













Le traitement efficace des données est crucial pour les entreprises et organisations qui font appel à l’analyse des grands volumes de données pour prendre des décisions informées. Un facteur clé qui affecte significativement le rendement du traitement des données est le format de stockage des données. Cet article explore l’impact de différents formats de stockage, notamment Parquet, Avro et ORC, sur le rendement des requêtes et les coûts dans les environnements de grands volumes de données sur la plateforme Google Cloud Platform (GCP). Cet article fournit des benchmarks, discute des incidences sur les coûts et offre des recommandations sur la sélection du format approprié en fonction de cas d’utilisation spécifiques.
Introduction aux formats de stockage dans les grands volumes de données
Les formats de stockage des données sont le pilier de tout environnement de traitement de grands volumes de données. Ils définissent comment les données sont stockées, lues et écrites, impactant directement l’efficacité de stockage, le rendement des requêtes et la vitesse de récupération des données. Dans l’écosystème des grands volumes de données, les formats colonnaires tels que Parquet et ORC et les formats de lignes tels que Avro sont largement utilisés en raison de leur optimisation pour certains types de requêtes et de tâches de traitement spécifiques.
- Parquet :Parquet est un format de stockage colonnaire optimisé pour les opérations de lecture intensives et l’analyse. Il est hautement efficient en matière de compression et d’encodage, ce qui le rend idéal pour les scénarios où la performance de lecture et l’efficacité de stockage sont prioritaires.
- Avro :Avro est un format de stockage de lignes conçu pour la serialisation des données. Il est connu pour ses capacités d’évolution du schéma et est souvent utilisé pour les opérations de stockage intensives où les données doivent être serialisées et déserialisées rapidement.
- ORC (Optimized Row Columnar) :ORC est un format de stockage en colonnes similaire à Parquet, mais optimisé pour les opérations d’écriture et de lecture. ORC est très efficace en matière de compression, ce qui réduit les coûts de stockage et accélère la récupération des données.
Objectif de recherche
L’objectif principal de cette recherche est d’évaluer comment différents formats de stockage (Parquet, Avro, ORC) influent sur la performance des requêtes et les coûts dans les environnements big data. Cet article vise à fournir des benchmarks basés sur divers types de requêtes et des volumes de données pour aider les ingénieurs et architectes des données à choisir le format le plus adapté à leurs cas d’utilisation spécifiques.
Ensemble d’expériences
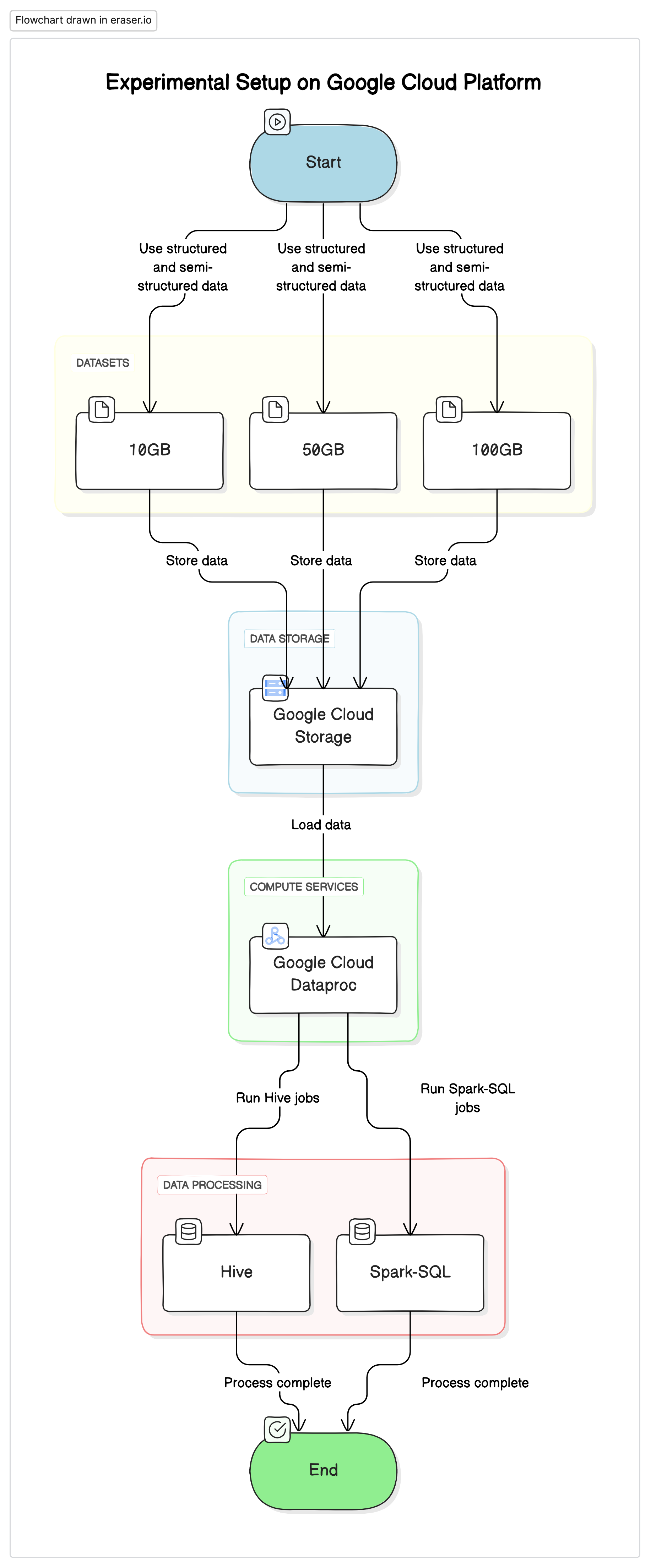
Pour mener cette recherche, nous avons utilisé un ensemble standardisé sur la Plateforme de services cloud Google (GCP), avec Google Cloud Storage comme référentiel de données et Google Cloud Dataproc pour exécuter les jobs Hive et Spark-SQL. Les données utilisées dans les expériences étaient une combinaison de jeux de données structurés et semi-structurés pour simuler des scénarios réels.
Composants clés
- Google Cloud Storage :Utilisé pour stocker les jeux de données dans différents formats (Parquet, Avro, ORC)
- Google Cloud Dataproc :Un service géré utilisant Apache Hadoop et Apache Spark pour exécuter les jobs Hive et Spark-SQL.
- Jeux de données :Trois jeux de données de tailles différentes (10GB, 50GB, 100GB) avec des types de données mixtes.
# Initialize PySpark and set up Google Cloud Storage as file system
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("BigDataQueryPerformance") \
.config("spark.jars.packages", "com.google.cloud.bigdataoss:gcs-connector:hadoop3-2.2.5") \
.getOrCreate()
# Configure the access to Google Cloud Storage
spark.conf.set("fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem")
spark.conf.set("fs.gs.auth.service.account.enable", "true")
spark.conf.set("google.cloud.auth.service.account.json.keyfile", "/path/to/your-service-account-file.json")
Requêtes d’essai.
- Requêtes SELECT simples :Récupération de toutes les colonnes d’une table
- Requêtes de filtrage :Requêtes SELECT avec des clauses WHERE pour filtrer des lignes spécifiques
- Requêtes d’agrégation :Requêtes impliquant des fonctions d’agrégation comme SUM, AVG, etc.
- Requêtes de jointure :Requêtes joignant deux ou plusieurs tables sur une clé commune
Résultats et Analyse
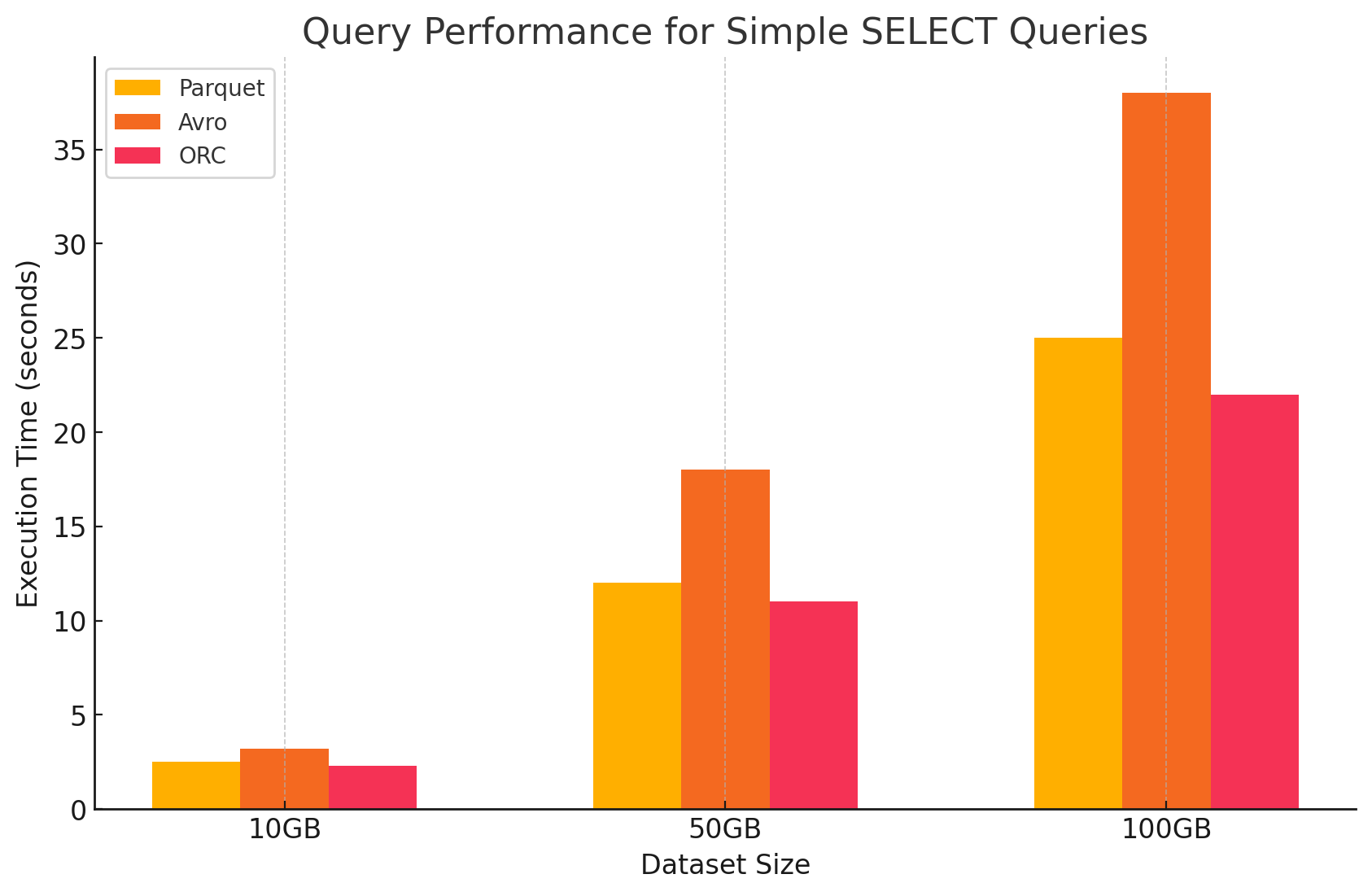
1. Requêtes SELECT simples
- Parquet :Il s’est montré exceptionnellement performant en raison de son format en colonnes, qui permettait un scan rapide de certaines colonnes. Les fichiers Parquet sont fortement compressés, réduisant le volume de données lues depuis le disque, ce qui a permis d’accélérer les temps d’exécution des requêtes.
# Simple SELECT query on Parquet file
parquet_df.select("column1", "column2").show()
- Avro :Avro a présenté des performances moyennes. En raison de son format basé sur les lignes, Avro a besoin de lire la ligne entière, même si seules certaines colonnes étaient nécessaires. Cela augmente les opérations I/O, conduisant à un ralentissement du débit de requête par rapport à Parquet et ORC.
-- Simple SELECT query on Avro file in Hive
CREATE EXTERNAL TABLE avro_table
STORED AS AVRO
LOCATION 'gs://your-bucket/dataset.avro';
SELECT column1, column2 FROM avro_table;
- ORC :ORC a montré des performances similaires à celles de Parquet, avec une compression légèrement meilleure et des techniques d’optimisation de stockage qui ont amélioré les vitesse de lecture. Les fichiers ORC sont également en colonnes, ce qui les rend adaptés pour les requêtes SELECT qui ne récupèrent que certaines colonnes.
# Simple SELECT query on ORC file
orc_df.select("column1", "column2").show()
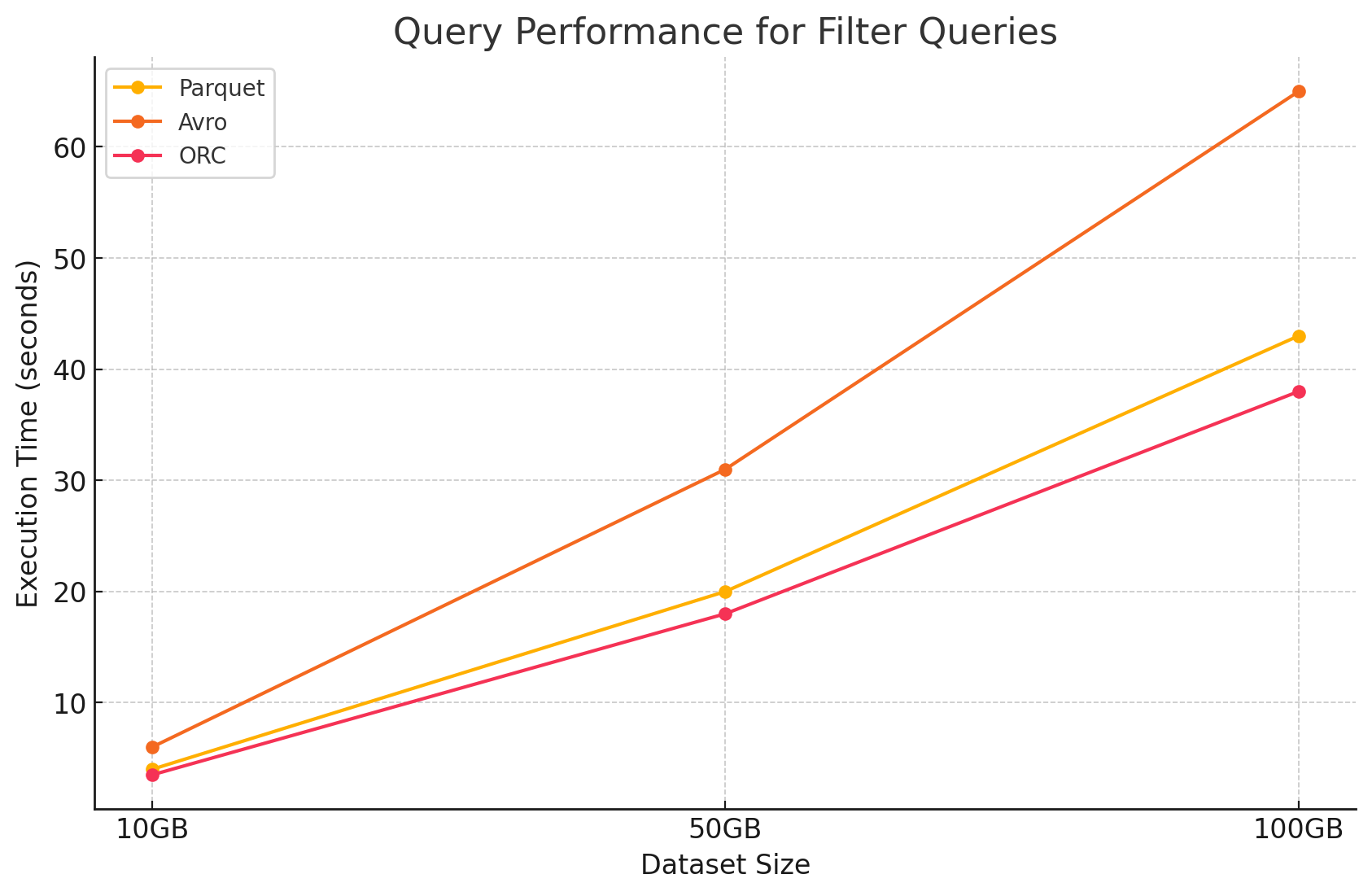
2. Requêtes de filtrage
- Parquet :Parquet a maintenu son avantage performant en raison de sa nature en colonnes et de la capacité de sauter rapidement les colonnes non pertinentes. Cependant, la performance a été légèrement impactée par la nécessité de scanner plus de lignes pour appliquer les filtres.
# Filter query on Parquet file
filtered_parquet_df = parquet_df.filter(parquet_df.column1 == 'some_value')
filtered_parquet_df.show()
- Avro :La performance a diminué davantage en raison de la nécessité de lire des rangées entières et d’appliquer des filtres sur toutes les colonnes, augmentant ainsi le temps de traitement.
-- Filter query on Avro file in Hive
SELECT * FROM avro_table WHERE column1 = 'some_value';
- ORC :Il a surpassé Parquet de peu dans les requêtes de filtrage en raison de sa fonction de pushdown des prédicats, qui permet de filtrer directement au niveau de stockage avant que les données ne soient chargées dans la mémoire.
# Filter query on ORC file
filtered_orc_df = orc_df.filter(orc_df.column1 == 'some_value')
filtered_orc_df.show()
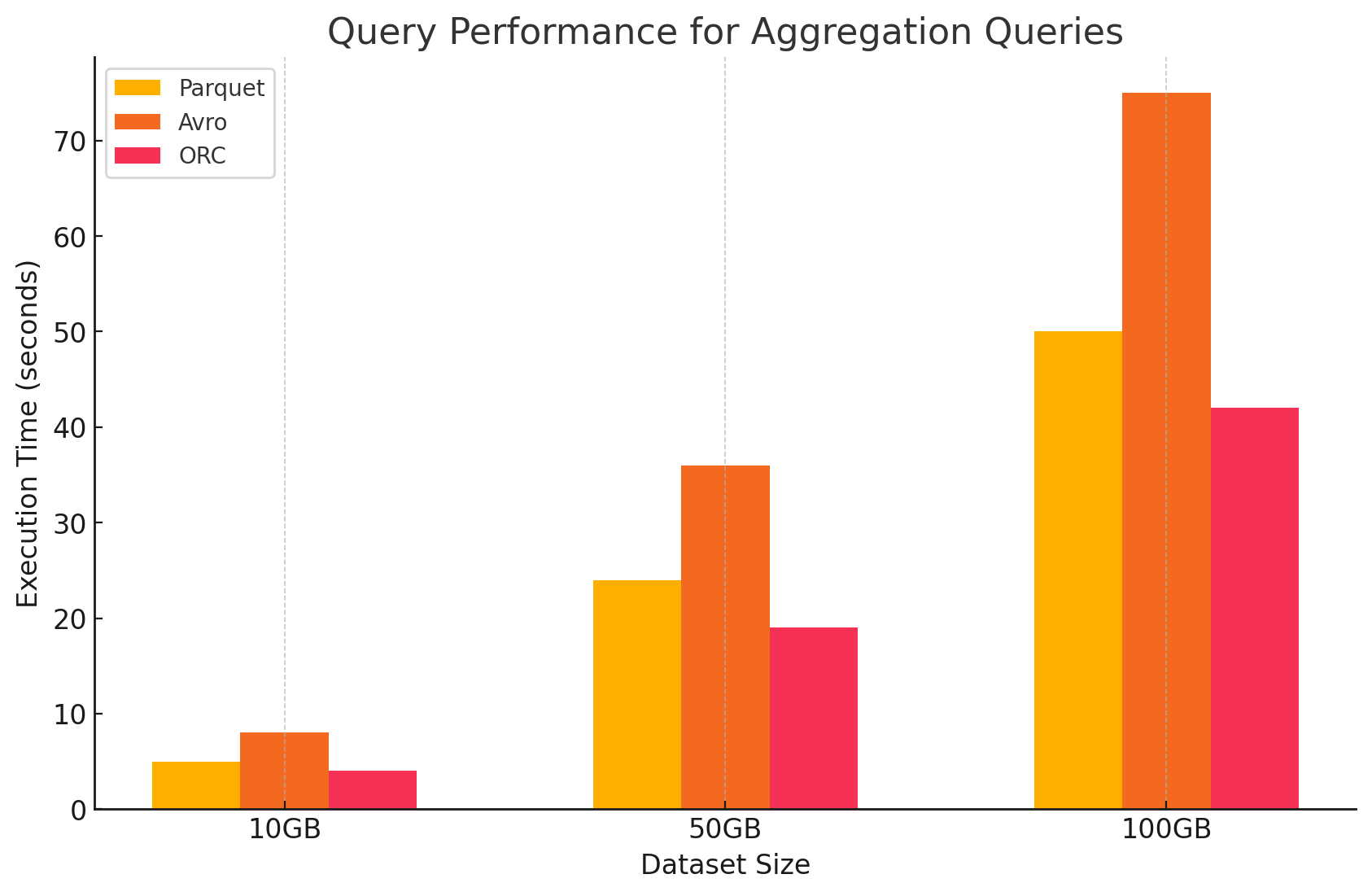
3. Requêtes d’agrégation
- Parquet :Parquet a fonctionné bien, mais moins efficacement que ORC. Le format colonne permet des opérations d’agrégation en accédant rapidement aux colonnes requises, mais Parquet manque certaines optimisations intégrées que propose ORC.
# Aggregation query on Parquet file
agg_parquet_df = parquet_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_parquet_df.show()
- Avro :Avro a été en retard en raison de son stockage row-based, qui exigeait de scanner et de traiter toutes les colonnes pour chaque rangée, augmentant le surchargement calculatoire.
-- Aggregation query on Avro file in Hive
SELECT column1, SUM(column2), AVG(column3) FROM avro_table GROUP BY column1;
- ORC :ORC a dépassé Parquet et Avro dans les requêtes d’agrégation. L’indexation avancée et les algorithmes de compression intégrés d’ORC ont permis un accès plus rapide aux données et une réduction des opérations I/O, ce qui le rend très adapté aux tâches d’agrégation.
# Aggregation query on ORC file
agg_orc_df = orc_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_orc_df.show()
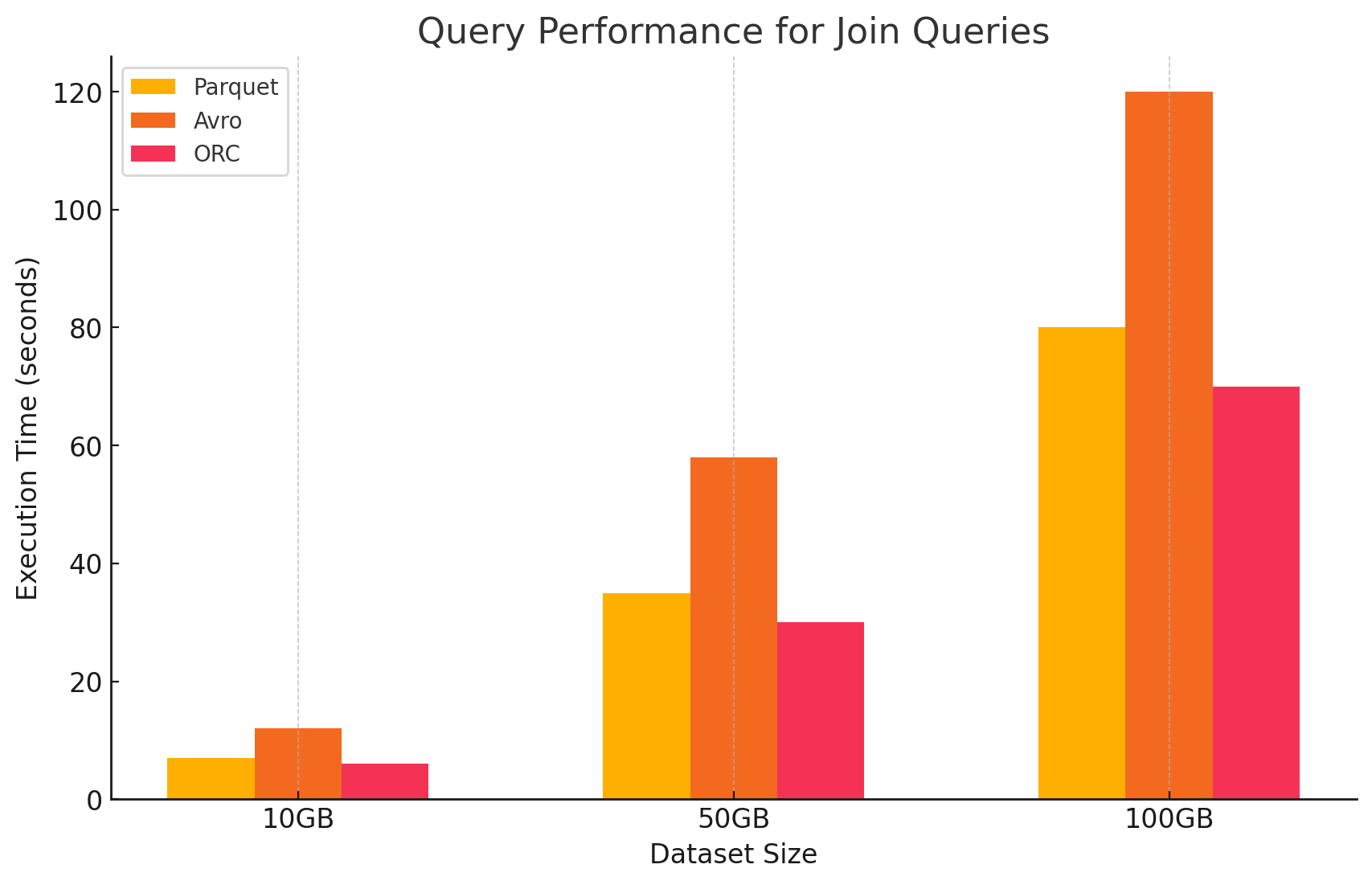
4. Requêtes de jointure
- Parquet :Parquet a fonctionné bien, mais moins efficacement que ORC dans les opérations de jointure en raison de sa lecture de données moins optimisée pour les conditions de jointure.
# Join query between Parquet and ORC files
joined_df = parquet_df.join(orc_df, parquet_df.key == orc_df.key)
joined_df.show()
- ORC :ORC a excellé dans les requêtes de jointure, bénéficiant de l’indexation avancée et de la capacité de pushdown des prédicats, qui ont miné le nombre de données scanner et traité pendant les opérations de jointure.
# Join query between two ORC files
joined_orc_df = orc_df.join(other_orc_df, orc_df.key == other_orc_df.key)
joined_orc_df.show()
- Avro : Avro a connu de graves difficultés avec les opérations de jointure, principalement à cause du haut overhead de la lecture de lignes complètes et de l’absence d’optimisations columnaires pour les clés de jointure.
-- Join query between Parquet and Avro files in Hive
SELECT a.column1, b.column2
FROM parquet_table a
JOIN avro_table b
ON a.key = b.key;
Impact du Format d’Enregistrement sur les Coûts
1. Efficacité de Stockage et Coût
- Parquet et ORC (formats colonnaires)
- Compression et coût de stockage : Both Parquet et ORC sont des formats de stockage colonnaire offrant de hauts taux de compression, en particulier pour des jeux de données avec beaucoup de valeurs répétitives ou similaires dans les colonnes. Cette haute compression réduit la taille des données globales, ce qui abaisse par conséquent les coûts de stockage, en particulier dans un environnement cloud où le stockage est facturé par GB.
- Ideal pour les charges de travail analytiques :En raison de leur nature colonnaire, ces formats sont idéals pour les charges de travail analytiques où seulement certaines colonnes sont fréquemment consultées. Cela signifie que moins de données sont lues depuis le stockage, réduisant à la fois les opérations I/O et les coûts associés.
- Avro (format basé sur les lignes)
- Coût de compression et de stockage : Avro offre généralement des taux de compression inférieurs aux formats colonnes comme Parquet et ORC car il stocke les données ligne par ligne. Cela peut entraîner des coûts de stockage plus élevés, en particulier pour les grands ensembles de données avec de nombreuses colonnes, car toutes les données d’une ligne doivent être lues, même si seules quelques colonnes sont nécessaires.
- Meilleur pour les charges de travail à forte écriture : Bien qu’Avro puisse entraîner des coûts de stockage plus élevés en raison d’une compression plus faible, il est mieux adapté aux charges de travail à forte écriture où les données sont continuellement écrites ou ajoutées. Le coût associé au stockage peut être compensé par les gains d’efficacité dans la sérialisation et la désérialisation des données.
2. Performance et coût du traitement des données
- Parquet et ORC (formats en colonnes)
- Réduction des coûts de traitement : Ces formats sont optimisés pour les opérations à forte lecture, ce qui les rend très efficaces pour interroger de grands ensembles de données. En permettant de lire uniquement les colonnes pertinentes nécessaires à une requête, ils réduisent la quantité de données traitées. Cela entraîne une diminution de l’utilisation du CPU et des temps d’exécution des requêtes plus rapides, ce qui peut réduire considérablement les coûts informatiques dans un environnement cloud où les ressources de calcul sont facturées en fonction de l’utilisation.
- Fonctionnalités avancées pour l’optimisation des coûts : ORC, en particulier, inclut des fonctionnalités comme le filtrage par prédicat et des statistiques intégrées, qui permettent au moteur de requêtes d’éviter la lecture de données inutiles. Cela réduit encore les opérations d’E/S et accélère les performances des requêtes, optimisant ainsi les coûts.
- Avro (formats basés sur les lignes)
- Couts de traitement élevés : Comme Avro est un format basé sur les lignes, cela exige généralement plus d’opérations E/S pour lire des lignes entières même lorsqu’il n’est nécessaire que de quelques colonnes. Cela peut entraîner des coûts computationnels augmentés en raison d’une utilisation plus élevée de la CPU et de temps d’exécution des requêtes plus longs, en particulier dans des environnements axés sur la lecture.
- Efficace pour le streaming et la sérialisation : Malgré les coûts de traitement plus élevés pour les requêtes, Avro est bien adapté aux tâches de streaming et de sérialisation où les vitesses d’écriture rapides et l’évolution des schémas sont plus cruciales.
3. Analyse des coûts avec des détails sur les tarifications
- Pour quantifier l’impact des coûts de chaque format d’enregistrement, nous avons mené une expérience utilisant GCP. Nous avons calculé les coûts associés à la fois à l’enregistrement et au traitement des données pour chaque format en fonction des modèles de tarification de GCP.
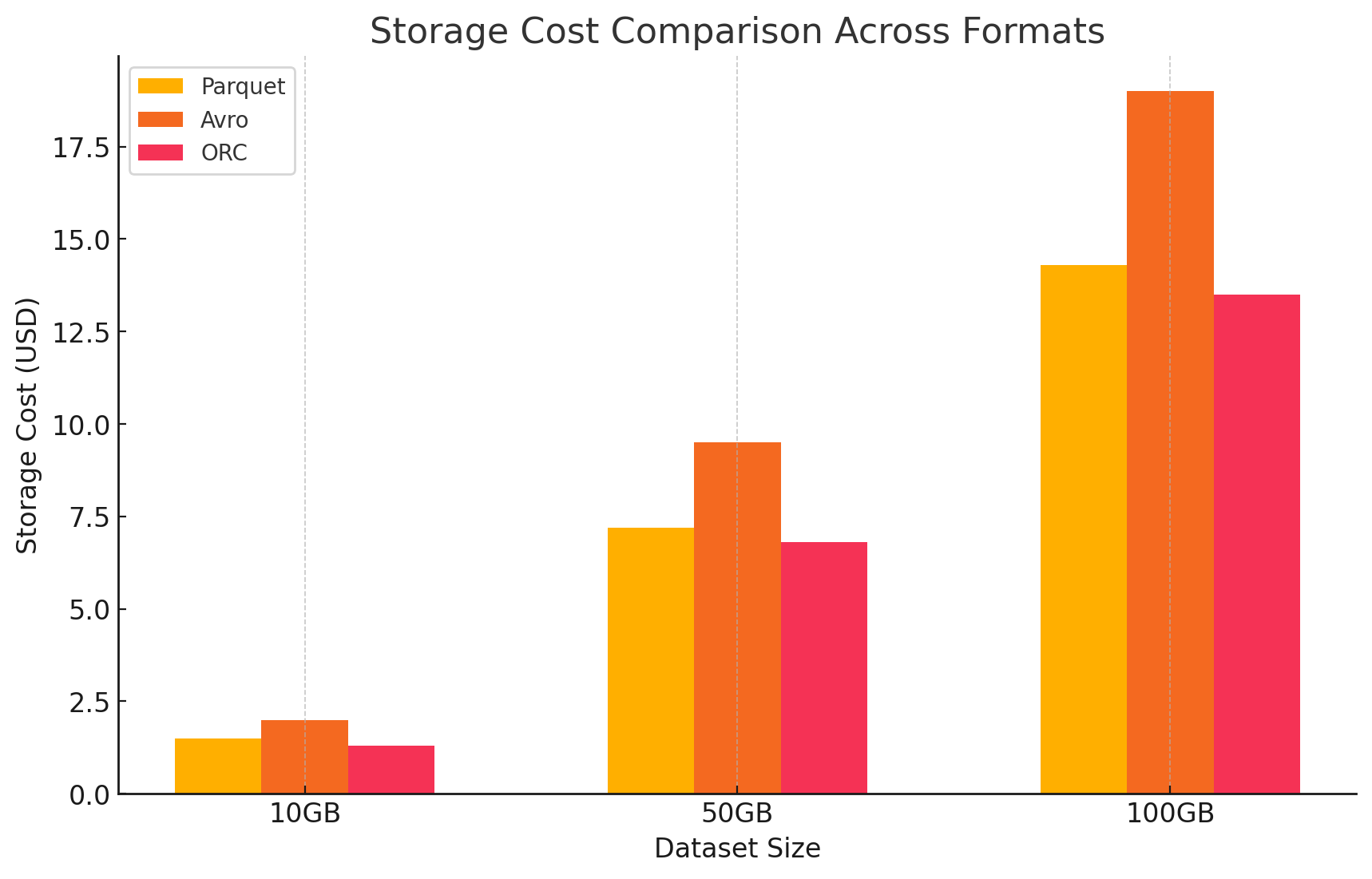
- Coûts de stockage Cloud Google
- Coût de stockage : Il est calculé en fonction de la quantité de données stockées sous chaque format. Google Cloud Payer par GB par mois pour les données stockées dans Google Cloud Storage. Les rapports de compression atteints par chaque format influent directement sur ces coûts. Les formats colonne tels que Parquet et ORC offrent généralement de meilleurs rapports de compression que les formats ligne tels que Avro, ce qui réduit les coûts de stockage.
- Voici un exemple de la manière dont sont calculés les coûts de stockage :
- Parquet :Une compression élevée réduit la taille des données, abaissant les coûts de stockage
- ORC :Comme Parquet, l’compression avancée d’ORC réduit également les coûts de stockage
- Avro :Une efficacité de compression inférieure entraîne des coûts de stockage plus élevés par rapport à Parquet et ORC
# Example of how to save data back to Google Cloud Storage in different formats
# Save DataFrame as Parque
parquet_df.write.parquet("gs://your-bucket/output_parquet")
# Save DataFrame as Avro
avro_df.write.format("avro").save("gs://your-bucket/output_avro")
# Save DataFrame as ORC
orc_df.write.orc("gs://your-bucket/output_orc")
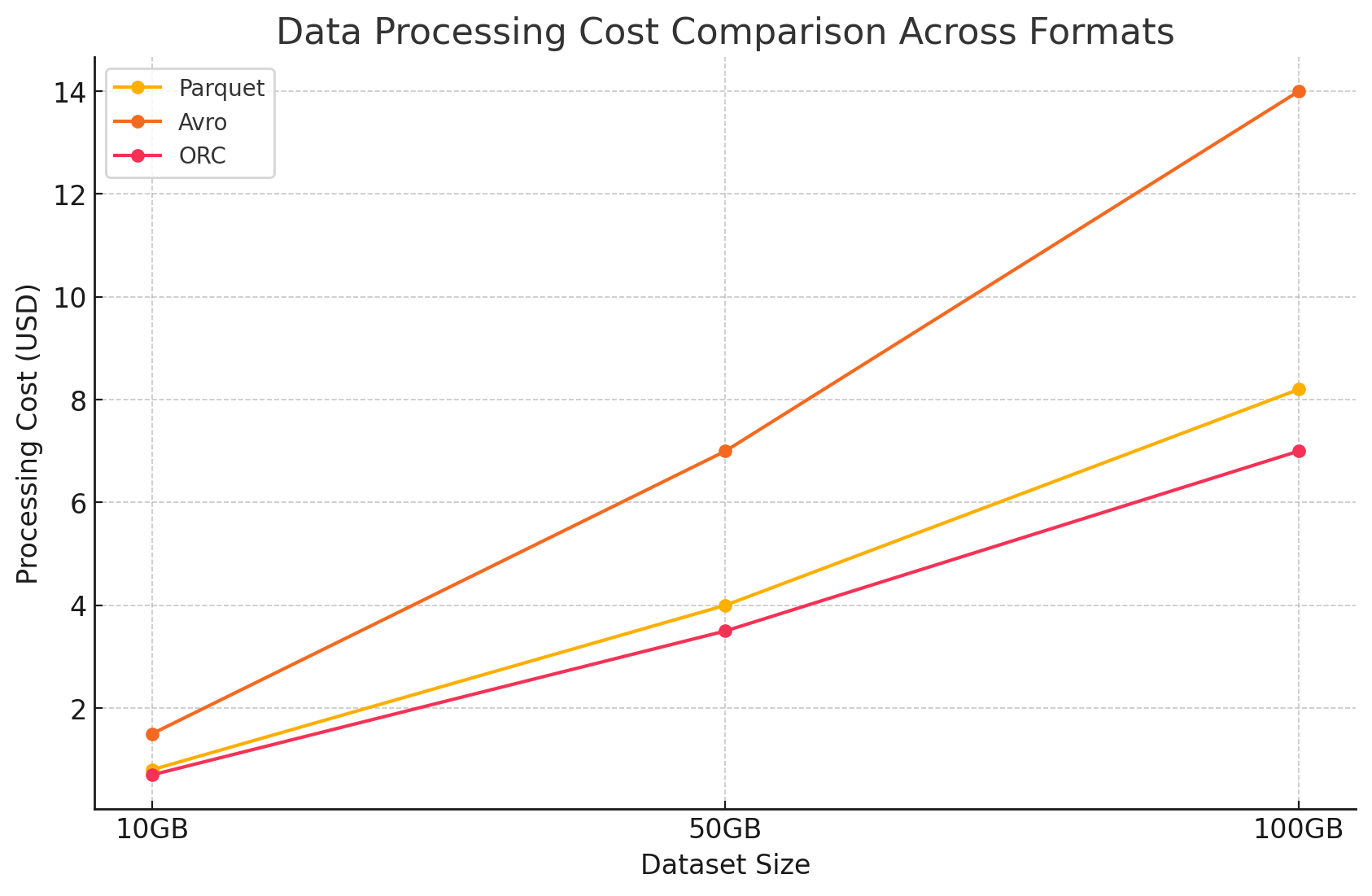
- Coûts de traitement des données
- Les coûts de traitement des données ont été calculés en fonction des ressources de calcul requises pour exécuter diverses requêtes en utilisant Dataproc sur GCP. GCP facture l’utilisation de Dataproc en fonction de la taille du cluster et de la durée pour laquelle les ressources sont utilisées.
- Coûts de calcul :
- Parquet et ORC :En raison de leur stockage colonne efficient, ces formats ont réduit le volume de données lues et traitées, ce qui a permis de réduire les coûts de calcul. Les temps d’exécution des requêtes plus rapides ont également contribué aux économies de coûts, en particulier pour les requêtes complexes impliquant de grands jeux de données.
- Avro :Avro a nécessité plus de ressources de calcul à cause de son format de rangées, ce qui a augmenté le volume de données lues et traitées. Cela a entraîné des coûts plus élevés, en particulier pour les opérations à lecture intense.
Conclusion
Le choix du format de stockage dans les environnements de big data a une incidence significative sur la performance des requêtes et les coûts. Les recherches et expériences précitées démontrent les points clés suivants :
- Parquet et ORC : Ces formats colonne offrent une excellente compression, qui réduit les coûts de stockage. Leur capacité à lire efficacement uniquement les colonnes nécessaires améliore considérablement la performance des requêtes et réduit les coûts de traitement des données. ORC légèrement outperforme Parquet pour certains types de requêtes en raison de ses fonctionnalités d’indexation et d’optimisation avancées, ce qui en fait une excellente sélection pour des charges de travail mixtes exigeant à la fois une haute performance en lecture et en écriture.
- Avro : Bien que Avro ne soit pas aussi efficace en matière de compression et de performance de requête que Parquet et ORC, il est supérieur dans les cas d’utilisation nécessitant des opérations d’écriture rapides et une évolution du schéma. Ce format est idéal pour les scénarios impliquant la sérialisation des données et le streaming où la performance d’écriture et la flexibilité sont prioritaires par rapport à l’efficacité de lecture.
- Efficacité coûtière : Dans un environnement cloud comme GCP, où les coûts sont fortement liés à la consommation de stockage et de calcul, choisir le format approprié peut entraîner des économies significatives. Pour les charges de travail analytiques qui sont principalement orientées vers la lecture, Parquet et ORC sont les options les plus rentables. Pour les applications qui nécessitent une ingestion de données rapide et une gestion de schéma flexible, Avro est une sélection adéquate malgré ses coûts de stockage et de calcul plus élevés.
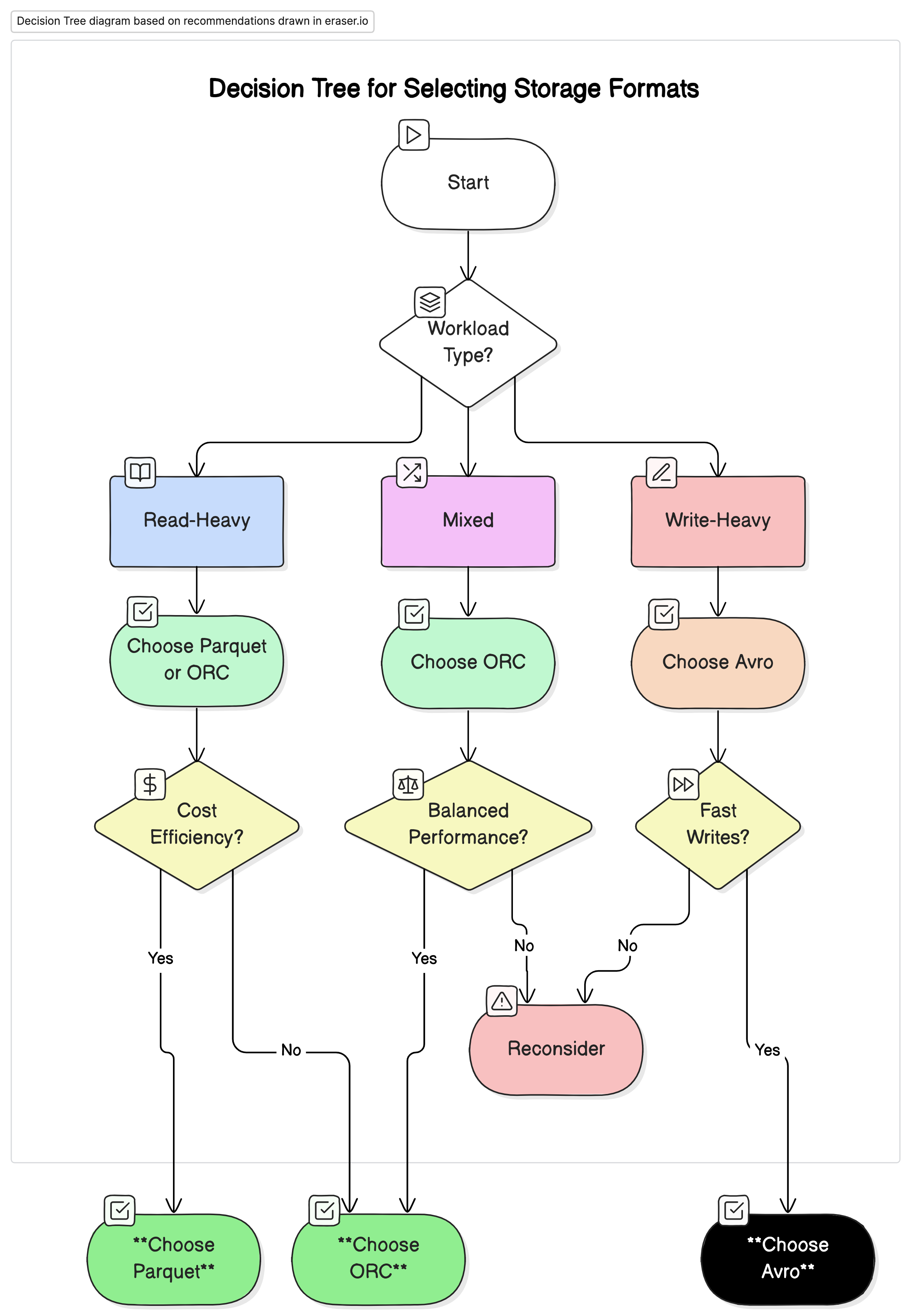
Recommandations
Sur la base de notre analyse, nous recommandons les options suivantes :
- Pour les charges de travail analytiques axées sur la lecture : Utilisez Parquet ou ORC. Ces formats offrent des performances et une efficacité coût supérieures en raison de leur haute compression et de performances de requêtes optimisées.
- Pour les charges de travail axées sur l’écriture et la sérialisation : Utilisez Avro. Il est mieux adapté aux scénarios où les écritures rapides et l’évolution des schémas sont cruciales, telles que le streaming de données et les systèmes de messagerie.
- Pour les charges de travail mixtes : ORC offre des performances équilibrées pour les opérations de lecture et d’écriture, ce qui en fait une choix idéal pour les environnements où les charges de données varient.
Pensées finales
La sélection du bon format de stockage pour les environnements de données massives est essentielle pour optimiser les performances et les coûts. La compréhension des forces et des faiblesses de chaque format permet aux ingénieurs de données de personnaliser leur architecture de données en fonction de cas d’utilisation spécifiques, maximisant l’efficacité et minimisant les dépenses. Au fur et à mesure que les volumes de données continuent de croître, la prise de décisions éclairées sur les formats de stockage deviendra de plus en plus importante pour maintenir des solutions de données escalables et rentables.
En évaluant attentivement les indicateurs de performance et les incidences financières présentées dans cet article, les organisations peuvent choisir le format de stockage qui correspond le mieux à leurs besoins opérationnels et à leurs objectifs financiers.
Source:
https://dzone.com/articles/performance-and-cost-implications-parquet-avro-orc