie een significante belasting op resources plaatst. Replicatie wordt meestal op regelmatige tijdintervallen uitgevoerd, afhankelijk van uw gekozen instellingen.
- De netwerkinstellingen van de VM’s moeten vaak worden gewijzigd bij failover naar een andere locatie. De VM-netwerken van de externe locatie kunnen verschillen van de netwerken van de primaire locatie. Daarom kunnen de IP-adressen ook verschillend zijn en moeten ze worden gecontroleerd en gewijzigd samen met de andere netwerkinstellingen tijdens failover.
Clusteren vs Replicatiegebaseerde VM-failover
| Failover met clustering | Failover met behulp van een replica | |
| Doel | Hoge beschikbaarheid | Rampenherstel |
| Bescherming tegen | Alleen hardwarestoringen | Hardware- en softwarestoringen |
| Beheer | Automatisch gestart | Handmatig gestart |
| Duur van downtime (RTO) | Failover is sneller, dus de VM-downtime is kort (korte RTO) | Failover kost meer tijd, dus de VM-downtime is langer |
| Vereisten | Meer vereisten | Minder vereisten |
| Oplossingsprijs | Clusteroplossingen zijn meestal duurder | Replicatieoplossingen zijn kostenefficiënter |
| Data verlies (RPO) | Nagenoeg geen dataverlies (zeer lage RPO) | Data verlies is afhankelijk van de frequentie van replicatie |
Gecombineerd gebruik van clusters en replica’s voor VM-failover
Cluster- en replicafailoveroplossingen worden soms gezien als alternatieven, maar ze kunnen elkaar aanvullen. Laten we eens kijken naar enkele voorbeelden van hoe het gebruik van beide failoveroplossingen kan helpen om uw VM’s te beschermen tegen zowel server- als site-level storingen.
- Voorbeeld 1: U kunt de VM’s die binnen een cluster draaien repliceren naar een host op een externe locatie. Bovendien kunt u de VM’s die binnen één cluster draaien repliceren naar een ander cluster. Als een host uitvalt, houdt de failover-cluster die VM’s online. Als de hele locatie een storing ondervindt, kunt u overschakelen naar de VM-replica’s die zijn opgeslagen op een externe locatie.
- Voorbeeld 2: Een virus beschadigt bestanden in sommige VM’s. Een failover-cluster kan niet beschermen tegen dergelijke storingen. Maar als u VM-replica’s heeft met meerdere herstelpunten, kunt u elke VM herstellen naar een tijdstip voordat hun bestanden beschadigd of verwijderd waren.
Het gebruik van de NAKIVO-oplossing voor geautomatiseerde VMware-VM-failover naar replica’s
NAKIVO Backup & Replication is een oplossing voor back-up en katastrofherstel die virtuele machines (VM’s) die binnen een cluster draaien, kan beschermen, VM’s kopieert, overschakelt naar kopieën en complexe katastrofherstelsequenties orkestreert. Clusters, evenals standalone ESXi of Hyper-V hosts, worden ondersteund als bron- en bestemmingspunten voor replicatie. De oplossing volgt automatisch de host waarop een VM zich bevindt, zodat die VM gekopieerd kan worden. Dit is nuttig omdat VM’s na een overschakeling of een belastingevenement (een cluster wordt vaak geconfigureerd samen met belastingevenementen) van een host naar een andere host kunnen migreren binnen een cluster. Dat’s waarom de software die u gebruikt om een VM uit een cluster te kopiëren, moet in staat zijn de host te volgen waar de VM zich bevindt.
De NAKIVO oplossing kan de netwerkinstellingen van een VM automatisch wijzigen nadat er een overschakeling is gebeurd; gebruik de Netwerktoewijzing en herbouw IP-functies bij het configureren van een replicatie- of overschakelingstaak.
Laten we een voorbeeld bekijken van Automatische VM-overloop (met Netwerktoewijzing en herbouw IP) in NAKIVO Backup & Replication. We beginnen door een VM-kopie te maken.
Configureer replicatie nodig voor VM-overschakeling
Op het dashboard voor taken, klik op Aanmaken > VMware vSphere-replicatietaak als u een VMware virtuele omgeving heeft. Noteer dat u een replicatietaak voor een Microsoft Hyper-V VM of een Amazon EC2-instance op dezelfde manier kunt maken.
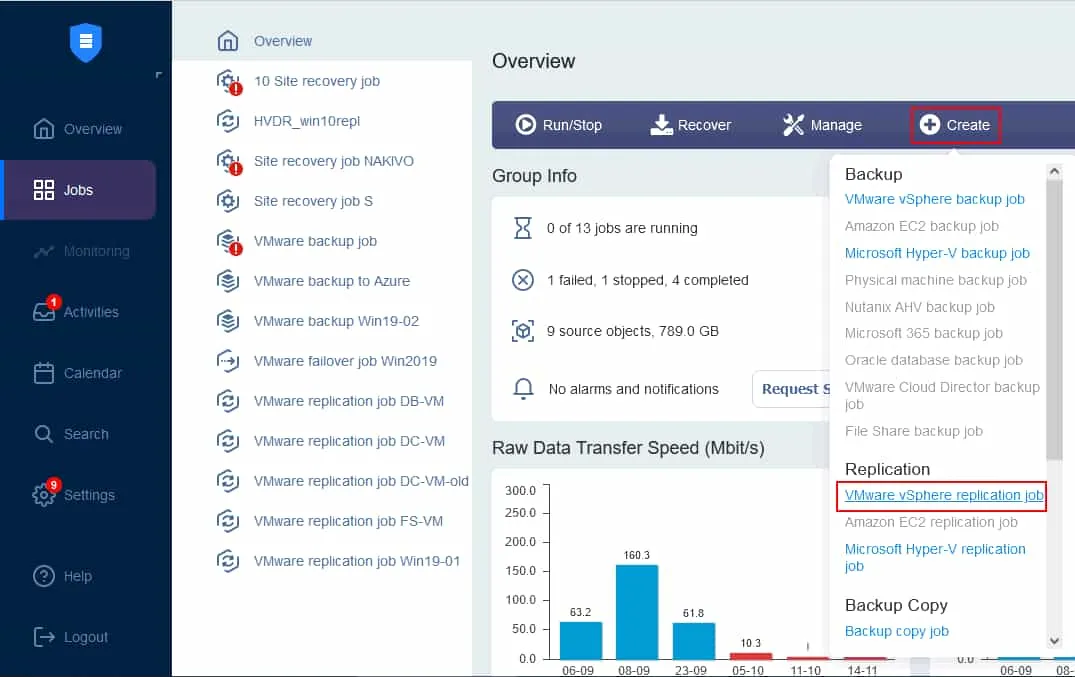
De replicatietaakassistent wordt gestart.
- Selecteer de virtuele machines die je wilt repliceren. In dit voorbeeld zal de Server2019 VM, die draait op het Windows Server 2019 besturingssysteem, gerepliceerd worden. Klik op Volgende.
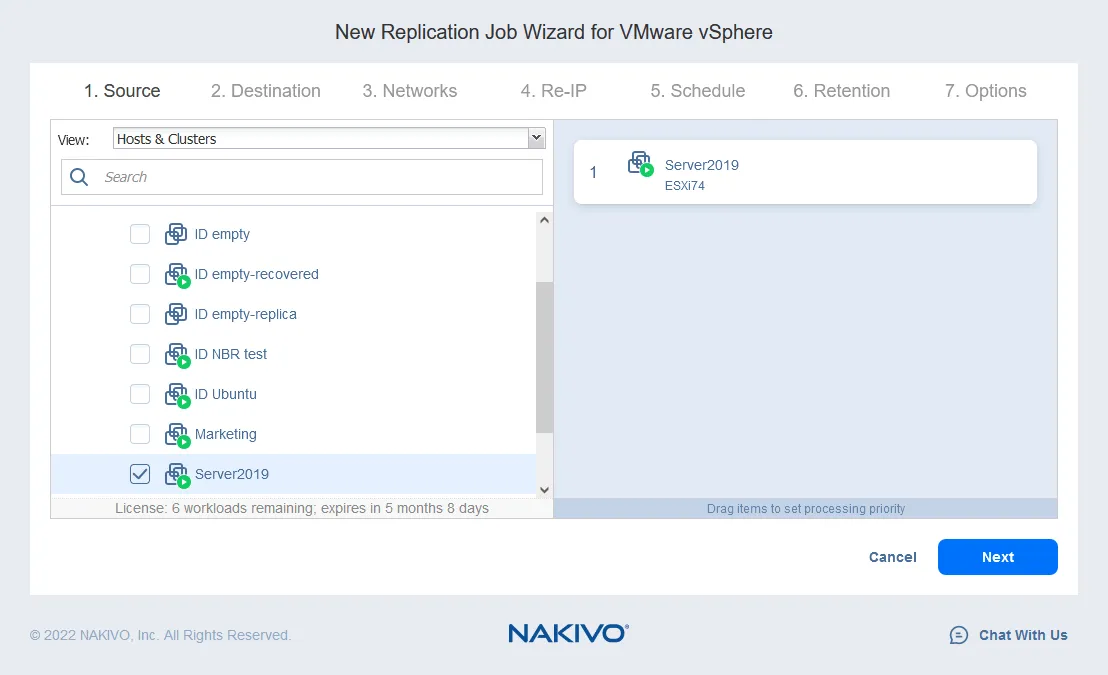
- Selecteer een bestemmingshost voor de VM-replica om op te draaien (10.10.10.90 in ons geval). Selecteer het datastore dat aan de geselecteerde host is gekoppeld voor plaatsing van de VM-bestanden. Klik op Volgende.
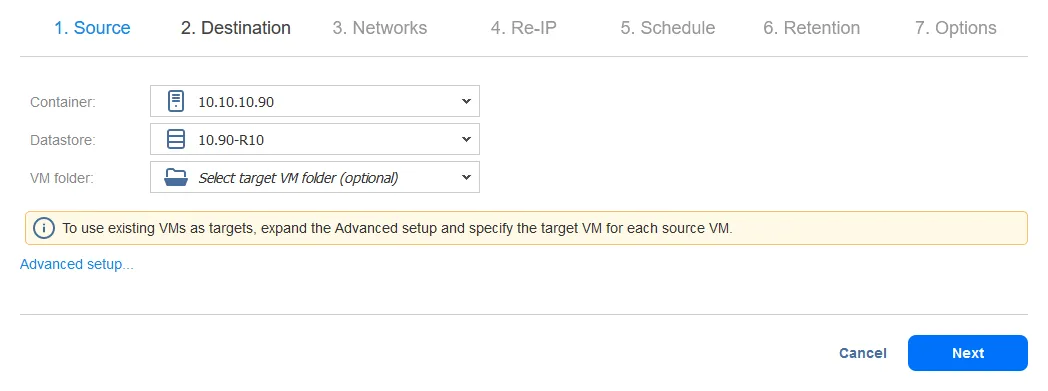
- Je kunt Netwerkmapping en Re-IP opties instellen bij het configureren van een replicatiejob of een failoverjob. In deze walkthrough zullen Netwerkmapping en Re-IP later geconfigureerd worden wanneer de failoverjob is geconfigureerd. Daarom kun je deze stap voorlopig overslaan en gewoon op Volgende klikken.
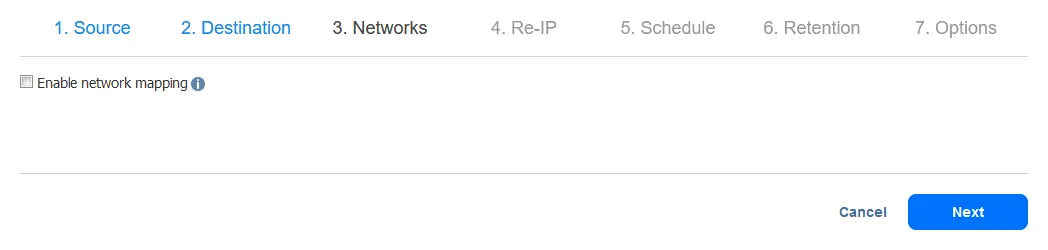
- De Re-IP-configuratie wordt uitgelegd tijdens de configuratie van de VM failover-taak in deze handleiding. Klik op Volgende.
- Selecteer uw planninginstellingen. Klik op Volgende wanneer u klaar bent.
- Stel de retentie-instellingen in. Onthoud dat u de retentiebeleid van grootvader-vader-zoon kunt instellen in deze stap. Klik op Volgende.
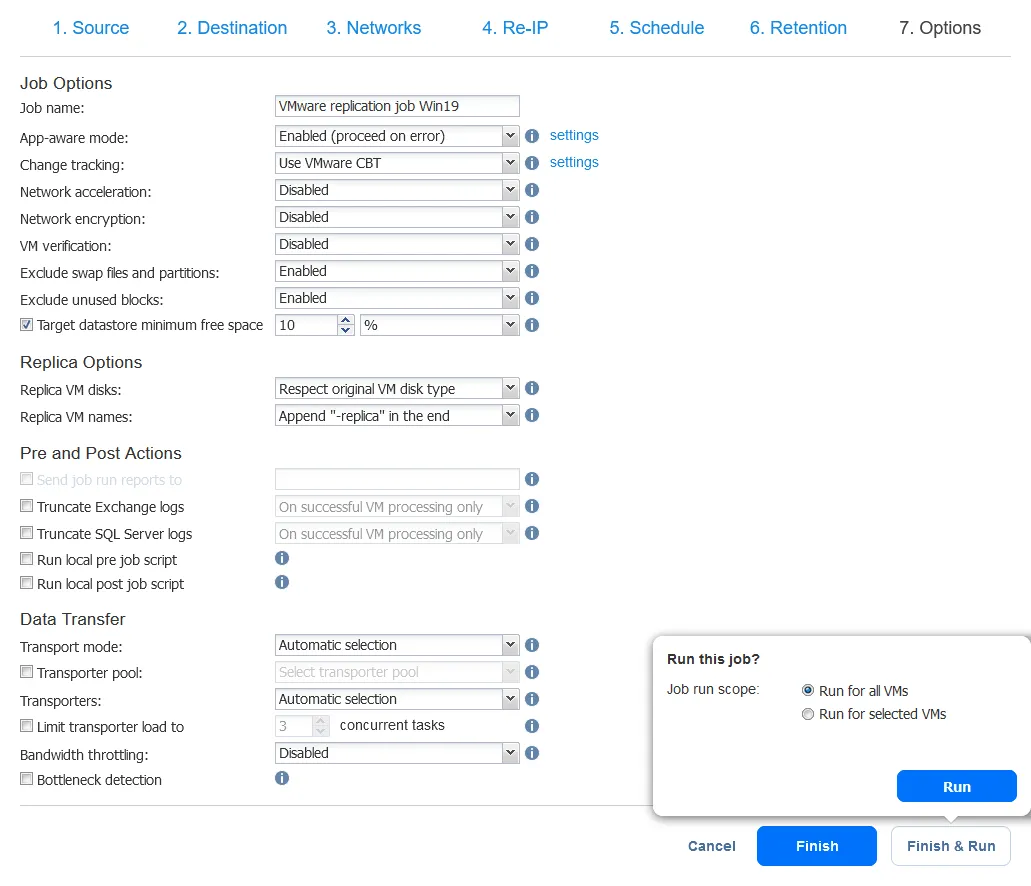
- Selecteer de opties voor de replicatienaamiddeling en klik op Voltooien of op de knop Voltooien & Uitvoeren. Wacht terwijl de kopie wordt aangemaakt.
VM-terugvalconfiguratie
Nu u een kopie van de VM heeft aangemaakt, kunt u deze kopie gebruiken voor een VM-terugval.
Op de startpagina van het dashboard klikt u op Herstellen> VMware Volledige Herstel (VM-kopie terugval). Het Nieuwe Terugvaltaakassistent wordt geopend.
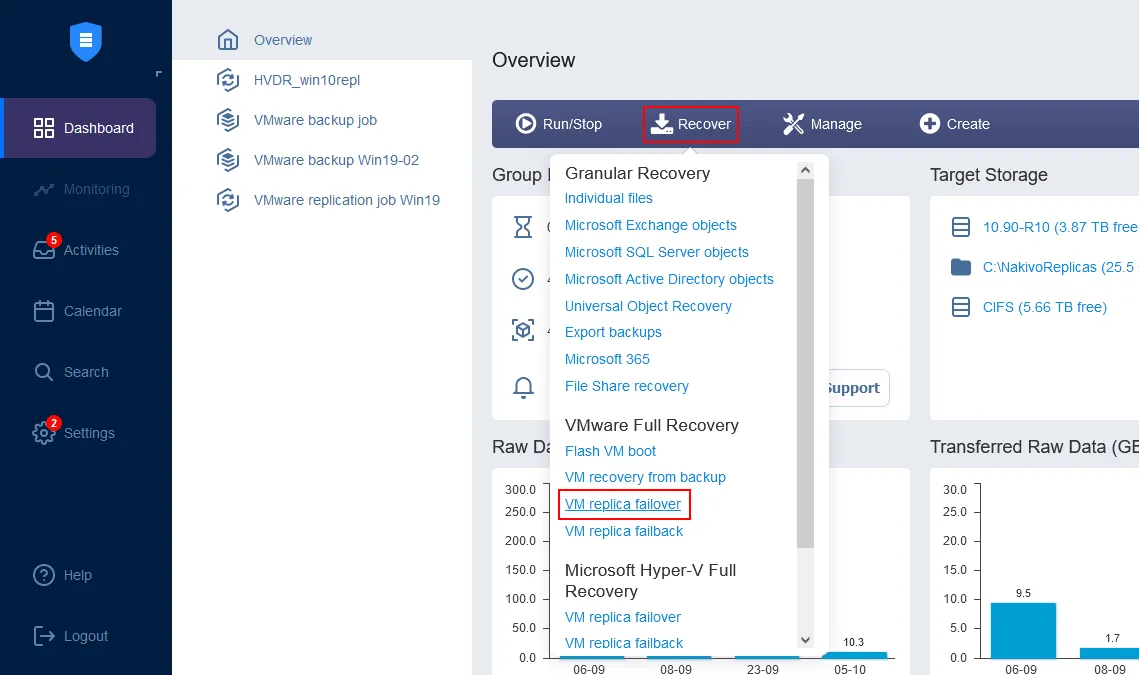
- Selecteer in het linkerpaneel de VM-kopie die u voor het terugval gebruikt gaat opnemen. In deze doorloper is de Server2019-replica, die net werd aangemaakt, gekozen.Kies in het rechterpaneel een herstelpunt. In de oplossing wordt het laatste herstelpunt standaard gekozen. Klik op Volgende.
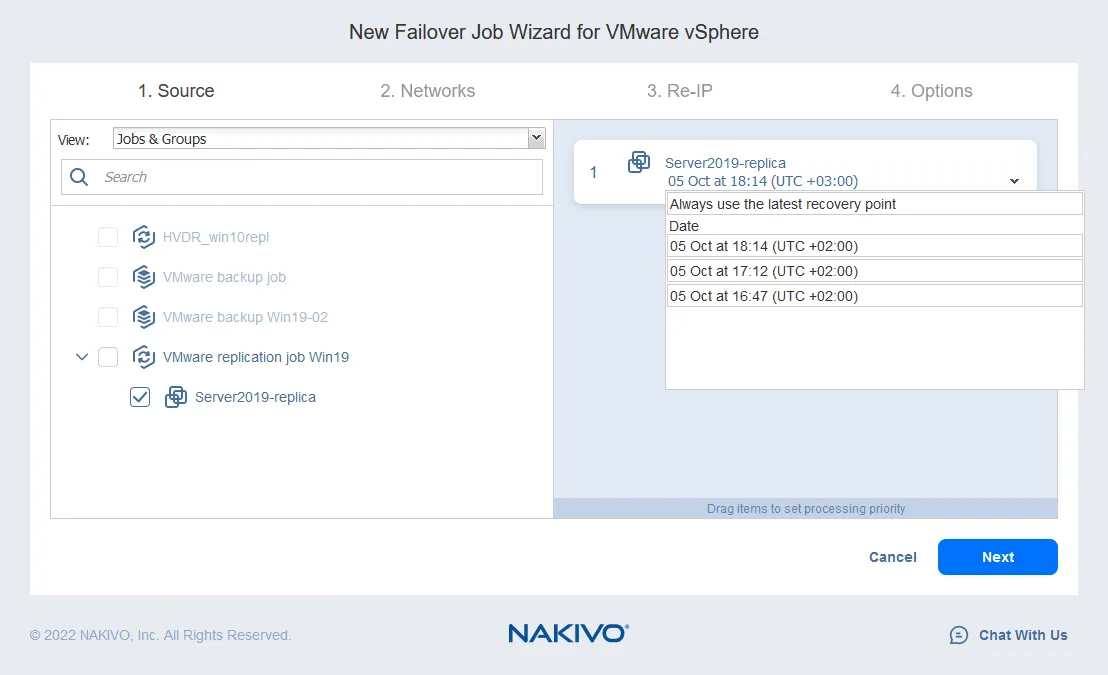
- Het Netwerk in kaart brengen helpt je het netwerk te veranderen waarmee de VM is verbonden. De bron- en doel-ESXi-hosts hebben waarschijnlijk verschillende instellingen voor virtuele switches. Aangezien een VM-replica een exacte kopie is van de bron-VM, worden de virtuele netwerken waarmee de bron-VM is verbonden behouden in de VM-replica.
Over het algemeen moet je de netwerkinstellingen van een VM-replica controleren en handmatig het netwerk wijzigen. NAKIVO Backup & Replication kan automatisch het bronnetwerk toewijzen aan een doelnetwerk. Je hoeft alleen Netwerk in kaart brengen in te stellen bij het configureren van de replicatie- of failover-taak.
- Om Netwerk in kaart brengen in te schakelen, selecteer het selectievakje. Als je eerder een regel voor netwerkmapping hebt gemaakt, kun je op Bestaande mapping toevoegen klikken. Als er geen regels voor netwerkmapping zijn, klik dan op Nieuwe mapping maken.
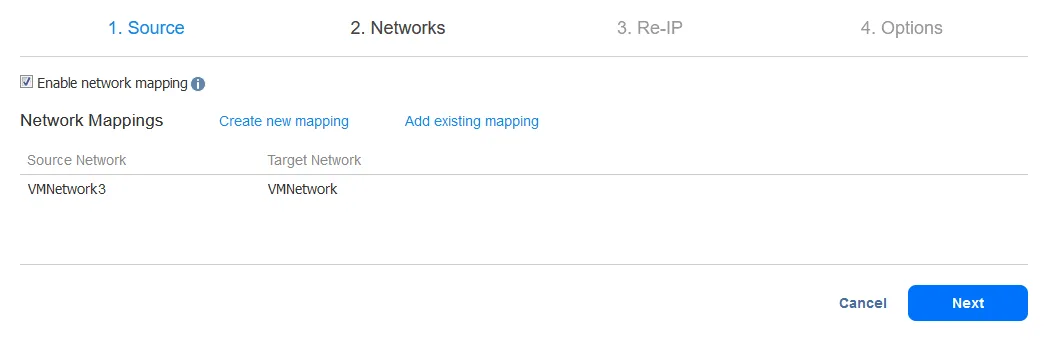
-
Om een nieuwe regel voor netwerkmapping te maken, selecteer het bronnetwerk en het doelnetwerk. Het bronnetwerk is het netwerk waarmee de bron-VM is verbonden. Het doel (doel) netwerk is het netwerk waarmee de VM-replica moet worden verbonden.
Let op: De naam van het VM-netwerk is niet hetzelfde als het IP-adres of het netwerkadres.
Klik op Opslaan om de regel voor netwerkmapping op te slaan en klik vervolgens op Volgende om door te gaan met de configuratie.
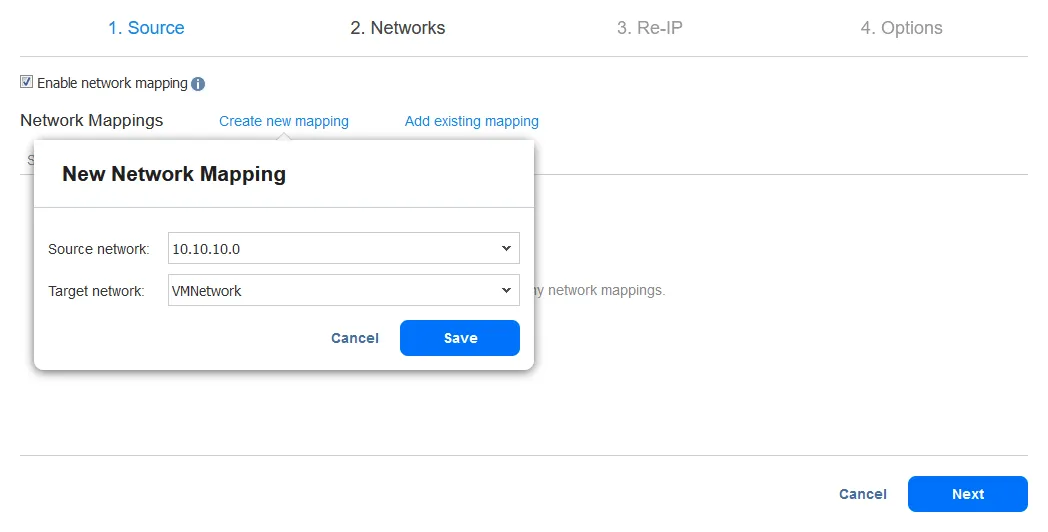
- De Re-IP-functie maakt het mogelijk om de IP-instellingen van de VM-replica te wijzigen. Het kan worden gebruikt voor statische IP-adressen. Selecteer het selectievakje Re-IP inschakelen als je deze optie wilt inschakelen en maak vervolgens een Re-IP-regel aan of voeg een bestaande regel toe. Klik op Nieuwe regel maken als er nog geen regels zijn gemaakt. Een pop-upmenu verschijnt.
- De bron-VM-instellingen zijn het IP-adres en het netwerkmasker die moeten worden gewijzigd.
-
De doelinstellingen zijn de instellingen die moeten worden toegepast voor de VM-replica wanneer failover optreedt. In dit voorbeeld dekt het [*] karakter het laatste octet af. Het [*] duidt op elk nummer van 1 tot 254. Als de bron-IP-adressen bijvoorbeeld 10.10.10.1, 10.10.10.96 en 10.10.10.222 zijn, zouden de doeladressen respectievelijk 192.168.10.1, 192.168.10.96 en 192.168.10.222 zijn. Het laatste octet van het IP-adres wordt behouden.
Klik op Opslaan om je Re-IP-regel op te slaan en ga verder.
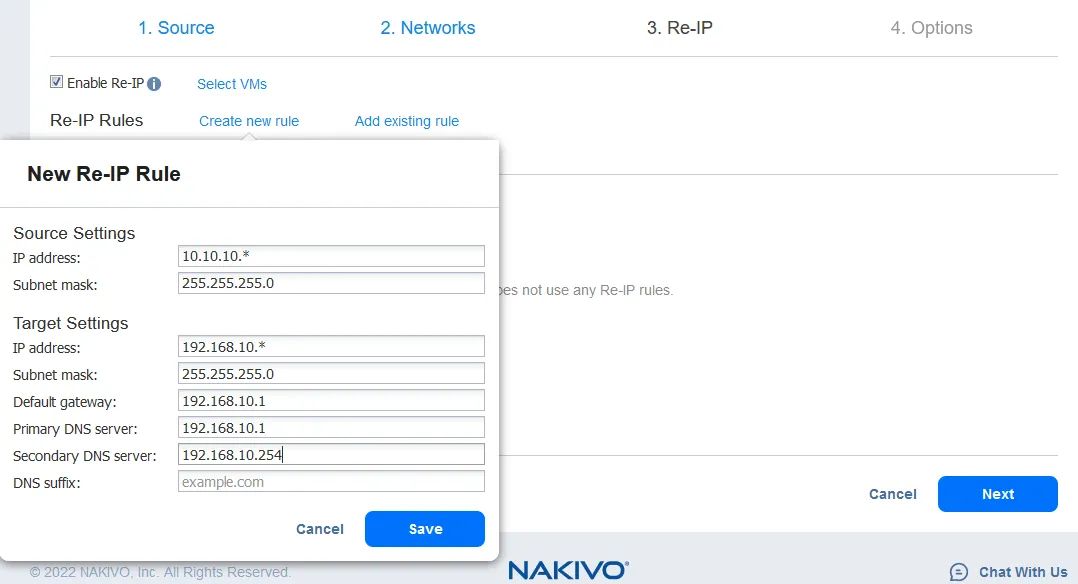
Na het toevoegen van de Re-IP-regel zou je scherm er zo uit moeten zien:
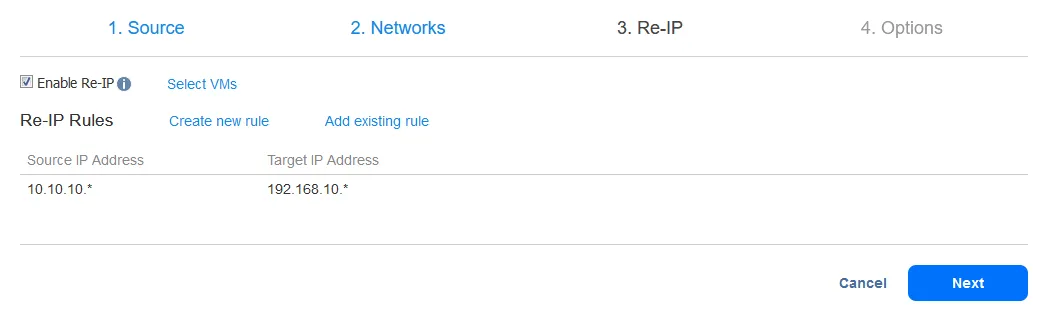
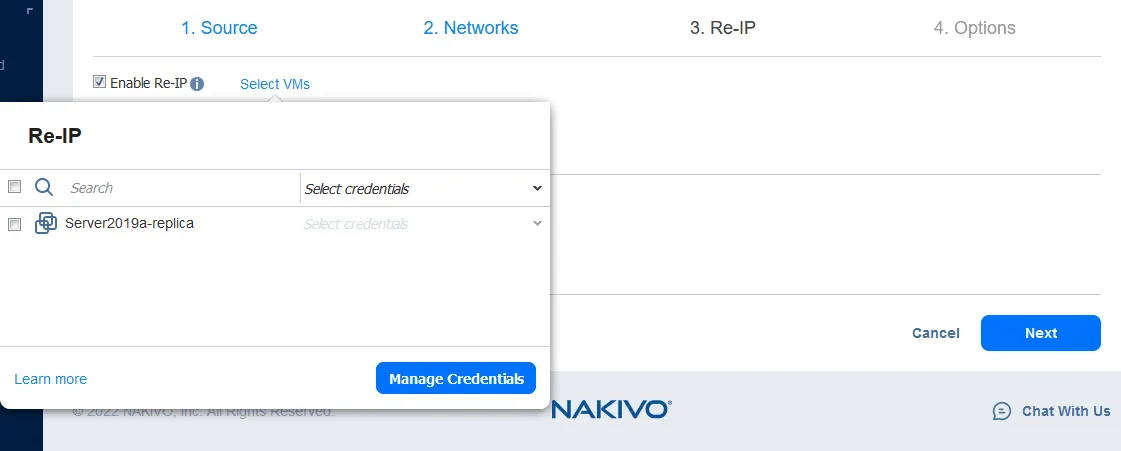
Selecteer nu de VM’s waarop de Re-IP-regels moeten worden toegepast. De failover-taak in dit voorbeeld bevat slechts één VM-replica, dus selecteer het enkele selectievakje.
Selecteer vervolgens de referenties voor elke VM. Klik op Referenties beheren> Referenties toevoegen om nieuwe referenties toe te voegen. De toegevoegde referenties kunnen worden geselecteerd uit de keuzelijst.
Let op: De referenties zijn nodig voor NAKIVO Backup & Replication om toegang te krijgen tot de netwerkinstellingen van het besturingssysteem binnen de VM en het script toe te passen dat die instellingen wijzigt. VMware Tools moet zijn geïnstalleerd op VMware vSphere VM’s en Hyper-V Integration Services moeten zijn geïnstalleerd op Microsoft Hyper-V VM’s.
Wanneer je al deze instellingen hebt geconfigureerd, klik dan op Volgende.
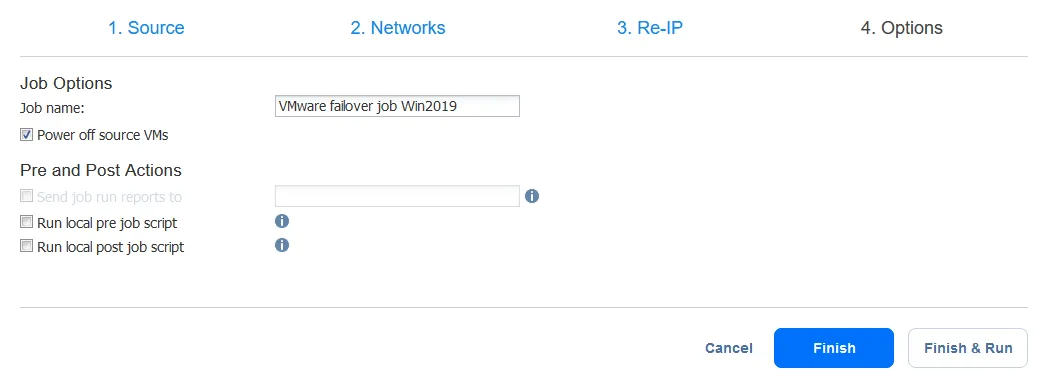
Configureer nu de opties voor de VM-failovertaak. Je kunt het selectievakje Bron-VM’s uitschakelen selecteren. Het kan handig zijn om een conflict van IP-adressen te voorkomen als zowel de bron- als replica-VM’s hetzelfde netwerk gebruiken of dezelfde IP-adressen hebben. Nadat je alle opties hebt geconfigureerd, klik je op Afsluiten & Uitvoeren.
Wacht tot de VM-failovertaak is voltooid.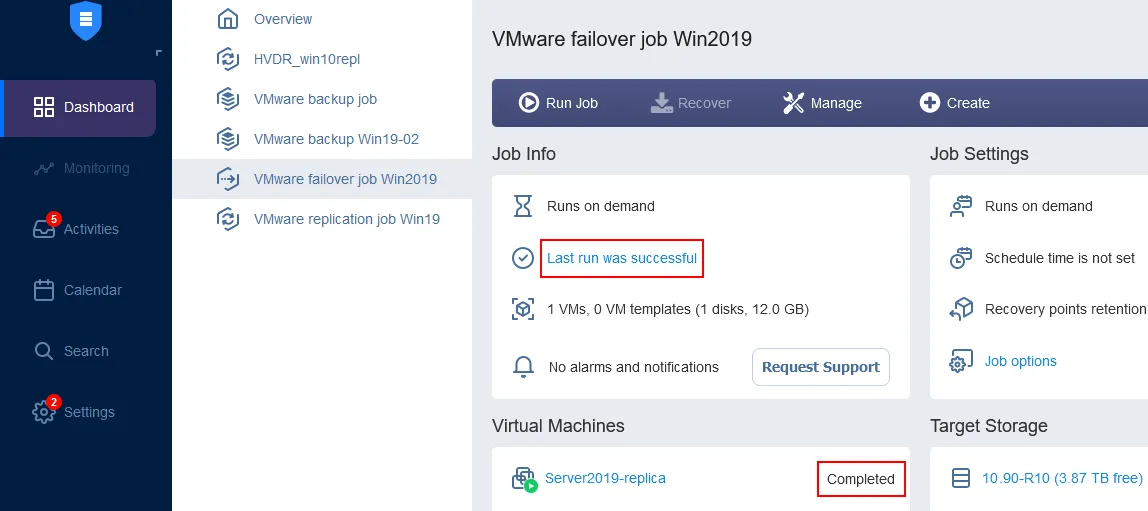 </diy
</diy - Om Netwerk in kaart brengen in te schakelen, selecteer het selectievakje. Als je eerder een regel voor netwerkmapping hebt gemaakt, kun je op Bestaande mapping toevoegen klikken. Als er geen regels voor netwerkmapping zijn, klik dan op Nieuwe mapping maken.