













가상 머신(VMs)의 가용성은 비즈니스 연속성을 보장하는 데 중요합니다. 비즈니스 및 미션 중요 가상 머신에서 실행되는 서비스가 중단될 경우, 회사는 돈과 고객 신뢰를 잃을 수 있습니다. 장애 발생 후 즉시 VM 가용성을 복원하려면 적절한 장애 조치 기술을 사용해야합니다.
VM 복제본으로의 장애 조치는 재해 복구의 일부로 데이터 및 작업을 정규 워크플로우에 최소한의 중단으로 복원하는 데 사용될 수 있습니다. VM 장애 조치 프로세스는 조직의 비즈니스 연속성 및 재해 복구(BCDR)에 설명되어야합니다. VM 장애 조치 유형 및 사용 사례에 대해 자세히 알아 보겠습니다.
장애 조치란?
장애 조치는 주 시스템의 장애가 발생한 후 보조 시스템(때로는 보조 위치에서)에서 가상 머신(VM)을 다시 시작하는 과정입니다. 보조 시스템에는 비즈니스 운영을 유지하기 위한 모든 필요한 데이터가 포함되어 있습니다. 여기서 시스템은 서버, 데이터베이스, 가상 머신 등이 될 수 있습니다.
가상 환경에서는 두 가지 일반적인 장애 조치 방법이 있습니다:
- VM 복제본 사용(보통 다른 가상화 서버에 위치)은 주 VM이 실패한 경우 장애 조치를 수행하는 데 사용됩니다.
- 장애 조치 클러스터 사용(복제가 필요하지 않음)
페일오버는 백업에서의 복구보다 워크로드를 복원하는 데 더 적은 시간이 필요하므로 더 낮은 복구 시간 목표(RTO)를 달성할 수 있습니다. 그러나 VM 복제 또는 클러스터링을 사용하더라도 VM 백업을 만들어야 하는 필요성은 없어지지 않습니다. 백업(일반적으로 압축됨)은 이전 복구 지점에서 데이터를 복구해야 할 때 유용합니다.
복제 기반 재해 복구를 위한 기본 VM 페일오버 용어를 살펴보겠습니다.
페일오버 용어집
- 장애: 시스템 충돌, 전원 장애, 네트워크 문제, 랜섬웨어 공격 등의 결과로 하드웨어 또는 소프트웨어에 문제가 발생하여 시스템이 오프라인 상태가 되는 경우입니다.
- 기본 시스템: 운영 환경에서 라이브 운영을 수행하는 시스템입니다.
- 보조 시스템: 주 시스템의 복제본을 정기적으로 업데이트한 후 사용 가능한 여분의 시스템입니다. 보조 시스템은 온프레미스나 원격 위치에 호스팅될 수 있습니다.
- 복제: VM 페일오버를 준비하기 위한 중요한 과정입니다. 복제는 특정 시점의 주 VM의 정확한 복사본인 레플리카를 생성합니다.
- VM 페일백: 페일백은 사건이 해결된 후 복제 VM에서 기본 시스템으로 다시 전환하는 프로세스입니다.
페일오버 유형
페일오버에는 세 가지 유형이 있습니다:
- A planned failover is used for scheduled migrations of workloads from one system/site to another. Use cases include performing maintenance on the primary system, electrical works performed at the production site, and expected disaster scenarios. For example, a weather alert about a tornado may require a planned failover to ensure availability.
- 계획되지 않은 장애 조치(Failover)는 예상치 못한 장애로 인해 중요한 가상 머신 또는 전체 기본 사이트가 오프라인 상태가 될 때 수행되는 장애 조치입니다. 이러한 장애는 자연재해, 사고(전력 장애), 악성 소프트웨어 공격 또는 기타 어떤 사건에 의해 발생할 수 있습니다. 계획되지 않은 장애 조치에서는 호스트와 복제본이 사전에 준비되어야 합니다.
- A test failover, as the name suggests, is used for testing purposes. Testing scenarios can include rehearsing unplanned failover scenarios to ensure that
- 설정된 RTO(RTOs)와 RPOs(RPOs)를 충족할 수 있으며
- 필요할 때 모든 것이 잘 작동하고 원활하게 실행될 수 있습니다
- 재해 복구에 참여하는 모든 직원이 자신의 역할과 책임을 이해하고 있습니다
장애 조치 시퀀스
VM 장애 조치 중에는 작업의 장애 조치 시퀀스와 VM 시작 순서가 워크플로우의 성공적인 재개를 보장하는 데 중요합니다. 이러한 것들은 귀하의 조직의 재해 복구 계획의 개발 단계에서 정의되어야 합니다. 시퀀스는 다른 VM에서 실행되는 서비스 간의 종속성을 포착해야 합니다.
예를 들어, VM에서 실행되는 일부 서비스와 응용 프로그램의 인증이 다른 VM에서 실행되는 Active Directory를 사용할 수 있습니다. 데이터베이스 서버는 첫 번째 VM에서 실행되고 응용 프로그램 서버는 두 번째 VM에서 실행되며 웹 서버는 세 번째 VM에서 실행될 수 있습니다.
VM에는 먼저 Active Directory 서버가 시작되어야 합니다. 그런 다음 인증에 Active Directory를 사용하는 서비스를 사용하는 VM을 시작할 수 있습니다. 데이터베이스 서버가 있는 VM은 응용 프로그램 서버가 있는 VM보다 먼저 시작되어야 합니다. 왜냐하면 응용 프로그램 서버가 데이터베이스에 연결하기 때문입니다. 데이터베이스 서버와 응용 프로그램 서버가 시작된 후에 웹 서버가 시작될 수 있습니다.
Main Failover Solutions
가상 환경에서 사용되는 주요 솔루션은 다음과 같습니다:
- 장애 조치 클러스터링
- VM 복제를 사용한 장애 조치
각각을 고려해 봅시다.
솔루션 1. 장애 조치 클러스터링
A failover cluster is a group of at least two servers or nodes that are configured to take over workloads when one node is down or unavailable. Clustering is an enterprise-class automated solution that can be used for the most important, business-critical VMs. Microsoft Hyper-V offers a Failover Cluster made up of several Hyper-V hosts. VMware’s equivalent is a High Availability cluster, which is made up of ESXi hosts.
첫 번째 다이어그램에서 두 호스트(또는 노드라고도 함)가 올바르게 작동하는 클러스터를 볼 수 있습니다. VM은 호스트에서 실행되며 VM 파일은 양쪽 호스트에서 액세스할 수 있는 공유 스토리지에 위치해 있습니다.
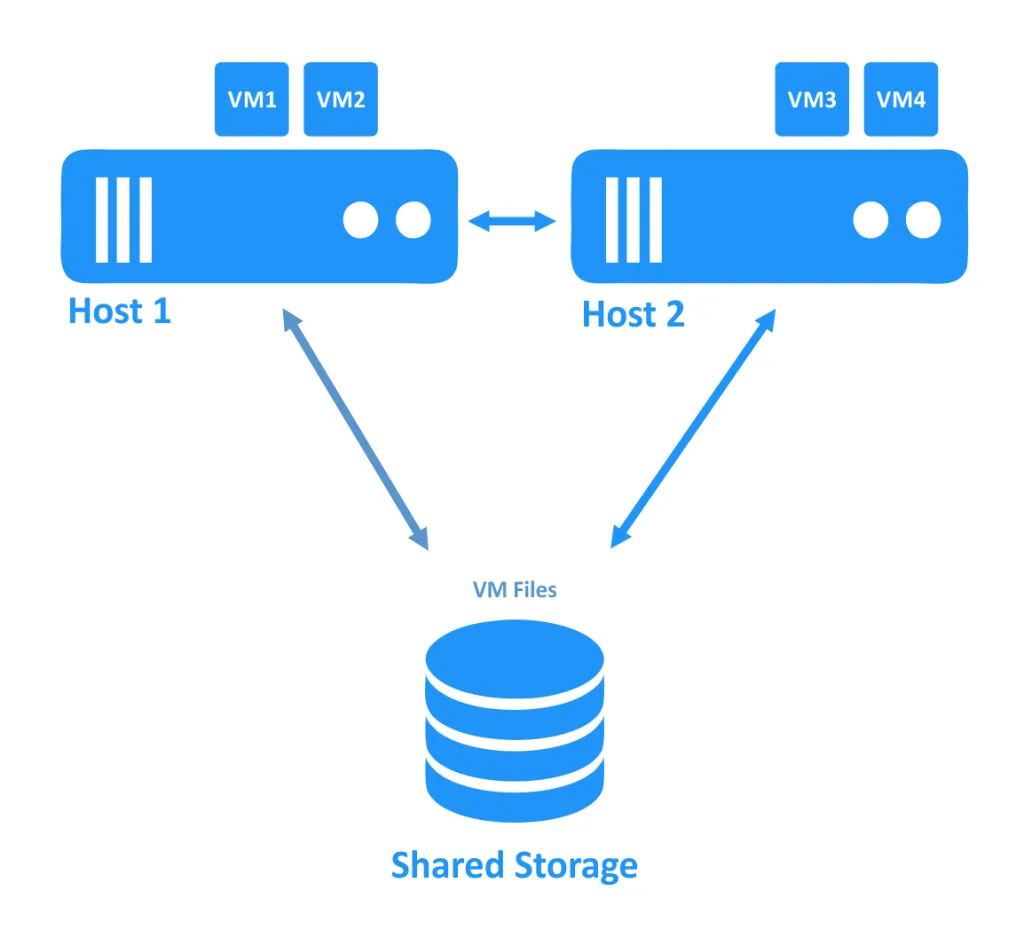
호스트 중 하나가 다운되면 오프라인 노드에서 실행되던 VM에 대한 연결 소유권이 여전히 온라인인 다른 노드로 전송됩니다. 이것이 장애 조치 프로세스입니다. 고가용성 VM은 다시 시작될 수 있습니다.
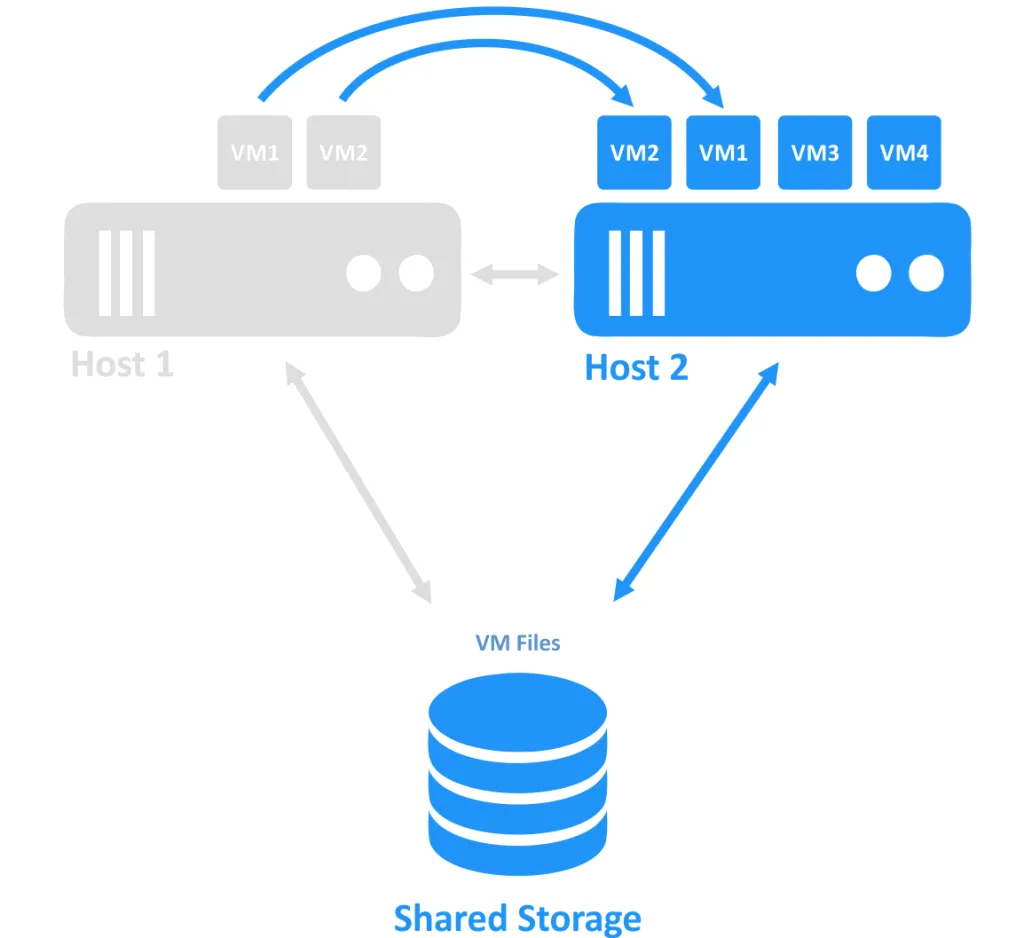
장애 조치 클러스터링 요구 사항
장애 조치 클러스터를 구축하기 위해 다음 요구 사항을 충족해야 합니다:
- 호스트에 연결된 공유 저장소는 전용 고속 네트워크로 저지연으로 연결되어 있어야 합니다. 여러 호스트가 동시에 저장소에 위치한 데이터에 접근할 수 있도록 클러스터화된 파일 시스템을 사용해야 합니다.
- VM이 실행 중인 호스트는 동일한 하드웨어를 가져야 하거나 적어도 동일한 패밀리의 하드웨어를 가져야 합니다. 프로세서는 VM이 호스트 간 장애 조치(failover) 중에 올바르게 실행되도록 하기 위해 동일한 명령어 집합을 지원해야 합니다.
- A high-speed redundant network with low latency. There should be multiple, separate cluster networks, that is, a cluster must have different networks for storage, management, VM migration, connection of hosts amongst each other, etc.
사용 사례
장애 조치 클러스터는 서버 장애로부터 VM을 복구하여 중요한 VM에 대한 고가용성을 제공하는 데 사용됩니다. 클러스터 내에서 노드로 불리는 호스트 중 하나가 실패하면 해당 호스트에서 실행 중이던 VM은 다른 정상 호스트로 이동(장애 조치)합니다. 설정에 따라 장애 조치된 VM은 장애가 해결된 후 해당 이벤트가 발생하기 전에 실행 중이던 호스트로 다시 이동될 수 있습니다.
장점
A failover cluster has advantages that provide strong protection:
- A failover cluster provides automatic VM failover. You don’t need to start the failed VMs manually on other hosts.
- 장애 조치 시 데이터 손실이 거의 없습니다. 다운타임은 일반적으로 VM, 운영 체제(OS), 그리고 VM에서 실행 중인 소프트웨어를 로드하는 데 걸리는 시간으로 제한됩니다.
- VM웨어 고가용성 클러스터에 포함된 고장 허용 기능은 다운타임 및 데이터 손실 없이 VM 장애 조치를 보장합니다.
단점
A failover cluster does not protect against:
- VM의 소프트웨어 장애. 소프트웨어 버그나 바이러스로 인해 VM 시스템이 충돌할 수 있습니다.
- VM 내에서 파일이 실수로 삭제될 수 있습니다.
- 공유 스토리지 장애. 공유 스토리지가 실패하면 클러스터도 실패합니다. 공유 스토리지는 클러스터의 중요한 구성 요소로, 클러스터 내의 VM에 속한 가상 디스크가 공유 스토리지에 저장됩니다.
- A disaster that makes the whole physical site unavailable.
페일오버 클러스터에 대한 자세한 정보는 VMware 클러스터링에 대한 완전 가이드를 읽어보세요.
솔루션 2. VM 복제를 사용한 페일오버
VM 복제에 의존한 VM 페일오버는 관리자에 의해 트리거될 때 VM을 복제하고 복제본을 시작하는 특수 애플리케이션을 사용하여 실행할 수 있습니다. 데이터 보호 소프트웨어 외에도, 소스 VM이 실패할 경우 VM 복제본을 실행할 준비가 미리 된 ESXi 또는 Hyper-V 호스트(환경에 따라)가 필요합니다.
아래 다이어그램에서는 두 개의 호스트가 네트워크를 통해 연결되어 있습니다. VM은 호스트의 디스크를 사용하고 있습니다. 소스 VM은 첫 번째 호스트에서 실행되고, 특정 시점의 소스 VM의 정확한 복사본인 VM 복제본은 두 번째 호스트에 꺼진 상태로 위치해 있습니다.
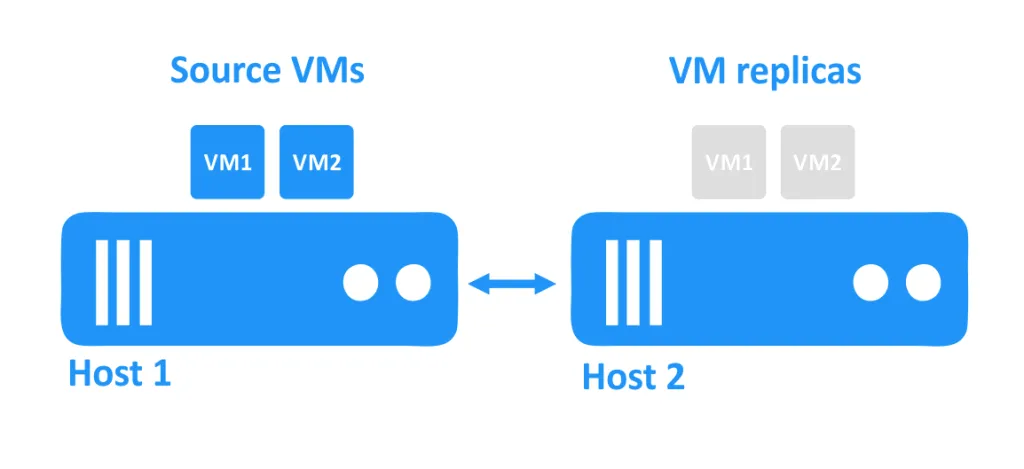
하나의 호스트가 다운되면 해당 호스트에서 실행되던 VM에 접근할 수 없게 됩니다. 다른 호스트에 위치한 VM 복제본은 관리자에 의해 전원을 켜게 됩니다.
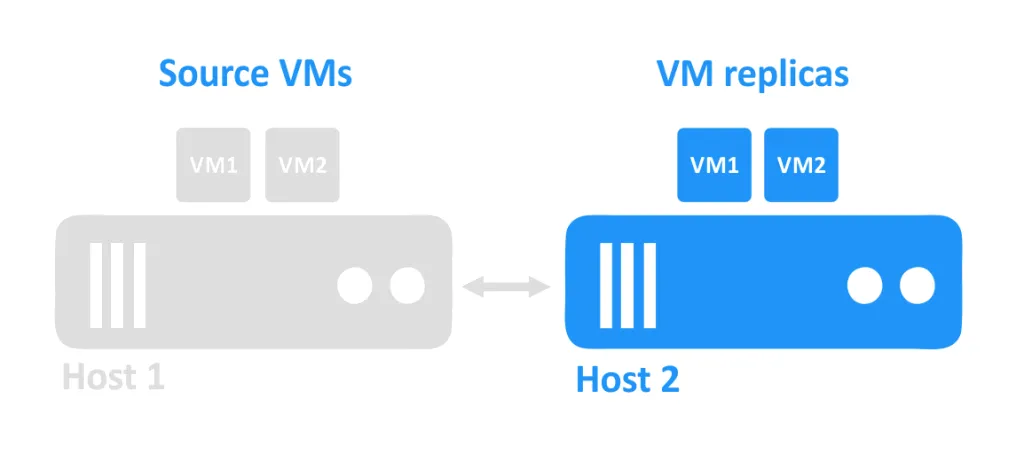
VM 복제 요구 사항
기본적인 VM 副本 제어에는 두 hosts 이상과 副本 솔루션이 있어야 합니다. 첫 번째 host 上에 실행중인 소스 VM을 두 번째 host에 副本化합니다. VM 副本는 두 번째 host에 위치합니다.
사용 사례
VM 副本를 사용하여 Hardware 또는 Software 장애가 발생할 때 이전이 가능합니다. ESXi나 Hyper-V host의 장애는 hardware 장애의 예입니다. Software 장애의 예로는 실패한 更新, Sofware 虫, 恶意软件 攻撃, 또는 사용자의 과정에 의해 파일이 意外적으로 지워진 것입니다.
장점
VM 副本를 이용한 이전의 주요 장점은 副本를 멀리 있는 장소로 이전할 수 있는 것입니다. VM 副本을 생성하는 동안, 소스 VMから 복사되는 데이터는 네트워크 연결(bandwidth이 限制되어 있을 수 있음)를 통해 멀리 있는 장소로 전송할 수 있습니다. 멀리 있는 장소는 인근 사무실이나 세계 的另一端에 위치할 수 있습니다. VM 副本이 기본 생산 사이트에서 위치할 수도 있습니다.
단점
VM 副本를 사용한 이전에 대한 단점 목록입니다.
- hardware 또는 software 장애가 발생하고 副本이 두 번째 host에서 시작되기 전의 short period of downtime가 발생합니다.
- 이전은 수동으로 시작되어야 합니다.
- 意外의 이전 과정에서 마지막 副本化 이후에 기록된 데이터가 잃을 수 있습니다. VM 副本은 일반적으로 실시간(synchronous) 과정이 아니며, synchronous replication은 리소스에 significant load을 places합니다. 副本는 자신의 선택한 setting에 따라 정기적인 time interval에서 실행됩니다.
- VM의 네트워크 설정은 다른 사이트로의 장애 조치(failover) 시 변경되어야 합니다. 원본 사이트의 VM 네트워크와 원격 사이트의 VM 네트워크는 다를 수 있습니다. 따라서 IP 주소도 다를 수 있으며, 장애 조치 중 다른 네트워크 설정과 함께 확인하고 변경해야 합니다.
클러스터링 vs 복제 기반 VM 장애 조치
| 클러스터링을 이용한 장애 조치 | 복제를 이용한 장애 조치 | |
| 목적 | 고가용성 | 재해 복구 |
| 다음에 대한 보호 | 하드웨어 장애만 | 하드웨어 및 소프트웨어 장애 |
| 관리 | 자동으로 시작 | 수동으로 시작 |
| 가동 중지 시간 (RTO) | 장애 조치가 더 빨라 VM 가동 중지 시간이 짧음 (짧은 RTO) | 장애 조치에 더 많은 시간이 소요되어 VM 가동 중지 시간이 더 길다 |
| 요구 사항 | 더 많은 요구 사항 | 더 적은 요구 사항 |
| 솔루션 가격 | 클러스터링 솔루션은 일반적으로 더 비싸다 | 복제 솔루션은 더 비용 효율적이다 |
| 데이터 손실 (RPO) | 거의 제로 데이터 손실 (매우 낮은 RPO) | 데이터 손실은 복제 빈도에 따라 다름 |
클러스터와 レプリカ 사용을 통한 VM 자동 재시작
클러스터 및 レプリKA 자동 재시작 솔루션은 때때로 대신 해결 方案으로 생각되지만, 서로를 supplement하는 용도로도 사용할 수 있습니다. 的服务器 级的vm 失败,
- 예 1: 클러스터 내에서 실행 중인 VM을 리모ote 사이트의 호스트로 복제 할 수 있습니다. 또한, 하나의 클러스터 내에서 실행 중인 VM을 다른 클러스터로 복제할 수도 있습니다. 따라서, 호스트가 실패하면 이러한 클러스터 기반 자동 재시작은 那些 VM online 유지합니다. hole site가 障碍 를 겪는 경우, 다른 사이트로부터 那些 VM 리plica를 가져와 자동 재시작할 수 있습니다.
- 예 2: computer virus가 某些 VM 내의 파일을 耳朵. A failover cluster cannot protect against such file system failures. but if you have VM replicas with multiple recovery points, you can restore each VM to a point in time before their files were damaged or deleted.
NAKIVO 솔루션을 사용하여 VMware VM Failover to Replica 자동화
NAKIVO Backup & Replication은 클러스터 내에서 실행되는 가상 머신을 보호하고, 가상 머신을 복제하고, 레플리카로 장애 조치를 수행하며, 복잡한 재해 복구 시퀀스를 조율할 수 있는 백업 및 재해 복구 솔루션입니다. 스탠드얼론 ESXi 또는 Hyper-V 호스트뿐만 아니라 클러스터도 소스 및 대상 지점으로 지원됩니다. 이 솔루션은 자동으로 가상 머신이 어느 호스트에 있는지 추적하여 해당 가상 머신을 복제할 수 있습니다. 이 기능은 재해 조치 이벤트나 로드 밸런싱 이벤트(클러스터는 일반적으로 로드 밸런싱과 함께 구성됨) 후에 가상 머신이 클러스터 내의 다른 호스트로 이동할 수 있기 때문에 유용합니다. 따라서 클러스터에서 가상 머신을 복제하는 데 사용하는 소프트웨어는 해당 가상 머신이 있는 호스트를 추적할 수 있어야 합니다.
NAKIVO 솔루션은 재해 조치 후 가상 머신의 네트워크 설정을 자동으로 변경할 수 있습니다. 복제 또는 재해 조치 작업을 구성할 때 네트워크 매핑 및 Re-IP 기능을 사용하면 됩니다.
NAKIVO Backup & Replication에서 자동 가상 머신 재해 조치(네트워크 매핑 및 Re-IP 포함) 예제를 살펴보겠습니다. 먼저 가상 머신 레플리카를 생성합니다.
가상 머신 재해 조치에 필요한 복제 구성
작업 대시보드에서 만들기 > VMware vSphere 복제 작업을 클릭하여 VMware 가상 환경을 사용하는 경우 복제 작업을 생성합니다. Microsoft Hyper-V VM이나 Amazon EC2 인스턴스에 대한 복제 작업도 동일한 방법으로 생성할 수 있습니다.
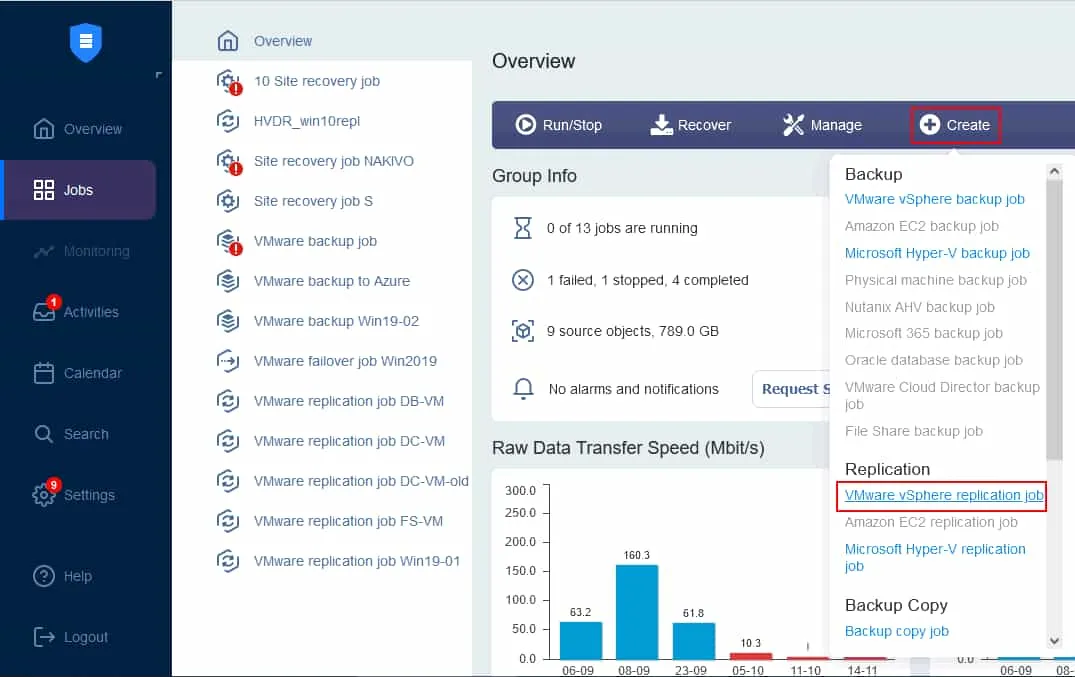
복제 작업 마법사가 시작됩니다.
- 仮想マシンを選択して、 replication したいvmを選択します。この例では、Server2019 vmがゲストオペレーティングシステムとしてWindows Server 2019を実行しているとし、 replication されます。Nextをクリックします。
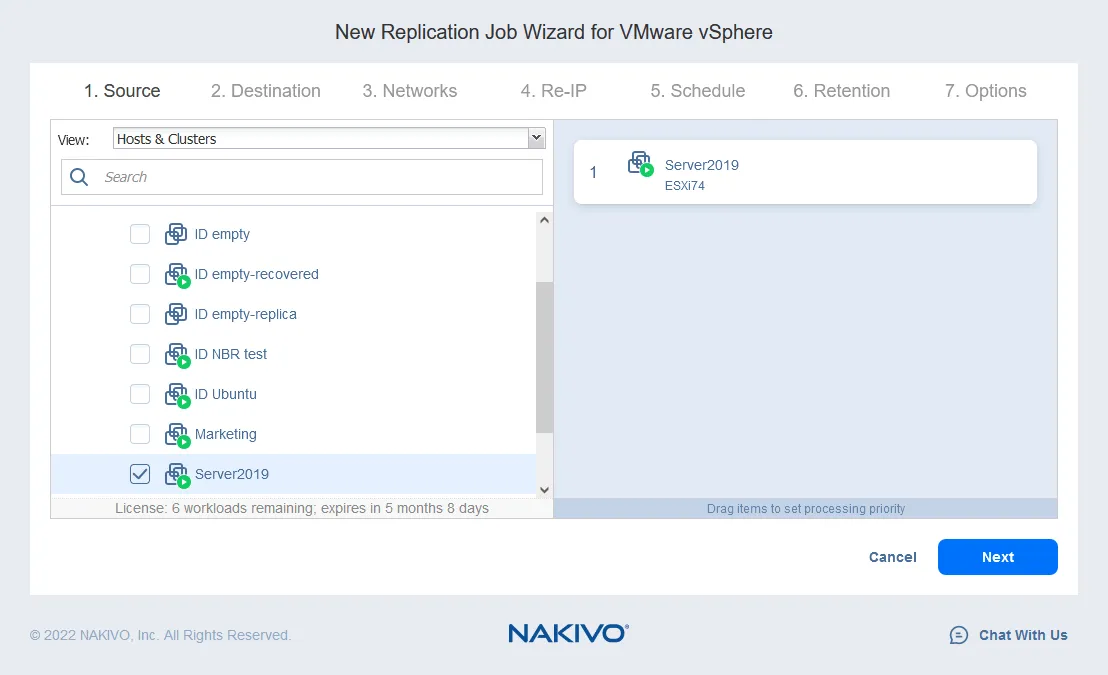
- vm replication が実行されるための宛先ホスト(今回は10.10.10.90)を選択します。選択したホストにマウントされたデータストアを選択し、vm ファイルの配置先として選択します。Nextをクリックします。
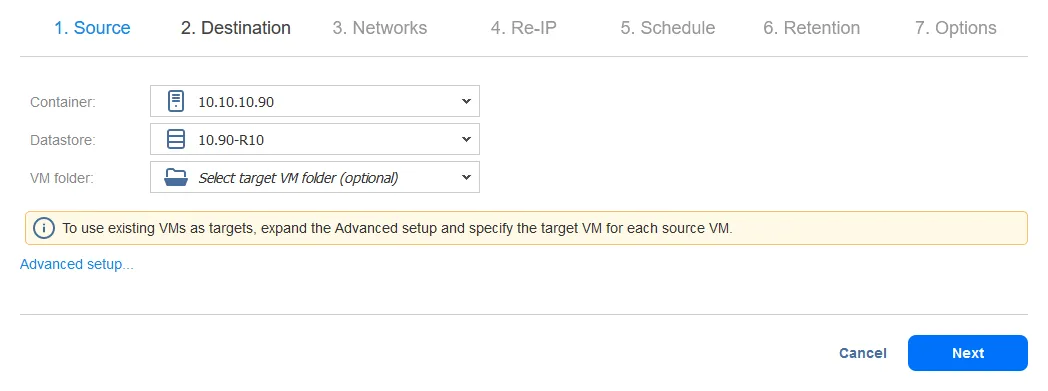
- replication ジョブやファイアーオーバージョブを設定する際に、ネットワークマッピングと再IP設定を行うことができます。このチュートリアルでは、ファイアーオーバージョブを設定する際に、後でネットワークマッピングと再IP設定を行うため、このステップをスキップし、Nextをクリックします。
- Re-IP 구성은 이 안내에서 VM 장애 조치 작업 구성 중에 설명될 것입니다. 다음을 클릭하세요.
- 스케줄링 설정을 선택하세요. 완료되면 다음을 클릭하세요.
- 유지 설정을 설정하세요. 이 단계에서 할아버지-아버지-아들 보관 정책을 설정할 수 있다는 점을 기억하세요. 다음을 클릭하세요.
- 복제 작업 옵션을 선택하고 완료 또는 완료 및 실행 버튼을 클릭하십시오. 복제본이 생성될 때까지 기다리십시오.
VM 재해 복구 구성
이제 VM 복제본이 생성되었으므로 이 복제본으로 VM 재해 복구를 수행할 수 있습니다.
대시보드의 홈 페이지에서 복구 > VMware 전체 복구 (VM 복제본 재해 복구)를 클릭하십시오. 새 복구 작업 마법사가 열립니다.
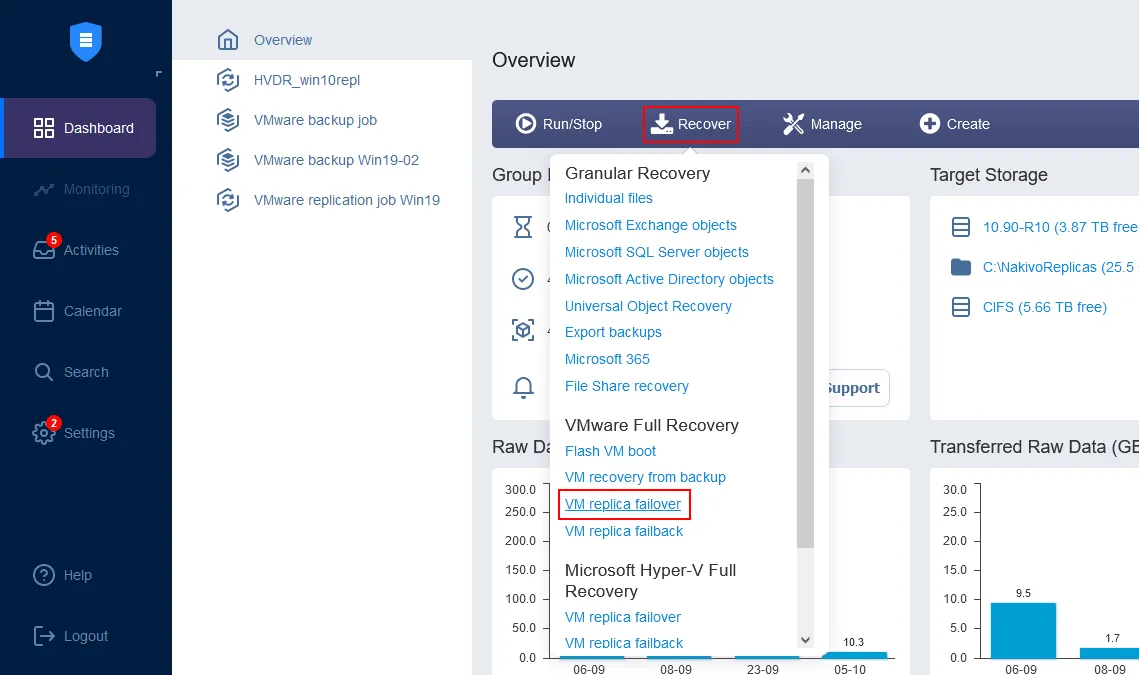
- 왼쪽 창에서 재해 복구에 사용할 VM 복제본을 선택하십시오. 이 안내서에서는 방금 생성된 Server2019-replica를 선택합니다.오른쪽 창에서 복구 지점을 선택하십시오. 솔루션에서는 기본적으로 최신 복구 지점이 선택됩니다. 다음을 클릭하십시오.
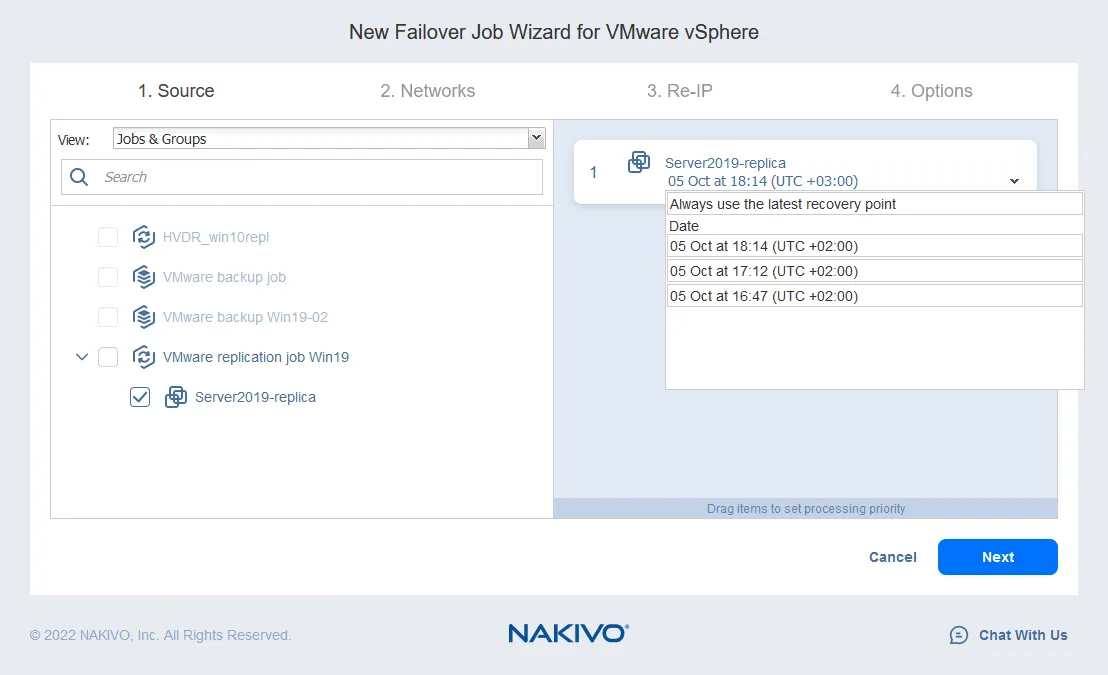
- 네트워크 매핑 기능을 사용하면 VM이 연결된 네트워크를 변경할 수 있습니다. 소스 및 대상 ESXi 호스트는 서로 다른 가상 스위치 설정을 가질 수 있습니다. VM 레플리카는 소스 VM의 정확한 사본이므로 소스 VM이 연결된 가상 네트워크는 VM 레플리카에 보존됩니다.
보통 VM 레플리카의 네트워크 설정을 확인하고 수동으로 네트워크를 변경해야 합니다. NAKIVO 백업 & 복제는 소스 네트워크를 대상 네트워크로 자동으로 매핑할 수 있습니다. 레플리케이션 또는 장애 조치 작업을 구성할 때 네트워크 매핑을 설정하기만 하면 됩니다.
- 네트워크 매핑을 활성화하려면 확인란을 선택하세요. 이전에 네트워크 매핑 규칙을 만든 경우 기존 매핑 추가를 클릭할 수 있습니다. 네트워크 매핑 규칙이 없는 경우 새 매핑 만들기를 클릭하세요.
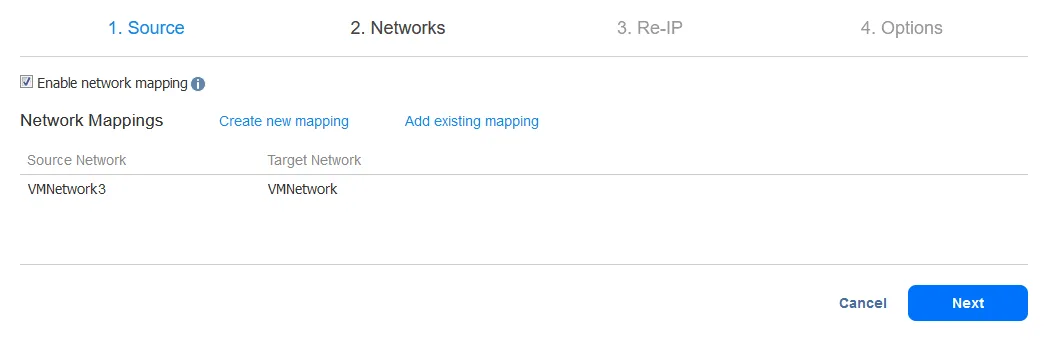
-
새 네트워크 매핑 규칙을 만들려면 소스 네트워크와 대상 네트워크를 선택하세요. 소스 네트워크는 소스 VM이 연결된 네트워크입니다. 대상(타겟) 네트워크는 VM 레플리카가 연결될 네트워크입니다.
참고: VM 네트워크 이름은 IP 주소나 네트워크 주소와 동일하지 않습니다.
저장을 클릭하여 네트워크 매핑 규칙을 저장한 후 다음을 클릭하여 구성을 진행하세요.
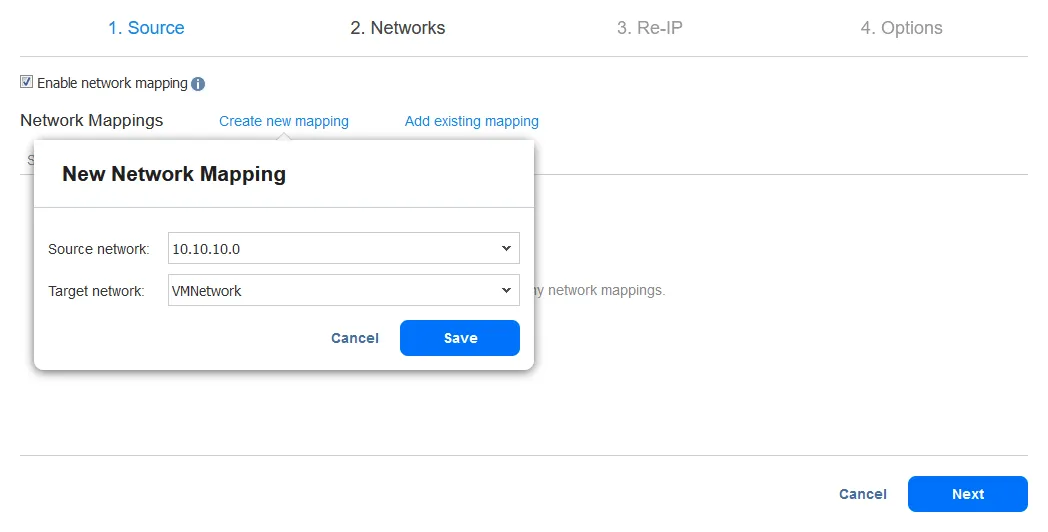
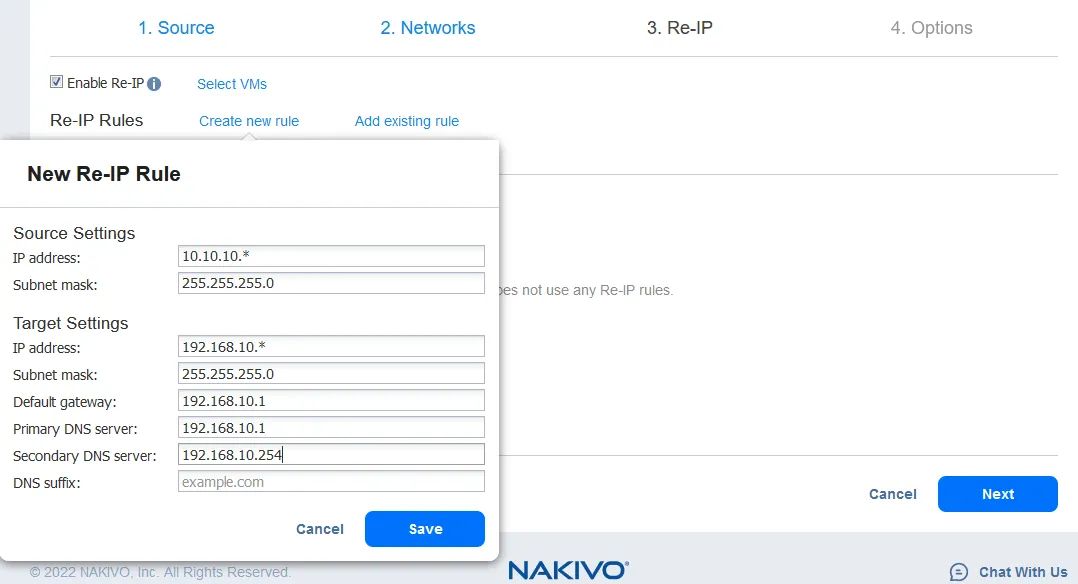
- Re-IP 기능을 사용하면 VM 레플리카의 IP 설정을 변경할 수 있습니다. 정적 IP 주소에 사용할 수 있습니다. 이 옵션을 활성화하려면 Re-IP 활성화 확인란을 선택하고, 새 Re-IP 규칙을 만들거나 기존 규칙을 추가하세요. 이전에 규칙을 만들지 않은 경우 새 규칙 만들기를 클릭하세요. 팝업 메뉴가 나타납니다.
- 네트워크 매핑을 활성화하려면 확인란을 선택하세요. 이전에 네트워크 매핑 규칙을 만든 경우 기존 매핑 추가를 클릭할 수 있습니다. 네트워크 매핑 규칙이 없는 경우 새 매핑 만들기를 클릭하세요.
- 소스 VM 설정은 변경해야 할 IP 주소와 네트워크 마스크입니다.
대상 설정은 장애 조치가 발생할 때 VM 레플리카에 적용되는 설정입니다. 이 예에서 [*] 문자는 마지막 옥텟을 대신합니다. [*]는 1에서 254까지의 숫자를 의미합니다. 예를 들어 소스 IP 주소가 10.10.10.1, 10.10.10.96 및 10.10.10.222인 경우 대상 주소는 각각 192.168.10.1, 192.168.10.96 및 192.168.10.222입니다. IP 주소의 마지막 옥텟은 보존됩니다.
저장을 클릭하여 Re-IP 규칙을 저장하고 진행하세요.
Re-IP 규칙을 추가한 후 화면이 다음과 같아야 합니다: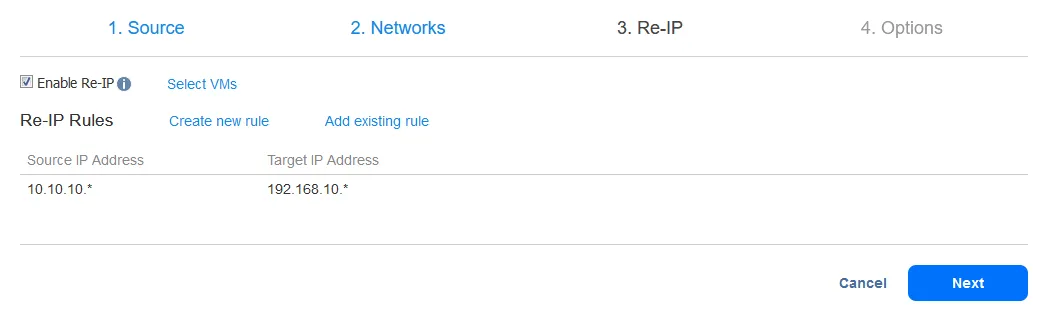
이제 Re-IP 규칙을 적용할 VM을 선택하세요. 이 예에서 장애 조치 작업에는 하나의 VM 레플리카만 포함되어 있으므로 확인란을 선택하세요.
그런 다음 각 VM에 대한 자격 증명을 선택하세요. 새 자격 증명을 추가하려면 자격 증명 관리> 자격 증명 추가를 클릭하세요. 추가된 자격 증명은 드롭다운 목록에서 선택할 수 있습니다.
참고: 자격 증명은 NAKIVO 백업 & 복제가 VM 내부의 운영 체제의 네트워크 설정에 액세스하고 해당 설정을 변경하는 스크립트를 적용하기 위해 필요합니다. VMware vSphere VM에는 VMware Tools이 설치되어 있어야 하며 Microsoft Hyper-V VM에는 Hyper-V 통