













リアルタイムデータの時代において、ストリーミング情報を処理および分析する能力は企業にとって重要となっています。強力な分散イベントストリーミングプラットフォームであるApache Kafkaは、これらのリアルタイムパイプラインの中心にしばしば位置しています。しかし、生のデータストリームを扱うことは複雑な場合があります。そこで、Streaming SQLが登場します。これにより、ユーザーはSQLの単純さでKafkaトピックをクエリおよび変換することができます。
Streaming SQLとは何ですか?
Streaming SQLは、動的なデータを処理および分析するために構造化クエリ言語(SQL)を適用することを指します。従来のSQLは、データベース内の静的データセットをクエリしますが、Streaming SQLはデータがシステムを流れる際に連続的に処理します。リアルタイムでのフィルタリング、集計、結合、ウィンドウ処理などの操作をサポートします。カフカがリアルタイムデータパイプラインのバックボーンとして機能する中、Streaming SQLはユーザーが直接Kafkaトピックをクエリできるようにし、複雑なコードを書かずにデータを分析および処理することを容易にします。
カフカ上のStreaming SQLの主要構成要素
1. Apache Kafka
カフカはトピックを介してリアルタイムイベントを保存およびストリーミングします。プロデューサーはデータをトピックに書き込み、コンシューマーはそのデータを処理または分析するために購読します。カフカの耐久性、拡張性、耐障害性はストリーミングデータに最適です。
2. Kafka Connect
Kafka Connectは、データベース、オブジェクトストア、その他のストリーミングプラットフォームなどの外部システムとの統合を容易にします。これにより、データをKafkaトピックへの取り込みやエクスポートがシームレスに可能になります。
3. ストリーミングSQLエンジン
複数のツールがKafka上でのストリーミングSQLを可能にしています。その中には次のものがあります:
- ksqlDB:Kafka Streams上に構築されたKafkaネイティブのストリーミングSQLエンジン。
- Apache Flink SQL:高度なSQL機能を備えた多機能なストリーム処理フレームワーク。
- Apache Beam:さまざまなランナーと互換性のあるバッチおよびストリーム処理のためのSQLを提供。
- Spark Structured Streaming:リアルタイムおよびバッチデータ処理のためのSQLをサポート。
ストリーミングSQLの仕組み
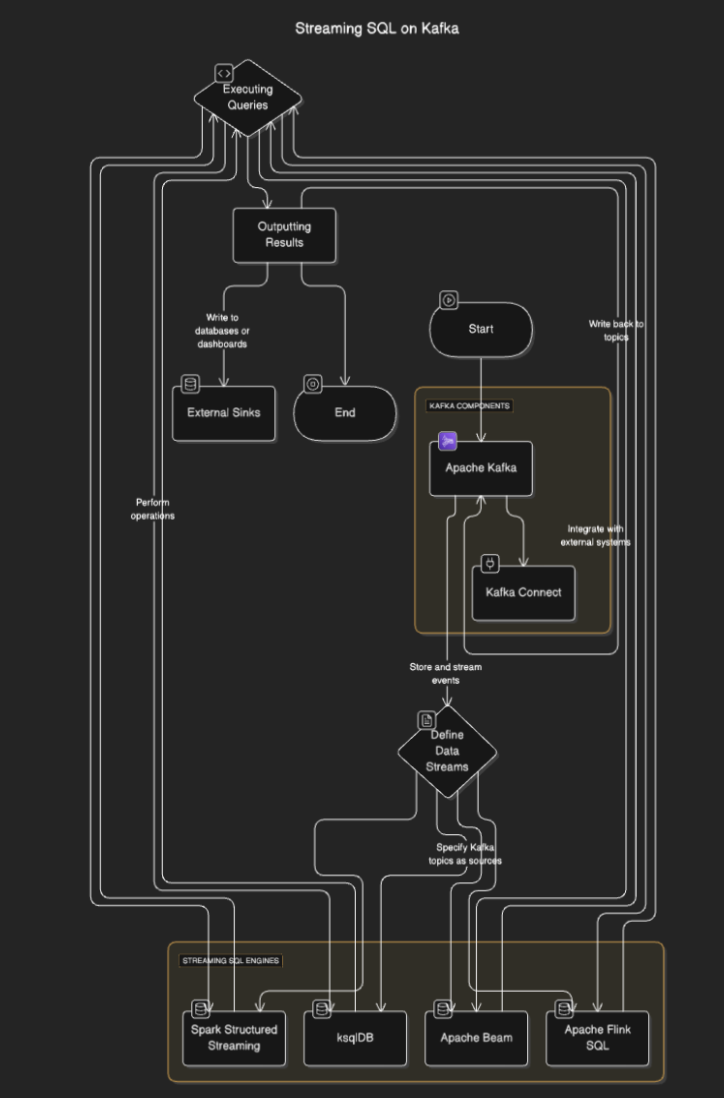
ストリーミングSQL エンジンは、トピックからデータを読み取り、リアルタイムで処理し、結果を他のトピック、データベース、または外部システムに出力するためにKafkaに接続します。このプロセスには通常、次のステップが含まれています:
- データストリームの定義:ユーザーはKafkaトピックをソースとして指定することで、ストリームやテーブルを定義します。
- クエリの実行:クエリを実行して、フィルタリング、集計、ストリームの結合などの操作を実行します。
- 結果の出力: 結果はKafkaトピックやデータベース、ダッシュボードなどの外部シンクに書き戻すことができます。
フローダイアグラム
Kafka向けストリーミングSQLツール
ksqlDB
ksqlDB はKafka向けに特化しており、Kafkaトピックを処理するためのSQLインターフェースを提供します。メッセージのフィルタリング、ストリームの結合、データの集計などの操作を簡略化します。主な機能には次のものがあります:
- 宣言型SQLクエリ: コーディングなしでリアルタイム変換を定義します。
- マテリアライズドビュー: クエリ結果を永続化して高速なルックアップを実現します。
- Kafkaネイティブ: 低レイテンシ処理に最適化されています。
例:
CREATE STREAM purchases (
user_id VARCHAR,
item_id VARCHAR,
amount DECIMAL
) WITH (
KAFKA_TOPIC='purchases_topic',
VALUE_FORMAT='JSON'
);
CREATE STREAM high_value_purchases AS
SELECT *
FROM purchases
WHERE amount > 100;
Apache Flink SQL
Apache Flink はバッチデータとストリーミングデータの両方に対するSQL機能を提供する強力なストリーム処理フレームワークです。イベント時間処理や高度なウィンドウ処理などの複雑な操作をサポートしています。
例:
CREATE TABLE purchases (
user_id STRING,
amount DECIMAL,
purchase_time TIMESTAMP(3),
WATERMARK FOR purchase_time AS purchase_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'purchases_topic',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json',
'scan.startup.mode' = 'earliest-offset'
);
SELECT user_id, COUNT(*) AS purchase_count
FROM purchases
GROUP BY user_id;
Apache Spark Structured Streaming
Spark Structured Streamingは、SQLベースのストリーム処理を可能にし、他のSparkコンポーネントともうまく統合されます。バッチ処理とストリーム処理を組み合わせた複雑なデータパイプラインに最適です。
例:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("StreamingSQL").getOrCreate()
# Read Kafka topic as a stream
df = spark.readStream.format("kafka").option("subscribe", "purchases_topic").load()
# Perform SQL-like transformations
df.selectExpr("CAST(value AS STRING)").createOrReplaceTempView("purchases")
query = spark.sql("SELECT user_id, COUNT(*) AS purchase_count FROM purchases GROUP BY user_id")
query.writeStream.format("console").start()
KafkaにおけるストリーミングSQLのユースケース
- リアルタイム分析。ユーザーの活動、販売、またはIoTセンサーデータをライブダッシュボードで監視します。
- データ変換。Kafkaトピックを通過するデータをクレンジング、フィルタリング、または強化します。
- 詐欺検出。リアルタイムで疑わしい取引やパターンを特定します。
- 動的アラート。特定の閾値や条件が満たされたときにアラートをトリガーします。
- データパイプラインの強化。外部データセットとストリームを結合して強化されたデータ出力を作成します
KafkaにおけるストリーミングSQLの利点
- 開発の簡素化。SQLは多くの開発者にとって馴染みがあり、学習曲線を減少させます。
- リアルタイム処理。ストリーミングデータに対して即座の洞察とアクションを可能にします。
- スケーラビリティ。Kafkaの分散アーキテクチャを活用することで、スケーラビリティが保証されます。
- 統合。既存のKafkaベースのパイプラインと簡単に統合できます。
課題と考慮事項
- ステート管理。複雑なクエリには大規模なステートの管理が必要で、パフォーマンスに影響を及ぼす可能性があります。
- クエリの最適化。高スループットのストリームを処理するために、クエリが効率的であることを確認します。
- ツールの選択。要件(レイテンシ、複雑さなど)に基づいて適切なSQLエンジンを選択します。
- 障害耐性。ストリーミングSQLエンジンはノードの障害に対応し、データの整合性を確保する必要があります。
結論
Kafka上のストリーミングSQLは、SQLのシンプルさでリアルタイムデータを活用するビジネスに力を与えます。ksqlDB、Apache Flink、Spark Structured Streamingなどのツールを使用することで、プログラミングの専門知識がなくても堅牢でスケーラブルで低レイテンシのデータパイプラインを構築することが可能です。
Source:
https://dzone.com/articles/real-time-insights-with-streaming-sql-on-kafka