













En la era de los datos en tiempo real, la capacidad de procesar y analizar información en streaming se ha vuelto crítica para las empresas. Apache Kafka, una poderosa plataforma de streaming de eventos distribuida, a menudo está en el corazón de estos pipelines en tiempo real. Pero trabajar con flujos de datos en bruto puede ser complejo. Aquí es donde entra Streaming SQL: permite a los usuarios consultar y transformar temas de Kafka con la simplicidad de SQL.
¿Qué es Streaming SQL?
Streaming SQL se refiere a la aplicación de lenguaje de consulta estructurado (SQL) para procesar y analizar datos en movimiento. A diferencia del SQL tradicional, que consulta conjuntos de datos estáticos en bases de datos, Streaming SQL procesa continuamente los datos a medida que fluyen a través de un sistema. Soporta operaciones como filtrado, agregación, unión y ventanas en tiempo real.
Con Kafka como la columna vertebral de los pipelines de datos en tiempo real, Streaming SQL permite a los usuarios consultar directamente los temas de Kafka, facilitando el análisis y la acción sobre los datos sin necesidad de escribir código complejo.
Componentes clave de Streaming SQL en Kafka
1. Apache Kafka
Kafka almacena y transmite eventos en tiempo real a través de temas. Los productores escriben datos en los temas, y los consumidores se suscriben para procesar o analizar esos datos. La durabilidad, escalabilidad y tolerancia a fallos de Kafka lo hacen ideal para el streaming de datos.
2. Kafka Connect
Kafka Connect facilita la integración con sistemas externos como bases de datos, almacenes de objetos u otras plataformas de transmisión. Permite la ingestión o exportación sin problemas de datos hacia/desde los temas de Kafka.
3. Motores de SQL en streaming
Varias herramientas permiten SQL en streaming en Kafka, incluyendo:
- ksqlDB: Un motor de SQL en streaming nativo de Kafka construido sobre Kafka Streams.
- Apache Flink SQL: Un marco de procesamiento de transmisiones versátil con capacidades avanzadas de SQL.
- Apache Beam: Proporciona SQL para procesamiento por lotes y en streaming, compatible con varios ejecutores.
- Spark Structured Streaming: Admite SQL para procesamiento de datos en tiempo real y por lotes.
¿Cómo funciona el SQL en streaming?
SQL en streaming los motores se conectan a Kafka para leer datos de los temas, procesarlos en tiempo real, y enviar los resultados a otros temas, bases de datos o sistemas externos. El proceso generalmente implica los siguientes pasos:
- Definir flujos de datos: Los usuarios definen flujos o tablas especificando los temas de Kafka como fuentes.
- Ejecutar consultas: Se ejecutan consultas SQL para realizar operaciones como filtrado, agregación y unión de flujos.
- Resultados de salida: Los resultados pueden ser escritos de vuelta a los temas de Kafka o a destinos externos como bases de datos o paneles.
Diagrama de flujo
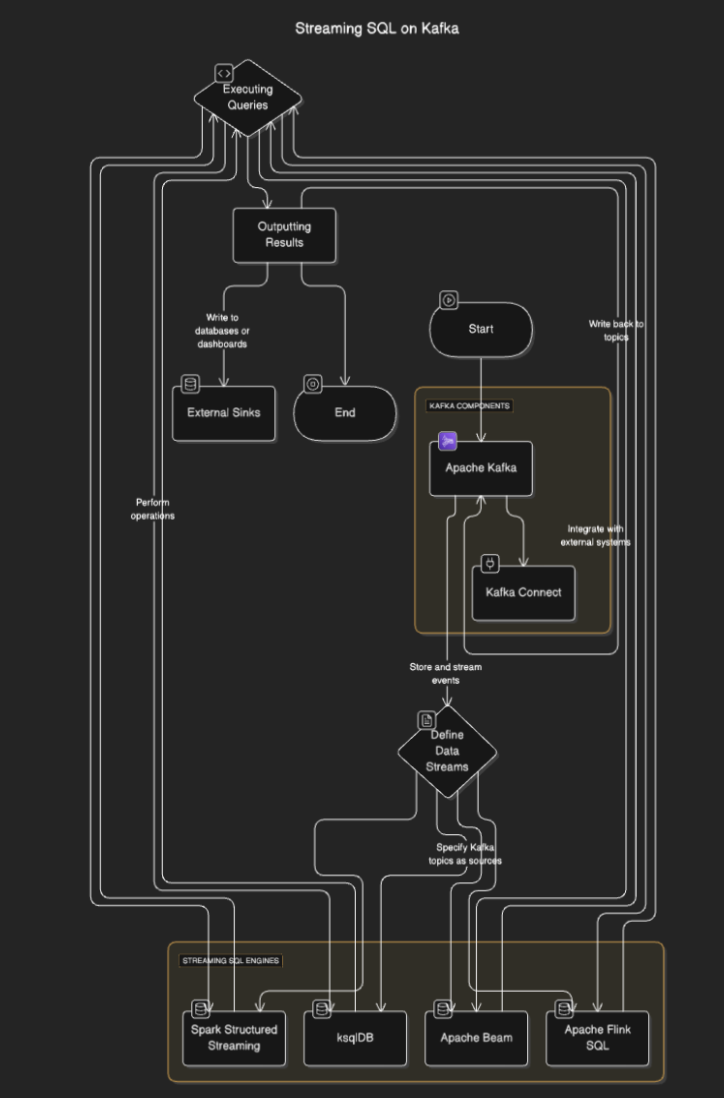
Herramientas de SQL en streaming para Kafka
ksqlDB
ksqlDB está diseñado específicamente para Kafka y proporciona una interfaz SQL para procesar temas de Kafka. Simplifica operaciones como filtrar mensajes, unir flujos y agregar datos. Las características clave incluyen:
- Consultas SQL declarativas: Define transformaciones en tiempo real sin necesidad de programación.
- Vistas materializadas: Persiste los resultados de las consultas para búsquedas rápidas.
- Optimizado para Kafka: Optimizado para procesamiento de baja latencia.
Ejemplo:
CREATE STREAM purchases (
user_id VARCHAR,
item_id VARCHAR,
amount DECIMAL
) WITH (
KAFKA_TOPIC='purchases_topic',
VALUE_FORMAT='JSON'
);
CREATE STREAM high_value_purchases AS
SELECT *
FROM purchases
WHERE amount > 100;
SQL de Apache Flink
Apache Flink es un potente marco de procesamiento de flujos que proporciona capacidades SQL tanto para datos por lotes como en tiempo real. Admite operaciones complejas como el procesamiento de tiempo de eventos y ventanas avanzadas.
Ejemplo:
CREATE TABLE purchases (
user_id STRING,
amount DECIMAL,
purchase_time TIMESTAMP(3),
WATERMARK FOR purchase_time AS purchase_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'purchases_topic',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json',
'scan.startup.mode' = 'earliest-offset'
);
SELECT user_id, COUNT(*) AS purchase_count
FROM purchases
GROUP BY user_id;
Apache Spark Structured Streaming
Spark Structured Streaming permite el procesamiento de flujos basado en SQL e se integra bien con otros componentes de Spark. Es ideal para canalizaciones de datos complejas que combinan procesamiento por lotes y en tiempo real.
Ejemplo:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("StreamingSQL").getOrCreate()
# Read Kafka topic as a stream
df = spark.readStream.format("kafka").option("subscribe", "purchases_topic").load()
# Perform SQL-like transformations
df.selectExpr("CAST(value AS STRING)").createOrReplaceTempView("purchases")
query = spark.sql("SELECT user_id, COUNT(*) AS purchase_count FROM purchases GROUP BY user_id")
query.writeStream.format("console").start()
Casos de uso para SQL en Streaming sobre Kafka
- Analítica en tiempo real. Monitorear actividad de usuario, ventas o datos de sensores IoT con paneles en vivo.
- Transformación de datos. Limpiar, filtrar o enriquecer datos mientras fluyen a través de los temas de Kafka.
- Detección de fraude. Identificar transacciones sospechosas o patrones en tiempo real.
- Alertas dinámicas. Disparar alertas cuando se alcanzan umbrales o condiciones específicas.
- Enriquecimiento de canalización de datos. Unir flujos con conjuntos de datos externos para crear salidas de datos enriquecidos
Beneficios de SQL en Streaming sobre Kafka
- Desarrollo simplificado. SQL es familiar para muchos desarrolladores, reduciendo la curva de aprendizaje.
- Procesamiento en tiempo real. Permite obtener ideas y acciones inmediatas sobre datos en streaming.
- Escalabilidad. Aprovechar la arquitectura distribuida de Kafka garantiza la escalabilidad.
- Integración. Se integra fácilmente con canalizaciones existentes basadas en Kafka.
Desafíos y consideraciones
- Administración del estado. Las consultas complejas pueden requerir la gestión de grandes estados, lo que podría afectar el rendimiento.
- Optimización de consultas. Asegúrese de que las consultas sean eficientes para manejar flujos de alto rendimiento.
- Selección de herramientas. Elija el motor SQL adecuado según sus requisitos (por ejemplo, latencia, complejidad).
- Tolerancia a fallos. Los motores SQL en streaming deben manejar fallos de nodos y garantizar la consistencia de los datos.
Conclusión
El streaming SQL en Kafka permite a las empresas aprovechar los datos en tiempo real con la simplicidad de SQL. Herramientas como ksqlDB, Apache Flink y Spark Structured Streaming hacen posible construir tuberías de datos robustas, escalables y de baja latencia sin necesidad de una profunda experiencia en programación.
Source:
https://dzone.com/articles/real-time-insights-with-streaming-sql-on-kafka