













Эффективная обработка данных является ключевым фактором для компаний и организаций, которые используют анализ больших данных для принятия информированных решений. Одним из ключевых факторов, который значительно влияет на перформанс обработки данных, является формат хранения данных. В этой статье исследуется влияние различных форматов хранения данных, в частности Parquet, Avro и ORC на производительность запросов и затраты в среде больших данных на платформе Google Cloud Platform (GCP). Статья предоставляет бенчмарки, discuss cost implications, и предлагает рекомендации по выбору соответствующего формата на основании специфических использований.
Введение в ФорматыStorage в Big Data
Форматы хранения данных являются основой любой среды обработки больших данных. Они определяют, как данные хранятся, читаются и записываются, непосредственно влияя на эффективность хранения, производительность запросов и скорость извлечения данных. В экосистеме больших данных колонковые форматы, такие как Parquet и ORC, и строковые форматы, такие как Avro, широко используются благодаря их оптимизированной производительности для определенных типов запросов и обработки задач.
- Parquet: Parquet является колонковым форматом хранения, оптимизированным для операций считывания и анализа. Он очень эффективен в плане сжатия и кодирования, делая его идеальным для сценариев, где приоритетом является производительность считывания и эффективность хранения.
- Avro: Avro является строковым форматом хранения, предназначенным для деSerialization данных. Его известен своими возможностями расширения схемы и часто используется для операций с большим объемом записей, когда данные требуется быстро десериализовать и ресериализовать.
- ORC (Оптимизированная Рядковая Колонка): ORC — это формат колонковой хранения, похожий на Parquet, но оптимизированный как для операций чтения, так и для записи. ORC очень эффективен в плане сжатия, что позволяет уменьшить затраты на хранение и ускорить обращение к данным.
Цель исследования
Главной целью этого исследования является оценка влияния различных форматов хранения (Parquet, Avro, ORC) на производительность и стоимость запросов в области больших данных. Статья нацелена на предоставление бенчмарков на основе различных типов запросов и объёмов данных, чтобы помочь специалистам по данным и архитекторам выбрать наиболее подходящий формат для их конкретных случаев использования.
Экспериментальная установка
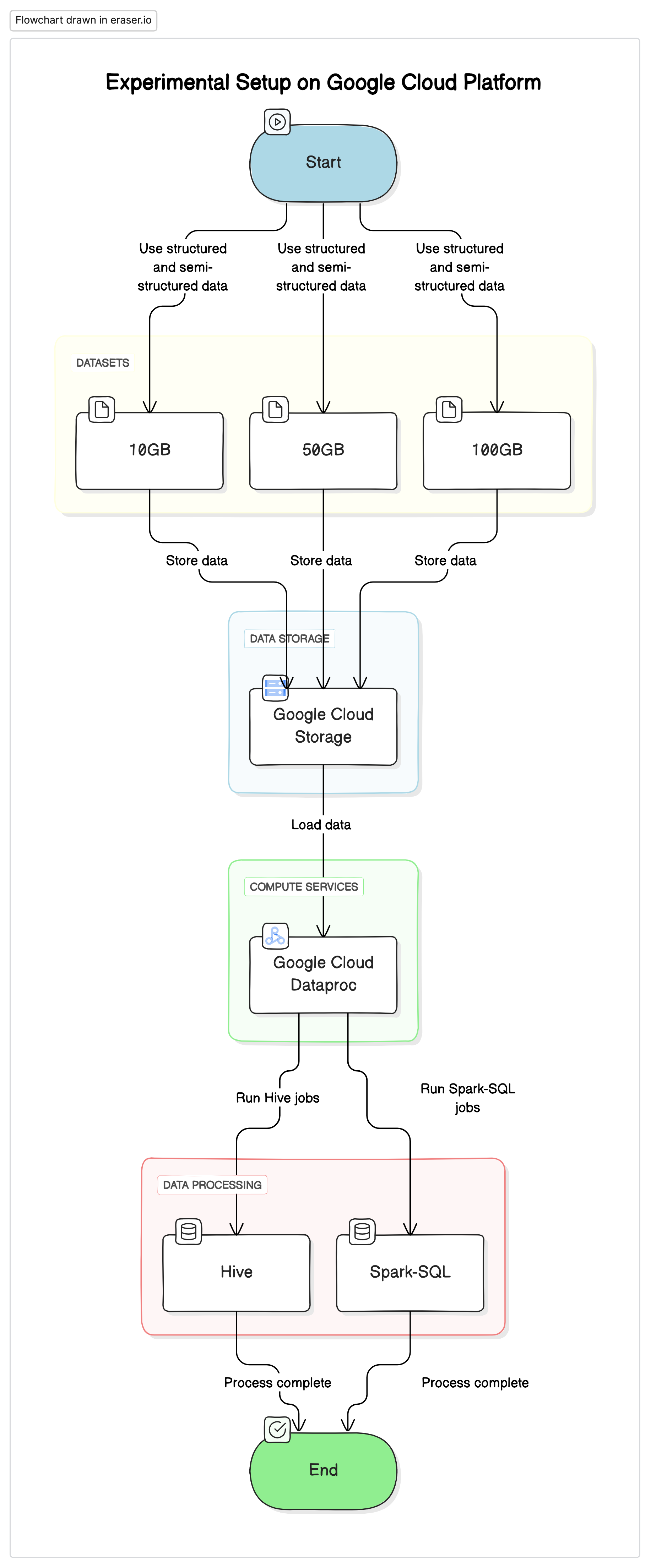
Для проведения исследования мы использовали стандартизированную установку на Google Cloud Platform (GCP) с Google Cloud Storage в качестве хранилища данных и Google Cloud Dataproc для выполнения задач Hive и Spark-SQL. Данные, использованные в экспериментах, представляли собой смесь структурированных и полуструктурированных наборов данных, имитирующих реальные сценарии.
Основные компоненты
- Google Cloud Storage: Использовался для хранения наборов данных в различных форматах (Parquet, Avro, ORC)
- Google Cloud Dataproc: Управляемая услуга Apache Hadoop и Apache Spark, использовавшаяся для запуска задач Hive и Spark-SQL.
- Наборы данных: Три набора данных различных размеров (10ГБ, 50ГБ, 100ГБ) с смешанными типами данных.
# Initialize PySpark and set up Google Cloud Storage as file system
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("BigDataQueryPerformance") \
.config("spark.jars.packages", "com.google.cloud.bigdataoss:gcs-connector:hadoop3-2.2.5") \
.getOrCreate()
# Configure the access to Google Cloud Storage
spark.conf.set("fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem")
spark.conf.set("fs.gs.auth.service.account.enable", "true")
spark.conf.set("google.cloud.auth.service.account.json.keyfile", "/path/to/your-service-account-file.json")
Тестовые запросы
- Простые SELECT запросы: Базовая выборка всех столбцов из таблицы
- Фильтровые запросы: Запросы SELECT сCLAUSE WHERE для фильтрации определённых строк
- Агрегированные запросы: Запросы с использованием GROUP BY и агрегирующих функций, таких как SUM, AVG и т. д..
- Связанные запросы: Запросы, объединяющие две или более таблиц на общей ключевой поле
Результаты и анализ
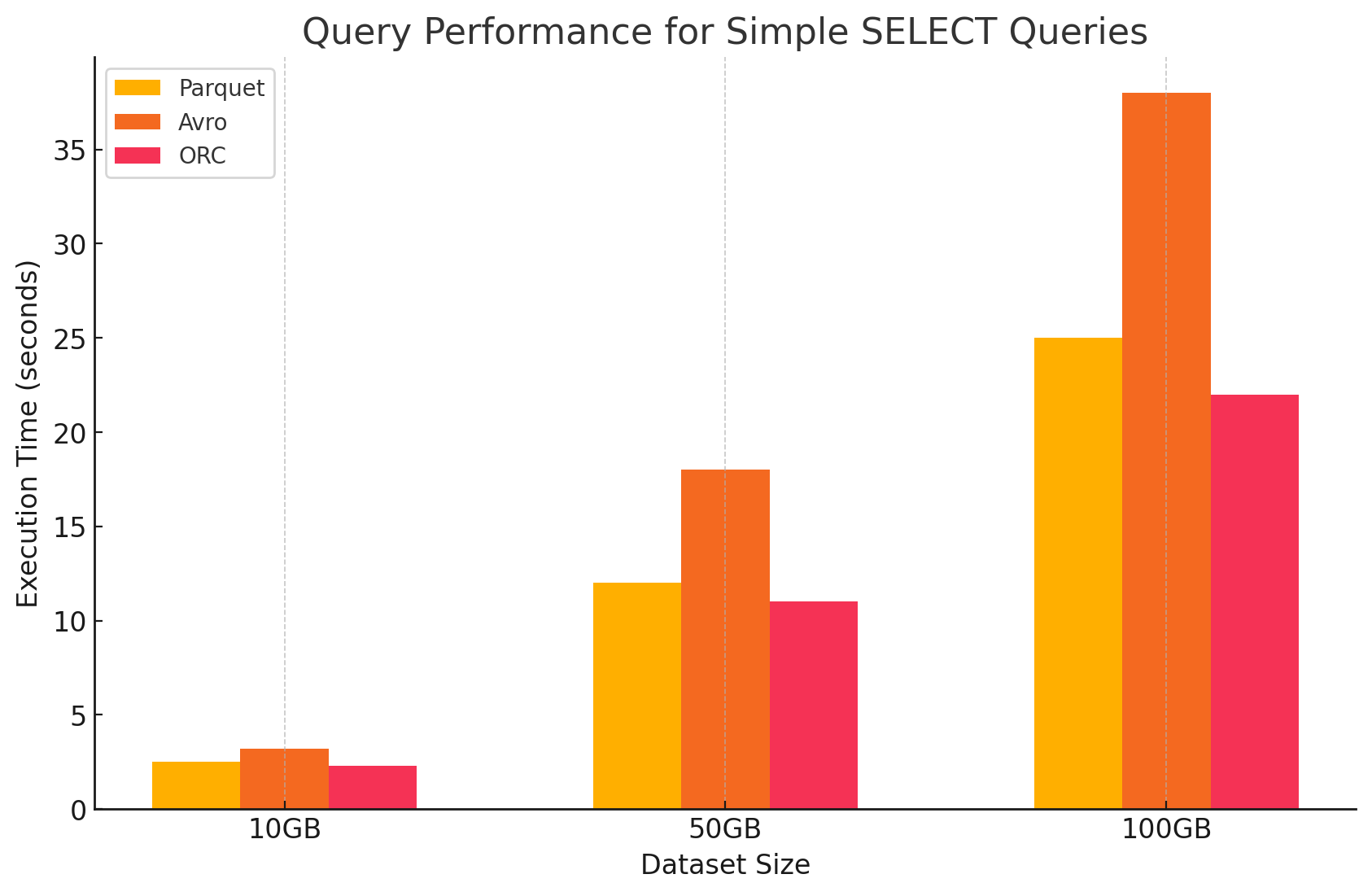
1. Простые SELECT запросы
- Parquet: Он сделал это особенно хорошо благодаря своему формату Storage columnar, который позволял быстро просматривать определенные колонки. Файлы Parquet сильно сжаты, что сокращает объем данных, считанных с диска, что приводит к более быстрому выполнению запросов.
# Simple SELECT query on Parquet file
parquet_df.select("column1", "column2").show()
- Avro: Avro показал среднюю Performanced. Будучи format based на строках, Avro требует прочитать всю строку, даже когда нужны только определенные колонки. Это увеличивает операции I/O, приводящие к более медленному выполнению запросов по сравнению с Parquet и ORC.
-- Simple SELECT query on Avro file in Hive
CREATE EXTERNAL TABLE avro_table
STORED AS AVRO
LOCATION 'gs://your-bucket/dataset.avro';
SELECT column1, column2 FROM avro_table;
- ORC: ORC показал схожее по performanced с Parquet, слегка лучшее сжатие и оптимизированные техники Storage, которые улучшают скорость чтения. Файлы ORC также columnar, делая их подходящими для SELECT запросов, которые выполняют только определенные колонки.
# Simple SELECT query on ORC file
orc_df.select("column1", "column2").show()
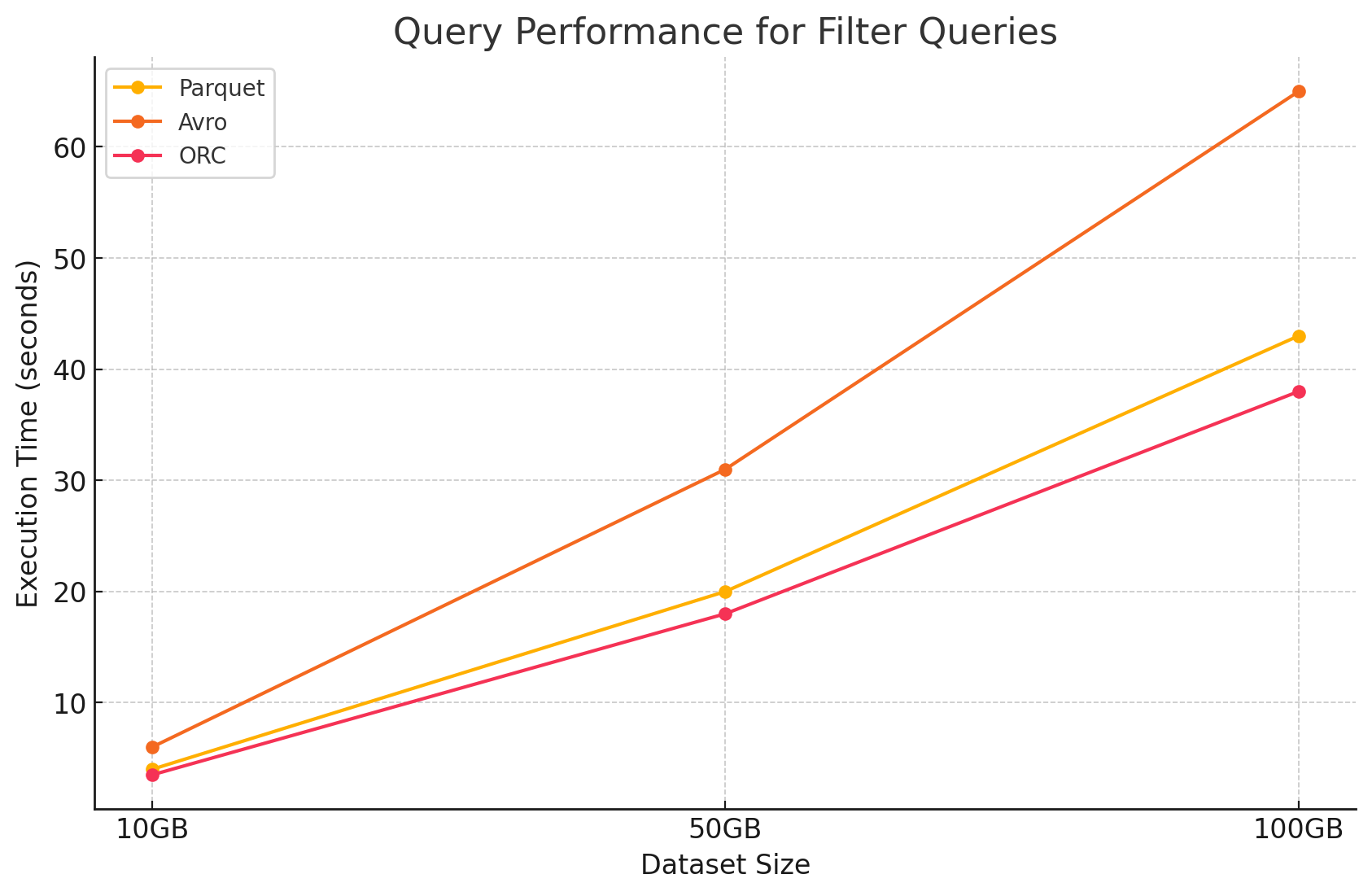
2. Фильтровые запросы
- Parquet: Parquet сохранил свои по performanced преимущества благодаря своей nature columnar и способности быстро пропустить неpertinentные колонки. Однако, Performanced был слегка поврежден необходимостью просмотреть больше строк для применения фильтров.
# Filter query on Parquet file
filtered_parquet_df = parquet_df.filter(parquet_df.column1 == 'some_value')
filtered_parquet_df.show()
- Авро:Показатели производительности снизились в связи с необходимостью прочитывания целых строк и применения фильтров по всем колонкам, что увеличило процесsing time.
-- Filter query on Avro file in Hive
SELECT * FROM avro_table WHERE column1 = 'some_value';
- ОРК:Это оказалось немного лучше, чем Паракет, в запросах с фильтрацией благодаря своей опциональной утилите сжатия, которая позволяет осуществлять фильтрацию на уровне хранения до загрузки данных в память.
# Filter query on ORC file
filtered_orc_df = orc_df.filter(orc_df.column1 == 'some_value')
filtered_orc_df.show()
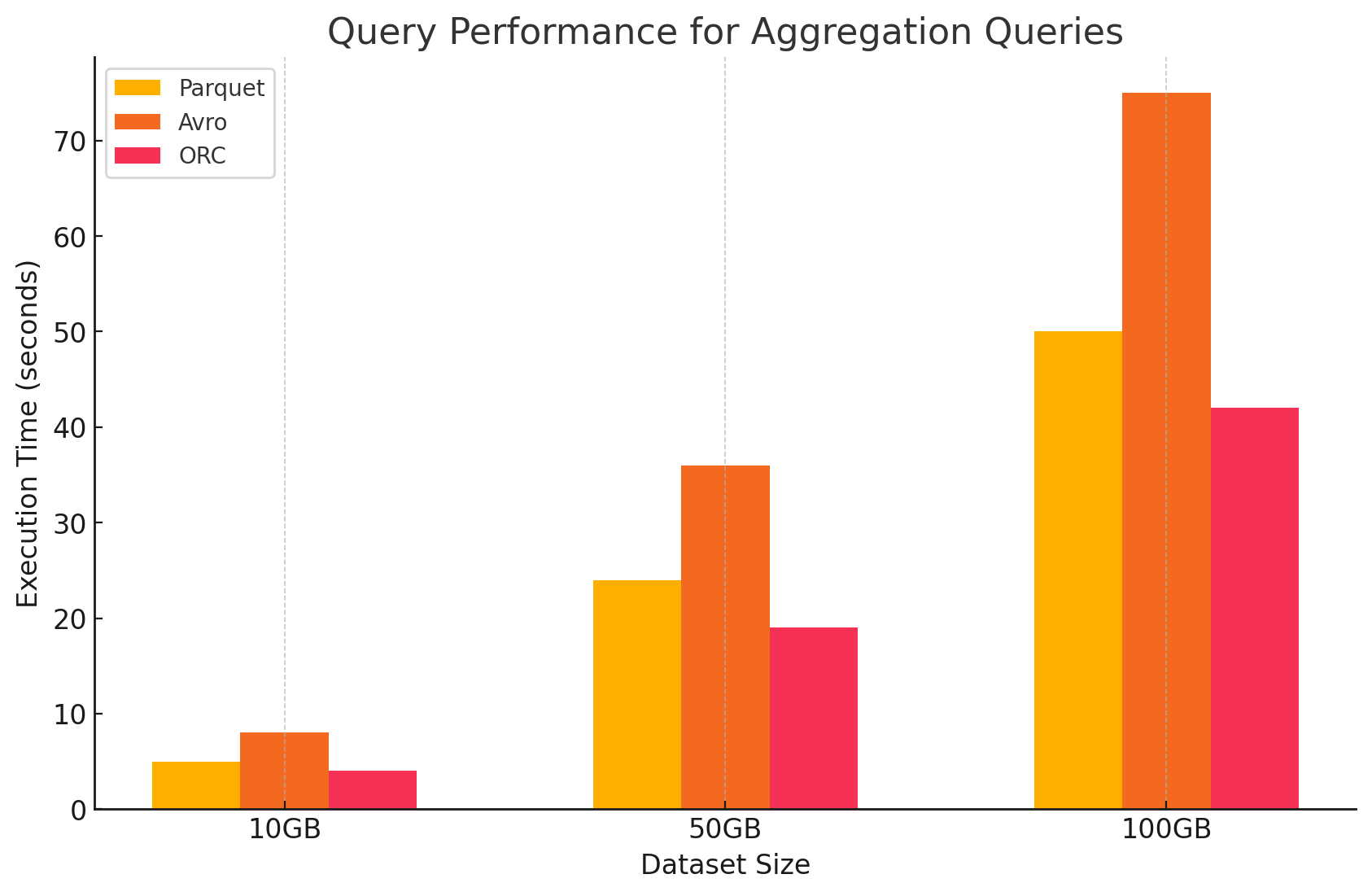
3. Запросы агрегирования
- Паракет:Паракет справился с задачей хорошо, но несколько менее эффективно, чем ОРК.Columnar формат ускоряет операции агрегирования, быстро находясь доступ к необходимым колонкам, но Паракет недостает некоторых встроенных оптимизаций, которые предлагает ОРК.
# Aggregation query on Parquet file
agg_parquet_df = parquet_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_parquet_df.show()
- Авро:Авро проигрывал за счет своего строго row-based хранения, которое требовало просмотра и обработки всех колонок для каждой строки, увеличивая накладные расходы на вычисления.
-- Aggregation query on Avro file in Hive
SELECT column1, SUM(column2), AVG(column3) FROM avro_table GROUP BY column1;
- ОРК:ОРК превосходил Паракет и Авро в запросах агрегирования. Avanced индексация и встроенные алгоритмы сжатия данных ускоряют доступ к данным и уменьшают I / O операции, делая его идеальным для задач агрегирования.
# Aggregation query on ORC file
agg_orc_df = orc_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_orc_df.show()
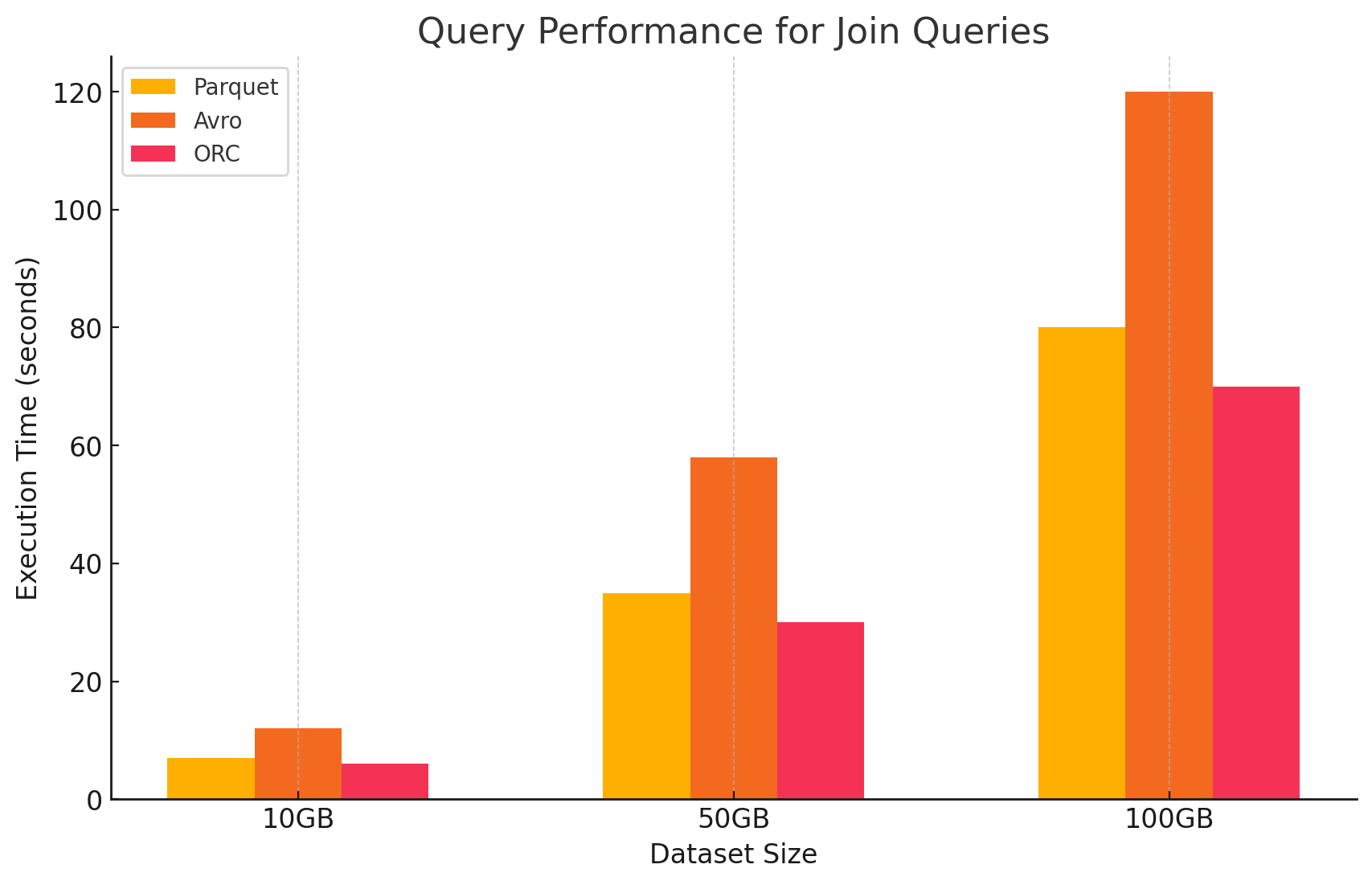
4. Join Queries
- Паракет:Паракет справился с задачей хорошо, но не aussi эффективно, чем ОРК в операциях join из-за своей менее оптимизированной обработки данных для join условий.
# Join query between Parquet and ORC files
joined_df = parquet_df.join(orc_df, parquet_df.key == orc_df.key)
joined_df.show()
- ОРК:ОРК превосходил в операциях join, использовав avanced индексацию и функции вычисления predicate pushdown, которые минимизировали просмотренные и обработанные данные во время операций join.
# Join query between two ORC files
joined_orc_df = orc_df.join(other_orc_df, orc_df.key == other_orc_df.key)
joined_orc_df.show()
- Авро: Авро сильно страдал от операций слияния, главным образом из-за высокой нагрузки при чтении полных строк и отсутствия оптимизаций по столбцам для ключей слияния.
-- Join query between Parquet and Avro files in Hive
SELECT a.column1, b.column2
FROM parquet_table a
JOIN avro_table b
ON a.key = b.key;
Влияние формата хранения на затраты
1. Эффективность и стоимость хранения
- Параquet и ORC (столбцовые форматы)
- Компрессия и стоимость хранения:Параquet и ORC являются столбцовыми форматами хранения, которые предлагают высокие отношения компрессии, особенно для наборов данных с множеством повторяющихся или схожих значений внутри колонок. Эта высокая компрессия уменьшает общую tail size, что, в свою очередь, снижает затраты на хранение, особенно в облачных средах, где стоимость хранения определяется по GB.
- Оптимально для аналитических нагрузок:В связи с их столбцовой природой, эти форматы идеальны для аналитических нагрузок, когда часто выполняются запросы по конкретным колонкам. Это意味着 меньше данных читается из хранения, уменьшая тем самым операции I/O и связанные с них затраты.
- Авро (строковый формат)
- Стоимость сжатия и хранения: Avro, как правило, обеспечивает нижее соотношение сжатия, чем колоночные форматы, такие как Parquet и ORC, поскольку данные он сохраняет строкой за строкой. Это может привести к более высоким затратам на хранение, особенно для больших наборов данных с множеством колонок, поскольку все данные в строке должны быть прочитаны, даже если нужны только несколько колонок.
- Лучше подходит для задач с интенсивной записью: 尽管Avro可能由于较低的压缩率而导致更高的存储成本,但它更适合处理大量连续写入或追加数据的工作负载。与存储相关的成本可能会通过提高数据序列化和反序列化的效率来抵消。
2. Performace and Cost of Data Processing
- Параquet и ORC (столбцовые форматы)
- Уменьшенные затраты на обработку:Эти форматы оптимизированы для операций с чтением, что делает их очень эффективными для работы с крупными наборами данных. Благодаря тому, что они позволяют прочитать только необходимые для запроса колонки, они уменьшают объем обрабатываемых данных. Это приводит к снижению использования CPU и ускорению выполнения запросов, что может значительно снизить вычислительные расходы в облачной среде, где ресурсы для вычислений вырабатываются на основе использования.
- Расширенные функции для оптимизации затрат:Особенно ORC включает такие функции, как сдвиг условия и встроенные статистики, которые позволяют ядру запроса пропустить чтение ненеобходимых данных. Это дополнительно уменьшает операции I/O и ускоряет производительность запросов, оптимизируя затраты.
- Avro (форматы на основе строк)
- Более высокие затраты на обработку: Поскольку Avro является строковым форматом, для чтения целых строк, даже если нужны только несколько столбцов, обычно требуется больше операций ввода-вывода. Это может привести к увеличению вычислительных затрат из-за большего использования процессора и увеличения времени выполнения запросов, особенно в средах с высокой нагрузкой на чтение.
- Эффективен для потоковой передачи и сериализации: Несмотря на более высокие затраты на обработку запросов, Avro хорошо подходит для задач потоковой передачи и сериализации, где более важны высокая скорость записи и эволюция схем.
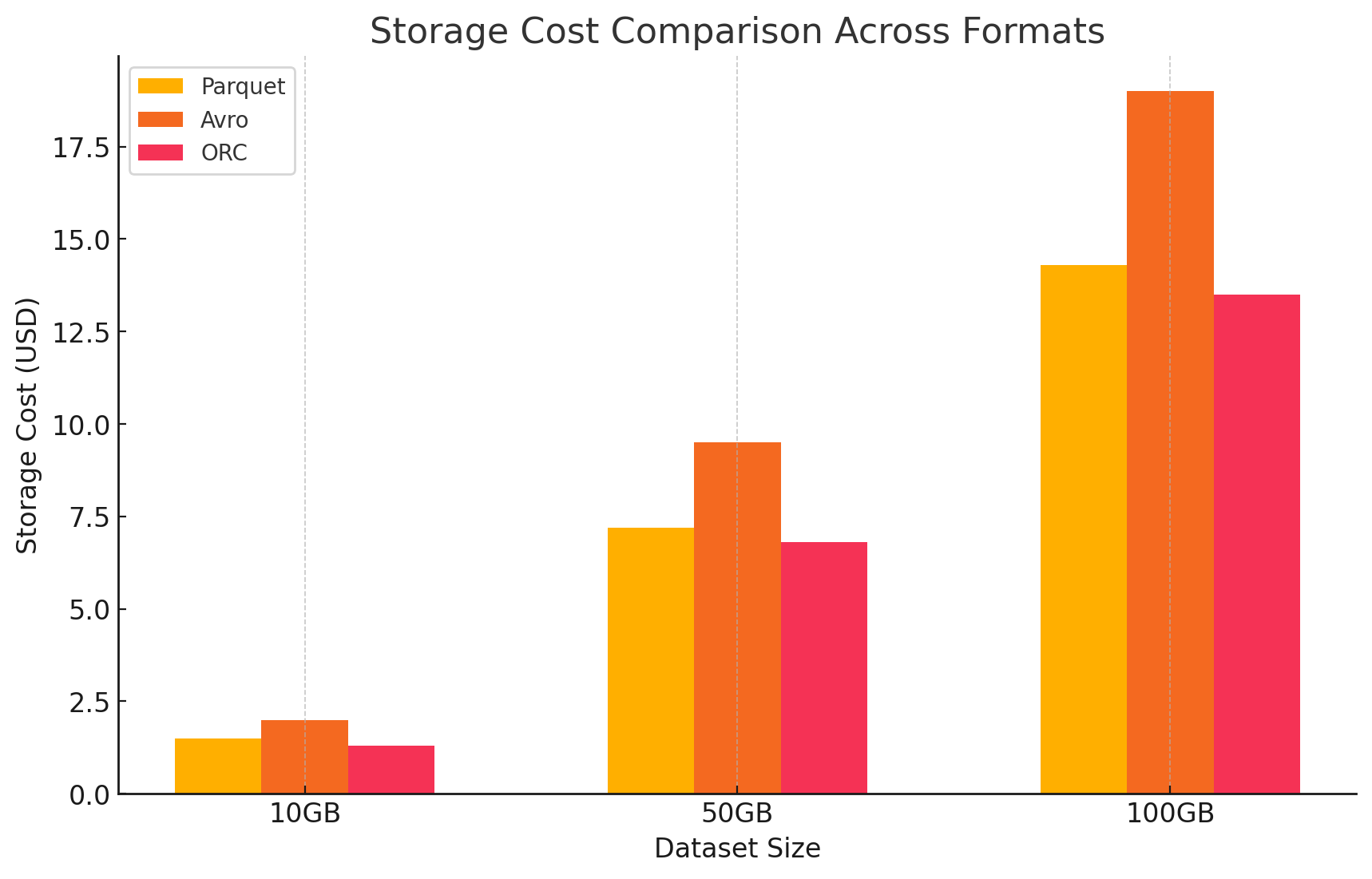
3. Анализ затрат с детализацией цен
- Для количественной оценки влияния затрат каждого формата хранения мы провели эксперимент с использованием GCP. Мы рассчитали затраты, связанные как с хранением данных, так и с их обработкой для каждого формата, основываясь на моделях ценообразования GCP.
- Стоимость хранения Google Cloud
- Стоимость хранения: Это вычисляется на основании объема данных, хранящихся в каждом формате. GCP взимает плату за GB в месяц за данные, хранящиеся в Google Cloud Storage. Оптимальные соотношения сжатия, достигаемые каждым форматом, непосредственно влияют на эти затраты.COLUMNAR форматы, такие как Parquet и ORC, обычно имеют лучшие отношения сжатия, чем строковые форматы, такие как Avro, что приводит к снижению стоимости хранения.
- Вот пример того, как определялась стоимость хранения:
- Parquet: Высокая компрессия привела к уменьшению размера данных, что по降低了стоимость хранения
- ORC: Подобно Parquet, усовершенствованная компрессия ORC также эффективно снижает стоимость хранения
- Avro: Низкая эффективность сжатия привела к более высокой стоимости хранения по сравнению с Parquet и ORC
# Example of how to save data back to Google Cloud Storage in different formats
# Save DataFrame as Parque
parquet_df.write.parquet("gs://your-bucket/output_parquet")
# Save DataFrame as Avro
avro_df.write.format("avro").save("gs://your-bucket/output_avro")
# Save DataFrame as ORC
orc_df.write.orc("gs://your-bucket/output_orc")
- Стоимость обработки данных
- Стоимость обработки данных была вычислена на основе ресурсов вычисления, необходимых для выполнения различных запросов с использованием Dataproc на GCP. GCP взимает плату за использование Dataproc в зависимости от размера кластера и продолжительности использования ресурсов.
- Стоимость вычислений:
- Parquet и ORC: Благодаря их эффективному колоночному хранению, эти форматы уменьшают объем данных, который читается и обрабатывается, что приводит к снижению стоимости вычислений. Быстреее выполнение запросов также способствовало экономии за счет сложных запросов с большими наборами данных.
- Avro: Avro требует больше ресурсов вычисления из-за своего строго расположенного формата строк, который увеличивает объем данных, который читается и обрабатывается. Это привело к повышению затрат, особенно для операций с большим объемом чтения.
Заключение
Выбор формата хранения в средах больших данных значительно влияет на производительность запросов и стоимость. Исследование и эксперимент, указанные выше, демонстрируют следующие ключевые точки:
- Parquet и ORC: Эти колонковые форматы обеспечивают отличное сжатие, что уменьшает стоимость хранения. Их способность эффективно читать только необходимые столбцы значительно улучшает производительность запросов и снижает стоимость обработки данных. ORC немного превосходит Parquet в некоторых типах запросов благодаря продвинутым функциям индексации и оптимизации, что делает его отличным выбором для смешенных рабочих нагрузок, требующих высокой производительности как чтения, так и записи.
- Avro: Хотя Avro не так эффективен в отношении сжатия и производительности запросов, как Parquet и ORC, он превосходит в случаях, требующих быстрых операций записи и эволюции схемы. Этот формат идеально подходит для сценариев, связанных с сериализацией данных и потоковой обработкой, где производительность записи и гибкость имеют приоритет над эффективностью чтения.
- Эффективность стоимости: В облачной среде, такой как GCP, где стоимость тесно связана с использованием хранения и вычислений, выбор правильного формата может привести к существенной экономии стоимости. Для аналитических рабочих нагрузок, которые в основном связаны с чтением, Parquet и ORC являются наиболее экономически эффективными вариантами. Для приложений, требующих быстрого_INGESTION_ данных и гибкого управления схемой, Avro является подходящим выбором, несмотря на более высокие затраты на хранение и вычисления.
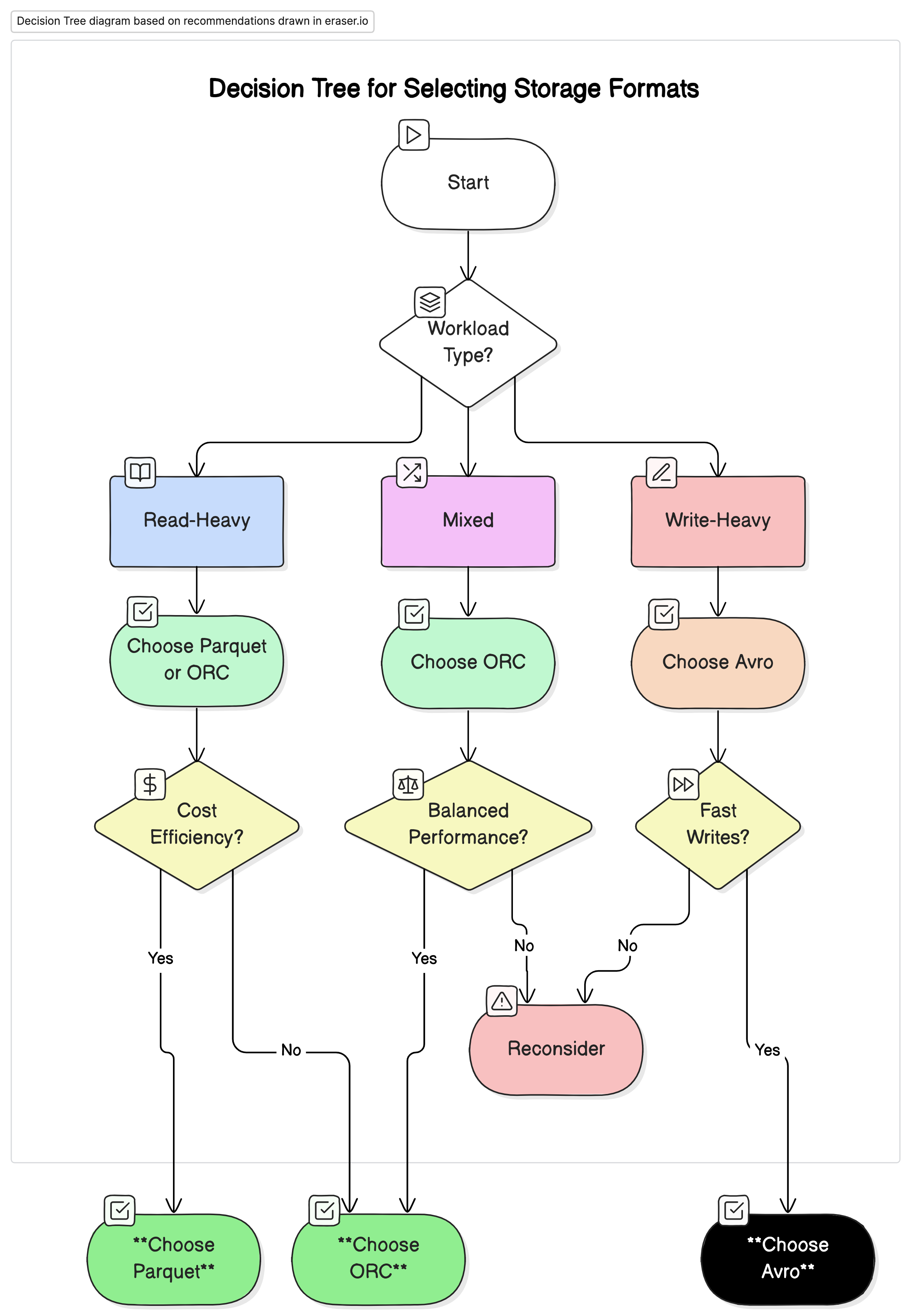
Рекомендации
На основе нашего анализа мы рекомендуем следующее:
- Для рабочих нагрузок с интенсивным чтением аналитических данных: Используйте Parquet или ORC. Эти форматы обеспечивают высокую производительность и экономичность из-за их высокой компрессии и оптимизированной производительности запросов.
- Для рабочих нагрузок с интенсивным записью и сериализацией: Используйте Avro. Он более подходит для сценариев, где важны быстрые записи и эволюция схемы, таких как потоковая обработка данных и системы обмена сообщениями.
- Для смешанных рабочих нагрузок: ORC предлагает сбалансированную производительность для операций чтения и записи, что делает его идеальным выбором для сред, где данные рабочие нагрузки различны.
Итоговые мысли
Выбор правильного формата хранения для окружений больших данных критически важен для оптимизации производительности и стоимости. Понимание сильных и слабых сторон каждого формата позволяет специалистам по данным адаптировать свою архитектуру данных к конкретным случаям использования, максимизируя эффективность и минимизируя затраты. Когда объемы данных продолжают расти, информированные решения о форматах хранения становятся все более важными для поддержания масштабируемых и экономически эффективных решений для данных.
Продуманным образом оценивая показатели производительности и стоимость, изложенные в этой статье, организации могут выбрать формат хранения, который лучше соответствует их операционным потребностям и финансовым целям.
Source:
https://dzone.com/articles/performance-and-cost-implications-parquet-avro-orc