













La disponibilità delle macchine virtuali è essenziale per garantire la continuità aziendale. Quando i servizi in esecuzione sulle VM aziendali e mission-critical diventano non disponibili, le aziende possono perdere denaro e fiducia dei clienti. Per ripristinare immediatamente la disponibilità delle VM dopo un guasto, è necessario utilizzare tecniche di failover appropriate.
Il failover a una replica della VM può far parte del ripristino dopo un disastro per ripristinare dati e operazioni con minime interruzioni ai flussi di lavoro regolari. Il processo di failover della VM dovrebbe essere descritto nella continuità aziendale e nel ripristino dopo un disastro (BCDR) dell’organizzazione. Esaminiamo più nel dettaglio i tipi e gli utilizzi del failover della VM.
Cos’è un Failover?
Il failover è il processo di ripristino di una macchina virtuale (VM) su un sistema secondario (e talvolta in una posizione secondaria) in seguito a un guasto del sistema primario. Il sistema secondario contiene tutti i dati necessari per mantenere le operazioni aziendali. Un sistema in questo contesto può essere un server, un database, una macchina virtuale, ecc.
Negli ambienti virtuali, ci sono due metodi comuni di failover:
- Utilizzo di una replica della VM (di solito situata su un altro server di virtualizzazione) viene utilizzata per eseguire il failover se una VM primaria fallisce
- Utilizzo di un cluster di failover (nessuna replica richiesta)
Il failover richiede meno tempo per ripristinare i carichi di lavoro rispetto al ripristino da un backup e, di conseguenza, è possibile raggiungere un obiettivo di tempo di ripristino (RTO) più basso. Tuttavia, l’utilizzo della replica delle VM o del clustering non elimina la necessità di creare backup delle VM. Un backup (di solito compresso) è utile quando è necessario recuperare i dati dal vecchio punto di ripristino.
Esaminiamo i termini di base del failover delle VM per il ripristino di emergenza basato sulla replica.
Glossario del failover
- Guasto: Ogni problema hardware o software causato da un blocco del sistema, un’interruzione di corrente, problemi di rete, attacchi ransomware, ecc., che mette offline un sistema.
- Sistema primario: Il sistema che gestisce le operazioni in tempo reale nell’ambiente di produzione.
- Sistema secondario: Il sistema standby redundante, che viene regolarmente aggiornato con copie del sistema primario. Il sistema secondario può essere ospitato in loco o in una posizione remota.
- Replica: Il processo essenziale per prepararsi al failover delle VM. La replica crea una copia esatta, cioè una replica, della VM primaria per un dato momento.
- Failback della VM: Il failback è il processo di ritorno al sistema primario dalla VM replica dopo che l’incidente è stato risolto.
Tipi di failover
Ci sono tre tipi di failover:
- A planned failover is used for scheduled migrations of workloads from one system/site to another. Use cases include performing maintenance on the primary system, electrical works performed at the production site, and expected disaster scenarios. For example, a weather alert about a tornado may require a planned failover to ensure availability.
- Un failover non pianificato è un failover eseguito quando si verifica un guasto imprevisto che porta offline una VM critica o l’intero sito primario. Il guasto può essere causato da uno qualsiasi di una serie di disastri naturali, incidenti (un’interruzione di corrente), un attacco malware, o qualsiasi altro incidente. Per un failover non pianificato, host e repliche dovrebbero essere preparati in anticipo.
- A test failover, as the name suggests, is used for testing purposes. Testing scenarios can include rehearsing unplanned failover scenarios to ensure that
La Sequenza di Failover
Durante un failover di una VM, la sequenza di azioni e l’ordine di avvio della VM sono essenziali per garantire la ripresa riuscita dei flussi di lavoro. Devono essere definiti nella fase di sviluppo del piano di ripristino di emergenza dell’organizzazione. La sequenza dovrebbe catturare le dipendenze tra i diversi servizi che girano su diverse VM.
Ad esempio, l’autenticazione per alcuni servizi e applicazioni che girano su VM potrebbe utilizzare Active Directory, che è in esecuzione su un’altra VM. Un server di database potrebbe essere in esecuzione sulla prima VM, un server di applicazioni sulla seconda e il server web sulla terza.
La VM con il server Active Directory deve essere avviata per prima. Successivamente possono essere avviate le VM con i servizi che utilizzano Active Directory per l’autenticazione. La VM con il server del database deve essere avviata prima della VM con il server dell’applicazione, perché il server dell’applicazione si connette al database. Una volta che le VM con il server del database e il server dell’applicazione sono state avviate, può essere avviata la VM con il server web.
Soluzioni principali per il failover
Le principali soluzioni utilizzate negli ambienti virtuali sono:
- raggruppamento di failover
- failover utilizzando le repliche delle VM
Consideriamole una per una.
Soluzione 1. Raggruppamento di failover
A failover cluster is a group of at least two servers or nodes that are configured to take over workloads when one node is down or unavailable. Clustering is an enterprise-class automated solution that can be used for the most important, business-critical VMs. Microsoft Hyper-V offers a Failover Cluster made up of several Hyper-V hosts. VMware’s equivalent is a High Availability cluster, which is made up of ESXi hosts.
Nel primo diagramma sottostante, puoi vedere un cluster in cui entrambi gli host (chiamati anche nodi) funzionano correttamente. Le VM sono in esecuzione sugli host e i file delle VM sono posizionati su una memoria condivisa accessibile da entrambi gli host.
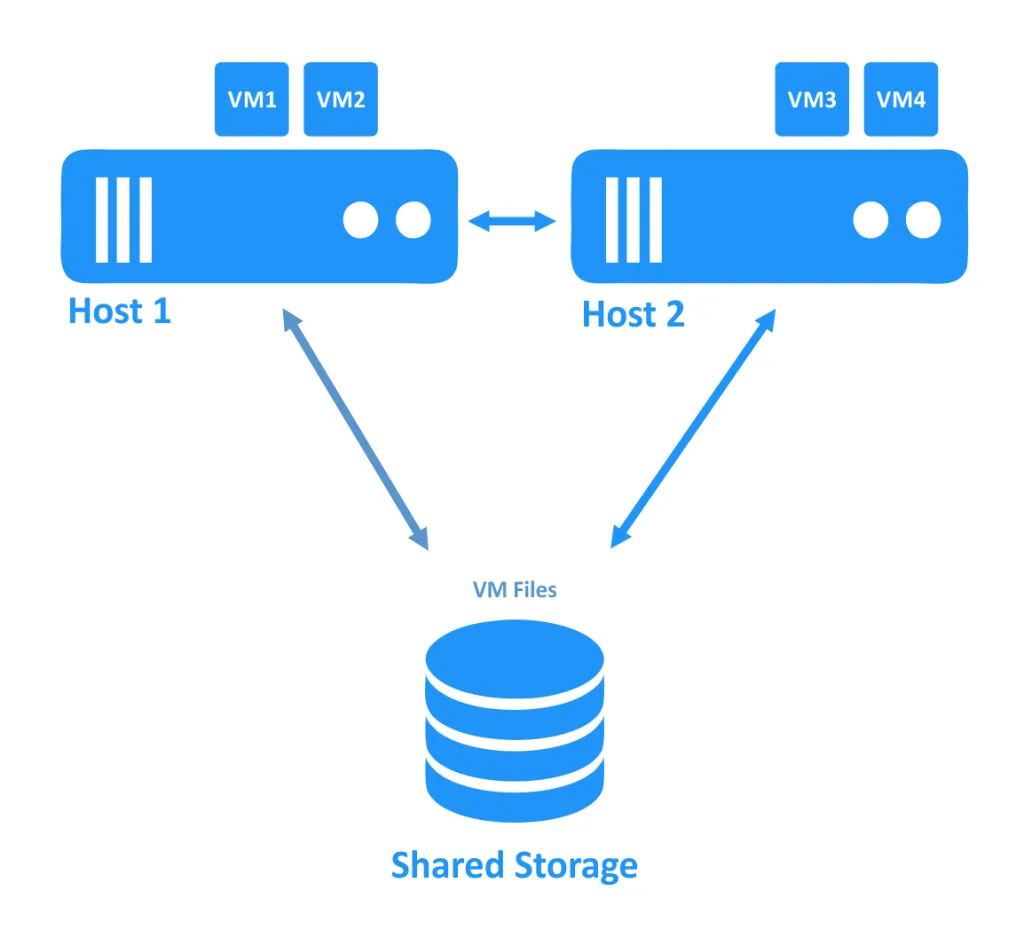
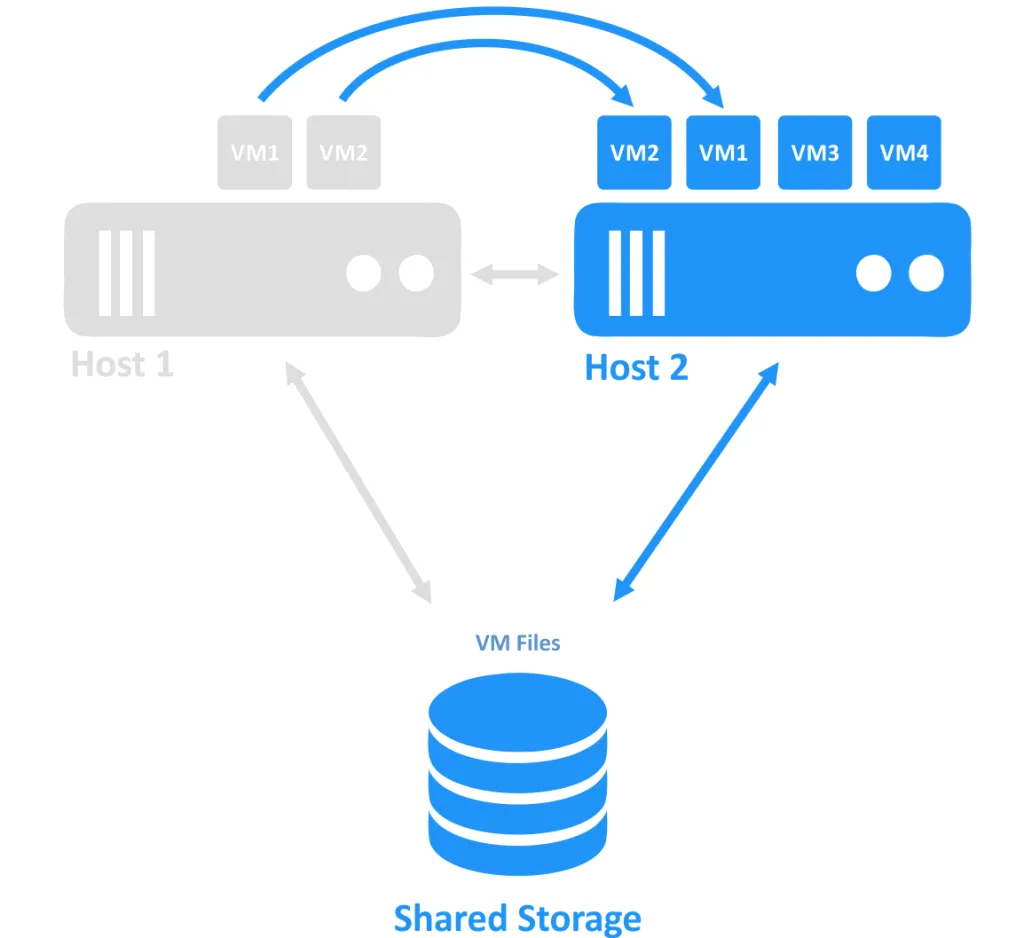
Quando uno degli host si spegne, la proprietà della connessione alla VM (che era in esecuzione sul nodo offline) viene trasferita a un altro nodo ancora online. Questo è il processo di failover. Una VM altamente disponibile potrebbe aver bisogno di essere riavviata.
Requisiti per il raggruppamento di failover
I seguenti requisiti devono essere soddisfatti per creare un cluster di failover:
- Archiviazione condivisa collegata agli host con una rete dedicata ad alta velocità e bassa latenza. Deve essere utilizzato un sistema di file clusterizzato per garantire che più host possano accedere contemporaneamente ai dati situati sull’archiviazione.
- Gli host su cui girano le VM devono avere lo stesso hardware o, almeno, hardware della stessa famiglia. I processori devono supportare gli stessi set di istruzioni per garantire la compatibilità affinché le VM possano funzionare correttamente dopo la migrazione da un host all’altro durante il failover.
- A high-speed redundant network with low latency. There should be multiple, separate cluster networks, that is, a cluster must have different networks for storage, management, VM migration, connection of hosts amongst each other, etc.
Casi d’uso
I cluster di failover vengono utilizzati per recuperare le VM da un guasto del server, fornendo un’alta disponibilità per le VM critiche. Se uno degli host (chiamati nodi) all’interno di un cluster fallisce, le VM che erano in esecuzione sull’host guasto vengono migrate (failover) su altri host sani. A seconda delle impostazioni, le VM che sono state trasferite possono essere riportate sull’host su cui erano in esecuzione prima dell’incidente una volta risolto il guasto.
Vantaggi
A failover cluster has advantages that provide strong protection:
- A failover cluster provides automatic VM failover. You don’t need to start the failed VMs manually on other hosts.
- Durante il failover, si verifica una perdita di dati quasi nulla. L’interruzione è di solito limitata al tempo necessario per caricare la VM, il sistema operativo (OS) e il software in esecuzione sulla VM.
- La funzionalità di tolleranza ai guasti inclusa nel cluster di alta disponibilità di VMware garantisce il failover delle VM senza tempi di inattività e senza perdita di dati.
Svantaggi
A failover cluster does not protect against:
- Guasto software delle VM. Bug del software o virus possono causare un arresto del sistema in una VM.
- Eliminazione accidentale dei file all’interno della VM.
- Guasto dello storage condiviso. Il cluster fallisce se lo storage condiviso fallisce. Lo storage condiviso è un componente cruciale del cluster; i dischi virtuali delle VM all’interno di un cluster sono memorizzati nello storage condiviso.
- A disaster that makes the whole physical site unavailable.
Per ulteriori informazioni su cos’è un cluster di failover, leggi la guida completa sui cluster VMware.
Soluzione 2. Failover utilizzando repliche delle VM
Il failover delle VM basato sulle repliche delle VM può essere eseguito da applicazioni specializzate, che possono replicare le VM e avviare le repliche quando richiesto dall’amministratore. Oltre al software di protezione dei dati, è necessario disporre di host ESXi o Hyper-V (a seconda del proprio ambiente) preparati in anticipo per eseguire le repliche delle VM in caso di guasto delle VM sorgente.
Nel diagramma sottostante, puoi vedere due host connessi tra loro tramite la rete. Le VM stanno utilizzando i dischi degli host. Le VM sorgente stanno eseguendo sul primo host, e le repliche delle VM, che sono copie esatte delle VM sorgente in un determinato momento, sono situate sul secondo host in uno stato spento.
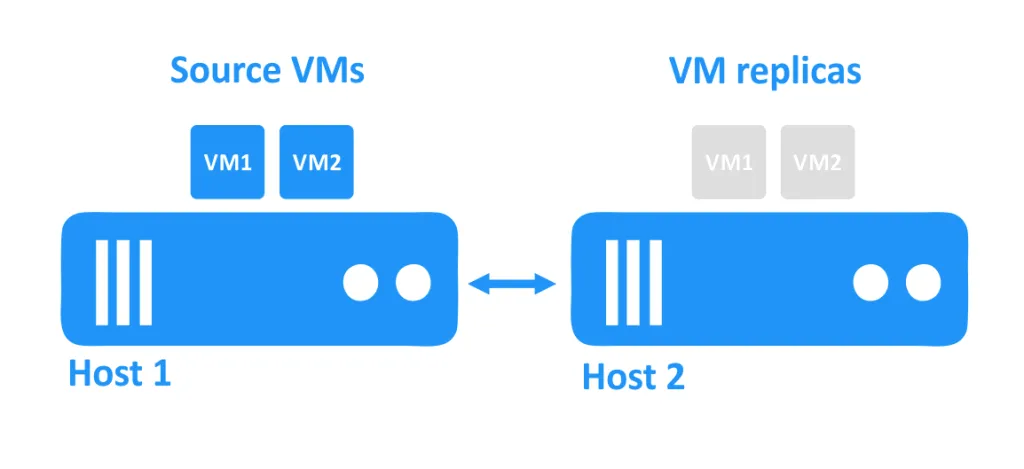
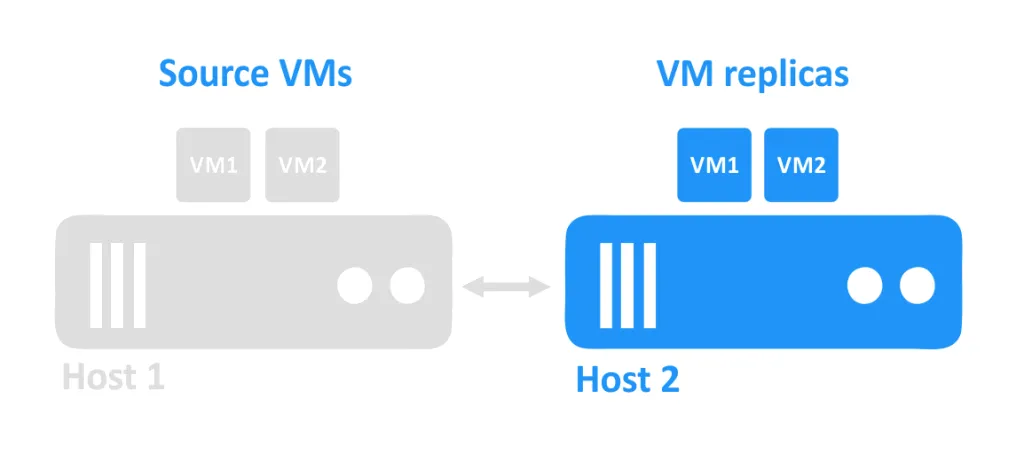
Quando un host va giù, le VM che stavano eseguendo su quell’host diventano inaccessibili. Le repliche delle VM situate su un altro host vengono quindi avviate dall’amministratore.
Requisiti per la replica delle VM
I requisiti di base per la replica di VM sono due o più host e una soluzione di replica. Una VM sorgente in esecuzione sul primo host viene replicata sul secondo host. La replica della VM si trova sul secondo host.
Casi d’uso
Il failover utilizzando repliche di VM può essere utilizzato quando si verifica un guasto hardware o software. I fallimenti dell’host ESXi o Hyper-V sono un esempio di guasto hardware. Esempi di guasto software possono essere aggiornamenti falliti, bug software, attacchi di virus o cancellazione accidentale di file da parte di un utente.
Vantaggi
Il principale vantaggio del failover di VM verso una replica è la possibilità di passare a un sito remoto. Quando viene creata una replica di VM, i dati copiati da una VM sorgente possono essere trasmessi su una connessione di rete (con larghezza di banda limitata) a un sito remoto. Il sito remoto potrebbe trovarsi in un ufficio nelle vicinanze o dall’altra parte del mondo. La replica della VM potrebbe anche trovarsi presso il sito di produzione primario.
Svantaggi
L’elenco degli svantaggi per un failover utilizzando repliche di VM:
- C’è un breve periodo di inattività tra un guasto e l’avvio della replica sul secondo host.
- Il failover deve essere avviato manualmente.
- I dati scritti dall’ultima replica possono essere persi durante un failover non pianificato. La replica di VM spesso non è un processo in tempo reale (sincrono), poiché la replica sincrona pone un carico significativo sulle risorse. La replica di solito viene eseguita a intervalli regolari a seconda delle impostazioni scelte.
- Le impostazioni di rete delle VM devono essere spesso modificate in caso di failover verso un altro sito. Le reti delle VM del sito remoto possono differire da quelle del sito principale. Di conseguenza, gli indirizzi IP potrebbero essere diversi e devono essere controllati e modificati insieme alle altre impostazioni di rete durante il failover.
Cluster vs failover basato sulla replica delle VM
| Failover con clustering | Failover utilizzando una replica | |
| Scopo | Disponibilità elevata | Recupero di emergenza |
| Protezione contro | Solo guasti hardware | Guasti hardware e software |
| Amministrazione | Avviato automaticamente | Avviato manualmente |
| Durata dell’indisponibilità (RTO) | Il failover è più veloce, quindi l’indisponibilità della VM è breve (RTO breve) | Il failover richiede più tempo, quindi l’indisponibilità della VM è più lunga |
| Requisiti | Più requisiti | Meno requisiti |
| Prezzo della soluzione | Le soluzioni di clustering sono di solito più costose | Le soluzioni di replica sono più economiche |
| Perdita di dati (RPO) | Perdita di dati prossima allo zero (RPO molto basso) | La perdita di dati dipende dalla frequenza della replica |
Utilizzo congiunto di cluster e repliche per il failover delle VM
Le soluzioni di failover basate su cluster e repliche sono talvolta considerate alternative, ma possono essere utilizzate per integrarsi a vicenda. Esaminiamo alcuni esempi di come l’uso di entrambe le soluzioni di failover possa aiutare a proteggere le tue VM contro guasti a livello di server e sito.
- Esempio 1: È possibile replicare le VM in esecuzione all’interno di un cluster su un host in un sito remoto. Inoltre, è possibile replicare le VM in esecuzione all’interno di un cluster su un altro cluster. Pertanto, in caso di guasto di un host, il cluster di failover mantiene attive quelle VM. Se l’intero sito subisce un’interruzione, è possibile eseguire il failover sulle repliche delle VM memorizzate in un sito remoto.
- Esempio 2: Un virus danneggia i file all’interno di alcune VM. Un cluster di failover non può proteggere contro tali guasti. Ma se hai repliche di VM con più punti di ripristino, puoi ripristinare ogni VM a un punto nel tempo prima che i loro file siano stati danneggiati o eliminati.
Utilizzo della soluzione NAKIVO per il failover automatico delle VM VMware alla replica
NAKIVO Backup & Replication è una soluzione di backup e ripristino di emergenza che può proteggere le VM in esecuzione all’interno di un cluster, replicare le VM, passare alle repliche e orchestrare sequenze di DR complesse. I cluster così come gli host ESXi o Hyper-V autonomi sono supportati come punti di origine e destinazione per la replica. La soluzione tiene traccia automaticamente dell’host su cui risiede una VM in modo da poter replicare quella VM. Questo è utile perché le VM possono migrare da un host all’altro all’interno di un cluster dopo eventi di failover o eventi di bilanciamento del carico (un cluster è di solito configurato in congiunzione con il bilanciamento del carico). Ecco perché il software che si utilizza per replicare una VM da un cluster deve essere in grado di tenere traccia dell’host su cui risiede la VM.
La soluzione NAKIVO può modificare automaticamente le impostazioni di rete della VM al momento del failover; basta utilizzare le funzionalità di Network Mapping e Re-IP durante la configurazione di un lavoro di replica o failover.
Consideriamo un esempio di Failover automatico della VM (con Network Mapping e Re-IP) in NAKIVO Backup & Replication. Inizieremo creando una replica della VM.
Configurazione della replica necessaria per il failover della VM
Nella dashboard dei lavori, fare clic su Crea > Lavoro di replica VMware vSphere se si dispone di un ambiente virtuale VMware. Si noti che è possibile creare un lavoro di replica per una VM Microsoft Hyper-V o un’istanza Amazon EC2 allo stesso modo.
Viene avviato il wizard del lavoro di replica.
- Seleziona le macchine virtuali che desideri replicare. In questo esempio, la VM Server2019, che esegue Windows Server 2019 come sistema operativo guest, verrà replicata. Clicca su Avanti.
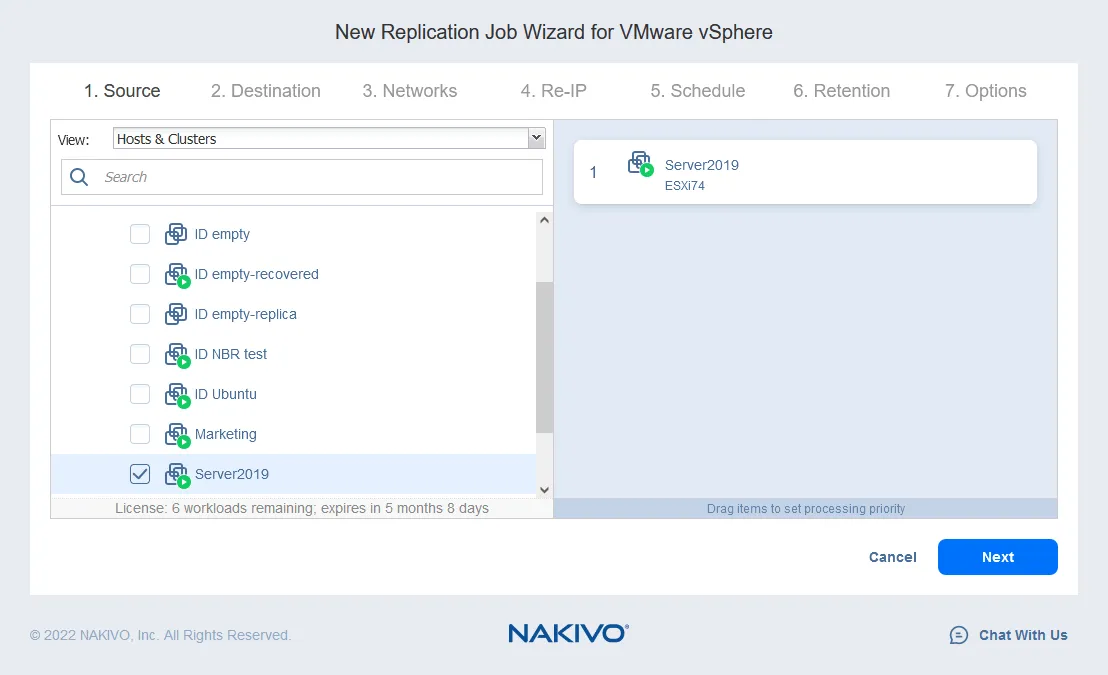
- Seleziona un host di destinazione per far funzionare la replica della VM (10.10.10.90 nel nostro caso). Seleziona il datastore montato sull’host selezionato per il posizionamento dei file della VM. Clicca su Avanti.
- Puoi impostare le opzioni di mappatura di rete e Re-IP durante la configurazione di un lavoro di replica o di failover. In questa procedura guidata, la mappatura di rete e il Re-IP verranno configurati successivamente quando il lavoro di failover sarà configurato. Pertanto, puoi saltare questo passaggio per il momento e fare clic su Avanti.
- La configurazione Re-IP verrà spiegata durante la configurazione del job di failover della VM in questa procedura guidata. Fare clic su Avanti.
- Seleziona le impostazioni di pianificazione. Fare clic su Avanti quando hai finito.
- Imposta le impostazioni di conservazione. Ricorda che puoi impostare la politica di conservazione nonno-padre-figlio a questo passaggio. Fare clic su Avanti.
- Seleziona le opzioni di lavoro di replica e clicca su Finish o sul pulsante Finish & Run. Attendi mentre la replica viene creata.
Configurazione del failover della VM
Ora che hai creato una replica della VM, puoi eseguire il failover della VM su questa replica.
Sulla homepage nella dashboard, clicca su Recover > VMware Full Recovery (failover della replica della VM). Si apre il Wizard del nuovo lavoro di failover.
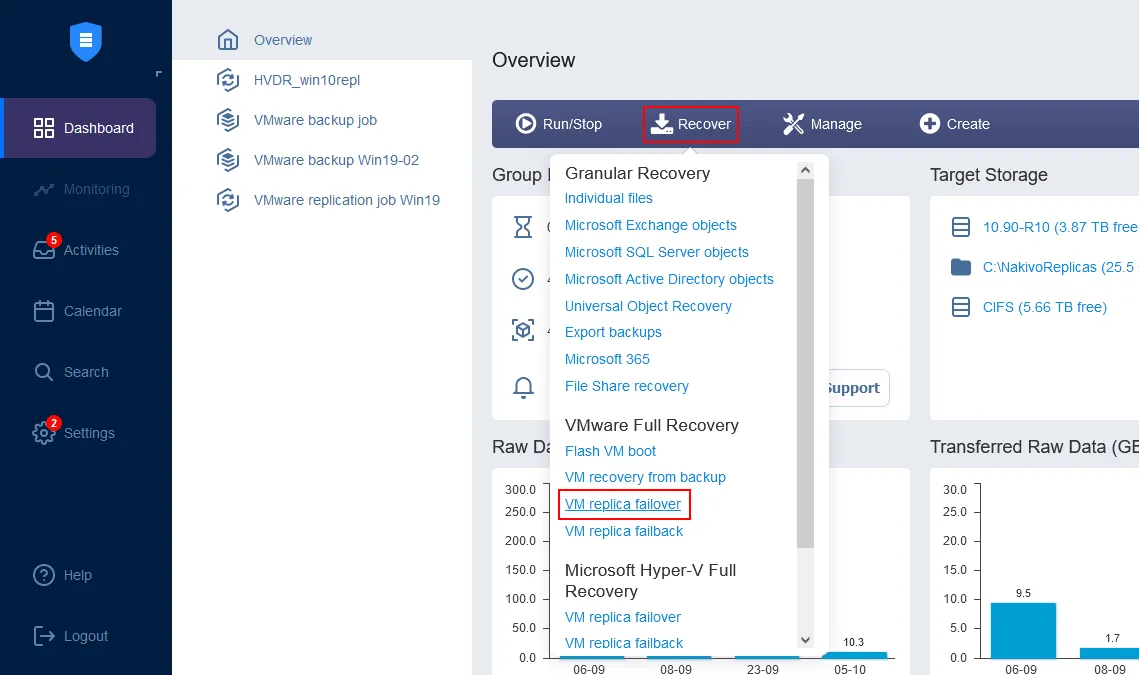
- Nel riquadro sinistro, seleziona la replica della VM da utilizzare per il failover. In questa procedura guidata, viene selezionato il Server2019-replica, appena creato. Nel riquadro destro, seleziona un punto di ripristino. Il punto di ripristino più recente è selezionato per impostazione predefinita nella soluzione. Clicca su Avanti.
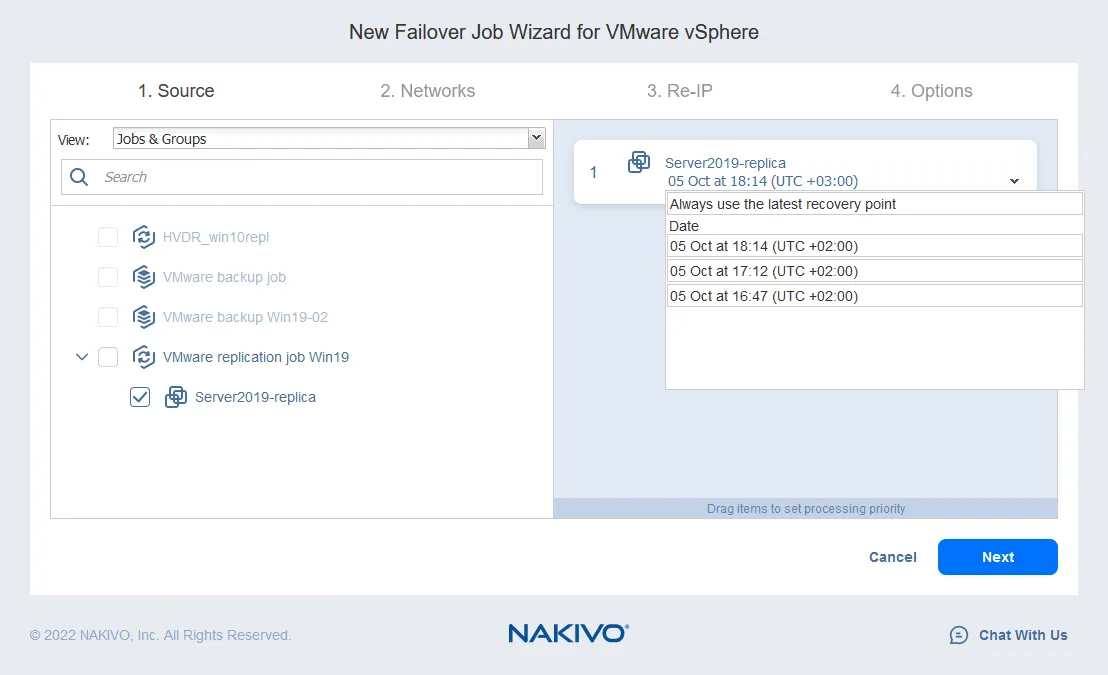
- Mappatura di rete ti aiuta a cambiare la rete a cui è connessa la VM. Gli host ESXi di origine e destinazione probabilmente hanno impostazioni diverse per lo switch virtuale. Poiché una replica di VM è una copia esatta della VM di origine, le reti virtuali a cui è connessa la VM di origine vengono preservate nella replica di VM.
Di solito, è necessario controllare le impostazioni di rete di una replica di VM e cambiarla manualmente. NAKIVO Backup & Replication può mappare automaticamente la rete di origine a una rete di destinazione. È sufficiente configurare la mappatura di rete durante la configurazione del job di replica o failover.
- Per abilitare la mappatura di rete, seleziona la casella di controllo. Se hai già creato una regola di mappatura di rete, puoi fare clic su Aggiungi mappatura esistente. Se non ci sono regole di mappatura di rete, fai clic su Crea nuova mappatura.
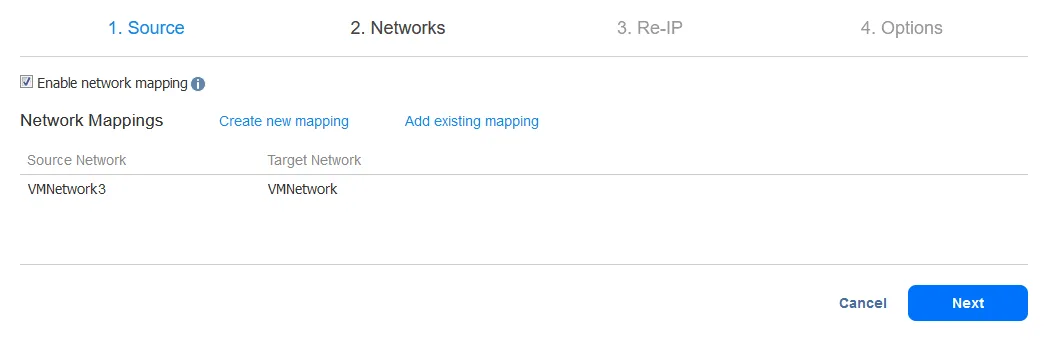
-
Per creare una nuova regola di mappatura di rete, seleziona la rete di origine e la rete di destinazione. La rete di origine è la rete a cui è connessa la VM di origine. La rete di destinazione (obiettivo) è la rete a cui dovrebbe essere connessa la replica di VM.
Nota: Il nome della rete VM non è lo stesso dell’indirizzo IP o dell’indirizzo di rete.
Fai clic su Salva per salvare la regola di mappatura di rete e quindi fai clic su Avanti per procedere nella configurazione.
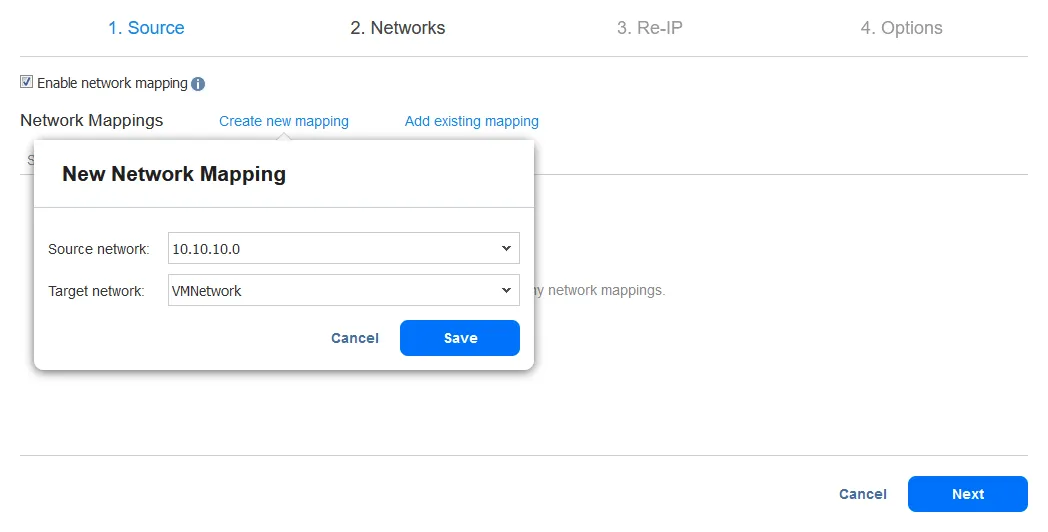
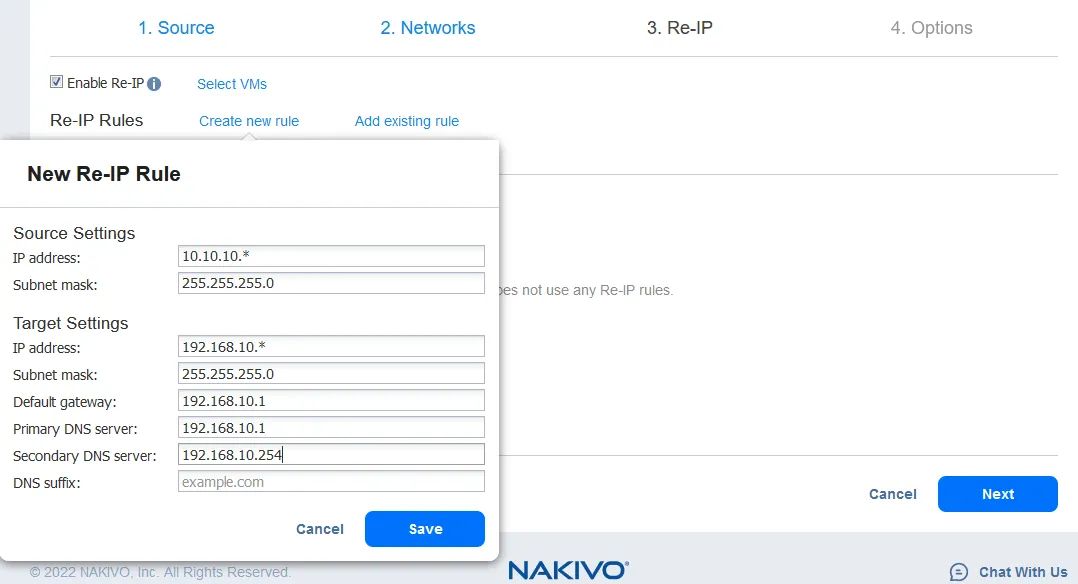
- La funzione Re-IP ti consente di modificare le impostazioni IP della replica di VM. Può essere utilizzata per indirizzi IP statici. Seleziona la casella di controllo Abilita Re-IP se desideri abilitare questa opzione e quindi crea una regola Re-IP o aggiungi una regola esistente. Fai clic su Crea nuova regola se non sono state create regole in precedenza. Viene visualizzato un menu popup.
- Le impostazioni della VM di origine sono l’indirizzo IP e la maschera di rete che devono essere modificati.
-
Le impostazioni di destinazione sono le impostazioni da applicare alla replica di VM quando si verifica il failover. In questo esempio, il carattere [*] copre l’ultimo ottetto. Il [*] indica qualsiasi numero da 1 a 254. Se gli indirizzi IP di origine sono, ad esempio, 10.10.10.1, 10.10.10.96 e 10.10.10.222, gli indirizzi di destinazione sarebbero rispettivamente 192.168.10.1, 192.168.10.96 e 192.168.10.222. L’ultimo ottetto dell’indirizzo IP viene preservato.
Fai clic su Salva per salvare la regola Re-IP e procedere.
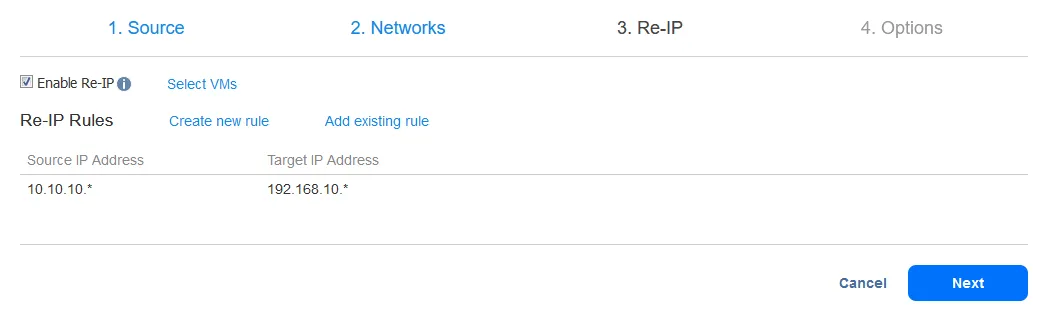
Dopo aver aggiunto la regola Re-IP, la tua schermata dovrebbe apparire come segue:
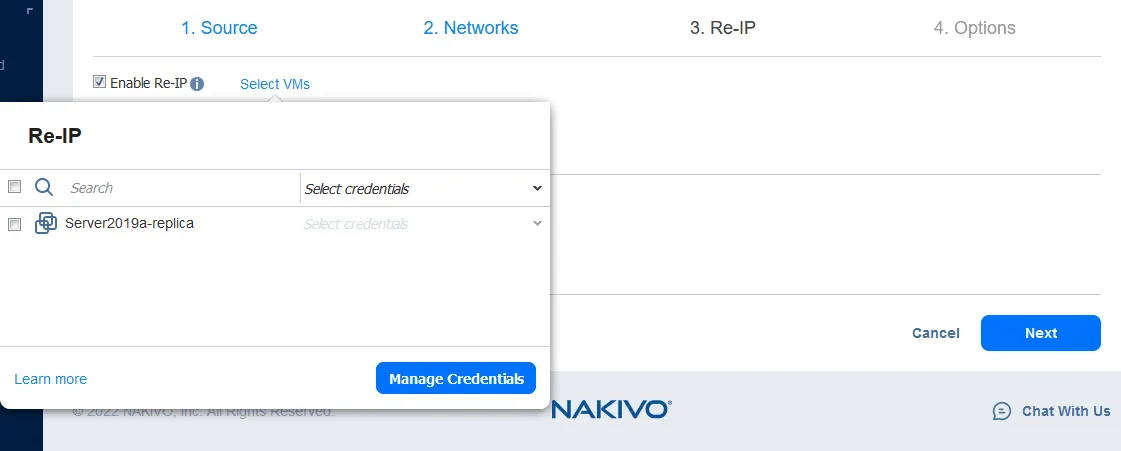
Ora seleziona le VM per le quali le regole Re-IP devono essere applicate. Il job di failover in questo esempio contiene solo una replica di VM, quindi seleziona la casella di controllo corrispondente.
Quindi seleziona le credenziali per ogni VM. Fai clic su Gestisci credenziali > Aggiungi credenziali per aggiungere nuove credenziali. Le credenziali aggiunte possono essere selezionate dalla lista a discesa.
Nota: Le credenziali sono necessarie affinché NAKIVO Backup & Replication possa accedere alle impostazioni di rete del sistema operativo all’interno della VM e applicare lo script che modifica tali impostazioni. Deve essere installato VMware Tools sulle VM di VMware vSphere e Hyper-V Integration Services sulle VM di Microsoft Hyper-V.
Una volta configurate tutte queste impostazioni, fai clic su Avanti.
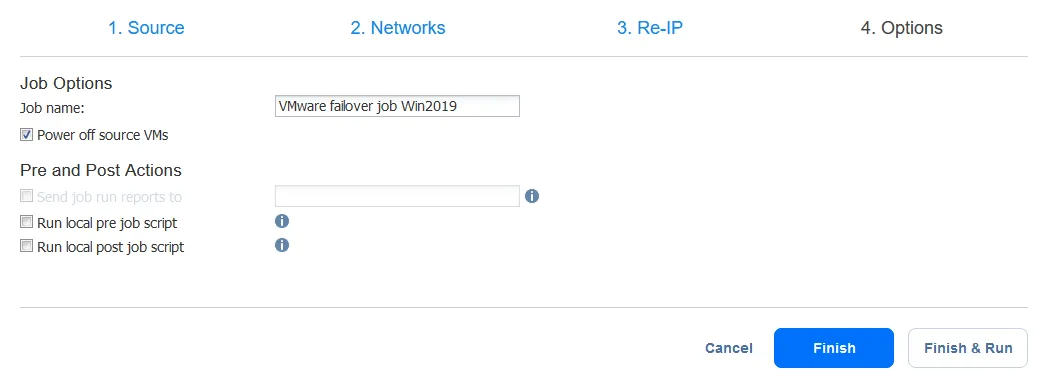
- Ora, configura le opzioni del job di failover della VM. Puoi selezionare la casella di controllo Spegni le VM di origine. Può essere utile per evitare conflitti di indirizzi IP se sia le VM di origine che le VM di replica utilizzano la stessa rete o hanno gli stessi indirizzi IP. Dopo aver configurato tutte le opzioni, fai clic su Termina e avvia.
Attendi che il job di failover della VM sia completato.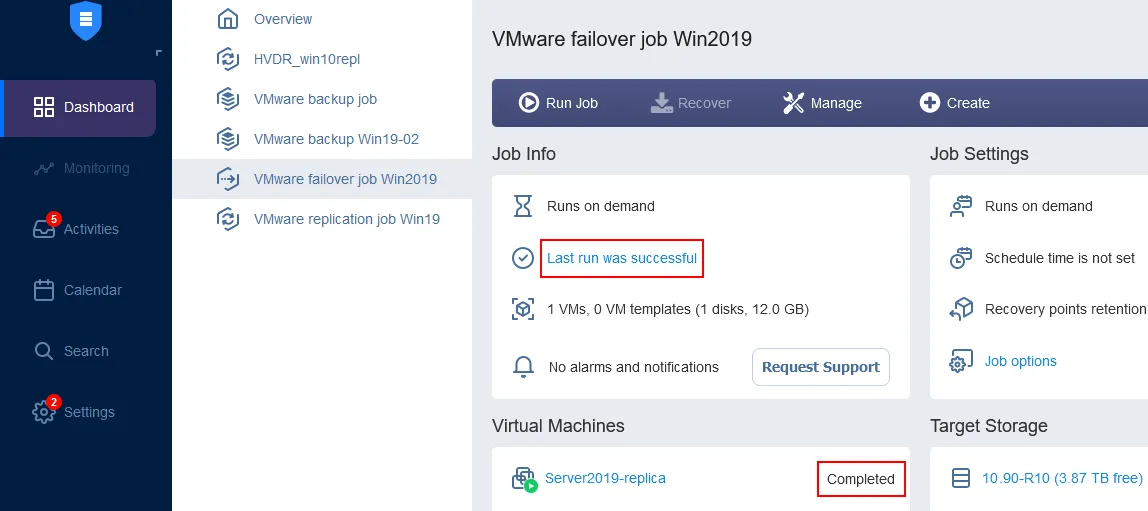
Ora puoi verificare che la replica di VM sia in esecuzione. Vai su Configurazione > Inventario e fai clic sul pulsante Aggiorna tutto. Dopo l’aggiornamento, puoi vedere che la VM Server2019-replica è già in esecuzione sull’host ESXi di destinazione. Da questa pagina (la pagina Inventario) puoi anche gestire le credenziali, le regole di mappatura di rete e le regole Re-IP.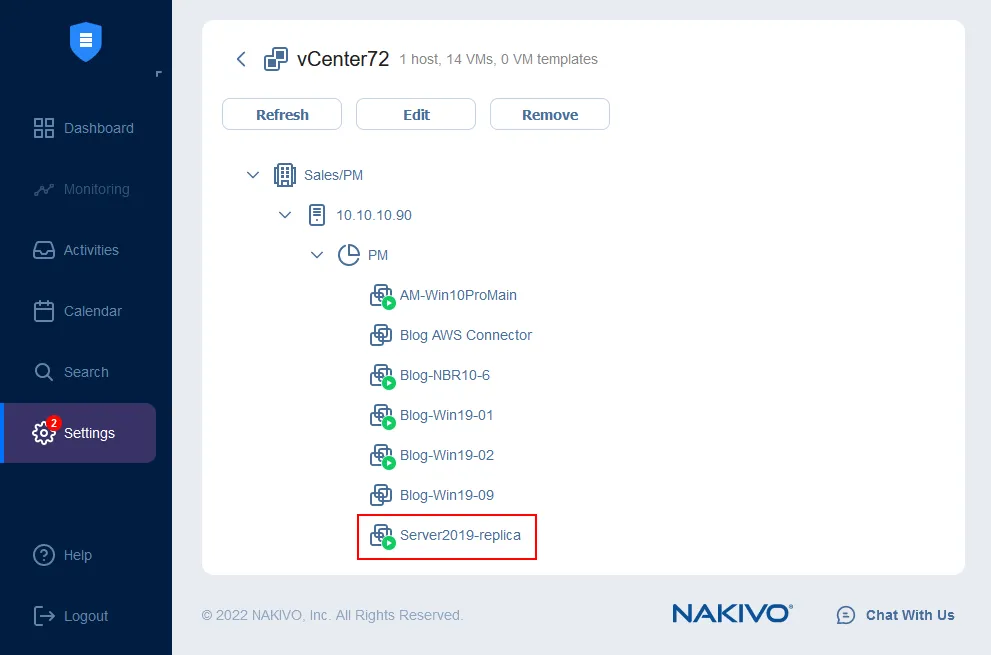
Conclusioni
Il failover della VM è utile per scenari di ripristino da disastro con molte macchine virtuali o per ripristinare anche una singola VM al fine di garantire continuità operativa e alta disponibilità. Tuttavia, è importante capire che qualsiasi piano di ripristino da disastro dovrebbe essere accompagnato da una solida strategia di backup per una protezione dei dati più affidabile ed efficiente.
Considera l’utilizzo di NAKIVO Backup & Replication, una soluzione di protezione VM veloce, affidabile e conveniente, per proteggere le VM utilizzando il metodo di failover verso la replica. La soluzione supporta anche il backup e il ripristino granulare per ambienti virtuali, fisici, cloud e SaaS da un’interfaccia web centralizzata.
- Per abilitare la mappatura di rete, seleziona la casella di controllo. Se hai già creato una regola di mappatura di rete, puoi fare clic su Aggiungi mappatura esistente. Se non ci sono regole di mappatura di rete, fai clic su Crea nuova mappatura.