













Na era dos dados em tempo real, a capacidade de processar e analisar informações em streaming tornou-se crucial para as empresas. O Apache Kafka, uma poderosa plataforma distribuída de streaming de eventos, muitas vezes está no centro desses pipelines em tempo real. Mas trabalhar com fluxos de dados brutos pode ser complexo. É aí que o Streaming SQL entra em cena: ele permite que os usuários consultem e transformem tópicos do Kafka com a simplicidade do SQL.
O que é o Streaming SQL?
O Streaming SQL refere-se à aplicação da linguagem de consulta estruturada (SQL) para processar e analisar dados em movimento. Ao contrário do SQL tradicional, que consulta conjuntos de dados estáticos em bancos de dados, o Streaming SQL processa continuamente os dados à medida que fluem por um sistema. Ele suporta operações como filtragem, agregação, junção e janelamento em tempo real.Com o Kafka como espinha dorsal dos pipelines de dados em tempo real, o Streaming SQL permite que os usuários consultem diretamente tópicos do Kafka, facilitando a análise e a ação sobre os dados sem escrever código complexo.
Componentes-chave do Streaming SQL no Kafka
1. Apache Kafka
O Kafka armazena e transmite eventos em tempo real por meio de tópicos. Os produtores escrevem dados nos tópicos, e os consumidores se inscrevem para processar ou analisar esses dados. A durabilidade, escalabilidade e tolerância a falhas do Kafka o tornam ideal para dados em streaming.
2. Kafka Connect
O Kafka Connect facilita a integração com sistemas externos como bancos de dados, repositórios de objetos ou outras plataformas de streaming. Ele permite a ingestão ou exportação contínua de dados para/de tópicos do Kafka.
3. Motores de SQL de Streaming
Várias ferramentas permitem o SQL de Streaming no Kafka, incluindo:
- ksqlDB: Um motor de SQL de streaming nativo do Kafka construído sobre o Kafka Streams.
- Apache Flink SQL: Um framework versátil de processamento de stream com capacidades avançadas de SQL.
- Apache Beam: Fornece SQL para processamento em lote e em stream, compatível com vários executores.
- Spark Structured Streaming: Suporta SQL para processamento de dados em tempo real e em lote.
Como Funciona o SQL de Streaming?
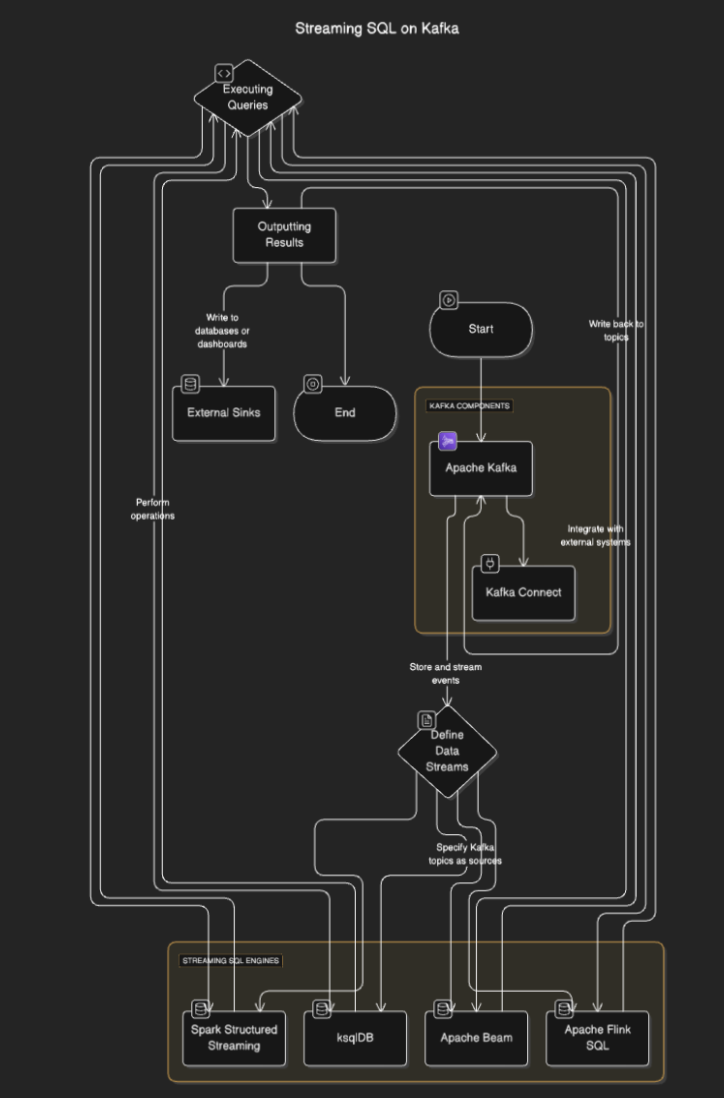
SQL de Streaming se conectam ao Kafka para ler dados dos tópicos, processá-los em tempo real e enviar os resultados para outros tópicos, bancos de dados ou sistemas externos. O processo geralmente envolve as seguintes etapas:
- Definindo fluxos de dados: Os usuários definem fluxos ou tabelas especificando os tópicos do Kafka como fontes.
- Executando consultas: Consultas SQL são executadas para realizar operações como filtragem, agregação e junção de fluxos.
- Resultados de saída: Os resultados podem ser escritos de volta para tópicos do Kafka ou destinos externos como bancos de dados ou painéis.
Diagrama de Fluxo
Ferramentas de SQL em Tempo Real para Kafka
ksqlDB
ksqlDB foi desenvolvido especialmente para o Kafka e fornece uma interface SQL para processar tópicos do Kafka. Ele simplifica operações como filtragem de mensagens, junção de fluxos e agregação de dados. Recursos principais incluem:
- Consultas SQL Declarativas: Defina transformações em tempo real sem codificação.
- Visões Materializadas: Persista os resultados da consulta para pesquisas rápidas.
- Nativo do Kafka: Otimizado para processamento de baixa latência.
Exemplo:
CREATE STREAM purchases (
user_id VARCHAR,
item_id VARCHAR,
amount DECIMAL
) WITH (
KAFKA_TOPIC='purchases_topic',
VALUE_FORMAT='JSON'
);
CREATE STREAM high_value_purchases AS
SELECT *
FROM purchases
WHERE amount > 100;
Apache Flink SQL
Apache Flink é um poderoso framework de processamento de streaming que fornece capacidades SQL para dados em lote e em streaming. Ele suporta operações complexas como processamento de tempo de evento e janelas avançadas.
Exemplo:
CREATE TABLE purchases (
user_id STRING,
amount DECIMAL,
purchase_time TIMESTAMP(3),
WATERMARK FOR purchase_time AS purchase_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'purchases_topic',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json',
'scan.startup.mode' = 'earliest-offset'
);
SELECT user_id, COUNT(*) AS purchase_count
FROM purchases
GROUP BY user_id;
Apache Spark Structured Streaming
Spark Structured Streaming permite o processamento de fluxo baseado em SQL e integra-se bem com outros componentes do Spark. É ideal para pipelines de dados complexos que combinam processamento em lote e em fluxo.
Exemplo:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("StreamingSQL").getOrCreate()
# Read Kafka topic as a stream
df = spark.readStream.format("kafka").option("subscribe", "purchases_topic").load()
# Perform SQL-like transformations
df.selectExpr("CAST(value AS STRING)").createOrReplaceTempView("purchases")
query = spark.sql("SELECT user_id, COUNT(*) AS purchase_count FROM purchases GROUP BY user_id")
query.writeStream.format("console").start()
Casos de Uso para SQL em Streaming no Kafka
- Análise em tempo real. Monitore a atividade do usuário, vendas ou dados de sensores IoT com painéis ao vivo.
- Transformação de dados. Limpe, filtre ou enriqueça dados conforme eles fluem pelos tópicos do Kafka.
- Deteção de fraudes. Identifique transações suspeitas ou padrões em tempo real.
- Alertas dinâmicos. Acione alertas quando determinados limites ou condições forem atingidos.
- Enriquecimento de pipeline de dados. Junte fluxos com conjuntos de dados externos para criar saídas de dados enriquecidos
Benefícios do SQL em Streaming no Kafka
- Desenvolvimento simplificado. O SQL é familiar para muitos desenvolvedores, reduzindo a curva de aprendizado.
- Processamento em tempo real. Permite insights imediatos e ações sobre dados em fluxo.
- Escala. Aproveitando a arquitetura distribuída do Kafka, garante escalabilidade.
- Integração. Integra facilmente com pipelines existentes baseados no Kafka.
Desafios e Considerações
- Gerenciamento de estado. Consultas complexas podem exigir o gerenciamento de grandes estados, o que pode afetar o desempenho.
- Otimização de consulta. Garanta que as consultas sejam eficientes para lidar com streams de alto rendimento.
- Seleção de ferramentas. Escolha o motor SQL certo com base em seus requisitos (por exemplo, latência, complexidade).
- Tolerância a falhas. Os motores SQL de streaming devem lidar com falhas de nós e garantir a consistência dos dados.
Conclusão
O Streaming SQL no Kafka capacita as empresas a aproveitar os dados em tempo real com a simplicidade do SQL. Ferramentas como ksqlDB, Apache Flink e Spark Structured Streaming tornam possível construir pipelines de dados robustos, escaláveis e de baixa latência sem a necessidade de uma expertise em programação profunda.
Source:
https://dzone.com/articles/real-time-insights-with-streaming-sql-on-kafka