













In het tijdperk van real-time gegevens is de mogelijkheid om streaminginformatie te verwerken en analyseren cruciaal geworden voor bedrijven. Apache Kafka, een krachtig gedistribueerd evenementenstreamingplatform, staat vaak centraal in deze real-time pipelines. Maar werken met ruwe gegevensstromen kan complex zijn. Hier komt Streaming SQL om de hoek kijken: het stelt gebruikers in staat om Kafka-onderwerpen te query’en en te transformeren met de eenvoud van SQL.
Wat is Streaming SQL?
Streaming SQL verwijst naar de toepassing van gestructureerde query-taal (SQL) om gegevens in beweging te verwerken en analyseren. In tegenstelling tot traditionele SQL, die statische datasets in databases query’t, verwerkt streaming SQL continu gegevens terwijl deze door een systeem stroomt. Het ondersteunt operaties zoals filteren, aggregeren, joinen en windowing in real-time.
Met Kafka als de ruggengraat van real-time gegevenspipelines, stelt Streaming SQL gebruikers in staat om direct Kafka-onderwerpen te query’en, waardoor het eenvoudiger wordt om de gegevens te analyseren en actie te ondernemen zonder complexe code te schrijven.
Belangrijke componenten van Streaming SQL op Kafka
1. Apache Kafka
Kafka slaat real-time evenementen op en streamt deze via onderwerpen. Producenten schrijven gegevens naar onderwerpen, en consumenten abonneren zich om die gegevens te verwerken of te analyseren. De duurzaamheid, schaalbaarheid en fouttolerantie van Kafka maken het ideaal voor streaming gegevens.
2. Kafka Connect
Kafka Connect vergemakkelijkt de integratie met externe systemen zoals databases, objectopslagplaatsen of andere streamingplatforms. Het maakt naadloze invoer of export van gegevens naar/van Kafka-onderwerpen mogelijk.
3. Streaming SQL-engines
Verschillende tools maken Streaming SQL op Kafka mogelijk, waaronder:
- ksqlDB: Een op Kafka gebaseerde Streaming SQL-engine gebouwd op Kafka Streams.
- Apache Flink SQL: Een veelzijdig stream-verwerkingsframework met geavanceerde SQL-mogelijkheden.
- Apache Beam: Biedt SQL voor batch- en stream-verwerking, compatibel met verschillende runners.
- Spark Structured Streaming: Ondersteunt SQL voor real-time en batch-gegevensverwerking.
Hoe werkt Streaming SQL?
Streaming SQL -engines verbinden met Kafka om gegevens uit onderwerpen te lezen, deze in realtime te verwerken en resultaten naar andere onderwerpen, databases of externe systemen uit te voeren. Het proces omvat doorgaans de volgende stappen:
- Datastreams definiëren: Gebruikers definiëren streams of tabellen door Kafka-onderwerpen als bronnen te specificeren.
- Queries uitvoeren: SQL-query’s worden uitgevoerd om bewerkingen zoals filteren, aggregatie en het samenvoegen van streams uit te voeren.
- Resultaten weergeven: De resultaten kunnen worden teruggestuurd naar Kafka-onderwerpen of externe bestemmingen zoals databases of dashboards.
Stroomdiagram
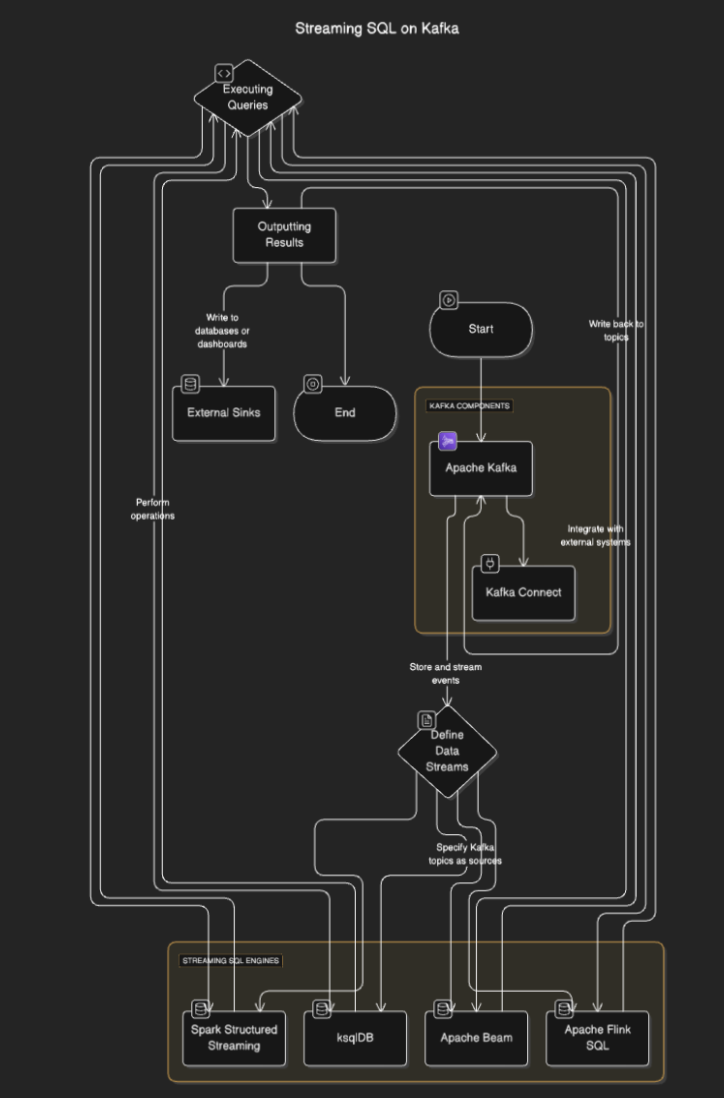
Streaming SQL-tools voor Kafka
ksqlDB
ksqlDB is speciaal gebouwd voor Kafka en biedt een SQL-interface om Kafka-onderwerpen te verwerken. Het vereenvoudigt operaties zoals het filteren van berichten, het samenvoegen van streams en het aggregeren van gegevens. Belangrijke functies zijn onder andere:
- Declaratieve SQL-query’s: Definieer real-time transformaties zonder codering.
- Gematerialiseerde weergaven: Bewaar queryresultaten voor snelle opzoekingen.
- Kafka-Native: Geoptimaliseerd voor verwerking met lage latentie.
Voorbeeld:
CREATE STREAM purchases (
user_id VARCHAR,
item_id VARCHAR,
amount DECIMAL
) WITH (
KAFKA_TOPIC='purchases_topic',
VALUE_FORMAT='JSON'
);
CREATE STREAM high_value_purchases AS
SELECT *
FROM purchases
WHERE amount > 100;
Apache Flink SQL
Apache Flink is een krachtig stream-verwerkingsframework dat SQL-mogelijkheden biedt voor zowel batch- als streaminggegevens. Het ondersteunt complexe bewerkingen zoals gebeurtenistijdsverwerking en geavanceerde venstering.
Voorbeeld:
CREATE TABLE purchases (
user_id STRING,
amount DECIMAL,
purchase_time TIMESTAMP(3),
WATERMARK FOR purchase_time AS purchase_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'purchases_topic',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json',
'scan.startup.mode' = 'earliest-offset'
);
SELECT user_id, COUNT(*) AS purchase_count
FROM purchases
GROUP BY user_id;
Apache Spark Structured Streaming
Spark Structured Streaming maakt SQL-gebaseerde streamverwerking mogelijk en integreert goed met andere Spark-componenten. Het is ideaal voor complexe datapipelines die batch- en streamverwerking combineren.
Voorbeeld:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("StreamingSQL").getOrCreate()
# Read Kafka topic as a stream
df = spark.readStream.format("kafka").option("subscribe", "purchases_topic").load()
# Perform SQL-like transformations
df.selectExpr("CAST(value AS STRING)").createOrReplaceTempView("purchases")
query = spark.sql("SELECT user_id, COUNT(*) AS purchase_count FROM purchases GROUP BY user_id")
query.writeStream.format("console").start()
Gebruiksscenario’s voor Streaming SQL op Kafka
- Real-time analytics. Monitor gebruikersactiviteiten, verkoop of IoT-sensordata met live dashboards.
- Data-transformatie. Reinig, filter of verrijk gegevens terwijl ze door Kafka-onderwerpen stromen.
- Fraudedetectie. Identificeer verdachte transacties of patronen in realtime.
- Dynamische waarschuwingen. Activeer waarschuwingen wanneer specifieke drempels of voorwaarden worden bereikt.
- Data-pijplijnverrijking. Combineer streams met externe datasets om verrijkte gegevensoutputs te creëren
Voordelen van Streaming SQL op Kafka
- Vereenvoudigde ontwikkeling. SQL is bekend bij veel ontwikkelaars, wat de leercurve vermindert.
- Real-time verwerking. Maakt onmiddellijke inzichten en acties op streaming data mogelijk.
- Schaalbaarheid. Door gebruik te maken van de gedistribueerde architectuur van Kafka wordt schaalbaarheid gegarandeerd.
- Integratie. Integreert eenvoudig met bestaande op Kafka gebaseerde pipelines.
Uitdagingen en Overwegingen
- State management. Complexe queries kunnen het beheer van grote states vereisen, wat de prestaties kan beïnvloeden.
- Query-optimalisatie. Zorg ervoor dat queries efficiënt zijn om hoge doorvoerstreams aan te kunnen.
- Toolselectie. Kies de juiste SQL-engine op basis van uw vereisten (bijv. latentie, complexiteit).
- Fouttolerantie. Streaming SQL-engines moeten knooppuntfouten afhandelen en gegevensconsistentie waarborgen.
Conclusie
Streaming SQL op Kafka stelt bedrijven in staat om real-time data te benutten met de eenvoud van SQL. Tools zoals ksqlDB, Apache Flink en Spark Structured Streaming maken het mogelijk om robuuste, schaalbare en weinig-latente datapipelines te bouwen zonder diepgaande programmeerkennis.
Source:
https://dzone.com/articles/real-time-insights-with-streaming-sql-on-kafka