













تحميل البيانات الفاعل هو أهمية كبيرة للشركات والمنظمات التي تعتمد على تحليل البيانات الكبيرة للتخمينات المعلوماتية. ويشكل عامل رئيسي يؤثر بشكل كبير على معالجة البيانات الأداء، وهو شكل التخزين الذي يتم به تخزين البيانات. يقوم هذا المقال باستكشاف تأثير أشكال التخزين المختلفة، بالتحديد Parquet و Avro و ORC على أداء التساؤلات والتكاليف في بيئات البيانات الكبيرة على منصة Google Cloud Platform (GCP). يوفر هذا المقال بمؤشرات، ويتناقش عن الآثار التكاليفية، ويقدم توصيات حول تحديد التنسيق المناسب وفقاً للحالات التي تمتد عنها.
مقدمة لأنماط التخزين في البيانات الكبيرة
أنماط التخزين في البيانات الكبيرة هي الأساس لأي بيئة تحميل البيانات الكبيرة. إنها تحدد كيفية تخزين البيانات، وقراءةها وكتابتها، وهذا يؤثر بشكل مباشر على فاعلية التخزين، وأداء التساؤلات، وسرعة تحصيل البيانات. في نظام البيانات الكبيرة، تستخدم أنماط الأعمدة المتوسطة مثل Parquet و ORC وأنماط الأسطر المتوسطة مثل Avro بسبب تحسينها لأداء الأعمال المعينة للتساؤلات والمهام التحليلية.
- Parquet: Parquet هي تخزين أعمدي متكامل للقراءة الكبيرة والتحليل. إنه فعال جداً فيما يتعلق بالتكسير والترميز، مما يجعله مناسبًا للحالات التي يتم تعزيز أداء القراءة والفاعلية المتكاملة.
- Avro: Avro هو ت
- ORC (Optimized Row Columnar): ORC هو تنسيق تخزين الأعمدة مماثل لـParquet لكنه محسن للعمليات القراءة والكتابة، يمتاز ORC بكفاءة عالية فيما يتعلق بالضغط، مما يقلل من تكاليف التخزين ويسرع استرجاع البيانات.
الهدف البحثي
الهدف الرئيسي من هذه البحثة هو تقييم كيفية تأثير تنسيقات التخزين المختلفة (Parquet, Avro, ORC) على أداء الاستعلامات وتكاليفها في البينات الكبيرة. هذه الورقة تهدف إلى توفير معاير لأنواع الاستعلامات المختلفة وحجمات البيانات لمساعدة مهندسي البيانات والمهندسين المعماريين في إختيار التنسيق الأكثر مناسباً للحالات التي يواجهونها.
إعداد التجربة
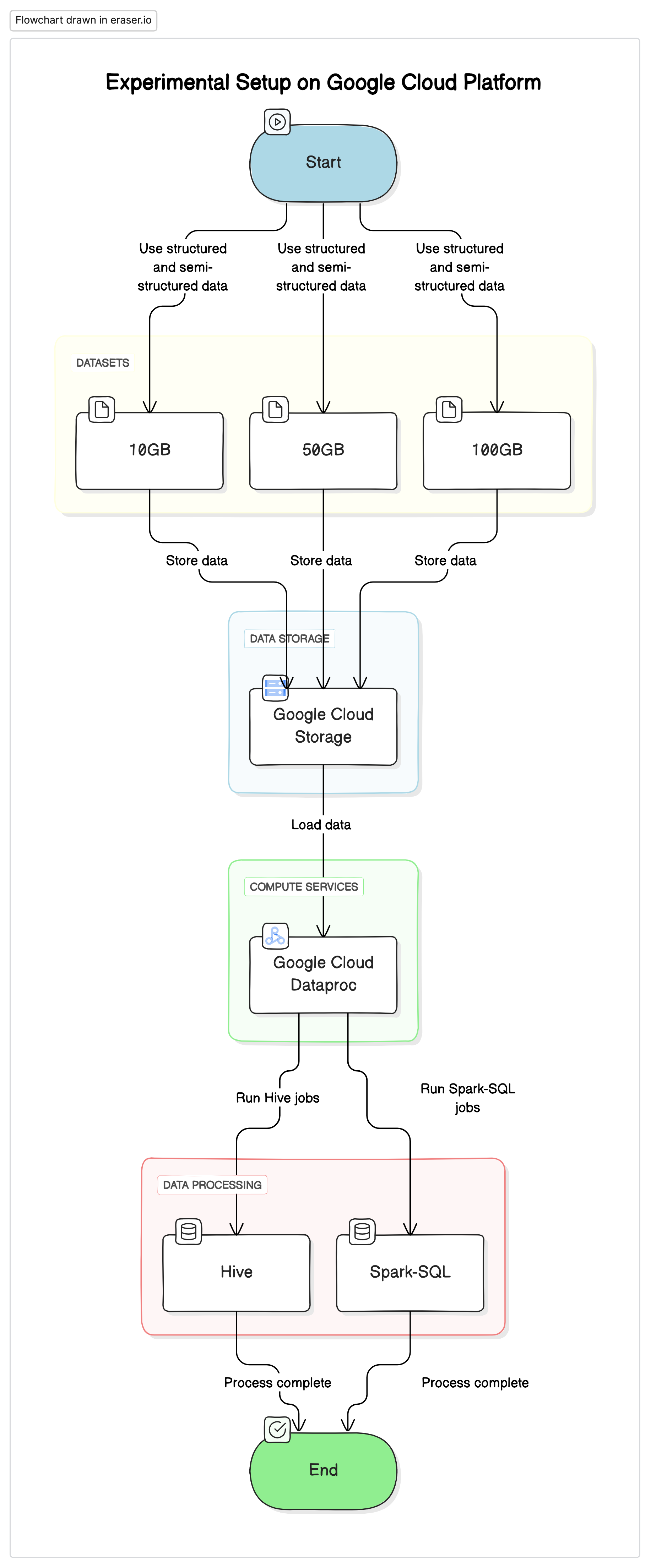
لإجراء هذه البحثة، قمنا باستخدام إعداد موحد على منصة Google Cloud (GCP) مع خزانة Google Cloud Storage كمخزن البيانات وخدمة Google Cloud Dataproc لتشغيل وظائف Hive و Spark-SQL. البيانات المستخدمة في التجارب كانت مزيج من البيانات المنظمة والبيانات النصف المنظمة لمحاكاة السيناريوهات الواقعية.
العناصر الرئيسية
- Google Cloud Storage: تستخدم لتخزين مجموعات البيانات بتنسيقات مختلفة (Parquet, Avro, ORC)
- Google Cloud Dataproc: خدمة مدارة Apache Hadoop و Apache Spark تستخدم لتشغيل وظائف Hive و Spark-SQL.
- مجموعات البيانات: ثلاث مجموعات بيانات من حجمات مختلفة (10GB, 50GB, 100GB) بأنواع البيانات المختلطة.
# Initialize PySpark and set up Google Cloud Storage as file system
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("BigDataQueryPerformance") \
.config("spark.jars.packages", "com.google.cloud.bigdataoss:gcs-connector:hadoop3-2.2.5") \
.getOrCreate()
# Configure the access to Google Cloud Storage
spark.conf.set("fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem")
spark.conf.set("fs.gs.auth.service.account.enable", "true")
spark.conf.set("google.cloud.auth.service.account.json.keyfile", "/path/to/your-service-account-file.json")
الاستعلامات الاختبارية
- استعلامات SELECT البسيطة: الاستخراج الأساسي لجميع الأعمدة من جدول
- استعلامات الفلترة: استعلامات SELECT مع شروط WHERE لتصفية صفوف معينة
- استعلامات التجميع: الاستعلامات التي تتضمن GROUP BY والدوال التجميعية مثل SUM وAVG وغيرها.
- استعلامات الانضمام: الاستعلامات التي تنضم فيها جدولين أو أكثر على مفتاح مشترك
النتائج والتحليل
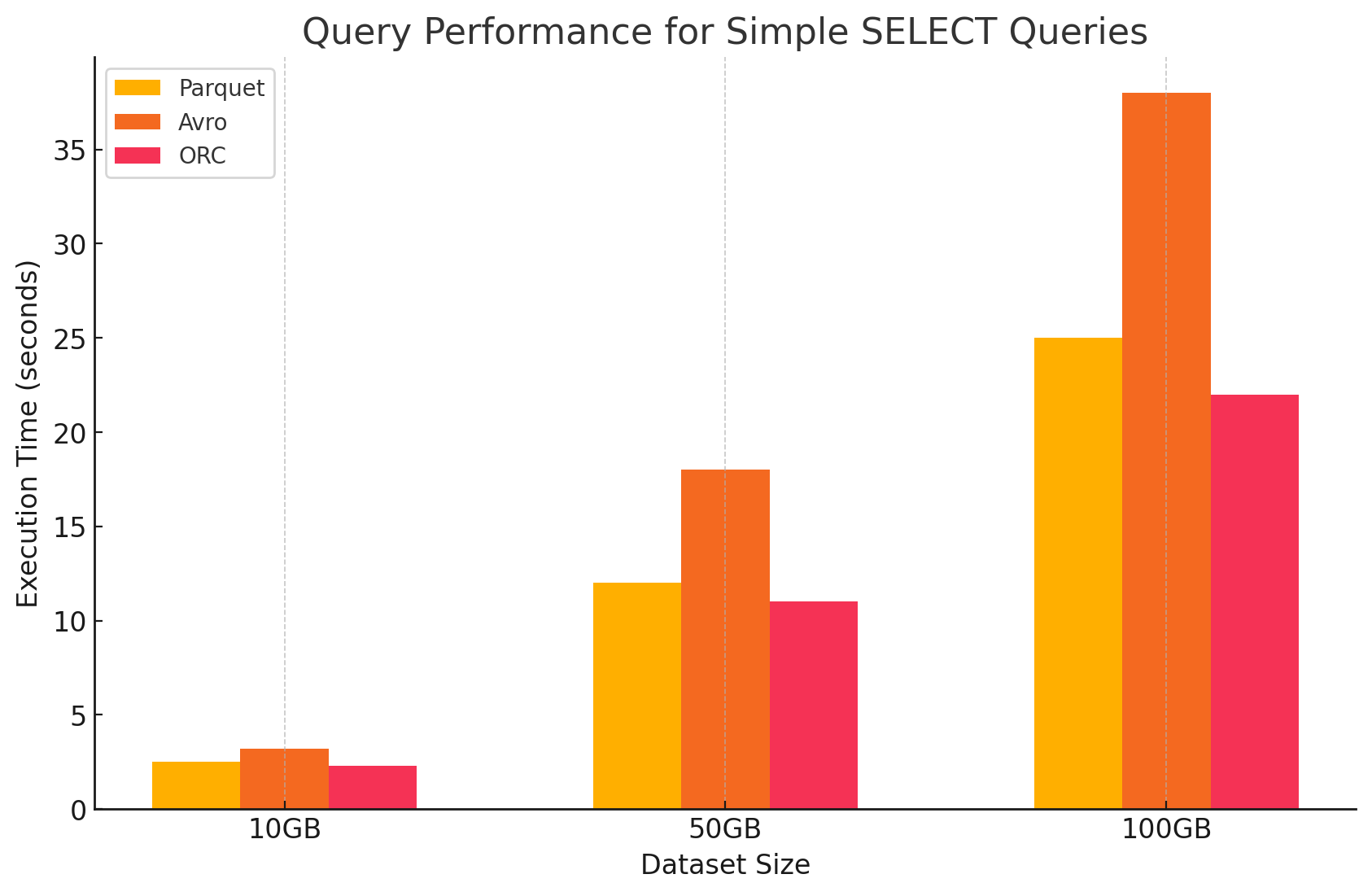
1. استعلامات SELECT البسيطة
- Parquet:أداءه كان ممتازًا بفضل تنسيق التخزين العمودي الذي يسمح بالمسح السريع للأعمدة المحددة. ملفات Parquet مضغوطة للغاية، مما يقلل من كمية البيانات المقروءة من القرص، مما يؤدي إلى تسريع وقت تنفيذ الاستعلامات.
# Simple SELECT query on Parquet file
parquet_df.select("column1", "column2").show()
- Avro:أداء Avro كان معتدلًا. كونه تنسيقًا قائمًا على الصفوف، تطلب Avro قراءة الصف بأكمله حتى عند الحاجة إلى أعمدة محددة فقط. هذا يزيد من عمليات الإدخال/الإخراج، مما يؤدي إلى أداء استعلام أبطأ مقارنة بـ Parquet و ORC.
-- Simple SELECT query on Avro file in Hive
CREATE EXTERNAL TABLE avro_table
STORED AS AVRO
LOCATION 'gs://your-bucket/dataset.avro';
SELECT column1, column2 FROM avro_table;
- ORC: ORC أظهر أداءً مشابهًا لـ Parquet، مع ضغط أفضل قليلاً وتقنيات تخزين محسنة تعزز من سرعة القراءة. ملفات ORC أيضًا عمودية، مما يجعلها مناسبة لاستعلامات SELECT التي تستخرج أعمدة محددة فقط.
# Simple SELECT query on ORC file
orc_df.select("column1", "column2").show()
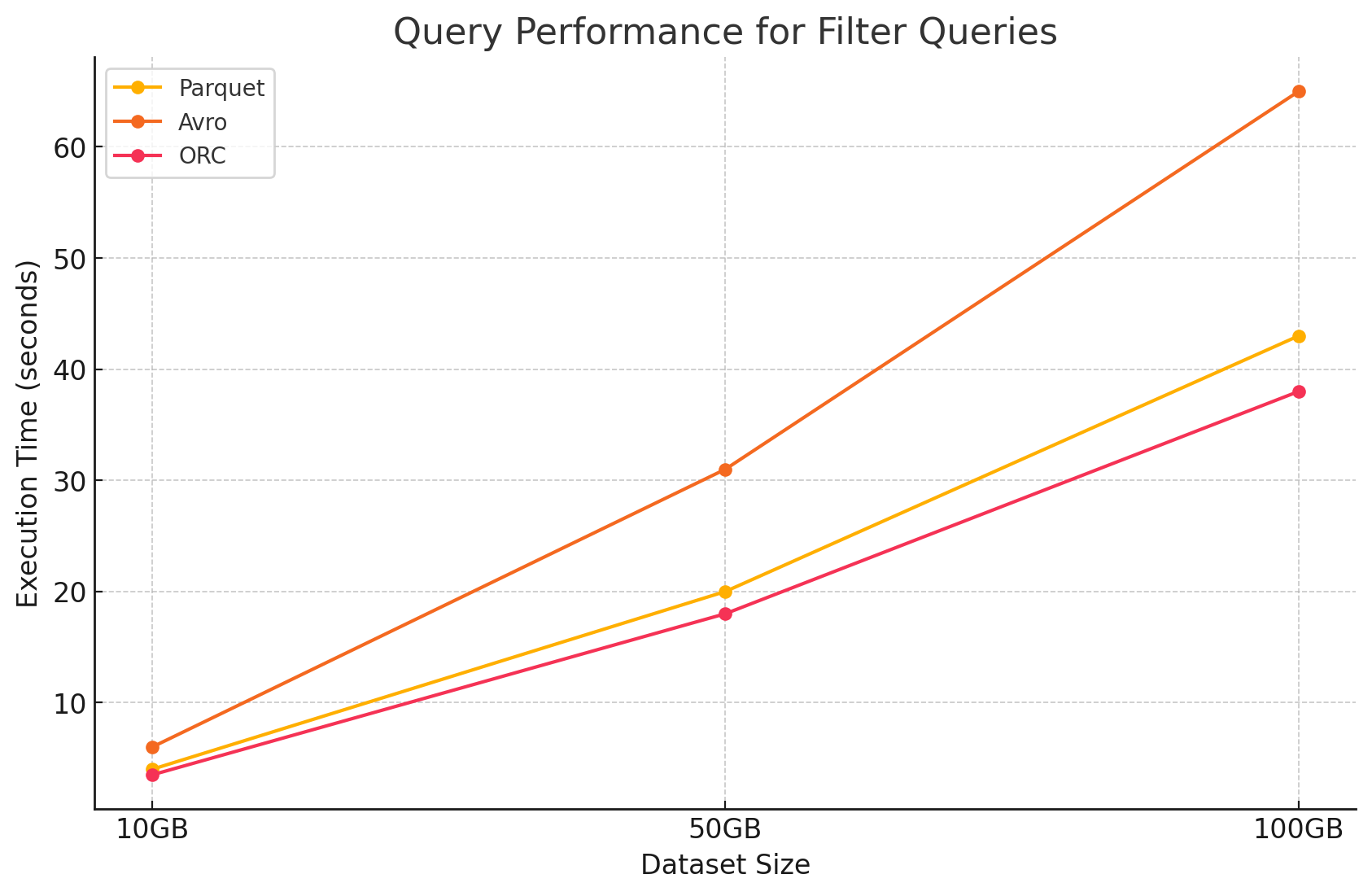
2. استعلامات الفلترة
- Parquet: حافظ Parquet على ميزة أدائه بفضل طبيعته العمودية وقدرته على تجاوز الأعمدة غير ذات الصلة بسرعة. ومع ذلك، تأثر الأداء قليلاً بسبب الحاجة إلى مسح المزيد من الصفوف لتطبيق الفلاتر.
# Filter query on Parquet file
filtered_parquet_df = parquet_df.filter(parquet_df.column1 == 'some_value')
filtered_parquet_df.show()
- أفرو: تدهورت الأداء بشكل أكبر بسبب الحاجة إلى قراءة الصفوف الكاملة وتطبيق الفلاتر عبر جميع الأعمدة، مما أدى إلى زيادة وقت المعالجة.
-- Filter query on Avro file in Hive
SELECT * FROM avro_table WHERE column1 = 'some_value';
- أو أم آر سي: قام بأداء أفضل قليلاً من باركيت في الاستعلامات الفلاتريّة بفضل خاصيتها المتقدمة بالمنطقة التي تسمح بالفلاترة مباشرة على مستوى التخزين قبل تحميل البيانات إلى الذاكرة.
# Filter query on ORC file
filtered_orc_df = orc_df.filter(orc_df.column1 == 'some_value')
filtered_orc_df.show()
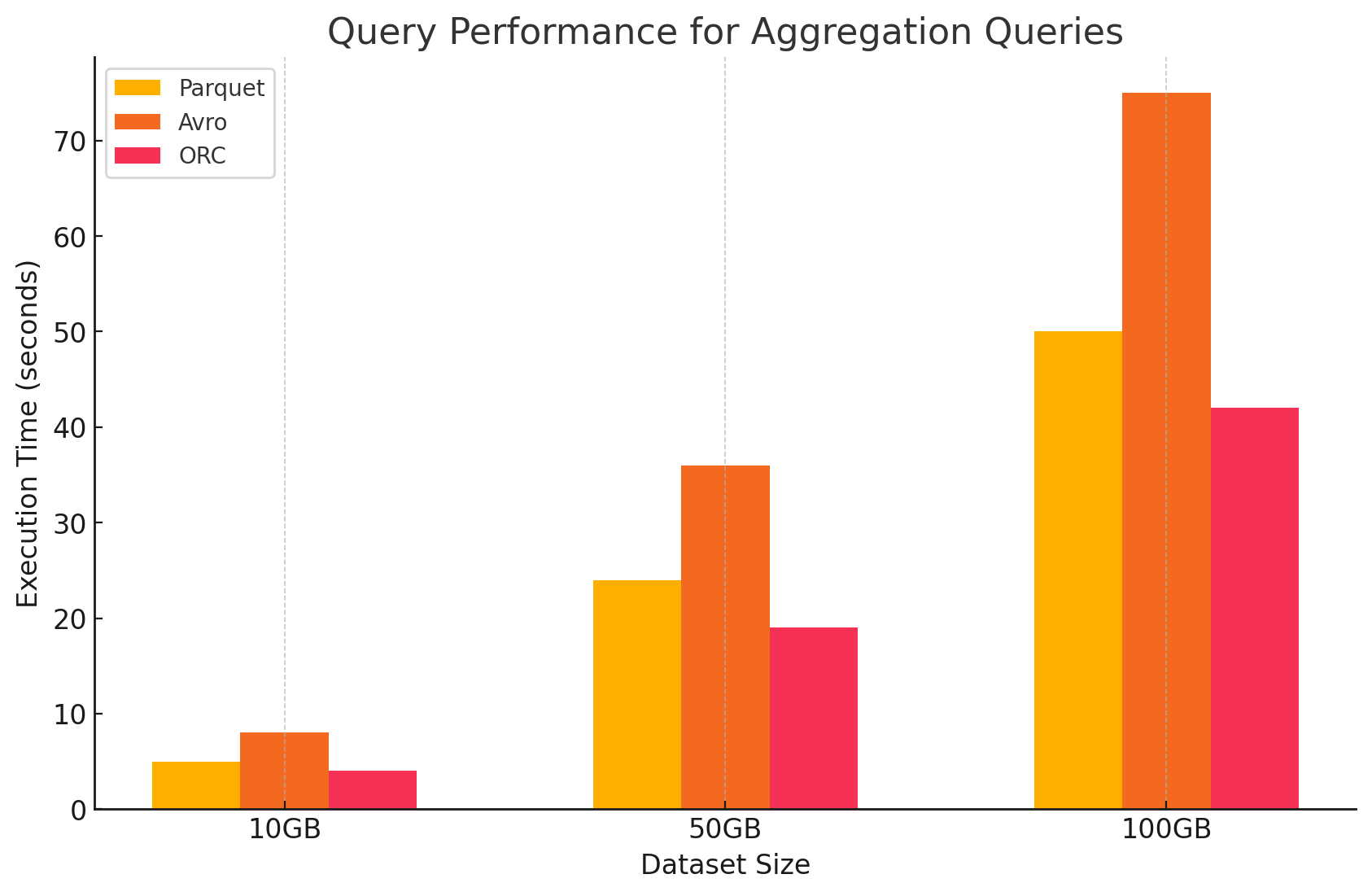
3. الاستعلامات التجميعية
- باركيت: أدى باركيت بشكل جيد، لكن أقل أداءً قليلاً من أو أم آر سي. يمكن لصيغة الأعمدة أن تفيد عمليات التجميع بالوصول بسرعة إلى الأعمدة المطلوبة، لكن باركيت يفتقد بعض تحسينات الأساس التي يقدمها أو أم آر سي.
# Aggregation query on Parquet file
agg_parquet_df = parquet_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_parquet_df.show()
- أفرو: لقد تم إتباع أفرو بعيداً بسبب تخزينها القائم على الصفوف، الذي كان يتطلب قراءة ومعالجة جميع الأعمدة لكل صف، مما أدى إلى زيادة الحمولة الحسابية.
-- Aggregation query on Avro file in Hive
SELECT column1, SUM(column2), AVG(column3) FROM avro_table GROUP BY column1;
- أو أم آر سي: قام أو أم آر سي بأداء أفضل من باركيت وأفرو في الاستعلامات التجميعية. استفادة أو أم آر سي من الفلاترة المتقدمة وخوارزميات الضغط الداخلية المتقدمة أدت إلى الوصول السريع إلى البيانات وتقليل عمليات الإدخال/الخروج، مما جعلها مناسبة للغاية لمهمات التجميع.
# Aggregation query on ORC file
agg_orc_df = orc_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_orc_df.show()
4. الاستعلامات الدالة
- باركيت: أدى باركيت بشكل جيد، لكن ليس بأداءٍ كافٍ كما يفعل أو أم آر سي في عمليات الدالة بسبب قراءة البيانات الأقل تحسينًا لشروط الدالة.
# Join query between Parquet and ORC files
joined_df = parquet_df.join(orc_df, parquet_df.key == orc_df.key)
joined_df.show()
- أو أم آر سي: أشرف أو أم آر سي في الاستعلامات الدالة، مما استفاد من قدرات الفلاترة المتقدمة وخاصيات دفع الشروط إلى الأسفل، والتي أقللت من البيانات التي يت
# Join query between two ORC files
joined_orc_df = orc_df.join(other_orc_df, orc_df.key == other_orc_df.key)
joined_orc_df.show()
- أفرو: أفرو قد تعانى بشكل كبير من عمليات الإنضمام، وهذا بالأساس بسبب العبء العالي لقراءة الصفوف الكاملة وعدم تحسينات العمودية لمفاتيح الإنضمام.
-- Join query between Parquet and Avro files in Hive
SELECT a.column1, b.column2
FROM parquet_table a
JOIN avro_table b
ON a.key = b.key;
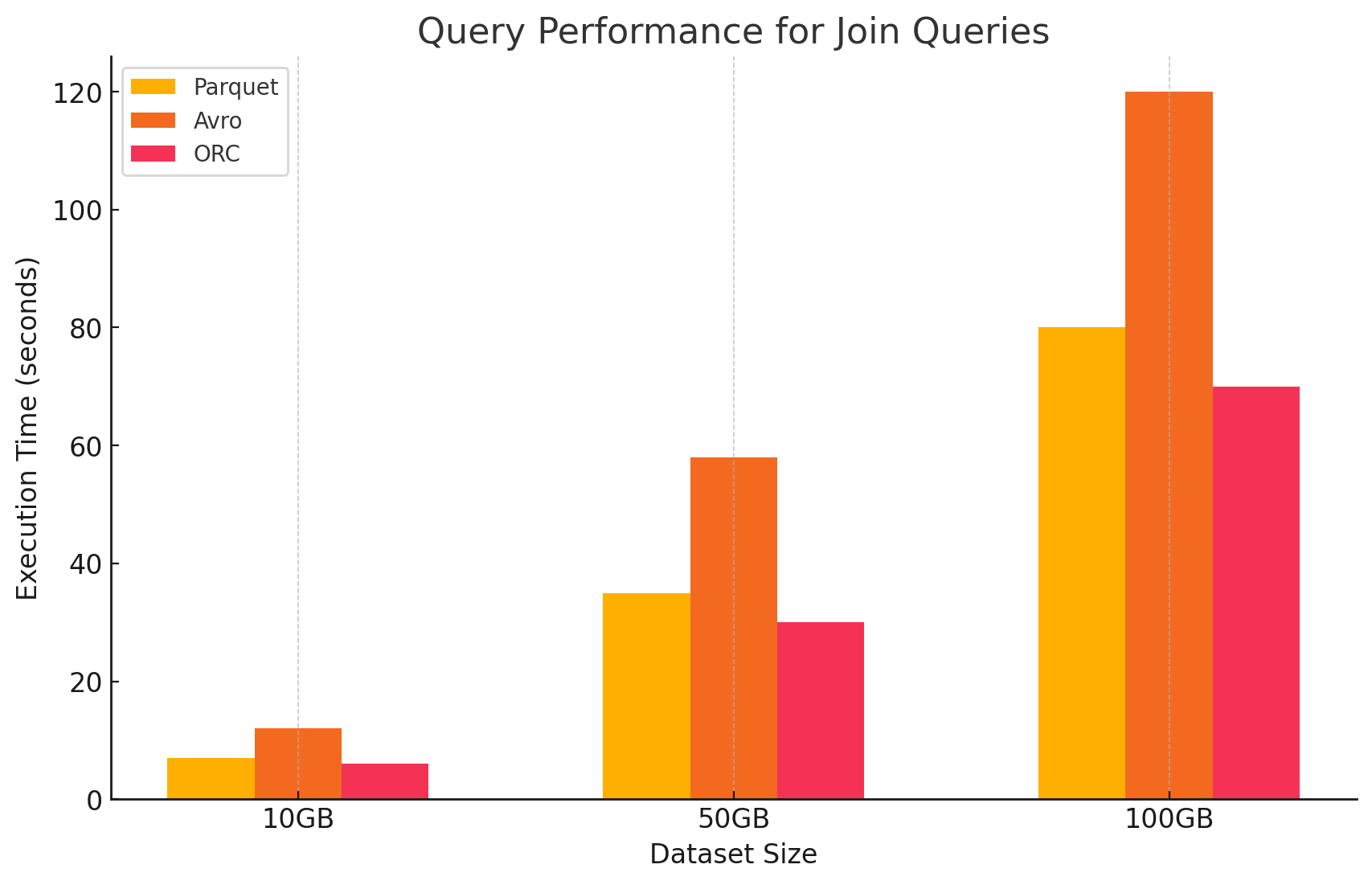
تأثير تنسيق التخزين على التكاليف
1. كفاءة التخزين وتكاليفه
- باركيوت وأورك (أشكال التخزين العمودية)
التمثيل وتكاليف التخزين: باركيوت وأورك هما أشكال التخزين العمودية التي توفر نسب تمثيل عالية، خاصةً لمجموعات البيانات التي تحتوي على الكثير من القيم المتكررة أو المشابهة داخل العمود. هذا التمثيل العالي يقلل من حجم البيانات الكلي، وبالتالي يخفض من تكاليف التخزين، وخاصةً في البيئات السحابية حيث يقبل تحصيل التخزين بالجيغابايت.
أمثل لأحمال العمل التحليلي: بسبب طبيعتهما العمودية، هذه الأشكال مثالية لأحمال العمل التحليلية التي يتم استعلام العمودات الخاصة بصفة دورية. هذا يعني قراءة القليل من البيانات من التخزين، مما يقلل من عمليات الإدخال والإخراج وتكاليفها. - Avro (تنسيق يعتمد على الصفوف)
- تكلفة الضغط والتخزين: عادةً ما يوفر Avro نسب ضغط أقل مقارنة بالتنسيقات العمودية مثل Parquet وORC لأنه يخزن البيانات صفًا بصف. هذا يمكن أن يؤدي إلى تكاليف تخزين أعلى، خاصةً بالنسبة لمجموعات البيانات الكبيرة التي تحتوي على العديد من الأعمدة، حيث يجب قراءة جميع البيانات في الصف حتى إذا كانت هناك حاجة إلى بعض الأعمدة فقط.
- أفضل للعمليات التي تتطلب كتابة كثيفة: على الرغم من أن Avro قد يؤدي إلى تكاليف تخزين أعلى بسبب الضغط الأقل، إلا أنه مناسب أكثر للعمليات التي تتطلب كتابة كثيفة حيث يتم كتابة البيانات أو إضافتها باستمرار. يمكن تعويض التكلفة المرتبطة بالتخزين بالتحسينات في كفاءة تسلسل البيانات وإلغاء التسلسل.
2. أداء معالجة البيانات والتكلفة
- Parquet و ORC (تنسيقات عمودية)
- خفض تكاليف المعالجة: تم تحسين هذه التنسيقات للعمليات التي تعتمد على القراءة بكثافة، مما يجعلها فعالة للغاية في استعلام مجموعات البيانات الكبيرة. لأنها تسمح بقراءة الأعمدة ذات الصلة فقط المطلوبة للاستعلام، فإنها تقلل من كمية البيانات المعالجة. يؤدي هذا إلى تقليل استخدام وحدة المعالجة المركزية وتسريع أوقات تنفيذ الاستعلام، مما يمكن أن يقلل بشكل كبير من تكاليف الحوسبة في بيئة السحابة حيث يتم فوترة موارد الحوسبة بناءً على الاستخدام.
- ميزات متقدمة لتحسين التكلفة: يتضمن ORC، على وجه الخصوص، ميزات مثل الدفع بالتوقع والإحصائيات المدمجة، التي تمكن محرك الاستعلام من تخطي قراءة البيانات غير الضرورية. هذا يقلل من عمليات الإدخال والإخراج بشكل أكبر ويزيد من سرعة أداء الاستعلام، مما يؤدي إلى تحسين التكاليف.
- أفرو (تنسيقات مبنية على الصفوف)
- تكاليف معالجة عالية: لأن أفرو هو تنسيق مبني على الصفوف، فهو يتطلب عموماً عمليات إدخال/إخراج إضافية لقراءة الصفوف بأكملها حتى عندما يكون الحاجة إلى بضعة أعمدة فقط. هذا قد يؤدي إلى زيادة تكاليف الحوسبة بسبب استخدام المعالج أعلى وزيادة أوقات تنفيذ الاستعلامات، خاصة في البيئات التي تحمل الكثير من القراءات.
- فعالية للتدفق والتسلسل: بغض النظر عن تكاليف معالجة الاستعلامات العالية، فإن أفرو ملائم لمهام التدفق والتسلسل حيث السرعة العالية في الكتابة وتطور المخططات أكثر أهمية.
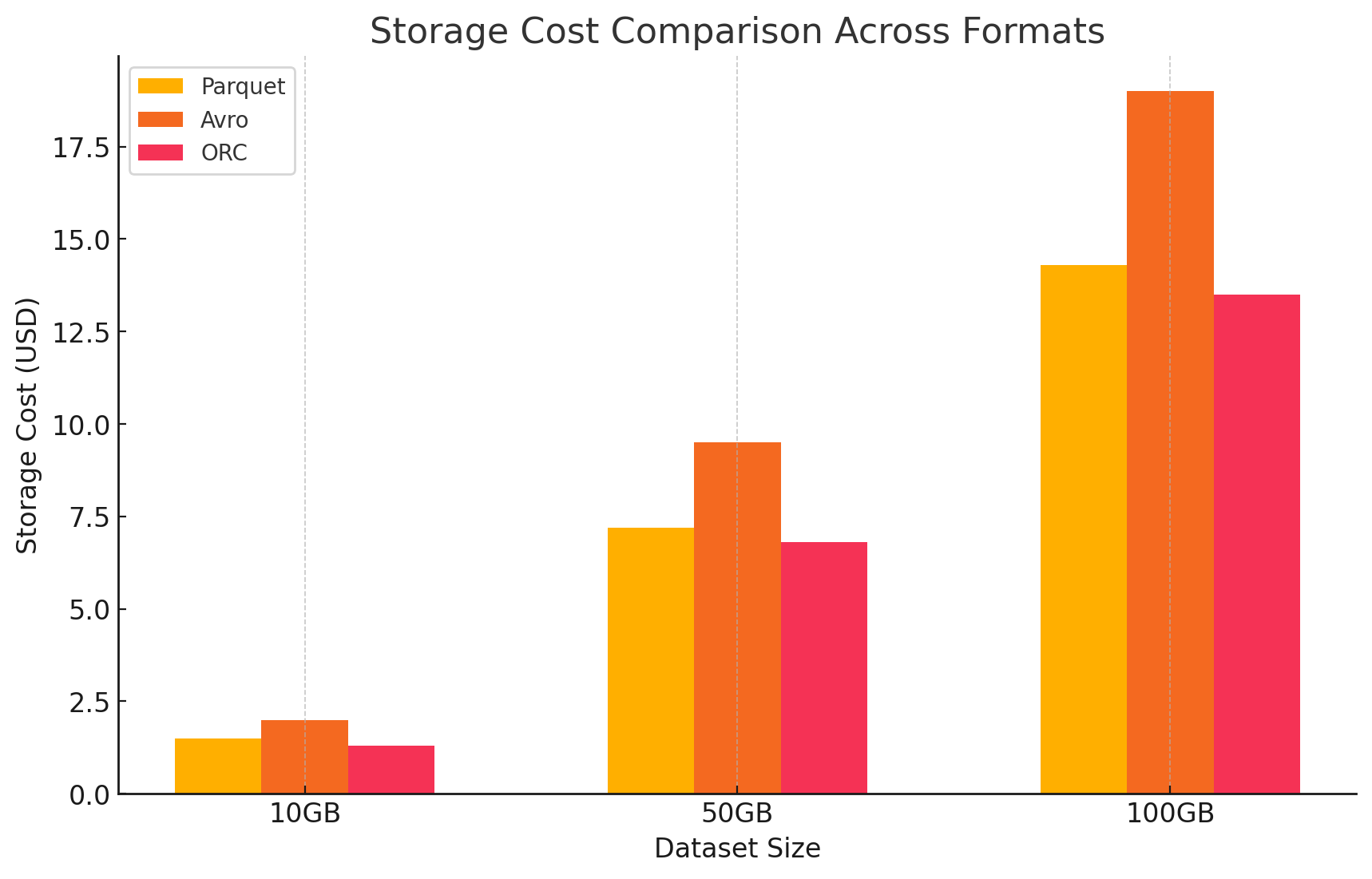
3. تحليل التكاليف مع تفاصيل التسعير
- لتوضيح تأثير كل تنسيق تخزين، قمنا بتجربة باستخدام GCP. حسبنا التكاليف المرتبطة بالتخزين ومعالجة البيانات لكل تنسيق وفقاً لنماذج تسعير GCP.
- تكاليف تخزين السحابة التي تقوم بها Google
- تكاليف التخزين: وهي محاسبة بناءا على كمية البيانات المتخزنة في كل تشكيل. يتم تسكير GCP بمعدل قيمة بتشكيل البيانات في السحابة التي تقوم بها Google لكل مائة جيب في الشهر. يؤثر معدلات التكامل التي يحققها كل تشكيل بشكل مباشر على تلك التكاليف. تشكيلات الأعمدة مثل Parquet و ORC تحصل على معدلات تكامل أفضل من تشكيلات الأسطر مثل Avro، وهذا يقلل من التكاليف التخزينية.
- هذه معطية مثالية لكيفية حساب التكاليف التخزينية:
- Parquet: وجد تكامل عالٍ يؤدي إلى تكاليف أصغر للبيانات، وهذا يخفض التكاليف التخزينية
- ORC: مثل Parquet، يوفر ORC تكامل متقدم أيضًا ويقلل من التكاليف التخزينية بشكل فعال
- Avro: وجد فعالية منخفضة للتكامل تمنح تكاليف أكثر من Parquet و ORC
# Example of how to save data back to Google Cloud Storage in different formats
# Save DataFrame as Parque
parquet_df.write.parquet("gs://your-bucket/output_parquet")
# Save DataFrame as Avro
avro_df.write.format("avro").save("gs://your-bucket/output_avro")
# Save DataFrame as ORC
orc_df.write.orc("gs://your-bucket/output_orc")
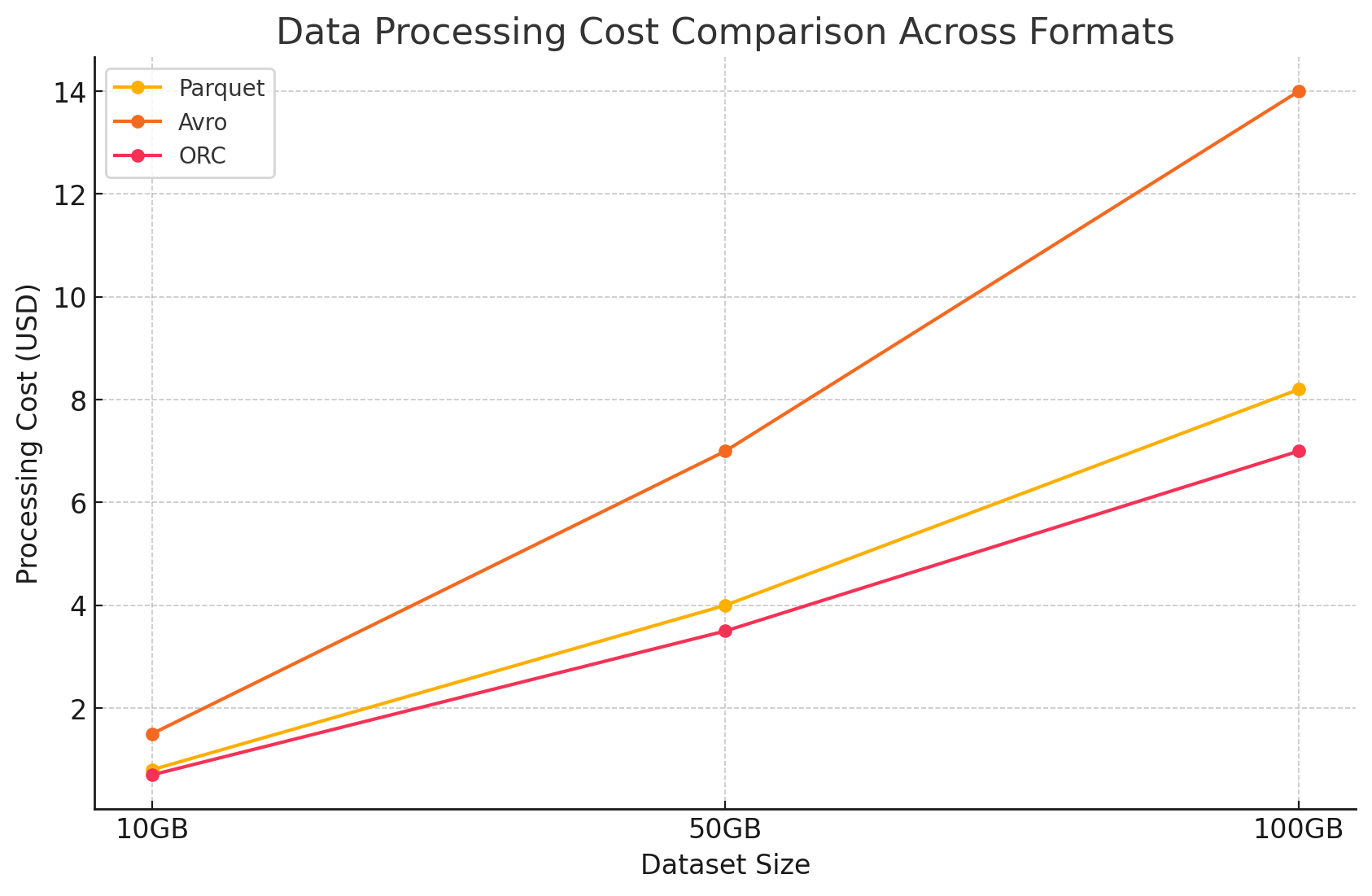
- تكاليف معالجة البيانات
- تم حساب تكاليف معالجة البيانات وفقاً للموارد المعالجة المطلوبة للقيام بمجموعة من الاستعمالات المختلفة بواسطة Dataproc على GCP. تطبق GCP رسومات لاستخدام Dataproc وفقاً لحجم المجموعة ومدة استخدام الموارد.
- تكاليف المعالجة:
- Parquet و ORC: وبسبب تخزينهم التجزئي الفعال، تلك الأنماط قللت من كمية البيانات التي تم قراءتها ومعالجتها، مما أدى إلى خفض تكاليف المعالجة. أيضًا ساعات تنفيذ الاستعمالات الأسرع ساهمت في توفير التوفيرات، بالأهمية للاستعمالات المعقدة التي تتضمن قاعدات كبيرة.
- Avro: أحتاج أكثر موارد معالجة بسبب تشكيله ال基于行为, الذي يزيد من كمية البيانات التي تم قراءتها ومعالجتها. هذا أدى إلى زيادة تكاليفه، وخاصة للأعمال القاطعة بالقراءة.
ختام
الاختيار الذي يتم إجراءه لتنسيق التخزين في بيئات البيانات الضخمة يؤثر بشكل كبير على أداء الاستعلام والتكاليف. البحث والتجربة السابقين يظهرون النقاط الرئيسية التالية:
- Parquet و ORC: هذان التنسيقات العمودية توفر تضغيضاً ممتازاً، والذي يقلل من تكاليف التخزين. قدرتهما على قراءة العمودات الضرورية بكفاءة يعزز من أداء الاستعلام ويرتفع من تكاليف معالجة البيانات. ORC يفوق Parquet بشكل ما في أنواع معينة من الاستعلامات بسبب ميزاته القائمة على التصنيف المتقدم والتحسين، مما يجعلها خياراً ممتازاً للمحملات المختلطة التي تتطلب أداء القراءة والكتابة عالياً.
- Avro: بينما لا يكون Avro بنفس الكفاءة فيما يتعلق بالتضغيض وأداء الاستعلام مثل Parquet و ORC، فهو يتميز في حالات الاستخدام التي تتطلب عمليات الكتابة السريعة وتطور المخطط. هذا التنسيق المثالي للسيناريوهات التي تتضمن تسلسل البيانات والتدفق حيث يتم التركيز على أداء الكتابة والمرونة على حد سواء من الكفاءة في القراءة.
- الكفاءة التكاليفية: في بيئة السحب السعرية مثل GCP، حيث تكمن التكاليف في الواقع بالقرب من استخدام التخزين والحوسبة، يمكن لاختيار التنسيق الصحيح أن يؤدي إلى توفير كبير في التكاليف. للمحملات التحليلية التي تتميز بالقراءة الكبيرة، Parquet و ORC هما الخيارات الأكثر كفاءة تكاليفياً. للتطبيقات التي تتطلب إمداد البيانات السريع وإدارة المخططات المرنة، Avro يعتبر خيار مناسب بغض النظر عن تكاليف التخزين والحوسبة الأعلى.
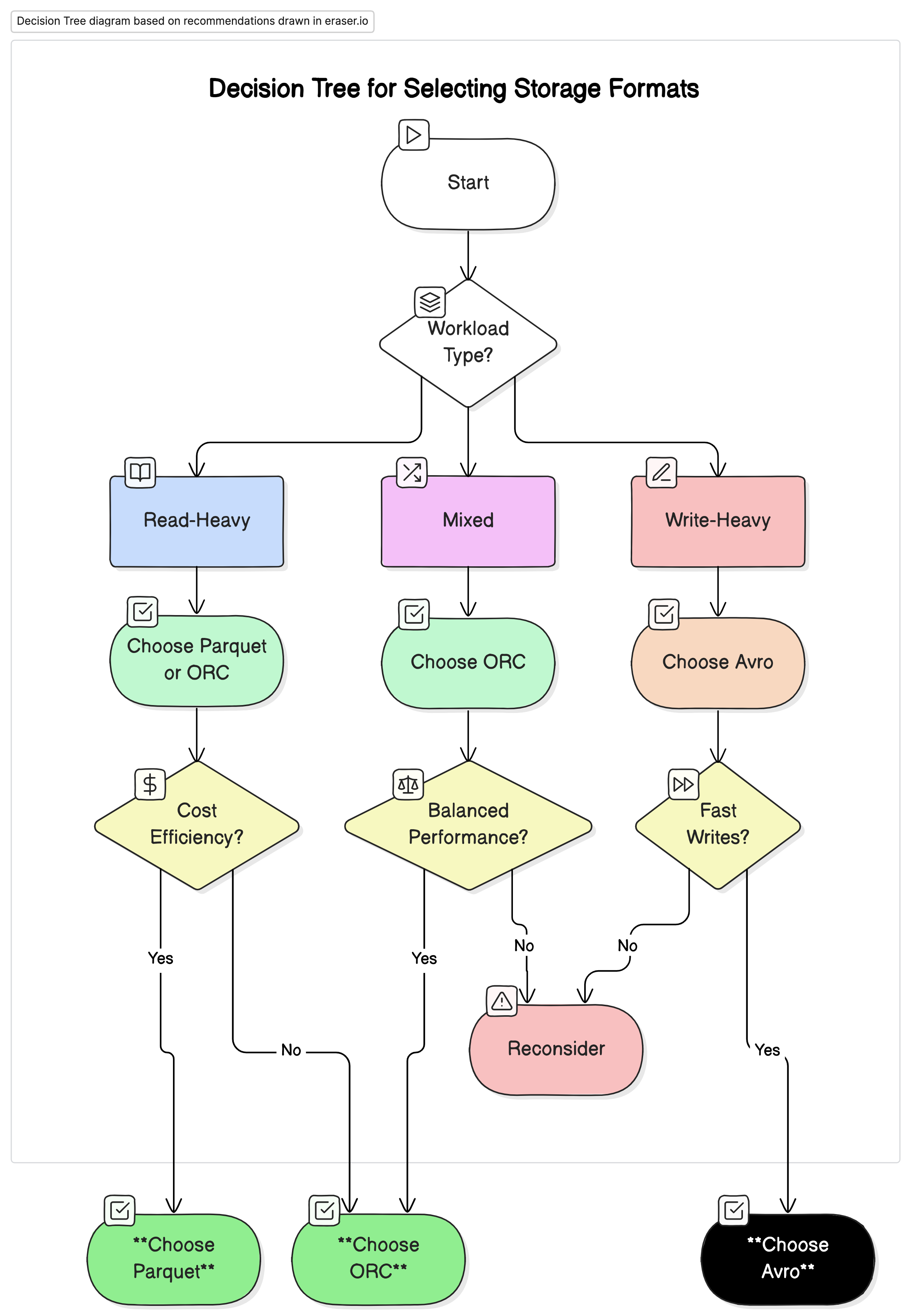
التوصيات
بناء على تحليلنا، نوصي بما يلي:
- للحملات التحليلية الكثيرة القراءة: استخدم Parquet أو ORC. تتمكن هذه الأشكال من تقديم أداء جيد وتكاليف معقولة بسبب الضغط العالي وأداء الاستعلام المحسن.
- للحملات الكثيرة الكتابة والتسلسل: استخدم Avro. هو أكثر مناسبية للسيناريوهات التي تتمحور حول الكتابة السريعة وتطور المخططات، مثل تدفق البيانات وأنظمة الرسائل.
- للحملات المزدوجة: ORC يقدم أداء متوازن للعمليات القراءة والكتابة، مما يجعله خيار مثالي للبيئات التي تتنوع في حملات البيانات.
الافكار النهائية
اختيار الشكل المناسب لتخزين البيانات في البيئات الكبيرة للبيانات هو أمرٌ حاسم لتحسين الأداء والتكاليف. فهم قوايا وضعف كل شكل يسمح لمهندسي البيانات بتخصيص هيكلة البيانات للحالات المحددة، مما يوفر الكفاءة ويقلل من التكاليف. وبما أن حجم البيانات يواصل النمو، فإن قراراتنا المستنيرة بشأن أشكال التخزين ستصبح أكثر أهمية بالمرة لإبقاء حلول البيانات قابلة للتطوير وتكاليفها معقولة.
بتقييم دقيق للمؤشرات الأساسية للأداء وآثار التكاليف المعروفة في هذه المقالة، يمكن للمنظمات أن تختار التشكيل التخزيني الأكثر توافقًا مع احتياجاتهم التشغيلية وأهدافهم المالية.
Source:
https://dzone.com/articles/performance-and-cost-implications-parquet-avro-orc