













В эпоху данных в реальном времени способность обрабатывать и анализировать потоковую информацию стала критически важной для бизнеса. Apache Kafka, мощная распределенная платформа потоковой передачи событий, часто находится в центре этих реальных пайплайнов. Однако работа с сырыми потоками данных может быть сложной. Здесь на помощь приходит Streaming SQL: он позволяет пользователям запрашивать и преобразовывать темы Kafka с простотой SQL.
Что такое Streaming SQL?
Streaming SQL относится к применению структурированного языка запросов (SQL) для обработки и анализа данных в движении. В отличие от традиционного SQL, который запрашивает статические наборы данных в базах данных, streaming SQL непрерывно обрабатывает данные по мере их поступления в систему. Он поддерживает операции, такие как фильтрация, агрегация, объединение и окно в реальном времени.
С Kafka в качестве основы для пайплайнов данных в реальном времени, Streaming SQL позволяет пользователям напрямую запрашивать темы Kafka, упрощая анализ и работу с данными без написания сложного кода.
Ключевые компоненты Streaming SQL на Kafka
1. Apache Kafka
Kafka хранит и передает события в реальном времени через темы. Производители записывают данные в темы, а потребители подписываются, чтобы обрабатывать или анализировать эти данные. Долговечность, масштабируемость и отказоустойчивость Kafka делают его идеальным для потоковых данных.
2. Kafka Connect
Kafka Connect облегчает интеграцию с внешними системами, такими как базы данных, объектные хранилища или другие потоковые платформы. Он обеспечивает безшовную загрузку или экспорт данных в/из тем Kafka.
3. Потоковые SQL-движки
Несколько инструментов позволяют работать с SQL в Kafka, включая:
- ksqlDB: Потоковый SQL-движок, построенный на Kafka Streams.
- Apache Flink SQL: Универсальный фреймворк потоковой обработки с продвинутыми возможностями SQL.
- Apache Beam: Предоставляет SQL для пакетной и потоковой обработки, совместим с различными раннерами.
- Spark Structured Streaming: Поддерживает SQL для обработки данных в реальном времени и пакетной обработки.
Как работает потоковой SQL?
Потоковые SQL-движки подключаются к Kafka для чтения данных из тем, обработки их в реальном времени и вывода результатов в другие темы, базы данных или внешние системы. Процесс обычно включает следующие шаги:
- Определение потоков данных: Пользователи определяют потоки или таблицы, указывая темы Kafka в качестве источников.
- Выполнение запросов: SQL-запросы выполняются для выполнения операций, таких как фильтрация, агрегация и объединение потоков.
- Вывод результатов: Результаты могут быть записаны обратно в темы Kafka или внешние хранилища, такие как базы данных или панели инструментов.
Диаграмма потока
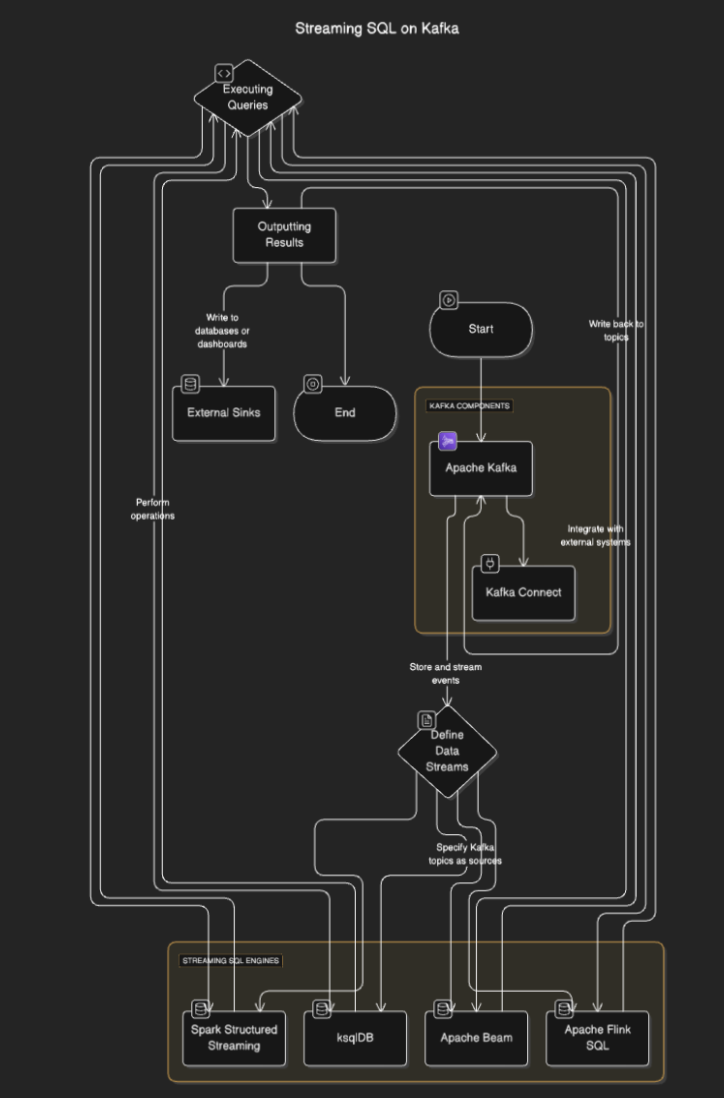
Инструменты Streaming SQL для Kafka
ksqlDB
ksqlDB предназначен для работы с Kafka и предоставляет SQL-интерфейс для обработки тем Kafka. Он упрощает операции, такие как фильтрация сообщений, объединение потоков и агрегация данных. Основные функции включают в себя:
- Декларативные SQL-запросы: Определение трансформаций в реальном времени без написания кода.
- Материализованные представления: Сохранение результатов запросов для быстрого доступа.
- Оптимизировано для Kafka: Оптимизировано для обработки с низкой задержкой.
Пример:
CREATE STREAM purchases (
user_id VARCHAR,
item_id VARCHAR,
amount DECIMAL
) WITH (
KAFKA_TOPIC='purchases_topic',
VALUE_FORMAT='JSON'
);
CREATE STREAM high_value_purchases AS
SELECT *
FROM purchases
WHERE amount > 100;
Apache Flink SQL
Apache Flink – мощный фреймворк для обработки потоков, который предоставляет возможности SQL как для пакетной, так и для потоковой обработки данных. Он поддерживает сложные операции, такие как обработка времени событий и продвинутое оконное разделение.
Пример:
CREATE TABLE purchases (
user_id STRING,
amount DECIMAL,
purchase_time TIMESTAMP(3),
WATERMARK FOR purchase_time AS purchase_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'purchases_topic',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json',
'scan.startup.mode' = 'earliest-offset'
);
SELECT user_id, COUNT(*) AS purchase_count
FROM purchases
GROUP BY user_id;
Структурированный поток Apache Spark
Spark Structured Streaming позволяет обработку потоков данных на основе SQL и хорошо интегрируется с другими компонентами Spark. Идеально подходит для создания сложных конвейеров данных, объединяющих пакетную и потоковую обработку.
Пример:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("StreamingSQL").getOrCreate()
# Read Kafka topic as a stream
df = spark.readStream.format("kafka").option("subscribe", "purchases_topic").load()
# Perform SQL-like transformations
df.selectExpr("CAST(value AS STRING)").createOrReplaceTempView("purchases")
query = spark.sql("SELECT user_id, COUNT(*) AS purchase_count FROM purchases GROUP BY user_id")
query.writeStream.format("console").start()
Сценарии использования Streaming SQL на Kafka
- Аналитика в реальном времени. Отслеживание активности пользователей, продаж или данных датчиков IoT с помощью интерактивных панелей управления в реальном времени.
- Преобразование данных. Очистка, фильтрация или обогащение данных по мере их прохождения через темы Kafka.
- Выявление мошенничества. Выявление подозрительных транзакций или узоров в реальном времени.
- Динамические оповещения. Генерация оповещений при достижении определенных порогов или условий.
- Обогащение конвейера данных. Объединение потоков с внешними наборами данных для создания обогащенных выходных данных
Преимущества Streaming SQL на Kafka
- Упрощенная разработка. SQL знакомо многим разработчикам, что уменьшает кривую обучения.
- Обработка в реальном времени. Позволяет мгновенно получать и анализировать данные в потоке.
- Масштабируемость. Использование распределенной архитектуры Kafka обеспечивает масштабируемость.
- Интеграция. Легко интегрируется с существующими конвейерами на основе Kafka.
Задачи и соображения
- Управление состоянием. Сложные запросы могут потребовать управления большими объемами данных, что может повлиять на производительность.
- Оптимизация запросов. Обеспечить эффективную обработку потоков с высокой пропускной способностью.
- Выбор инструмента. Выберите подходящий SQL-движок в зависимости от ваших требований (например, задержка, сложность).
- Отказоустойчивость. Системы потоковой обработки SQL должны уметь обрабатывать отказы узлов и обеспечивать согласованность данных.
Заключение
Потоковая обработка SQL на Kafka дает возможность бизнесу использовать данные в реальном времени с помощью простоты SQL. Инструменты, такие как ksqlDB, Apache Flink и Spark Structured Streaming, позволяют создавать надежные, масштабируемые и низколатентные конвейеры данных без глубоких знаний программирования.
Source:
https://dzone.com/articles/real-time-insights-with-streaming-sql-on-kafka