













في عصر البيانات الحية، أصبحت القدرة على معالجة وتحليل المعلومات التي تتدفق بشكل مستمر أمرًا حيويًا للشركات. يكون Apache Kafka، منصة تدفق الحدث الموزعة القوية، في قلب هذه الأنابيب الزمنية الحية في كثير من الأحيان. ولكن العمل مع تيارات البيانات الخام يمكن أن يكون معقدًا. هنا تأتي Streaming SQL: حيث يسمح للمستخدمين باستعلام وتحويل مواضيع Kafka ببساطة SQL.
ما هو Streaming SQL؟
تشير Streaming SQL إلى تطبيق لغة الاستعلام المهيكلة (SQL) لمعالجة وتحليل البيانات أثناء التحرك. على عكس SQL التقليدي، الذي يستعلم عن مجموعات بيانات ثابتة في قواعد البيانات، يعالج Streaming SQL بشكل مستمر البيانات أثناء تدفقها من خلال النظام. يدعم العمليات مثل التصفية والتجميع والانضمام والنوافذ بشكل فوري.مع Kafka كعمود فقري لأنابيب البيانات الحية، يسمح Streaming SQL للمستخدمين باستعلام مواضيع Kafka مباشرة، مما يجعل من السهل تحليل البيانات والتصرف فيها دون كتابة رموز معقدة.
مكونات Streaming SQL على Kafka الرئيسية
1. Apache Kafka
تخزن Kafka وتبث الأحداث في الوقت الحقيقي من خلال المواضيع. يكتب المنتجون البيانات في المواضيع، ويشترك المستهلكون لمعالجة أو تحليل تلك البيانات. دوامة Kafka وقابليتها للتوسيع ومقاومتها للأخطاء تجعلها مثالية لبيانات التدفق.
2. Kafka Connect
يسهل Kafka Connect التكامل مع الأنظمة الخارجية مثل قواعد البيانات ومتاجر الأشياء أو منصات البث الحي الأخرى. يمكنه تمكين استيعاب أو تصدير سلس للبيانات إلى/من مواضيع Kafka.
3. محركات بيانات SQL للبث الحي
عدة أدوات تمكن من بيانات SQL للبث الحي على Kafka، بما في ذلك:
- ksqlDB: محرك بيانات SQL للبث الحي مبني على Kafka Streams.
- Apache Flink SQL: إطار عمل لمعالجة البيانات الجارية متعدد الاستخدامات مع إمكانيات SQL المتقدمة.
- Apache Beam: يوفر SQL لمعالجة الدُفعات والبث الحي، متوافق مع عدة مشغلات.
- Spark Structured Streaming: يدعم SQL لمعالجة البيانات في الوقت الحقيقي ودُفعة واحدة.
كيف يعمل بيانات SQL للبث الحي؟
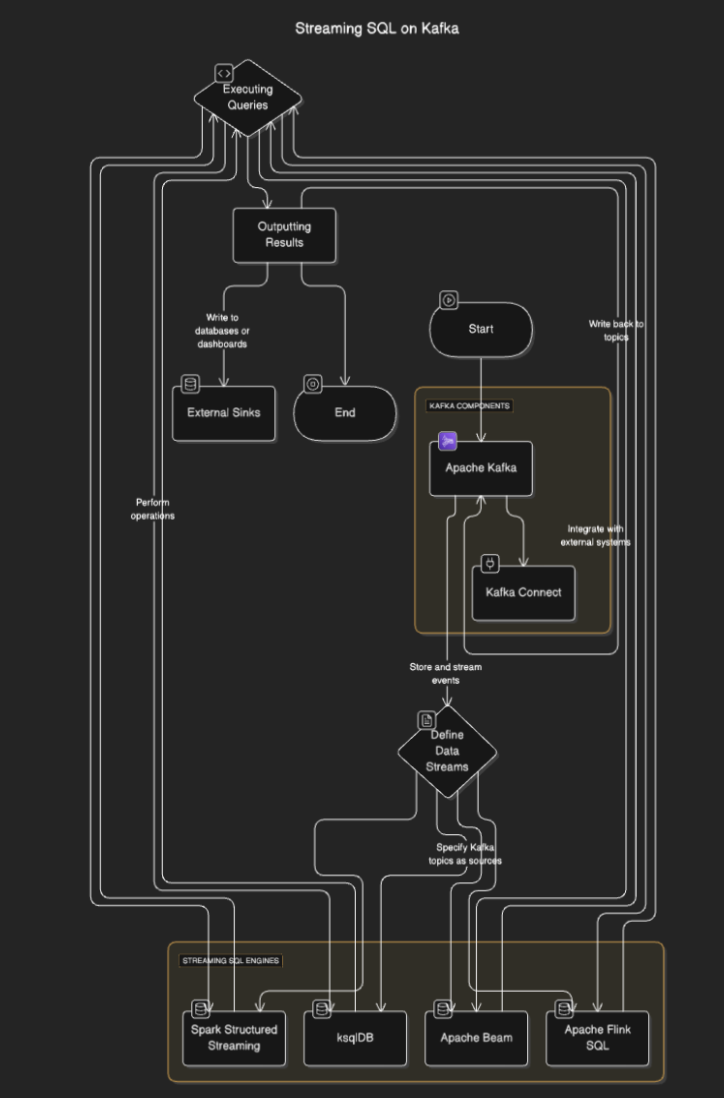
محركات بيانات SQL تتصل بـ Kafka لقراءة البيانات من المواضيع، معالجتها في الوقت الحقيقي، وإخراج النتائج إلى مواضيع أخرى أو قواعد بيانات أو أنظمة خارجية. يتضمن العملية عادة الخطوات التالية:
- تحديد تدفقات البيانات: يقوم المستخدمون بتحديد تدفقات البيانات أو الجداول عن طريق تحديد مواضيع Kafka كمصادر.
- تنفيذ الاستعلامات: يتم تنفيذ استعلامات SQL لأداء عمليات مثل التصفية والتجميع والانضمام بين التدفقات.
- إخراج النتائج: يمكن كتابة النتائج إلى مواضيع Kafka أو وجهات خارجية مثل قواعد البيانات أو لوحات المعلومات.
مخطط السير
أدوات SQL التي تدعم البث المباشر لـ Kafka
ksqlDB
ksqlDB مصمم خصيصًا لـ Kafka ويوفر واجهة SQL لمعالجة مواضيع Kafka. يبسط العمليات مثل تصفية الرسائل والانضمام بين التيارات وتجميع البيانات. تشمل الميزات الرئيسية:
- استعلامات SQL تصريحية: تعريف تحويلات الوقت الحقيقي بدون برمجة.
- عروض البيانات الموادية: الاحتفاظ بنتائج الاستعلام للبحث السريع.
- Kafka-Native: محسّنة لمعالجة منخفضة التأخر.
مثال:
CREATE STREAM purchases (
user_id VARCHAR,
item_id VARCHAR,
amount DECIMAL
) WITH (
KAFKA_TOPIC='purchases_topic',
VALUE_FORMAT='JSON'
);
CREATE STREAM high_value_purchases AS
SELECT *
FROM purchases
WHERE amount > 100;
Apache Flink SQL
Apache Flink هو إطار عمل قوي لمعالجة التيارات يوفر قدرات SQL لكل من البيانات التي تجمع دفعة والبيانات المباشرة. يدعم عمليات معقدة مثل معالجة الوقت للحدث والنوافذ المتقدمة.
مثال:
CREATE TABLE purchases (
user_id STRING,
amount DECIMAL,
purchase_time TIMESTAMP(3),
WATERMARK FOR purchase_time AS purchase_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'purchases_topic',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json',
'scan.startup.mode' = 'earliest-offset'
);
SELECT user_id, COUNT(*) AS purchase_count
FROM purchases
GROUP BY user_id;
Apache Spark Structured Streaming
التدفق المنظم بواسطة سبارك يمكنه معالجة تيارات البيانات بناءً على SQL ويتكامل بشكل جيد مع مكونات سبارك الأخرى. إنه مثالي لأنابيب البيانات المعقدة التي تجمع بين المعالجة الدفعية والتدفقية.
مثال:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("StreamingSQL").getOrCreate()
# Read Kafka topic as a stream
df = spark.readStream.format("kafka").option("subscribe", "purchases_topic").load()
# Perform SQL-like transformations
df.selectExpr("CAST(value AS STRING)").createOrReplaceTempView("purchases")
query = spark.sql("SELECT user_id, COUNT(*) AS purchase_count FROM purchases GROUP BY user_id")
query.writeStream.format("console").start()
حالات الاستخدام لـ SQL التدفقي على كافكا
- تحليل الوقت الحقيقي. رصد نشاط المستخدمين، المبيعات، أو بيانات أجهزة الاستشعار IoT مع لوحات تحكم حية.
- تحويل البيانات. تنقية، تصفية، أو إثراء البيانات أثناء تدفقها عبر مواضيع كافكا.
- كشف الاحتيال. التعرف على المعاملات المشبوهة أو الأنماط في الوقت الحقيقي.
- تنبيهات ديناميكية. تشغيل تنبيهات عند تحقيق عتبات أو شروط محددة.
- إثراء أنابيب البيانات. الانضمام بين التيارات مع مجموعات بيانات خارجية لإنشاء مخرجات بيانات مثرية
فوائد SQL التدفقي على كافكا
- تطوير مبسط. SQL مألوف لدى العديد من المطورين، مما يقلل من منحنى التعلم.
- معالجة الوقت الحقيقي. يمكن فورًا الحصول على رؤى واتخاذ إجراءات على البيانات التدفقية.
- التوسعية. استغلال الهندسة المعمارية الموزعة لكافكا يضمن التوسعية.
- التكامل. يتكامل بسهولة مع أنابيب كافكا الحالية.
التحديات والاعتبارات
- إدارة الحالة. قد تتطلب الاستعلامات المعقدة إدارة حالات كبيرة، مما قد يؤثر على الأداء.
- تحسين الاستعلام. تأكد من أن الاستعلامات فعالة للتعامل مع تيارات عالية.
- اختيار الأداة. اختر محرك SQL المناسب استنادًا إلى متطلباتك (على سبيل المثال، التأخر، القدرة).
- مقاومة الأعطال. يجب على محركات SQL للتيارات التعامل مع فشل العقدة وضمان توافق البيانات.
الاستنتاج
يمكن لـ Streaming SQL على Kafka أن يمنح الشركات قدرة استيعاب البيانات في الوقت الحقيقي ببساطة SQL. تجعل الأدوات مثل ksqlDB وApache Flink وSpark Structured Streaming من الممكن بناء خطوط أنابيب بيانات قوية وقابلة للتطوير وذات منخفض التأخر دون الحاجة إلى خبرة عميقة في البرمجة.
Source:
https://dzone.com/articles/real-time-insights-with-streaming-sql-on-kafka