













Il processamento efficiente dei dati è fondamentale per aziende e organizzazioni che si affidano alle analisi di grandi dati per prendere decisioni informate. Un fattore chiave che influisce significativamente sul rendimento del processamento dei dati è il formato di memorizzazione dei dati. Questo articolo esplora l’impatto di diversi formati di memorizzazione, specificamente Parquet, Avro e ORC, sul rendimento delle query e sui costi in ambienti di grandi dati su Google Cloud Platform (GCP). L’articolo fornisce benchmark, discute le implicazioni economiche e offre raccomandazioni sulla scelta del formato corretto in base a casi d’uso specifici.
Introduzione ai formati di memorizzazione nei grandi dati
I formati di memorizzazione sono la base di ogni ambiente di processamento di grandi dati. Definiscono come i dati sono memorizzati, letti e scritti, influendo direttamente sull’efficienza di memorizzazione, sul rendimento delle query e sulla velocità di recupero dei dati. Nell’ecosistema dei grandi dati, i formati a colonna come Parquet e ORC e i formati a riga come Avro sono ampiamente utilizzati a causa del loro ottimizzato rendimento per certi tipi di query e attività di processing.
- Parquet: Parquet è un formato di memorizzazione a colonna ottimizzato per operazioni di lettura pesanti e analisi. È altamente efficiente in termini di compressione e codifica, rendendolo ideale per scenario in cui si prioritza il rendimento delle letture e l’efficienza della memorizzazione.
- Avro: Avro è un formato di memorizzazione a riga progettato per la serializzazione dei dati. È conosciuto per le sue capacità di evoluzione dello schema e viene spesso utilizzato per operazioni di scrittura intense in cui i dati devono essere serializzati e deserializzati rapidamente.
- ORC (Optimized Row Columnar):ORC è un formato di archiviazione a colonna simile a Parquet, ma ottimizzato per entrambe le operazioni di lettura e scrittura. ORC è altamente efficiente in termini di compressione, che riduce i costi di archiviazione e accelerata la ricerca dati.
Scopo della ricerca
L’obiettivo primario di questa ricerca è valutare come differenti formati di archiviazione (Parquet, Avro, ORC) influiscono sulle prestazioni delle query e sui costi negli ambienti di grandi dati. Questo articolo si propone di fornire benchmark basati su diversi tipi di query e volumi di dati per aiutare gli ingegneri dati e gli architetti a scegliere il formato più adatto per i loro casi d’uso specifici.
Implementazione sperimentale
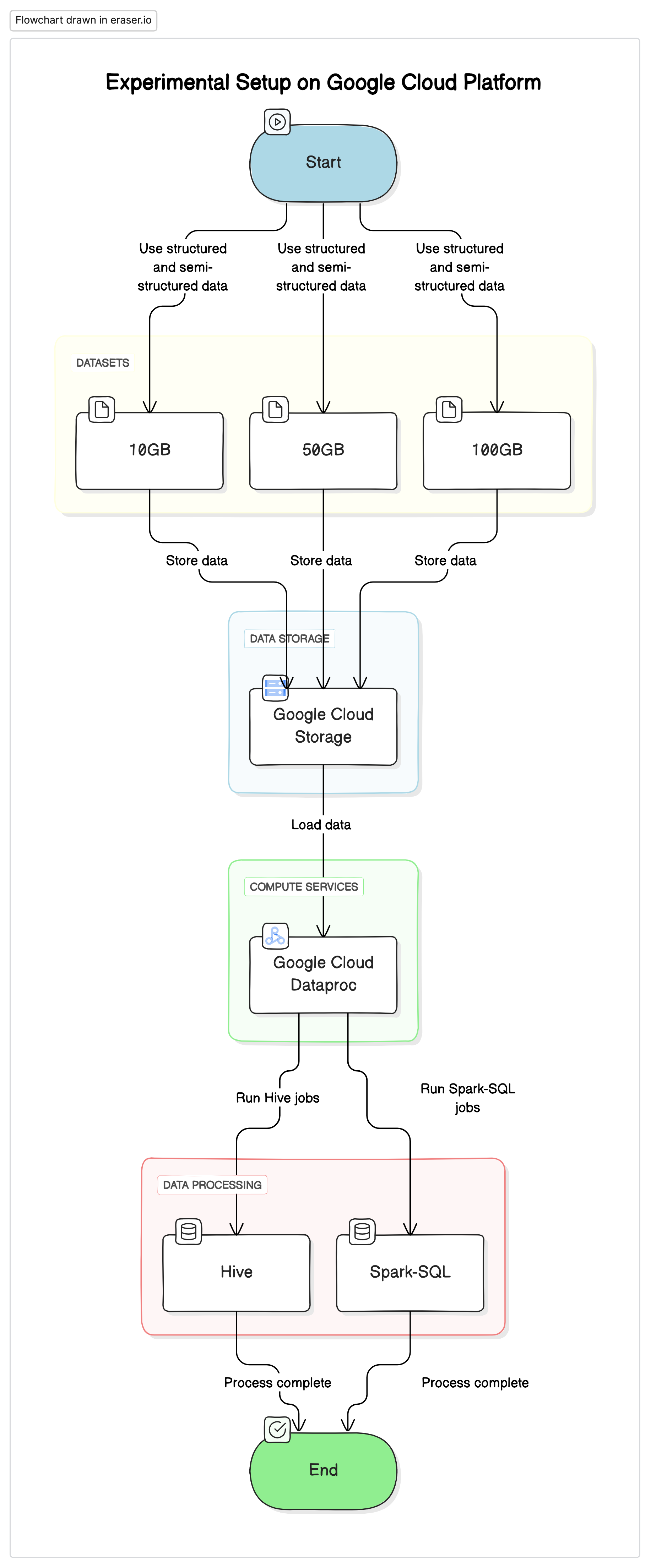
Per condurre questa ricerca, abbiamo usato un impianto standardizzato su Google Cloud Platform (GCP) con Google Cloud Storage come repository dati e Google Cloud Dataproc per eseguire i job Hive e Spark-SQL. I dati utilizzati negli esperimenti erano una miscela di dataset strutturati e semi-strutturati per emulare scenari reali.
Componenti chiave
- Google Cloud Storage:Usato per archiviare i dataset in differenti formati (Parquet, Avro, ORC)
- Google Cloud Dataproc:Un servizio gestito Apache Hadoop e Apache Spark utilizzato per eseguire i job Hive e Spark-SQL.
- Datasets:Tre dataset di dimensioni differenti (10GB, 50GB, 100GB) con tipi di dati misti.
# Initialize PySpark and set up Google Cloud Storage as file system
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("BigDataQueryPerformance") \
.config("spark.jars.packages", "com.google.cloud.bigdataoss:gcs-connector:hadoop3-2.2.5") \
.getOrCreate()
# Configure the access to Google Cloud Storage
spark.conf.set("fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem")
spark.conf.set("fs.gs.auth.service.account.enable", "true")
spark.conf.set("google.cloud.auth.service.account.json.keyfile", "/path/to/your-service-account-file.json")
Query di test
- Query di SELECT semplici:Ricerca di tutte le colonne in una tabella
- Query di filtro:Query di SELECT con clausole WHERE per filtrare righe specifiche
- Query di aggregazione:Query che coinvolgono FUNZIONI AGGIUNGESE come SUM, AVG, ecc..
- Query di join:Query che uniscono due o più tabelle su una chiave comune
Risultati e Analisi
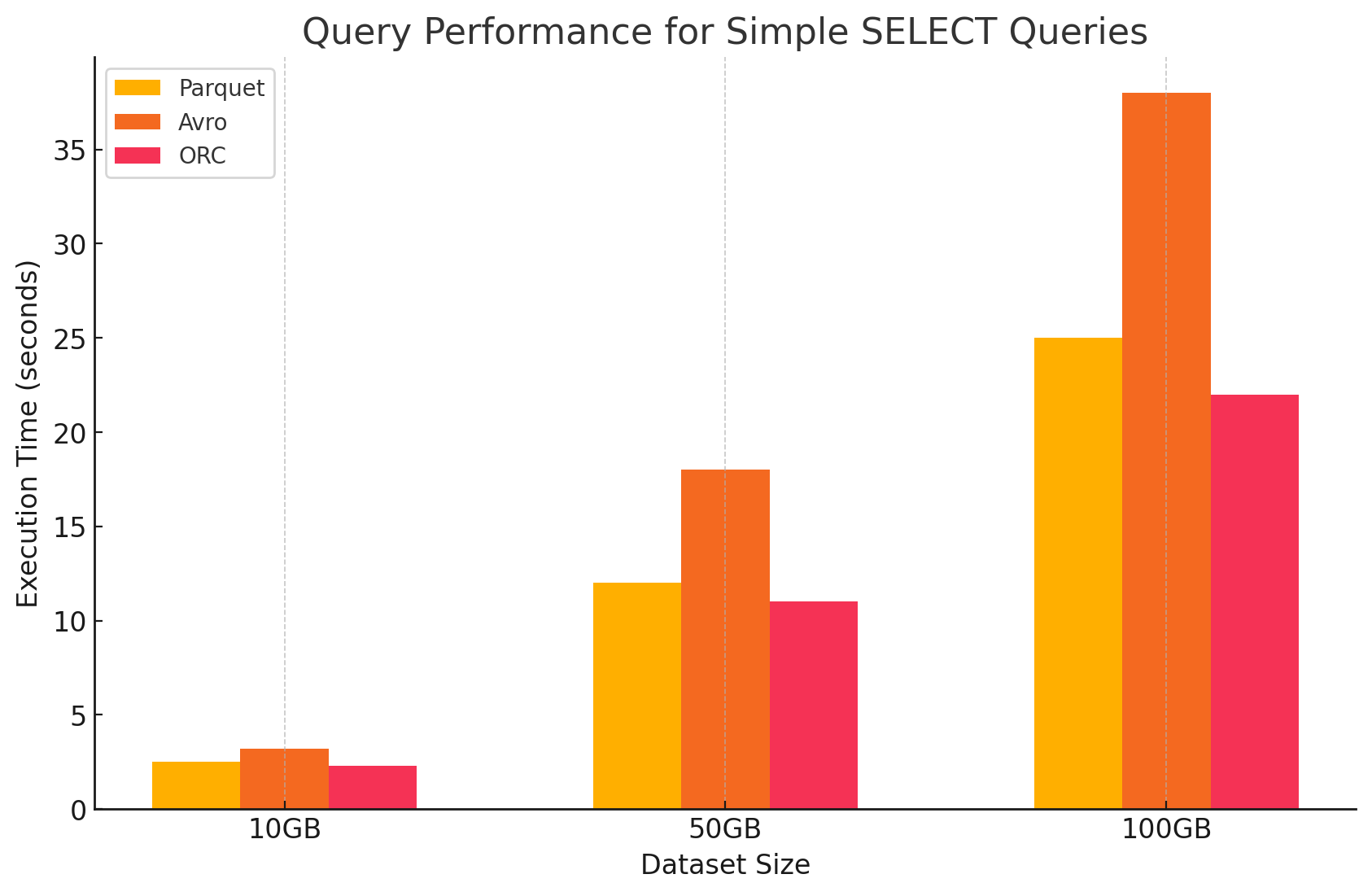
1. Query di SELECT semplici
- Parquet: Ha dimostrato un ottimo rendimento grazie al suo formato di archiviazione a colonna, che ha permesso di scannerizzare rapidamente le colonne specifiche. I file Parquet sono altamente compresi, riducendo il volume di dati letti dalla disco, il che ha portato a tempi di esecuzione di query più rapidi.
# Simple SELECT query on Parquet file
parquet_df.select("column1", "column2").show()
- Avro: Avro ha dimostrato un rendimento moderato. Essendo un formato a righe, Avro richiede la lettura dell’intera riga, anche quando sono necessarie solo colonne specifiche. Questo aumenta le operazioni I/O, portando a un rendimento di query più lento rispetto a Parquet e ORC.
-- Simple SELECT query on Avro file in Hive
CREATE EXTERNAL TABLE avro_table
STORED AS AVRO
LOCATION 'gs://your-bucket/dataset.avro';
SELECT column1, column2 FROM avro_table;
- ORC: ORC ha mostrato un rendimento simile a Parquet, con una compressione leggermente migliore e tecniche di archiviazione ottimizzate che hanno incrementato le velocità di lettura. I file ORC sono anch’essi a colonna, rendendoli adatti per le query di SELECT che recuperano solo colonne specifiche.
# Simple SELECT query on ORC file
orc_df.select("column1", "column2").show()
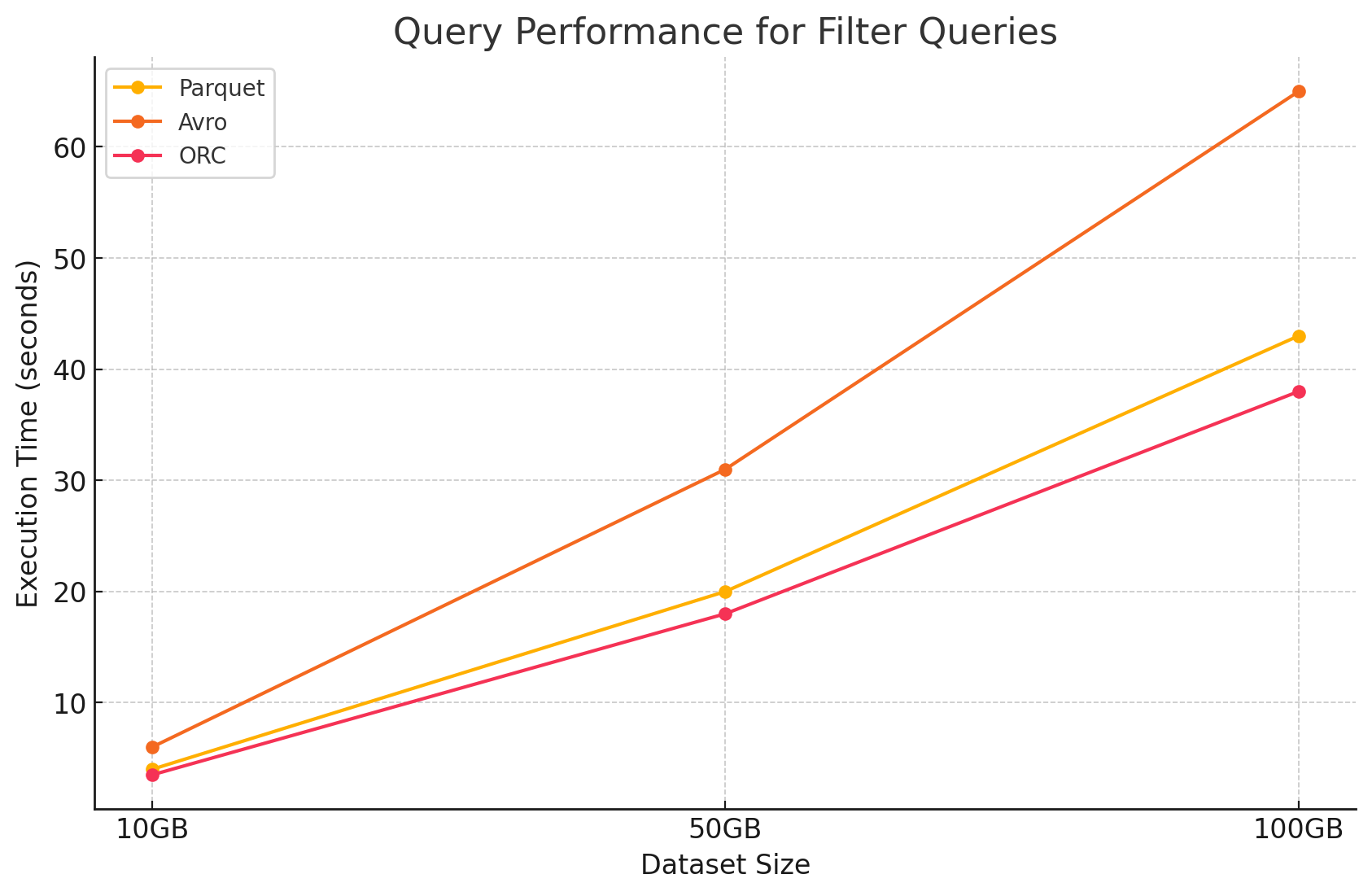
2. Query di filtro
- Parquet: Parquet ha mantenuto il suo vantaggio di rendimento a causa della sua natura a colonna e della capacità di saltare rapidamente le colonne non appropriate. Tuttavia, il rendimento è stato leggermente influenzato dalla necessità di scannerizzare più righe per applicare i filtri.
# Filter query on Parquet file
filtered_parquet_df = parquet_df.filter(parquet_df.column1 == 'some_value')
filtered_parquet_df.show()
- Avro:La performance è diminuita ulteriormente a causa della necessità di leggere interi righe e applicare filtri su tutte le colonne, aumentando il tempo di processamento.
-- Filter query on Avro file in Hive
SELECT * FROM avro_table WHERE column1 = 'some_value';
- ORC:Questo ha ottenuto un miglioramento leggero rispetto a Parquet nelle query di filtraggio grazie alla sua caratteristica di spintamento dei predicati, che consente di filtrare direttamente al livello di storage prima che i dati siano caricati in memoria.
# Filter query on ORC file
filtered_orc_df = orc_df.filter(orc_df.column1 == 'some_value')
filtered_orc_df.show()
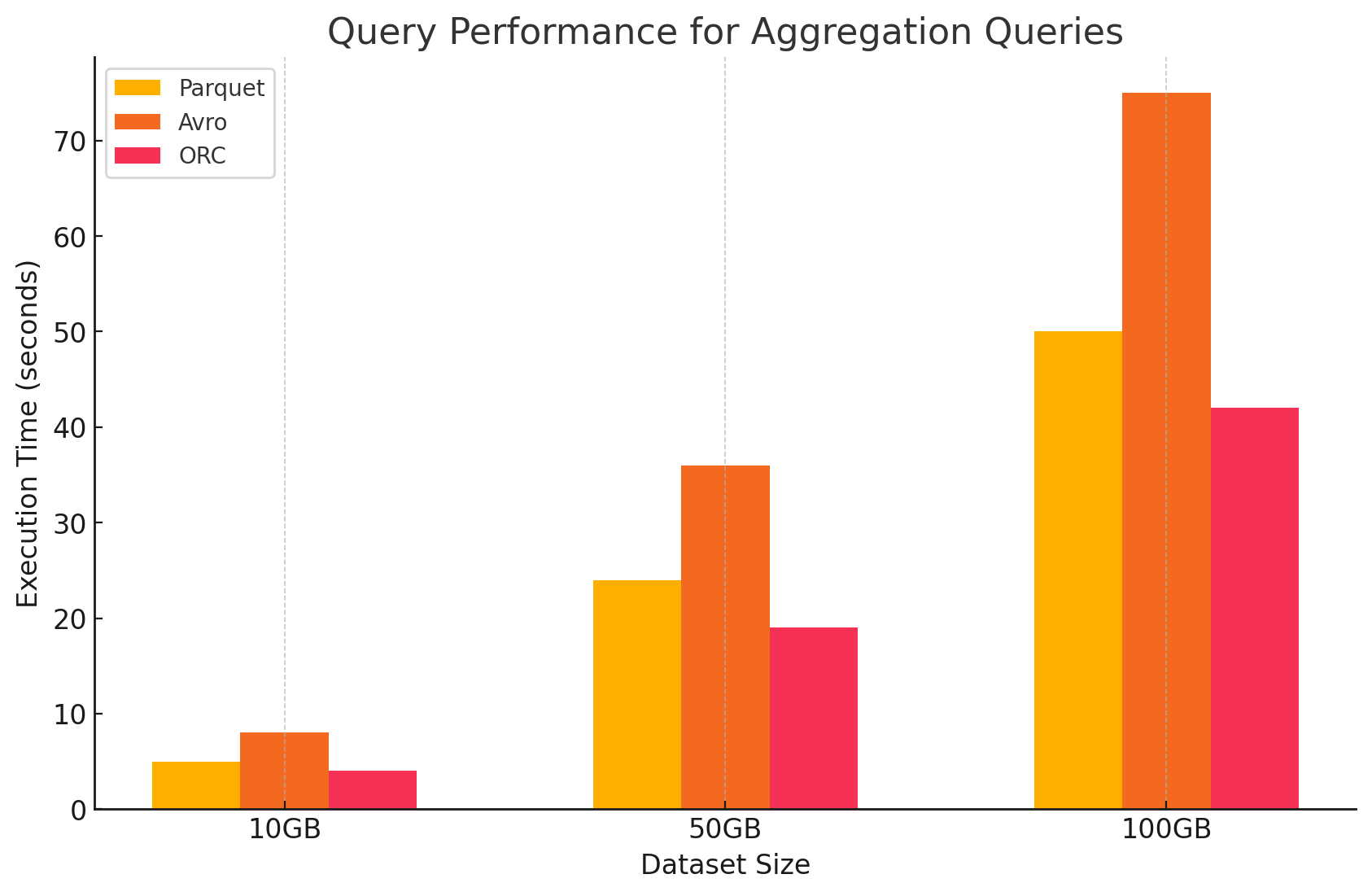
3. Query di aggregazione
- Parquet:Parquet ha fatto un buon lavoro, ma è stato leggermente meno efficiente di ORC. Il formato colonnare consente operazioni di aggregazione veloci tramite l’accesso rapido alle colonne richieste, ma Parquet manca di alcune ottimizzazioni integrate che ORC offre.
# Aggregation query on Parquet file
agg_parquet_df = parquet_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_parquet_df.show()
- Avro:Avro è stato indietro a causa del suo schema di memorizzazione riga, che richiedeva il scansionere e il processare di tutte le colonne per ogni riga, aumentando il carico computazionale.
-- Aggregation query on Avro file in Hive
SELECT column1, SUM(column2), AVG(column3) FROM avro_table GROUP BY column1;
- ORC:ORC ha superato entrambi Parquet e Avro nelle query di aggregazione. L’indicing avanzato di ORC e i suoi algoritmi di compressione integrati hanno consentito un accesso dati più veloce e hanno ridotto le operazioni di I/O, rendendolo molto adatto alle attività di aggregazione.
# Aggregation query on ORC file
agg_orc_df = orc_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_orc_df.show()
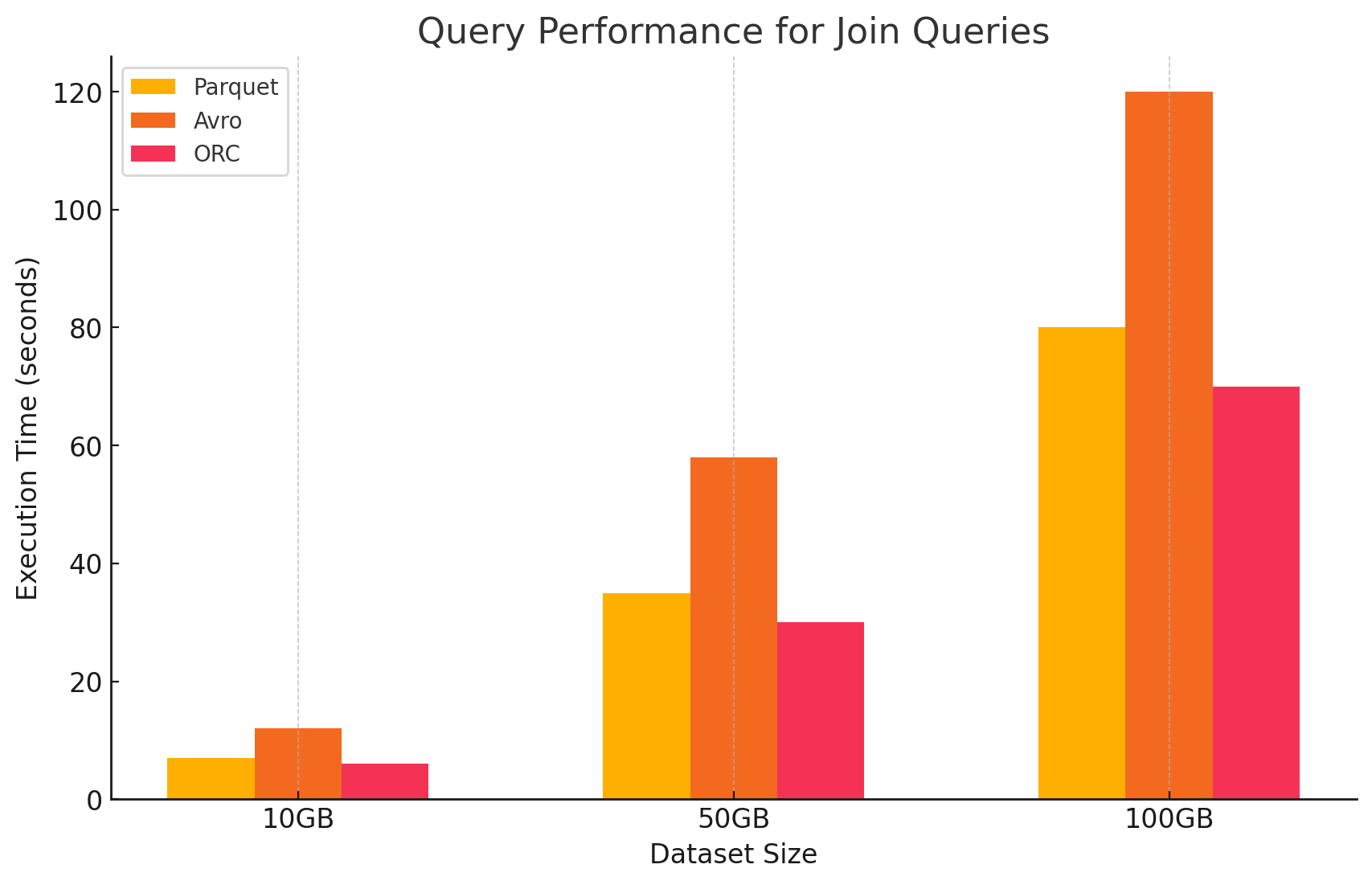
4. Query di join
- Parquet:Parquet ha funzionato bene, ma non è stato così efficiente come ORC nelle operazioni di join a causa della lettura meno ottimizzata dei dati per le condizioni di join.
# Join query between Parquet and ORC files
joined_df = parquet_df.join(orc_df, parquet_df.key == orc_df.key)
joined_df.show()
- ORC:ORC ha eccelluto nelle query di join, beneficiando dall’indicing avanzato e dalle capacità di spintamento predicato, che hanno minimizzato i dati scansionati e processati durante le operazioni di join.
# Join query between two ORC files
joined_orc_df = orc_df.join(other_orc_df, orc_df.key == other_orc_df.key)
joined_orc_df.show()
- Avro: Avro ha lottato significativamente con le operazioni di join, principalmente a causa dell’elevato overhead del caricamento delle righe complete e della mancanza di ottimizzazioni colonnari per le chiavi di join.
-- Join query between Parquet and Avro files in Hive
SELECT a.column1, b.column2
FROM parquet_table a
JOIN avro_table b
ON a.key = b.key;
Impatto del formato di storage sui costi
1. Efficienza di storage e costi
- Parquet e ORC (formati colonnari)
- Compressione e costi di storage:Entrambi Parquet e ORC sono formati di storage colonnare che offrono alte rapporti di compressione, specialmente per dataset con molti valori ripetuti o simili all’interno delle colonne. Questa alta compressione riduce la dimensione complessiva dei dati, diminuendo così i costi di storage, soprattutto in ambienti cloud dove il storage è fatturato a GB.
- Ottimale per carichi di lavoro di analytics:A causa della loro natura colonnare, questi formati sono ideali per carichi di lavoro analitici in cui sono frequentemente richieste soltanto determinate colonne. Questo significa che meno dati vengono letti dal storage, riducendo sia le operazioni di I/O che i relativi costi.
- Avro (formato basato su righe)
- Compressione e costi di archiviazione: Avro in genere fornisce rapporti di compressione inferiori rispetto ai formati a colonne come Parquet e ORC perché memorizza i dati riga per riga. Ciò può portare a costi di archiviazione più elevati, soprattutto per grandi set di dati con molte colonne, poiché tutti i dati in una riga devono essere letti, anche se sono necessarie solo alcune colonne.
- Migliore per carichi di lavoro con molte scritture: Sebbene Avro possa comportare costi di archiviazione più elevati a causa della compressione inferiore, è più adatto per carichi di lavoro con molte scritture, in cui i dati vengono continuamente scritti o aggiunti. I costi associati all’archiviazione possono essere compensati dai guadagni in efficienza nella serializzazione e deserializzazione dei dati.
2. Prestazioni e costi dell’elaborazione dei dati
- Parquet e ORC (formati a colonne)
- Costi di elaborazione ridotti: Questi formati sono ottimizzati per operazioni di lettura intensiva, il che li rende altamente efficienti per l’interrogazione di grandi set di dati. Poiché consentono di leggere solo le colonne pertinenti necessarie per una query, riducono la quantità di dati elaborati. Ciò porta a un minore utilizzo della CPU e a tempi di esecuzione delle query più rapidi, il che può ridurre significativamente i costi computazionali in un ambiente cloud dove le risorse di calcolo vengono fatturate in base all’utilizzo.
- Funzionalità avanzate per l’ottimizzazione dei costi: ORC, in particolare, include funzionalità come il predicate push-down e statistiche integrate, che consentono al motore di query di evitare di leggere dati non necessari. Questo riduce ulteriormente le operazioni di I/O e accelera le prestazioni delle query, ottimizzando i costi.
- Avro (formati a righe)
- Costi di elaborazione superiori: Poiché Avro è un formato a righe, di solito richiede più operazioni I/O per leggere interi righe anche quando sono necessarie solo poche colonne. Questo può portare a costi di elaborazione maggiori a causa dell’elevato utilizzo del CPU e di tempi di esecuzione di query più lunghi, specialmente in ambienti con elevato carico di lettura.
- Efficace per la streaming e la serializzazione: Nonostante i costi di elaborazione superiori per le query, Avro è molto adatto alle attività di streaming e serializzazione in cui le velocità di scrittura elevate e l’evoluzione dello schema sono più critiche.
3. Analisi dei costi con dettagli sul prezzo
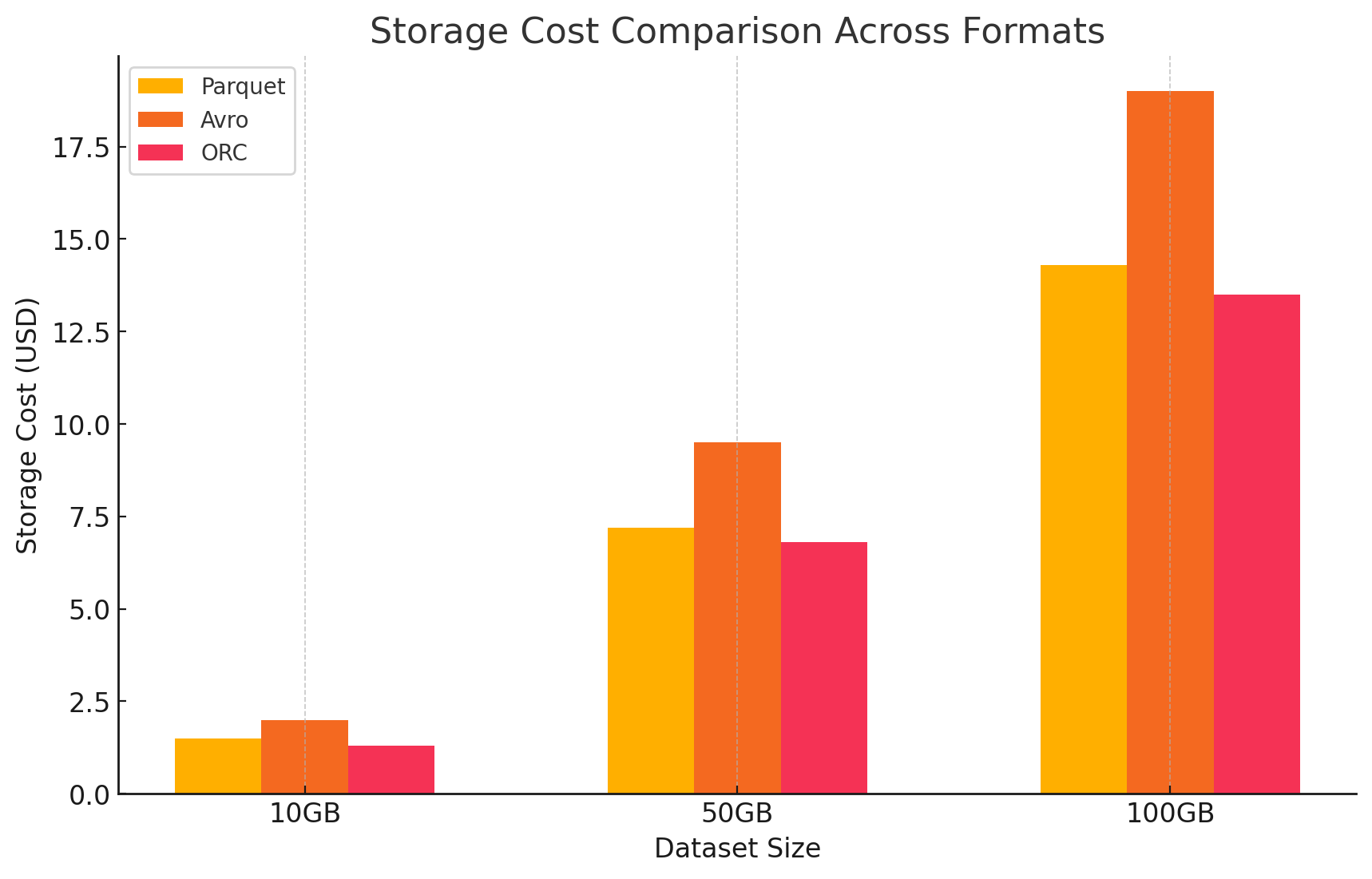
- Per quantificare l’impatto dei costi di ciascun formato di archiviazione, abbiamo condotto un esperimento utilizzando GCP. Abbiamo calcolato i costi associati sia all’archiviazione che all’elaborazione dati per ciascun formato in base ai modelli di prezzo di GCP.
- Costi di archiviazione Google Cloud
- Costo di archiviazione: Questo è calcolato in base alla quantità di dati archiviati in ogni formato. GCP addebita un importo per GB al mese per i dati archiviati in Google Cloud Storage. I tassi di compressione raggiunti da ciascun formato influiscono direttamente su questi costi. I formati a colonna come Parquet e ORC hanno generalmente tassi di compressione migliori rispetto ai formati a riga come Avro, riducendo così i costi di archiviazione.
- Ecco un esempio di come sono stati calcolati i costi di archiviazione:
- Parquet: La alta compressione ha ridotto la dimensione dei dati, abbassando i costi di archiviazione
- ORC: Come Parquet, anche l’efficace compressione di ORC ha abbassato i costi di archiviazione
- Avro: La bassa efficienza di compressione ha portato a costi di archiviazione superiori rispetto a Parquet e ORC
# Example of how to save data back to Google Cloud Storage in different formats
# Save DataFrame as Parque
parquet_df.write.parquet("gs://your-bucket/output_parquet")
# Save DataFrame as Avro
avro_df.write.format("avro").save("gs://your-bucket/output_avro")
# Save DataFrame as ORC
orc_df.write.orc("gs://your-bucket/output_orc")
- Costi di elaborazione dati
- I costi di elaborazione dati sono stati calcolati sulla base delle risorse computazionali richieste per eseguire varie query utilizzando Dataproc su GCP. GCP addebita per l’uso di Dataproc in base alla dimensione del cluster e alla durata dell’utilizzo delle risorse.
- Costi computazionali:
- Parquet e ORC: A causa della loro efficiente archiviazione a colonne, questi formati hanno ridotto la quantità di dati letti e elaborati, portando a costi computazionali inferiori. Le tempi di esecuzione di query più veloci hanno anche contribuito alle risparmi, soprattutto per query complesse che coinvolgono grandi dataset.
- Avro: Avro richiedeva più risorse computazionali a causa del suo formato basato su righe, che aumentava la quantità di dati letti e elaborati. Questo ha portato a costi più alti, soprattutto per operazioni con elevato carico di lettura.
Conclusioni
La scelta del formato di storage negli ambienti di grandi dati ha un impatto significativo sia sulla prestazione delle query che sul costo. La ricerca e gli esperimenti sopra descritti dimostrano i seguenti punti chiave:
- Parquet e ORC: Questi formati a colonna forniscono ottima compressione, che riduce i costi di storage. La loro capacità di leggere efficientemente solo le colonne necessarie aumenta显著mente la prestazione delle query e riduce i costi di processing dati. ORC si dimostra leggermente superiore a Parquet in alcuni tipi di query a causa delle sue caratteristiche di indice avanzate e di ottimizzazione, rendendolo una scelta eccellente per workload misti che richiedono sia un alto rendimento in lettura che in scrittura.
- Avro: Avro non è così efficiente in termini di compressione e prestazioni query come Parquet e ORC, ma è eccellente nei casi d’uso richiedenti operazioni di scrittura veloci e evoluzione dello schema. Questo formato è ideale per scenari che coinvolgono la serializzazione dati e il streaming in cui la prestazione di scrittura e la flessibilità sono prioritari rispetto all’efficienza di lettura.
- Efficienza costi: In un ambiente cloud come GCP, dove i costi sono strettamente legati all’utilizzo di storage e calcolo, scegliere il formato corretto può portare a risparmi significativi. Per workload analitici prevalentemente orientati alla lettura, Parquet e ORC sono le opzioni più economiche. Per applicazioni che richiedono una rapida ingestione dati e un gestimento schema flessibile, Avro è una scelta appropriata nonostante i suoi maggiori costi di storage e calcolo.
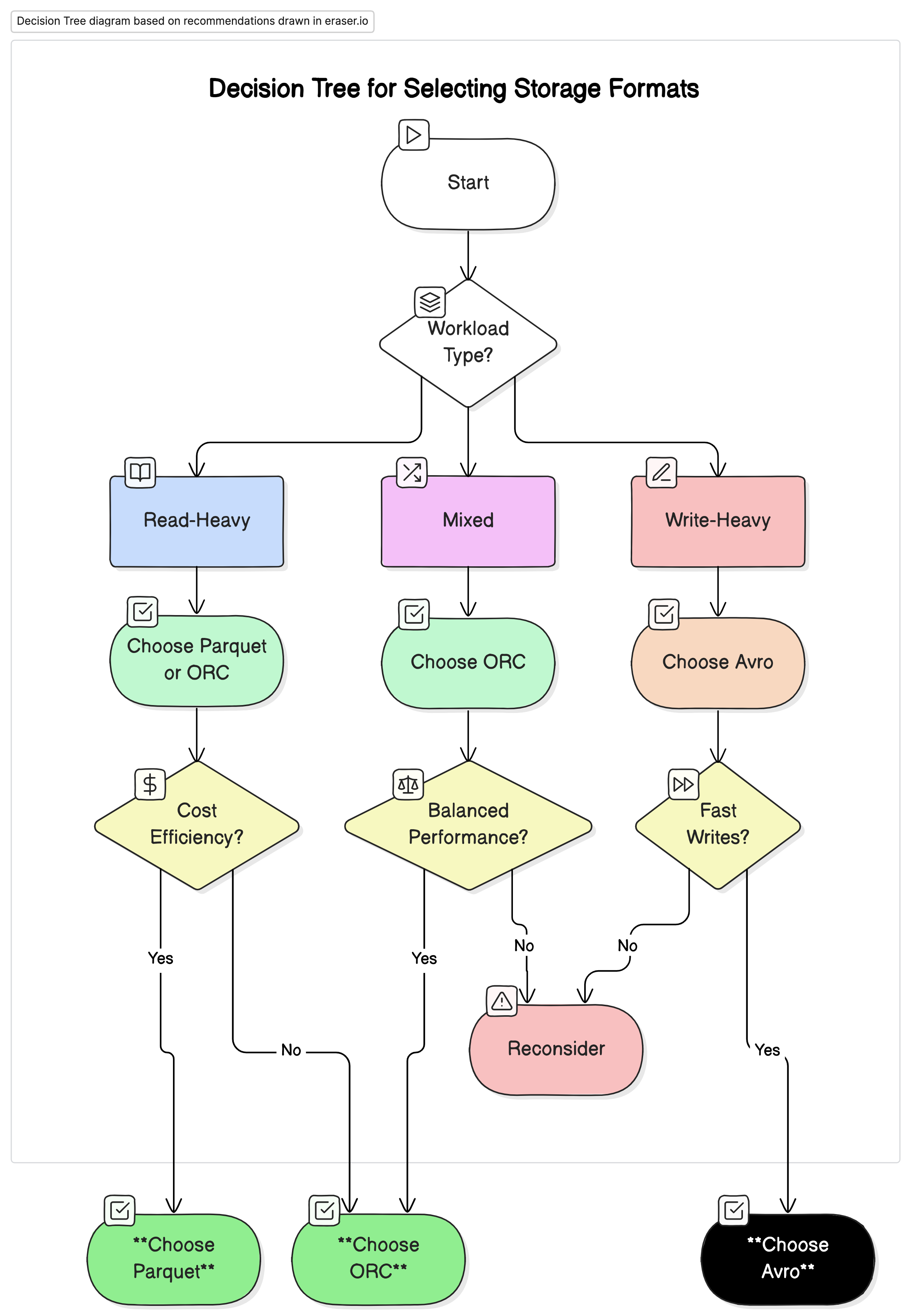
Raccomandazioni
Basandoci sull’analisi condotta, noi raccomandiamo il seguente:
- Per carichi di lavoro analitici con elevato volume di letture: Utilizza Parquet o ORC. Questi formati offrono prestazioni superiori e una maggiore efficienza economica grazie alla loro alta compressione e alle prestazioni di query ottimizzate.
- Per carichi di lavoro con elevato volume di scritture e serializzazione: Utilizza Avro. È più adatto a scenari in cui sono critiche scritture veloci e l’evoluzione dello schema, come nei flussi di dati e nei sistemi di messaggistica.
- Per carichi di lavoro misti: ORC offre prestazioni equilibrate sia per le operazioni di lettura che di scrittura, rendendolo una scelta ideale per ambienti in cui i carichi di lavoro dati variano.
Pensieri finali
La scelta del formato di storage corretto per ambienti di grandi dati è cruciale per ottimizzare sia le prestazioni che i costi. Comprendere le forze e i limiti di ciascun formato consente agli ingegneri dati di adattare la architettura dati ai singoli casi d’uso, massimizzando l’efficienza e minimizzando i costi. Con l’aumento continuo del volume dati, la decisione informata riguardo ai formati di storage diventerà sempre più importante per mantenere soluzioni di dati scalabili e economiche.
Attraverso un’attenta valutazione delle prestazioni dei benchmark e delle implicazioni costiose illustrate in questo articolo, le organizzazioni possono scegliere il formato di storage che miglioremente si adatta alle loro necessità operative e ai loro obiettivi finanziari.
Source:
https://dzone.com/articles/performance-and-cost-implications-parquet-avro-orc