













O processamento eficiente de dados é crucial para empresas e organizações que dependem de análise de dados em grandes quantidades para tomar decisões informadas. Um fator chave que afeta significativamente o desempenho do processamento de dados é o formato de armazenamento dos dados. Este artigo explora o impacto de diferentes formatos de armazenamento, especificamente Parquet, Avro e ORC, no desempenho de consultas e custos em ambientes de dados em granularidade na Plataforma da Google (GCP). Este artigo fornece benchmarks, discute implicações de custo e oferece recomendações sobre a seleção do formato apropriado baseado em casos de uso específicos.
Introdução a Formatos de Armazenamento em Dados em Grande Escala
Formatos de armazenamento de dados são a estrutura de suporte de qualquer ambiente de processamento de dados em grande escala. Eles definem como os dados são armazenados, lidos e escritos, impactando diretamente a eficiência de armazenamento, o desempenho de consultas e a velocidade de recuperação de dados. No ecossistema de dados em granularidade, formatos de coluna, como Parquet e ORC, e formatos de linha, como Avro, são amplamente usados devido à sua otimização para o desempenho de certos tipos de consultas e tarefas de processamento.
- Parquet: Parquet é um formato de armazenamento de colunas otimizado para operações de leitura pesada e análise. Ele é altamente eficiente em termos de compressão e codificação, tornando-se ideal para cenários onde o desempenho de leitura e a eficiência de armazenamento são priorizados.
- Avro: Avro é um formato de armazenamento de linhas projetado para serialização de dados. Ele é conhecido por suas capacidades de evolução de esquema e frequentemente usado para operações de gravação pesadas onde os dados precisam ser serializados e deserializados rapidamente.
- ORC (Optimized Row Columnar):ORC é um formato de armazenamento em colunas semelhante a Parquet, mas otimizado para ambas as operações de leitura e gravação. O ORC é altamente eficiente em termos de compressão, reduzindo o custo de armazenamento e acelerando a recuperação de dados.
Objetivo de Pesquisa
O objetivo principal desta pesquisa é avaliar como diferentes formatos de armazenamento (Parquet, Avro, ORC) afetam o desempenho de consulta e os custos em ambientes de big data. Este artigo visa fornecer benchmarks baseados em diferentes tipos de consultas e volumes de dados para ajudar engenheiros de dados e arquitetos a escolher o formato mais adequado para seus casos de uso específicos.
Configuração Experimental
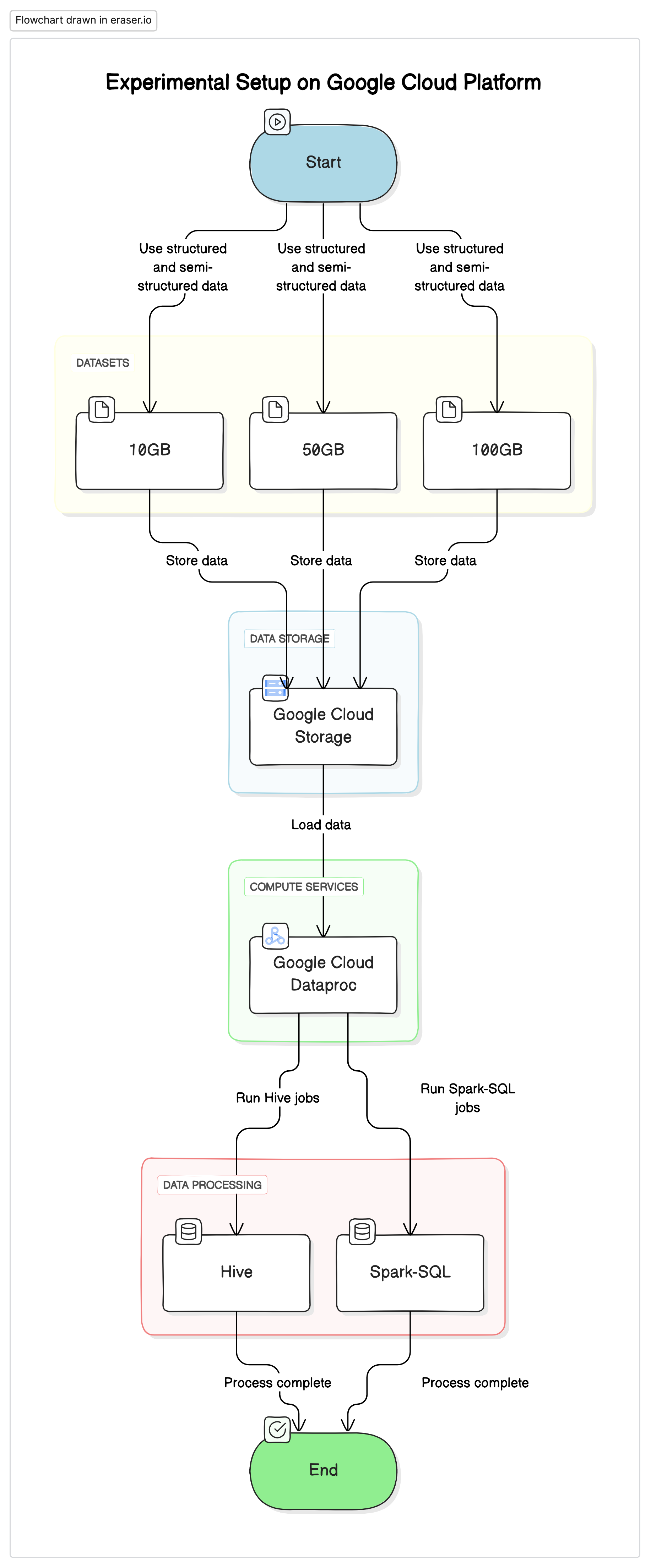
Para realizar esta pesquisa, utilizamos uma configuração padrão na Plataforma da Google Cloud (GCP) com o Google Cloud Storage como repositório de dados e o Google Cloud Dataproc para executar jobs de Hive e Spark-SQL. Os dados usados nos experimentos eram uma mistura de conjuntos de dados estruturados e semi-estruturados para simular cenários reais.
Componentes Chave
- Google Cloud Storage:Usado para armazenar os conjuntos de dados em diferentes formatos (Parquet, Avro, ORC)
- Google Cloud Dataproc:Um serviço gerenciado que implementa Apache Hadoop e Apache Spark, usado para executar jobs de Hive e Spark-SQL.
- Conjuntos de Dados:Três conjuntos de dados de tamanhos variados (10GB, 50GB, 100GB) com tipos de dados mistos.
# Initialize PySpark and set up Google Cloud Storage as file system
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("BigDataQueryPerformance") \
.config("spark.jars.packages", "com.google.cloud.bigdataoss:gcs-connector:hadoop3-2.2.5") \
.getOrCreate()
# Configure the access to Google Cloud Storage
spark.conf.set("fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem")
spark.conf.set("fs.gs.auth.service.account.enable", "true")
spark.conf.set("google.cloud.auth.service.account.json.keyfile", "/path/to/your-service-account-file.json")
Consultas de Teste
- Query simples SELECT: Retirada básica de todas as colunas de uma tabela
- Query de filtragem: Consultas SELECT com cláusulas WHERE para filtrar linhas específicas
- Query de agregação: Consultas que envolvem GROUP BY e funções de agregação como SUM, AVG, etc..
- Query de junção: Consultas que juntam duas ou mais tabelas em uma chave comum
Resultados e Análise
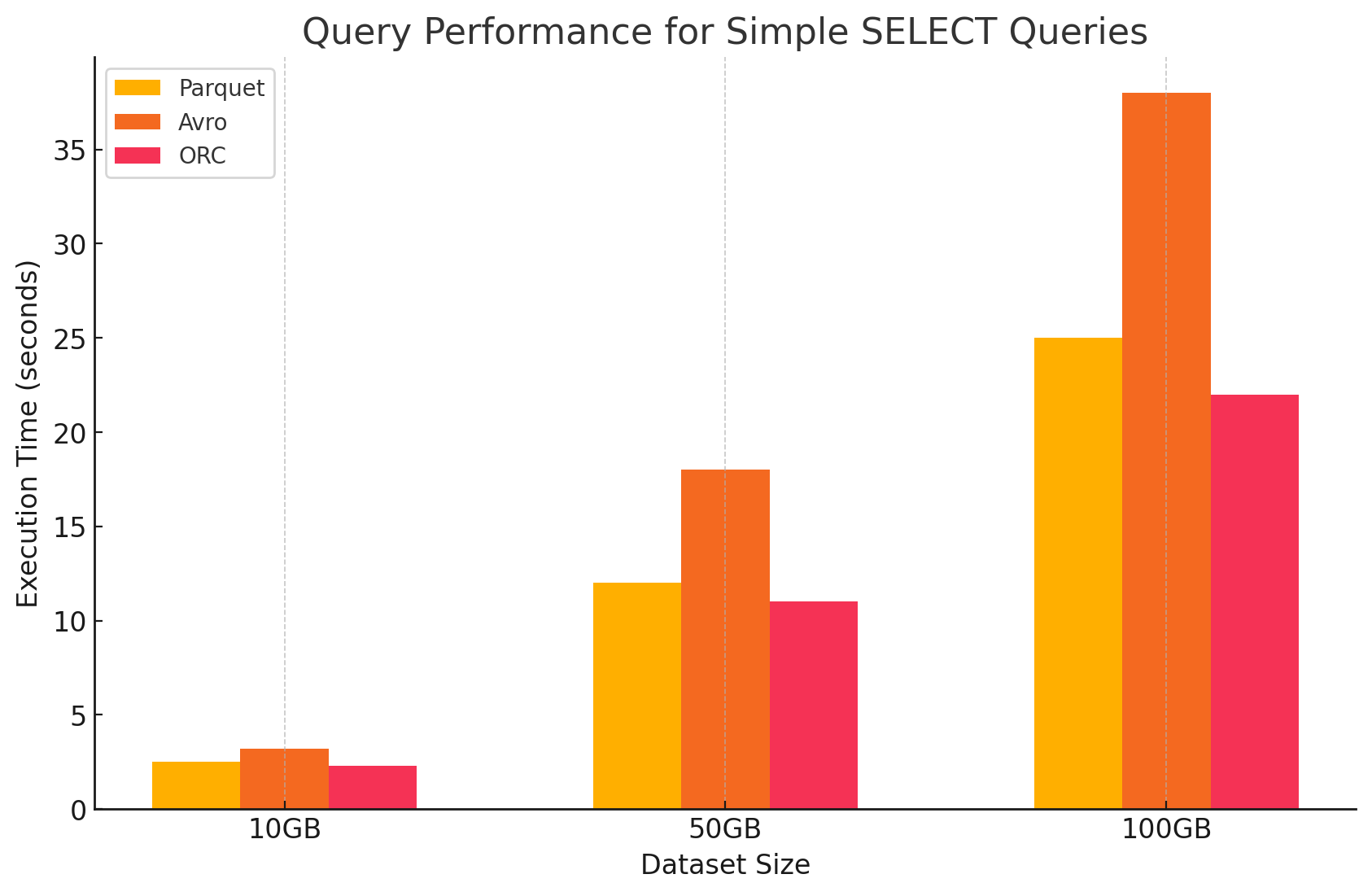
1. Query simples SELECT
- Parquet: Executou muito bem devido ao seu formato de armazenamento por colunas, que permitiu uma rápida leitura de colunas específicas. Os arquivos Parquet são altamente comprimidos, reduzindo a quantidade de dados lidos do disco, o que resultou em tempos de execução de consulta mais rápidos.
# Simple SELECT query on Parquet file
parquet_df.select("column1", "column2").show()
- Avro: O Avro executou moderadamente bem. sendo um formato baseado em linhas, o Avro exige a leitura de toda a linha, mesmo quando só são necessárias colunas específicas. Isto aumenta as operações de E/S, levando a performance de consulta mais lenta em comparação com o Parquet e ORC.
-- Simple SELECT query on Avro file in Hive
CREATE EXTERNAL TABLE avro_table
STORED AS AVRO
LOCATION 'gs://your-bucket/dataset.avro';
SELECT column1, column2 FROM avro_table;
- ORC: O ORC mostrou desempenho semelhante ao Parquet, com compressão ligeiramente melhor e técnicas de armazenamento otimizadas que melhoraram as velocidades de leitura. Os arquivos ORC também são colunares, fazendo com que eles sejam adequados para consultas SELECT que retornam apenas colunas específicas.
# Simple SELECT query on ORC file
orc_df.select("column1", "column2").show()
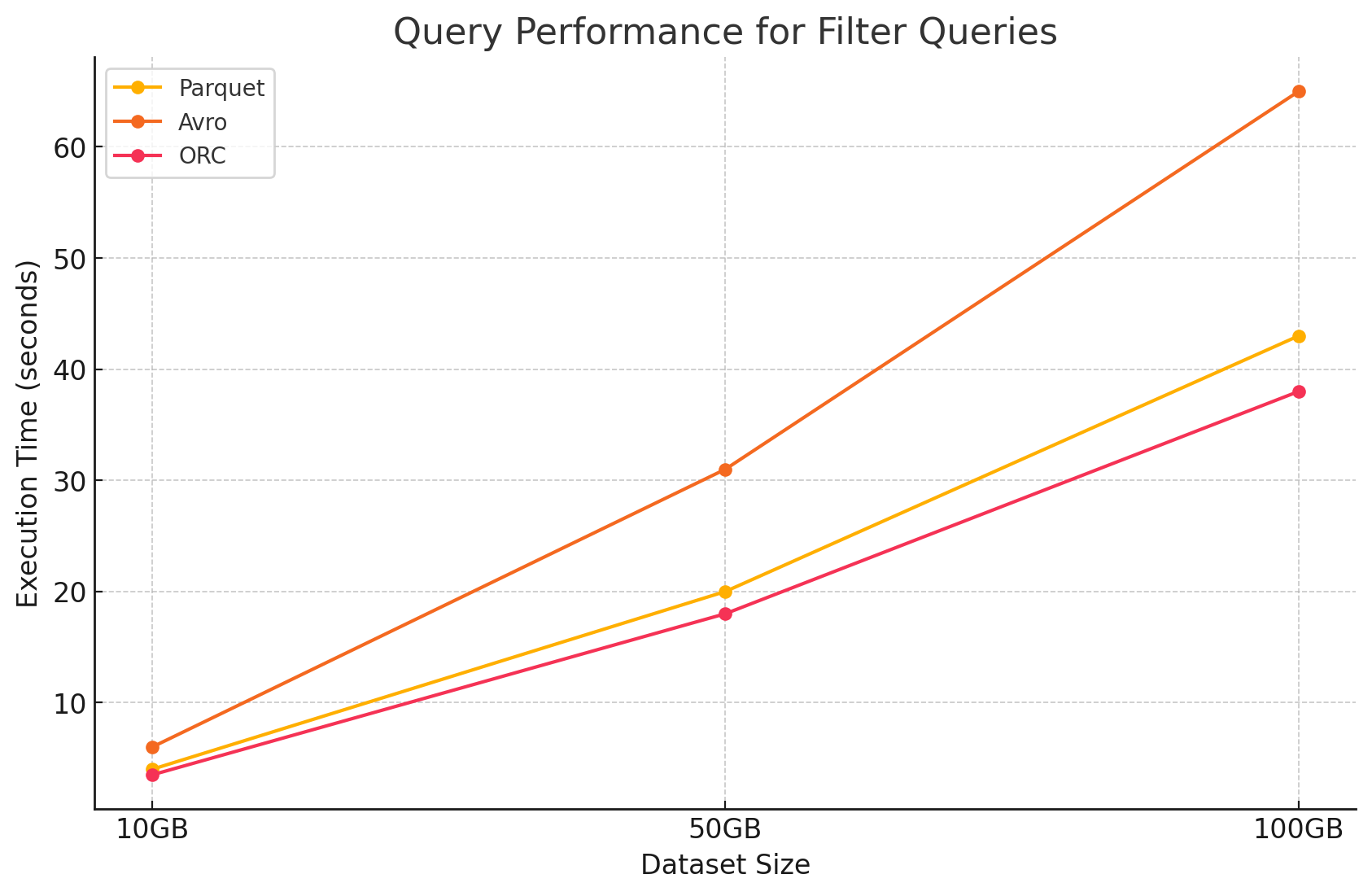
2. Query de filtragem
- Parquet: O Parquet manteve sua vantagem de desempenho devido à sua natureza de armazenamento por colunas e a habilidade de pular colunas irrelevantes rapidamente. No entanto, a performance ficou ligeiramente afetada pela necessidade de scanner mais linhas para aplicar filtros.
# Filter query on Parquet file
filtered_parquet_df = parquet_df.filter(parquet_df.column1 == 'some_value')
filtered_parquet_df.show()
- Avro:O desempenho diminuiu ainda mais devido à necessidade de ler linhas inteiras e aplicar filtros em todas as colunas, aumentando o tempo de processamento.
-- Filter query on Avro file in Hive
SELECT * FROM avro_table WHERE column1 = 'some_value';
- ORC:Este superou o Parquet ligeiramente em consultas de filtro devido à sua funcionalidade de pushdown de predicado, que permite o filtragem diretamente no nível de armazenamento antes que os dados sejam carregados na memória.
# Filter query on ORC file
filtered_orc_df = orc_df.filter(orc_df.column1 == 'some_value')
filtered_orc_df.show()
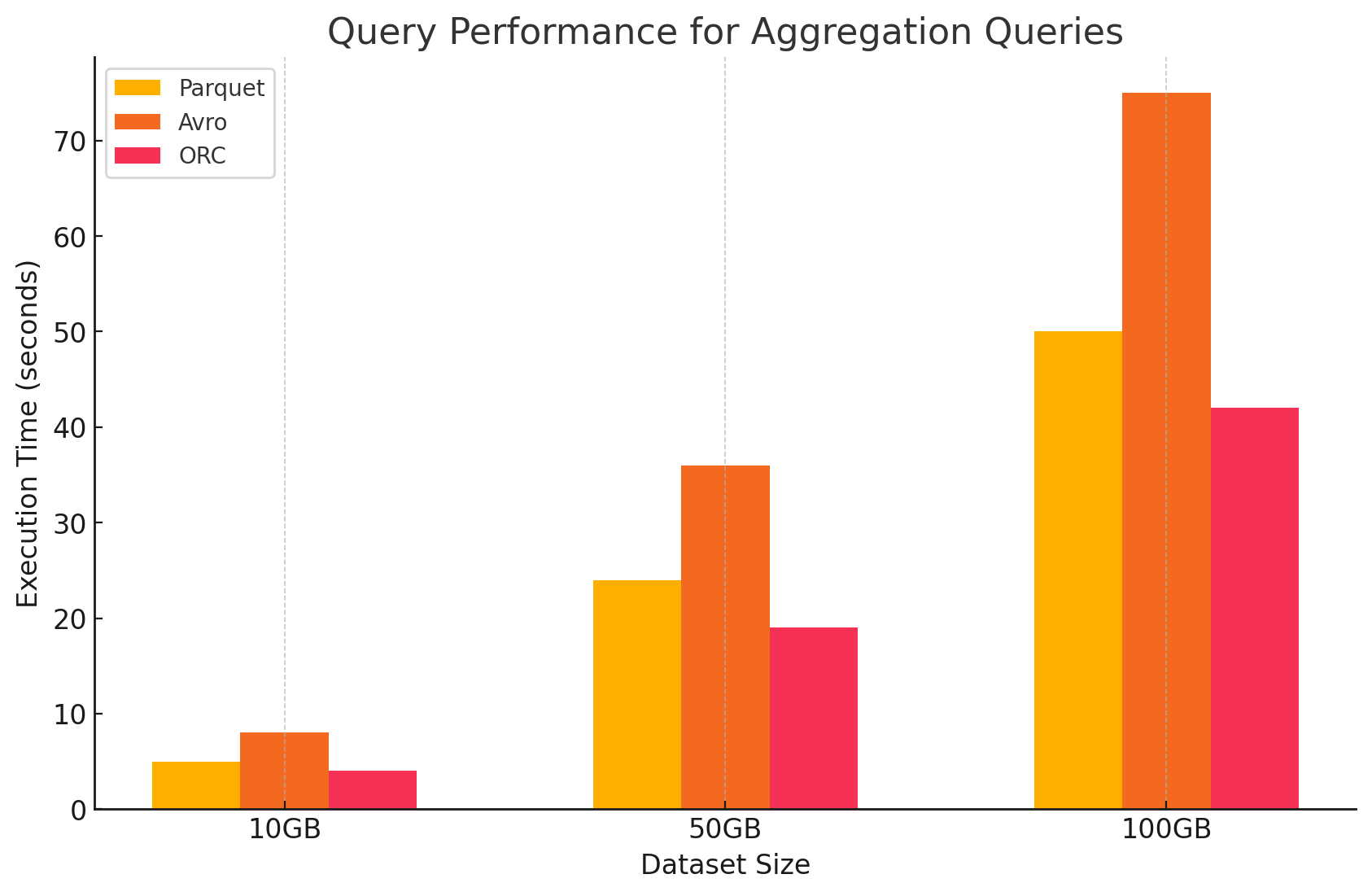
3. Consultas de Agregação
- Parquet:O Parquet teve um bom desempenho, mas menos eficiente do que o ORC. O formato colunar beneficia as operações de agregação através do acesso rápido às colunas necessárias, mas o Parquet faz falta de algumas das otimizações internas que o ORC oferece.
# Aggregation query on Parquet file
agg_parquet_df = parquet_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_parquet_df.show()
- Avro:O Avro ficou para trás devido ao seu armazenamento baseado em linhas, que exigiu a digitalização e o processamento de todas as colunas para cada linha, aumentando a sobrecarga computacional.
-- Aggregation query on Avro file in Hive
SELECT column1, SUM(column2), AVG(column3) FROM avro_table GROUP BY column1;
- ORC:O ORC superou ambos o Parquet e o Avro em consultas de agregação. As indexações avançadas e os algoritmos de compressão internos do ORC permitiram um acesso a dados mais rápido e redução de operações de E/S, tornando-o altamente adequado para tarefas de agregação.
# Aggregation query on ORC file
agg_orc_df = orc_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_orc_df.show()
4. Consultas de Junção
- Parquet:O Parquet teve um bom desempenho, mas não tão eficiente quanto o ORC em operações de junção devido à sua leitura de dados menos otimizada para condições de junção.
# Join query between Parquet and ORC files
joined_df = parquet_df.join(orc_df, parquet_df.key == orc_df.key)
joined_df.show()
- ORC:O ORC se destacou em consultas de junção, beneficiando de indexações avançadas e capacidades de pushdown de predicado, que minimizaram o número de dados escaneados e processados durante as operações de junção.
# Join query between two ORC files
joined_orc_df = orc_df.join(other_orc_df, orc_df.key == other_orc_df.key)
joined_orc_df.show()
- Avro: Avro teve dificuldades significativas com operações de junção, principalmente devido ao alto custo de leitura de linhas inteiras e a falta de otimizações colunares para chaves de junção.
-- Join query between Parquet and Avro files in Hive
SELECT a.column1, b.column2
FROM parquet_table a
JOIN avro_table b
ON a.key = b.key;
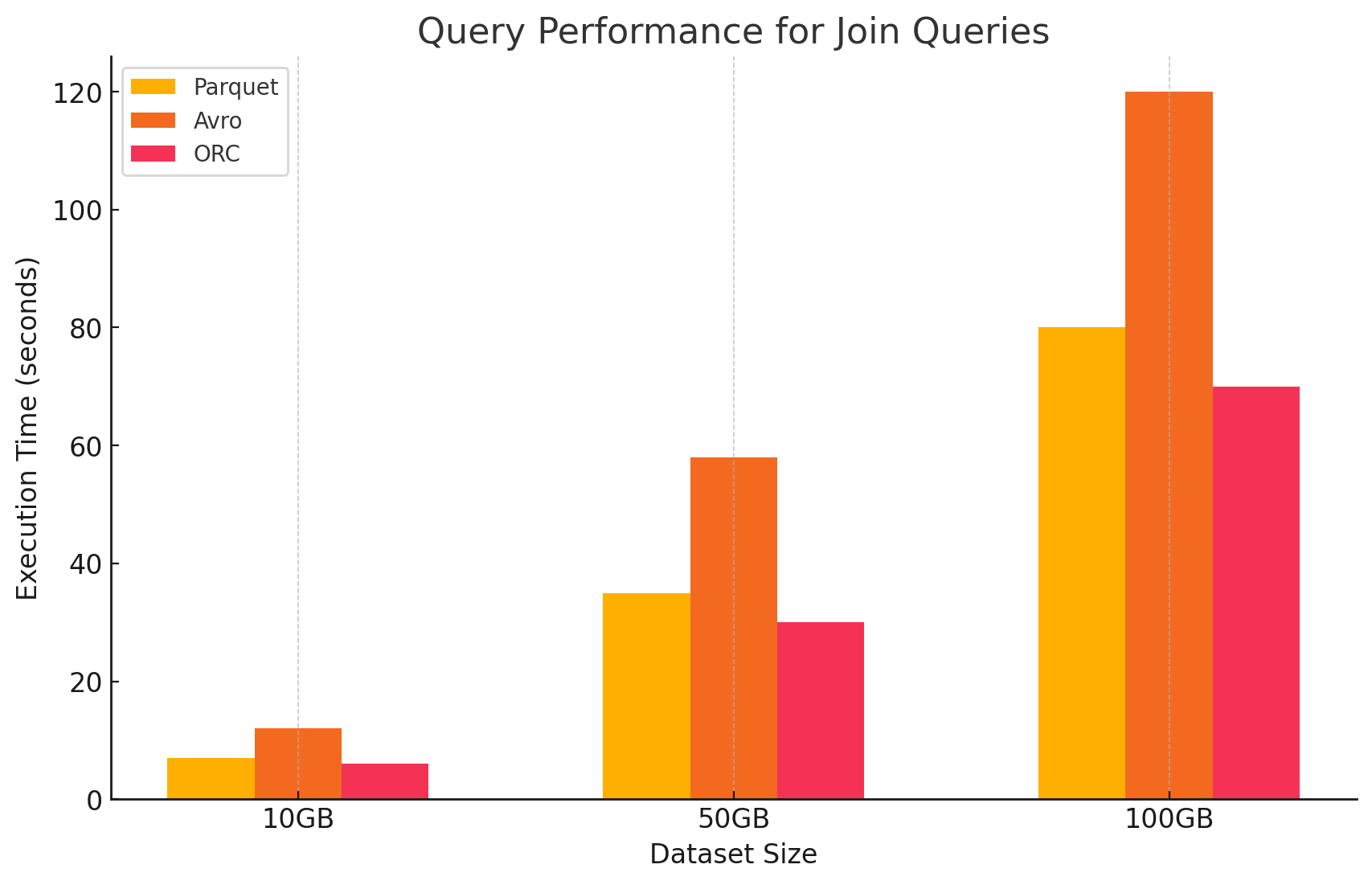
Impacto do Formato de Armazenamento nos Custos
1. Eficiência de Armazenamento e Custo
- Parquet e ORC (formatos colunares)
- Compressão e custo de armazenamento: Ambos o Parquet e o ORC são formatos de armazenamento colunares que oferecem altas taxas de compressão, especialmente para conjuntos de dados com muitos valores repeteis ou semelhantes dentro de colunas. Esta alta compressão reduce o tamanho de dados geral, reduzindo então os custos de armazenamento, particularmente em ambientes em nuvem onde o armazenamento é cobrado por GB.
- Otimizado para cargas de trabalho de análise: Devido à sua natureza colunar, esses formatos são ideais para cargas de trabalho de análise onde apenas colunas específicas são frequentemente consultadas. Isso significa que menos dados são lidos do armazenamento, reduzindo as operações de E/S e seus custos associados.
- Avro (formato de linhas)
- Custo de compressão e armazenamento: O Avro normalmente oferece taxas de compressão menores do que formatos de coluna, como Parquet e ORC, porque armazena dados linha por linha. Isso pode levar a custos de armazenamento superiores, particularmente para conjuntos de dados grandes com muitas colunas, já que todos os dados numa linha devem ser lidos, mesmo que apenas algumas colunas sejam necessárias.
- Melhor para cargas de trabalho com altas taxas de gravação: Embora o Avro possa resultar em custos de armazenamento superiores devido à baixa compressão, ele é melhor adaptado para cargas de trabalho com altas taxas de gravação onde dados estão sendo gravados ou acrescidos contínuamente. Os custos associados a armazenamento podem ser compensados pelos ganhos de eficiência nas serializações e deserializações de dados.
2. Desempenho e custo de processamento de dados
- Parquet e ORC (formatos de colunas)
- Custos de processamento reduzidos: Estes formatos são otimizados para operações de leitura pesada, o que os torna altamente eficientes para consultar grandes conjuntos de dados. Por permitirem apenas a leitura das colunas relevantes necessárias para uma consulta, eles reduzem a quantidade de dados processados. Isto resulta em menor uso de CPU e tempo de execução de consulta mais rápido, o que pode reduzir significativamente os custos de computação em um ambiente em nuvem onde recursos de computação são faturados com base no uso.
- Funcionalidades avançadas para otimização de custos: ORC, em particular, inclui funcionalidades como push-down de predicado e estatísticas integradas, que permitem ao motor de consulta pular o leitura de dados não necessários. Isto reduz ainda mais as operações de E/S e acelera o desempenho de consulta, otimizando custos.
- Avro (formatos baseados em linhas)
- Custos de processamento mais altos:Como o Avro é um formato baseado em linhas, ele normalmente requer mais operações de E/S para ler linhas inteiras mesmo quando são necessárias apenas algumas colunas. Isso pode levar a custos de processamento aumentados devido ao uso superior de CPU e a tempo de execução de consultas mais longos, especialmente em ambientes com elevado volume de leitura.
- Eficiente para streaming e serialização:Apesar dos custos de processamento mais altos para consultas, o Avro é bem adequado para tarefas de streaming e serialização onde a velocidade de gravação rápida e a evolução do esquema são mais críticas.
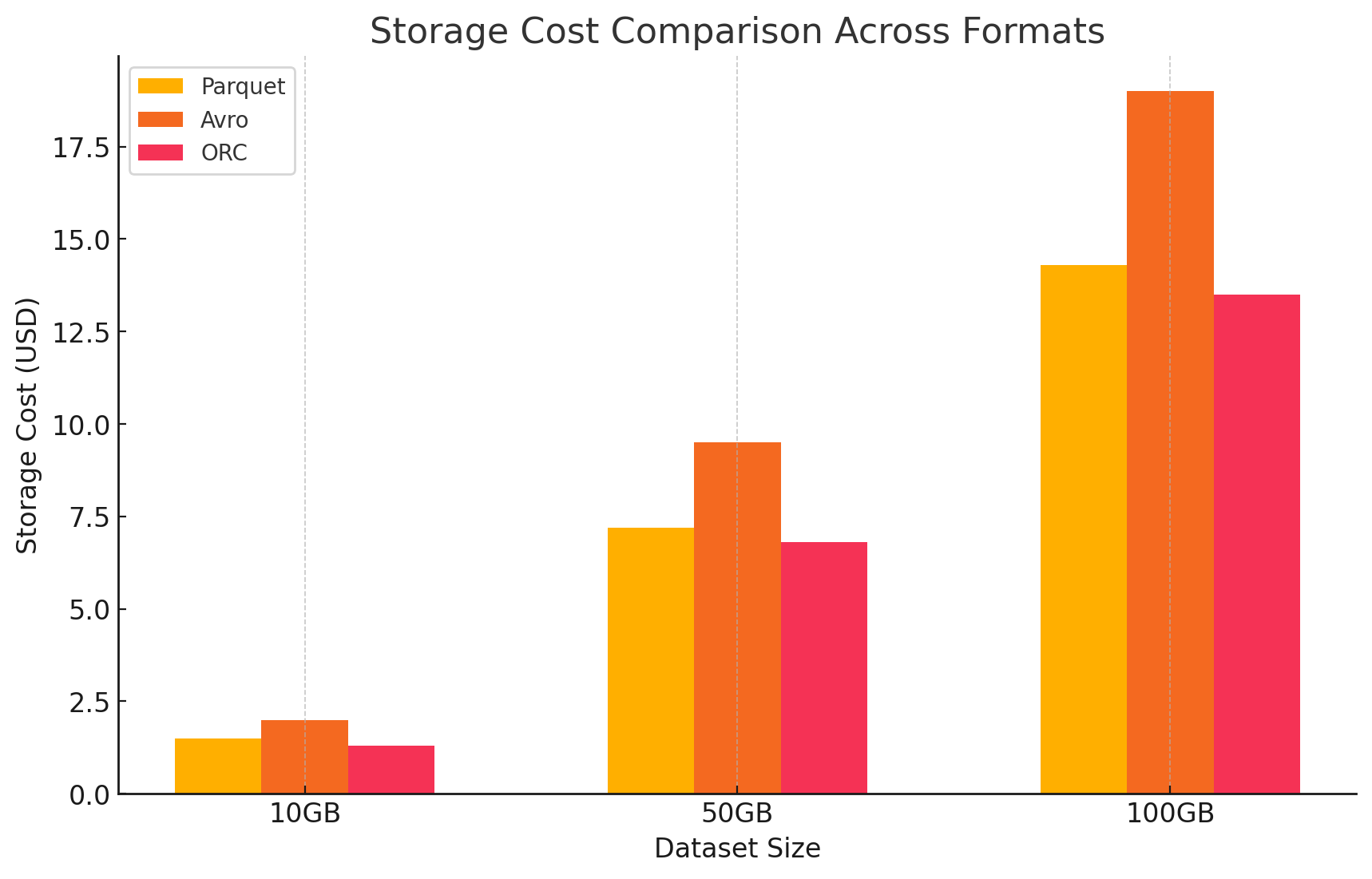
3. Análise de Custo com detalhes de Preços
- Para quantificar o impacto de cada formato de armazenamento nos custos, nós realizamos um experimento usando o GCP. Nós calcularmos os custos associados com ambos o armazenamento e o processamento de dados para cada formato com base nos modelos de preços do GCP.
- Custos de armazenamento do Google Cloud
- Custo de armazenamento: Este é calculado com base na quantidade de dados armazenados em cada formatação. O GCP cobra por GB por mês para dados armazenados no Google Cloud Storage. As taxas de compressão alcançadas por cada formatação afetam diretamente estes custos. As formatações colunares, como Parquet e ORC, normalmente têm melhores taxas de compressão do que as formatações baseadas em linhas, como Avro, resultando em custos de armazenamento mais baixos.
- Aqui está um exemplo de como os custos de armazenamento foram calculados:
- Parquet: A alta compressão resultou em tamanho de dado reduzido, abaixando o custo de armazenamento
- ORC: Similar a Parquet, a compressão avançada de ORC também reduziu eficazmente os custos de armazenamento
- Avro: A eficiência de compressão baixa resultou em custos de armazenamento mais altos em comparação com Parquet e ORC
# Example of how to save data back to Google Cloud Storage in different formats
# Save DataFrame as Parque
parquet_df.write.parquet("gs://your-bucket/output_parquet")
# Save DataFrame as Avro
avro_df.write.format("avro").save("gs://your-bucket/output_avro")
# Save DataFrame as ORC
orc_df.write.orc("gs://your-bucket/output_orc")
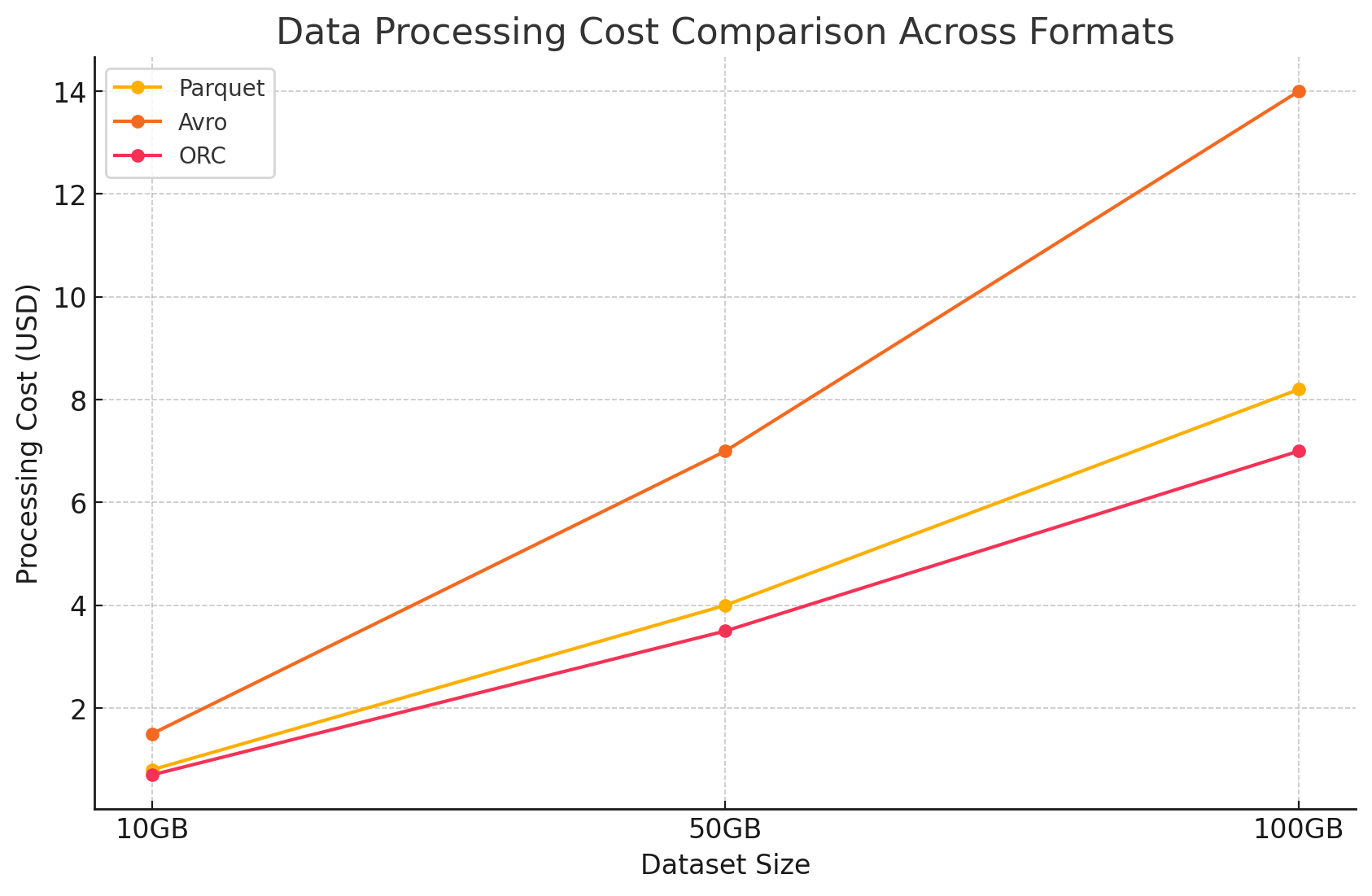
- Custos de processamento de dados
- Os custos de processamento de dados foram calculados com base nas recursos de computação necessários para executar várias consultas usando o Dataproc no GCP. O GCP cobra por uso do Dataproc com base no tamanho do cluster e na duração para a qual os recursos são usados.
- Custos de computação:
- Parquet e ORC: Ao utilizar um formato colunar eficiente de armazenamento, estes formatos reduziram a quantidade de dados lidos e processados, resultando em custos de processamento mais baixos. As melhores execuções de consultas também contribuíram para o economizado de custos, especialmente para consultas complexas envolvendo grandes conjuntos de dados.
- Avro: O Avro exigiu mais recursos de computação devido ao formato de linha, o que aumentou a quantidade de dados lidos e processados. Isto resultou em custos maiores, particularmente para operações de leitura intensiva.
Conclusão
A escolha do formato de armazenamento em ambientes de big data impacta significativamente tanto o desempenho de consulta quanto o custo. A pesquisa e os experimentos acima demonstram os seguintes pontos chave:
- Parquet e ORC: Estes formatos de coluna fornecem excelente compressão, reduzindo os custos de armazenamento. Sua capacidade de ler somente as colunas necessárias melhora consideravelmente o desempenho de consulta e reduz os custos de processamento de dados. ORC supera ligeiramente Parquet em certos tipos de consultas devido às suas funcionalidades de índice avançadas e otimização, tornando-o uma escolha excelente para cargas de trabalho mistas que exigem tanto alto desempenho de leitura quanto de gravação.
- Avro: Embora Avro não seja tão eficiente em termos de compressão e desempenho de consulta quanto Parquet e ORC, ele se destaca em casos de uso que exigem operações de gravação rápidas e evolução de esquema. Este formato é ideal para cenários envolvendo serialização de dados e streaming onde o desempenho de gravação e a flexibilidade são priorizados sobre a eficiência de leitura.
- Eficiência de custo: Em um ambiente cloud como o GCP, onde os custos estão fortemente ligados ao uso de armazenamento e computação, escolher o formato certo pode resultar em consideráveis economias de custo. Para cargas de trabalho de análise que são predominantemente pesadas na leitura, Parquet e ORC são as opções mais econômicas. Para aplicações que exigem ingestão rápida de dados e gerenciamento flexível de esquema, Avro é uma escolha adequada apesar de seus custos de armazenamento e computação superiores.
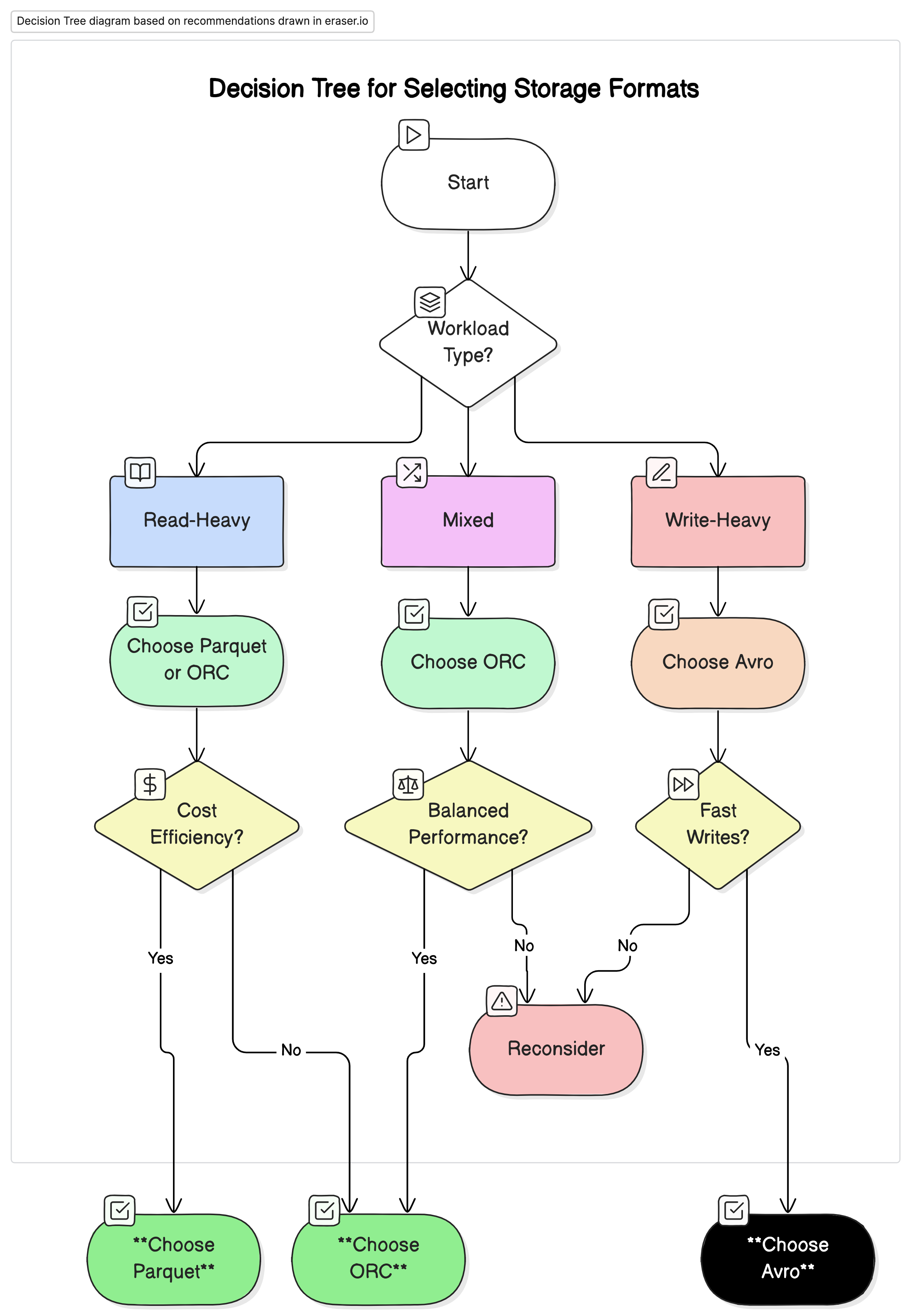
Recomendações
Baseado na nossa análise, recomendamos o seguinte:
- Para cargas de trabalho analíticas com forte leitura: Use Parquet ou ORC. Esses formatos proporcionam desempenho e eficiência de custo superiores devido à alta compressão e desempenho de consulta otimizado.
- Para cargas de trabalho com forte escrita e serialização: Use Avro. Ele é melhor adaptado a cenários onde escrita rápida e evolução de esquema são críticos, como em streaming de dados e sistemas de mensagens.
- Para cargas de trabalho mistas: ORC oferece desempenho balanceado para operações de leitura e escrita, tornando-se uma escolha ideal para ambientes onde as cargas de trabalho de dados variam.
Pensamentos Finais
Selecionar o formato de armazenamento adequado para ambientes de big data é crucial para otimizar o desempenho e o custo. Entender as forças e as fraquezas de cada formato permite que os engenheiros de dados personalizeiem sua arquitetura de dados para casos de uso específicos, maximizando a eficiência e minimizando os gastos. Com o continuo crescimento dos volumes de dados, tomar decisões informadas sobre formatos de armazenamento se tornará cada vez mais importante para manter soluções de dados escaláveis e eficientes em termos de custo.
Ao avaliar cuidadosamente as marcas de desempenho e as implicações de custo apresentadas neste artigo, as organizações podem escolher o formato de armazenamento que melhor se alinha com suas necessidades operacionais e objetivos financeiros.
Source:
https://dzone.com/articles/performance-and-cost-implications-parquet-avro-orc