













在即時數據的時代,處理和分析流式信息的能力對企業來說變得至關重要。Apache Kafka,作為一個強大的分佈式事件流平台,經常是這些即時管道的核心。然而,處理原始數據流可能會很複雜。這就是流式 SQL 出現的地方:它允許用戶用 SQL 的簡單性來查詢和轉換 Kafka 主題。
什麼是流式 SQL?
流式 SQL 是指應用 結構化查詢語言 (SQL) 來處理和分析運動中的數據。與傳統的 SQL 不同,後者查詢數據庫中的靜態數據集,流式 SQL 持續處理隨著系統流動的數據。它支持過濾、聚合、連接和窗口等即時操作。
以 Kafka 作為即時數據管道的骨幹,流式 SQL 允許用戶直接查詢 Kafka 主題,使得分析和處理數據變得更加簡單,而無需編寫複雜的代碼。
Kafka 上流式 SQL 的關鍵組件
1. Apache Kafka
Kafka 通過主題存儲和流式傳輸即時事件。生產者將數據寫入主題,消費者訂閱以處理或分析該數據。Kafka 的耐用性、可擴展性和容錯性使其成為流式數據的理想選擇。
2. Kafka Connect
Kafka Connect 有助於與外部系統(如數據庫、對象存儲或其他流式平台)進行集成。它使數據無縫地進行到 Kafka 主題中的摄取或導出。
3. 流式 SQL 引擎
多個工具支持在 Kafka 上進行流式 SQL,包括:
- ksqlDB:基於 Kafka Streams 構建的 Kafka 原生流式 SQL 引擎。
- Apache Flink SQL:功能強大的流處理框架,具有高級 SQL 功能。
- Apache Beam:提供批處理和流處理的 SQL,與各種運行器兼容。
- Spark Structured Streaming:支持實時和批處理的 SQL 數據處理。
流式 SQL 如何工作?
流式 SQL 引擎連接到 Kafka,從主題中讀取數據,實時處理數據,並將結果輸出到其他主題、數據庫或外部系統。該過程通常包括以下步驟:
- 定義數據流:用戶通過指定 Kafka 主題作為來源來定義流或表。
- 執行查詢:執行 SQL 查詢以執行過濾、聚合和連接流等操作。
- 輸出結果: 結果可以寫回Kafka主題或外部接收器,如數據庫或儀表板。
流程圖
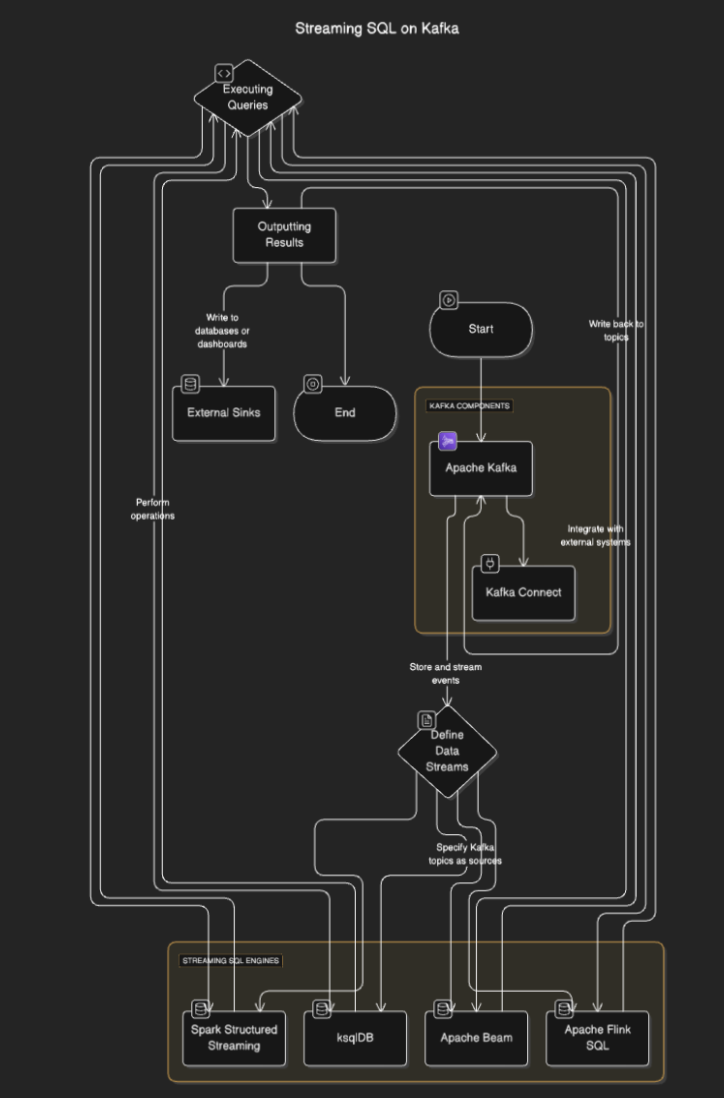
Kafka的流式SQL工具
ksqlDB
ksqlDB 是為Kafka而設計的,提供了一個SQL接口來處理Kafka主題。它簡化了操作,如篩選消息、連接流和聚合數據。主要功能包括:
- 聲明式SQL查詢: 定義實時轉換而無需編碼。
- 物化視圖: 對於快速查找保留查詢結果。
- Kafka原生: 適用於低延遲處理。
範例:
CREATE STREAM purchases (
user_id VARCHAR,
item_id VARCHAR,
amount DECIMAL
) WITH (
KAFKA_TOPIC='purchases_topic',
VALUE_FORMAT='JSON'
);
CREATE STREAM high_value_purchases AS
SELECT *
FROM purchases
WHERE amount > 100;
Apache Flink SQL
Apache Flink 是一個強大的流式處理框架,為批處理和流式數據提供了SQL功能。它支持諸如事件時間處理和高級窗口操作等複雜操作。
範例:
CREATE TABLE purchases (
user_id STRING,
amount DECIMAL,
purchase_time TIMESTAMP(3),
WATERMARK FOR purchase_time AS purchase_time - INTERVAL '5' SECOND
) WITH (
'connector' = 'kafka',
'topic' = 'purchases_topic',
'properties.bootstrap.servers' = 'localhost:9092',
'format' = 'json',
'scan.startup.mode' = 'earliest-offset'
);
SELECT user_id, COUNT(*) AS purchase_count
FROM purchases
GROUP BY user_id;
Apache Spark結構化流
Spark結構化流處理使基於SQL的流處理成為可能,並與其他Spark組件完美集成。它非常適合複雜的數據管道,結合了批處理和流處理。
示例:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("StreamingSQL").getOrCreate()
# Read Kafka topic as a stream
df = spark.readStream.format("kafka").option("subscribe", "purchases_topic").load()
# Perform SQL-like transformations
df.selectExpr("CAST(value AS STRING)").createOrReplaceTempView("purchases")
query = spark.sql("SELECT user_id, COUNT(*) AS purchase_count FROM purchases GROUP BY user_id")
query.writeStream.format("console").start()
在Kafka上使用流式SQL的用例
- 實時分析。監控用戶活動、銷售數據或IoT傳感器數據,並在實時儀表板上查看。
- 數據轉換。在數據通過Kafka主題時對其進行清理、過濾或豐富處理。
- 欺詐檢測。實時識別可疑交易或模式。
- 動態警報。當滿足特定閾值或條件時觸發警報。
- 數據管道豐富化。將流與外部數據集合併,創建豐富的數據輸出。
在Kafka上流式SQL的優勢
- 開發簡化。對許多開發人員來說,SQL是熟悉的,降低了學習曲線。
- 實時處理。使即時洞察和對流式數據的操作成為可能。
- 可擴展性。利用Kafka的分佈式架構確保可擴展性。
- 集成。輕鬆集成現有基於Kafka的管道。
挑戰和注意事項
- 狀態管理。複雜的查詢可能需要管理大量的狀態,這可能會影響性能。
- 查詢優化。確保查詢能夠有效處理高吞吐量數據流。
- 工具選擇。根據您的需求選擇適合的SQL引擎(例如延遲、複雜性)。
- 容錯容忍。流式SQL引擎必須處理節點故障並確保數據一致性。
結論
在Kafka上的流式SQL使企業能夠利用SQL的簡單性來利用實時數據。像ksqlDB、Apache Flink和Spark Structured Streaming這樣的工具使構建強大、可擴展和低延遲的數據管道成為可能,而無需深入的編程專業知識。
Source:
https://dzone.com/articles/real-time-insights-with-streaming-sql-on-kafka