













효율적인 데이터 처리는 빅데이터 분석을 통해 의사결정을 내리는 기업과 조직에 매우 중요합니다. 데이터 처리의 성능에 크게 영향을 미치는 주요 요소 중 하나는 데이터의 저장 형식입니다. 이 글에서는 Google Cloud Platform(GCP)의 빅데이터 환경에서 Parquet, Avro, ORC와 같은 다양한 저장 형식이 쿼리 성능과 비용에 미치는 영향을 탐구합니다. 또한 벤치마크 결과를 제공하고 비용 영향에 대해 논의하며, 특정 사용 사례에 맞는 적절한 형식을 선택하는 방법에 대한 권장 사항을 제시합니다.
빅데이터 저장 형식 소개
데이터 저장 형식은 모든 빅데이터 처리 환경의 근간입니다. 데이터가 어떻게 저장되고 읽히며 기록되는지를 정의하며, 이는 저장 효율성, 쿼리 성능, 데이터 검색 속도에 직접적인 영향을 미칩니다. 빅데이터 생태계에서는 Parquet와 ORC 같은 컬럼 형식과 Avro 같은 행 기반 형식이 특정 쿼리와 처리 작업에 최적화된 성능을 제공하기 때문에 널리 사용됩니다.
- Parquet: Parquet는 읽기 중심의 작업과 분석에 최적화된 컬럼 저장 형식입니다. 압축과 인코딩 면에서 매우 효율적이며, 읽기 성능과 저장 효율성이 우선시되는 시나리오에 이상적입니다.
- Avro: Avro는 데이터 직렬화를 위해 설계된 행 기반 저장 형식입니다. 스키마 진화 기능으로 잘 알려져 있으며, 데이터가 빠르게 직렬화되고 역직렬화되어야 하는 쓰기 중심의 작업에 자주 사용됩니다.
- ORC (Optimized Row Columnar):ORC는 Parquet과 비슷한 열 기반 저장 형식입니다만, 읽기와 쓰기 operatioin에 대해 optimized되어 있습니다. ORC는 압축에 대해 매우 高效하며, 이는 저장 비용을 감소 시키고 데이터 조회를 加速시키ます.
연구 목적
이 연구의 주요 목적은 다양한 저장 형식(Parquet, Avro, ORC)이 대량 데이터 환경에서 쿼리 성능과 コスト를 어떻게 영향을 미치는지 评定하는 것입니다. 이 글은 다양한 쿼리 유형과 데이터 용량을 기반으로 ベンチマーク을 제공하여, 데이터 엔지니어링과 아키텍처 engineers가 자신의 특정 사용 사례에 가장 적절한 형식을 선택할 수 있도록 도울 것입니다.
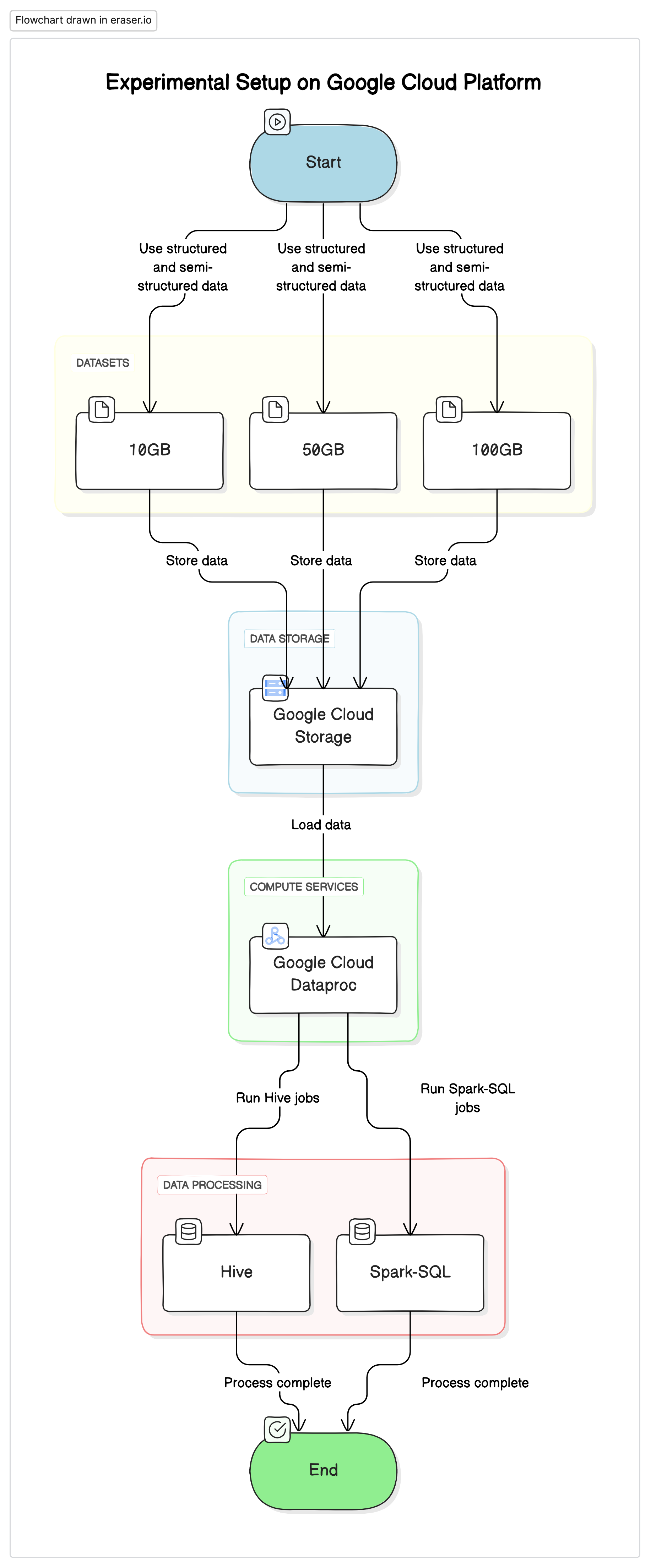
실험적 세팅
이 연구를 실시하기 위해, 우리는 Google Cloud Platform(GCP)에 표준화된 세팅을 使用하였습니다. 이에 Google Cloud Storage는 데이터 저장소로 사용되고, Google Cloud Dataproc은 Hive와 Spark-SQL 작업을 실행하기 위한 서비스였습니다. 실험에 사용되는 데이터는 구조化된 데이터와 半구조化된 데이터의 결합으로 실제 세계의 사례를 mimic하였습니다.
주요 요소
- Google Cloud Storage: 다양한 형식(Parquet, Avro, ORC)으로 datasets를 저장하는 것을 사용합니다.
- Google Cloud Dataproc: Apache Hadoop과 Apache Spark를 관리하는 서비스로 Hive와 Spark-SQL 작업을 실행합니다.Apache Hadoop
- Datasets: 크기가 다른 세 가지 datasets(10GB, 50GB, 100GB)을 사용하며 데이터 유형이 섞여 있습니다.
# Initialize PySpark and set up Google Cloud Storage as file system
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("BigDataQueryPerformance") \
.config("spark.jars.packages", "com.google.cloud.bigdataoss:gcs-connector:hadoop3-2.2.5") \
.getOrCreate()
# Configure the access to Google Cloud Storage
spark.conf.set("fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem")
spark.conf.set("fs.gs.auth.service.account.enable", "true")
spark.conf.set("google.cloud.auth.service.account.json.keyfile", "/path/to/your-service-account-file.json")
테스트 쿼리
- 간단한 SELECT 쿼리: 테이블에서 모든 열을 기본적으로 가져오는 것
- 過濾 쿼리: WHERE CLAUSE를 사용하여 specific 行을 過濾하는 SELECT 쿼리
- 집계 쿼리: GROUP BY와 SUM, AVG과 같은 집계 함수를 사용하는 쿼리
- 연결 쿼리: 공통 ключ에 따라 두 개 이상의 테이블을 연결하는 쿼리
결과 및 분석
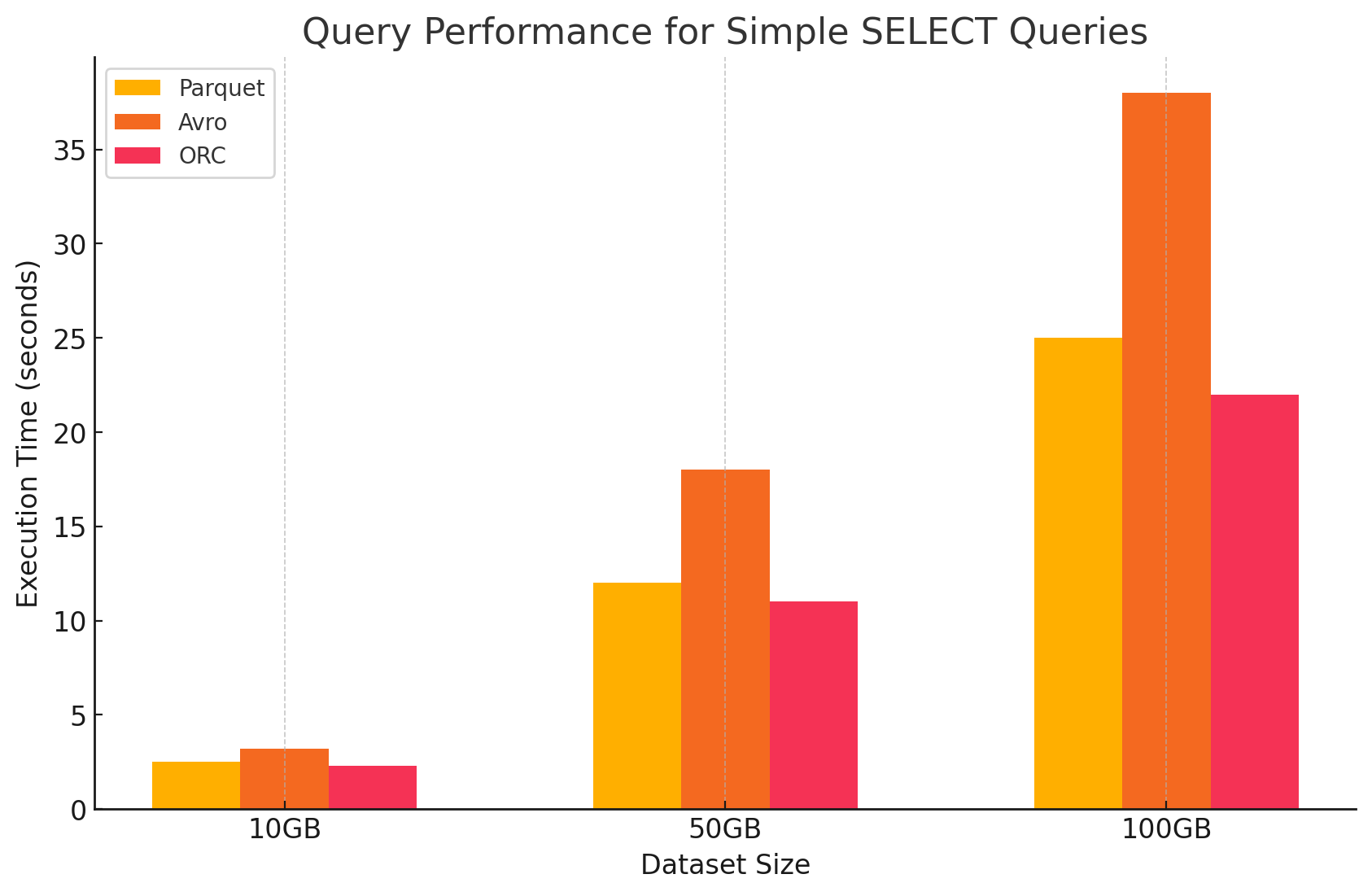
1. 간단한 SELECT 쿼리
- Parquet: 열 기반 저장 형식 때문에 특정 열을 빠르게 스캔 할 수 있었습니다. Parquet 파일은 强力하게 압축되었으며, 디스크에서 읽는 데 사용되는 데이터 量을 줄이어 쿼리 실행 시간을 더 빨라짐에 resulted.
# Simple SELECT query on Parquet file
parquet_df.select("column1", "column2").show()
- Avro: Avro는 중요하게 좋은 성과를 보였습니다. 行 기반 형식이므로, 특정 열만 필요하더라도 전체 行을 읽어야 했습니다. 이러한 것은 I/O 操作을 増加시키고 Parquet과 ORC와 비교해도 쿼리 성능이 느리게 나타났습니다.
-- Simple SELECT query on Avro file in Hive
CREATE EXTERNAL TABLE avro_table
STORED AS AVRO
LOCATION 'gs://your-bucket/dataset.avro';
SELECT column1, column2 FROM avro_table;
- ORC: ORC는 Parquet과 비슷한 성능을 보였지만, slightly better compression과 개선된 저장 기술로 읽기 속도를 향상시켰습니다. ORC 파일은 列 기반이며, SELECT 쿼리가 특정 열을 only 가져오는 것에 적용되기 때문에 적절하다.
# Simple SELECT query on ORC file
orc_df.select("column1", "column2").show()
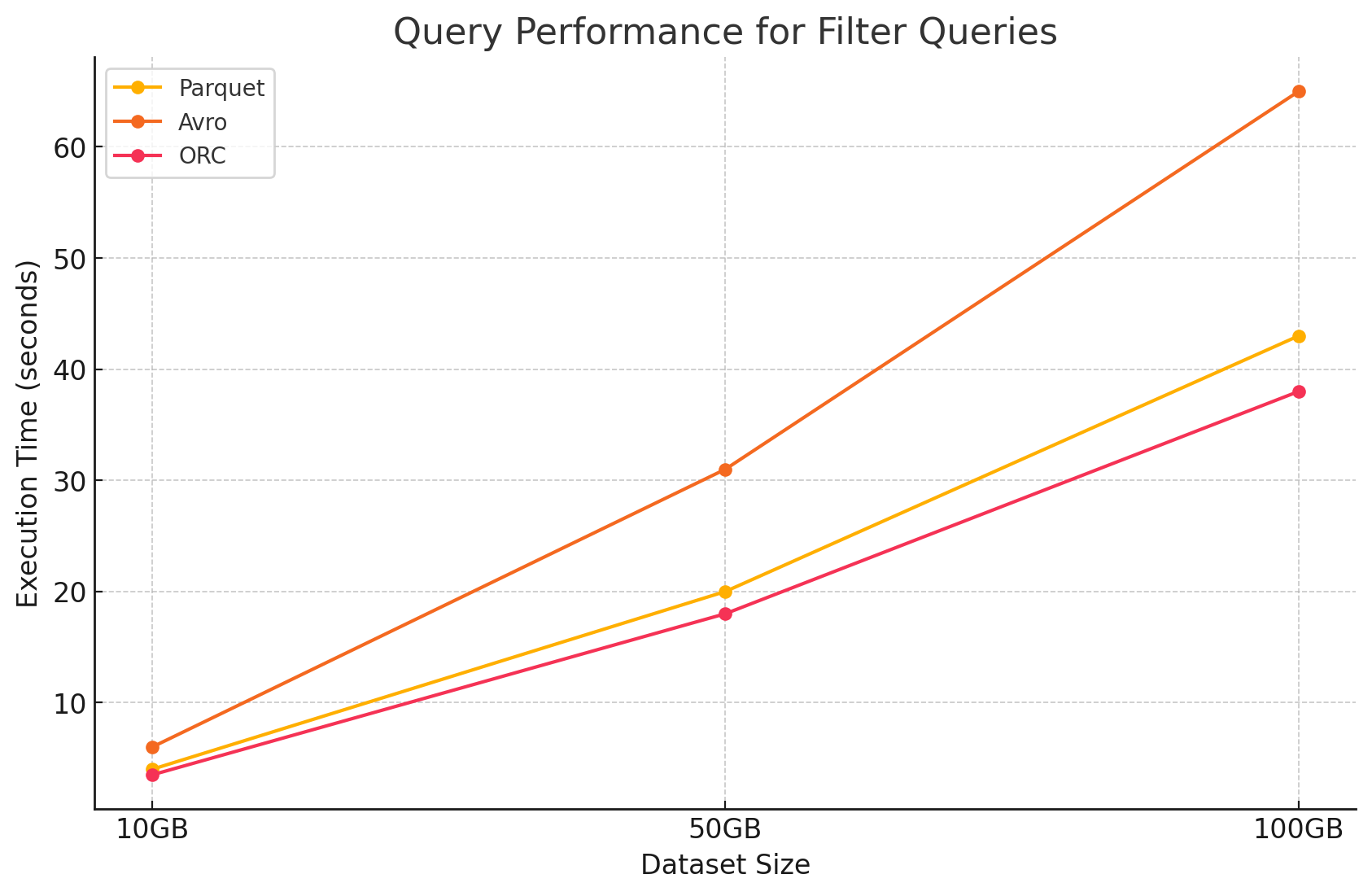
2. 過濾 쿼리
- Parquet: Parquet은 열 기반 자性的으로 過濾하는 것과 관련없는 열을 빠르게 건너뛰는 능력으로 성능 优势을 보유하였습니다. 그러나 過濾을 적용하기 위해 더 많은 行을 스캔하는 것이 성능에 slightly 영향을 미칠 수 있었습니다.
# Filter query on Parquet file
filtered_parquet_df = parquet_df.filter(parquet_df.column1 == 'some_value')
filtered_parquet_df.show()
- Avro: 전체 행을 읽고 모든 열에 필터를 적용해야 했기 때문에 성능이 더 저하되어 처리 시간이 증가했습니다.
-- Filter query on Avro file in Hive
SELECT * FROM avro_table WHERE column1 = 'some_value';
- ORC: 데이터를 메모리에 로드하기 전에 저장 수준에서 필터링을 직접 수행할 수 있는 프레디케이트 푸시다운 기능 덕분에 필터 쿼리에서 Parquet보다 약간 더 뛰어난 성능을 보였습니다.
# Filter query on ORC file
filtered_orc_df = orc_df.filter(orc_df.column1 == 'some_value')
filtered_orc_df.show()
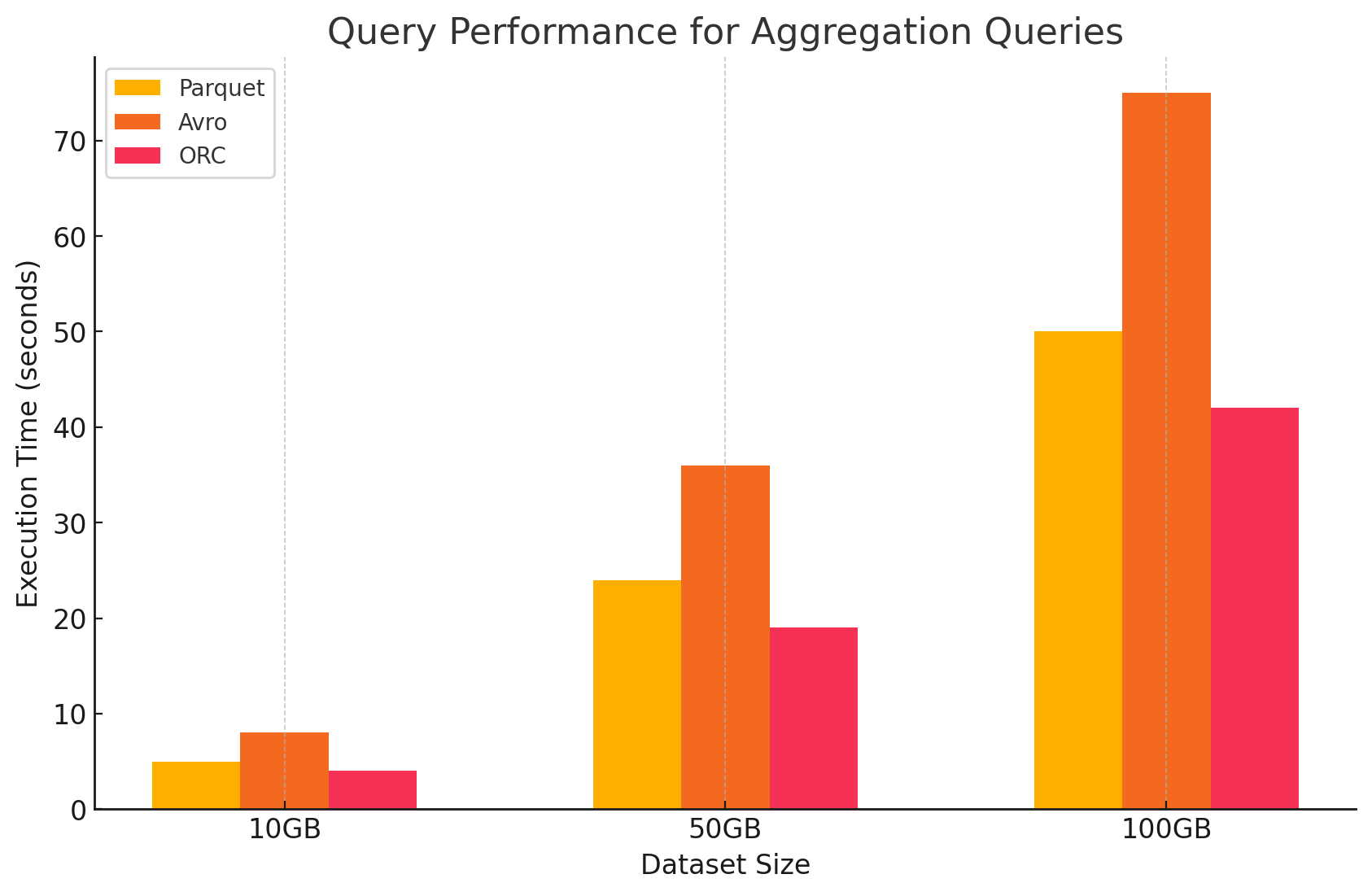
3. 집계 쿼리
- Parquet: Parquet는 양호한 성능을 보였으나 ORC보다는 약간 효율이 떨어졌습니다. 컬럼 형식은 필요한 열에 빠르게 접근하여 집계 작업에 유리하지만, Parquet는 ORC가 제공하는 일부 내장 최적화 기능이 부족합니다.
# Aggregation query on Parquet file
agg_parquet_df = parquet_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_parquet_df.show()
- Avro: Avro는 행 기반 저장 방식으로 인해 각 행의 모든 열을 스캔하고 처리해야 하므로 계산 오버헤드가 증가하여 성능이 뒤처졌습니다.
-- Aggregation query on Avro file in Hive
SELECT column1, SUM(column2), AVG(column3) FROM avro_table GROUP BY column1;
- ORC: ORC는 집계 쿼리에서 Parquet와 Avro 모두보다 뛰어난 성능을 보였습니다. ORC의 고급 인덱싱 및 내장 압축 알고리즘은 더 빠른 데이터 접근과 I/O 작업을 줄여 집계 작업에 매우 적합했습니다.
# Aggregation query on ORC file
agg_orc_df = orc_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_orc_df.show()
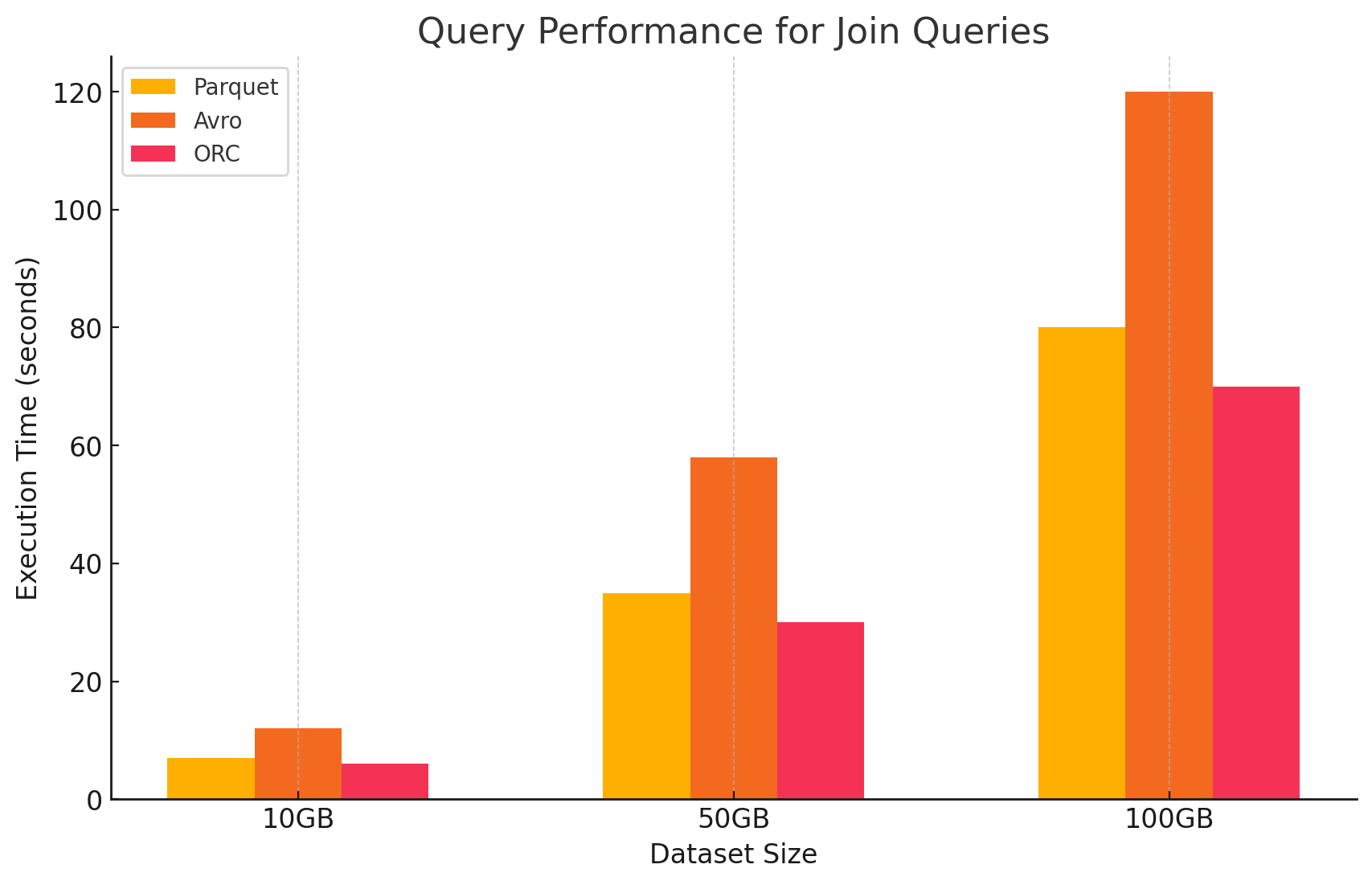
4. 조인 쿼리
- Parquet: Parquet는 양호한 성능을 보였으나, 조인 조건에 대한 데이터 읽기 최적화가 덜 되어 ORC보다는 효율이 떨어졌습니다.
# Join query between Parquet and ORC files
joined_df = parquet_df.join(orc_df, parquet_df.key == orc_df.key)
joined_df.show()
- ORC: ORC는 고급 인덱싱과 프레디케이트 푸시다운 기능 덕분에 조인 쿼리에서 뛰어난 성능을 발휘하여 스캔되고 처리되는 데이터를 최소화했습니다.
# Join query between two ORC files
joined_orc_df = orc_df.join(other_orc_df, orc_df.key == other_orc_df.key)
joined_orc_df.show()
- Avro: Avro는 조인 연산에SIGNIFICANTLY 제한이 있습니다. 주로 전체 행을 읽는 높은 오버헤드와 조인 키를 위한 칼럼형 최적화의 결합 부족으로 인해 그렇습니다.
-- Join query between Parquet and Avro files in Hive
SELECT a.column1, b.column2
FROM parquet_table a
JOIN avro_table b
ON a.key = b.key;
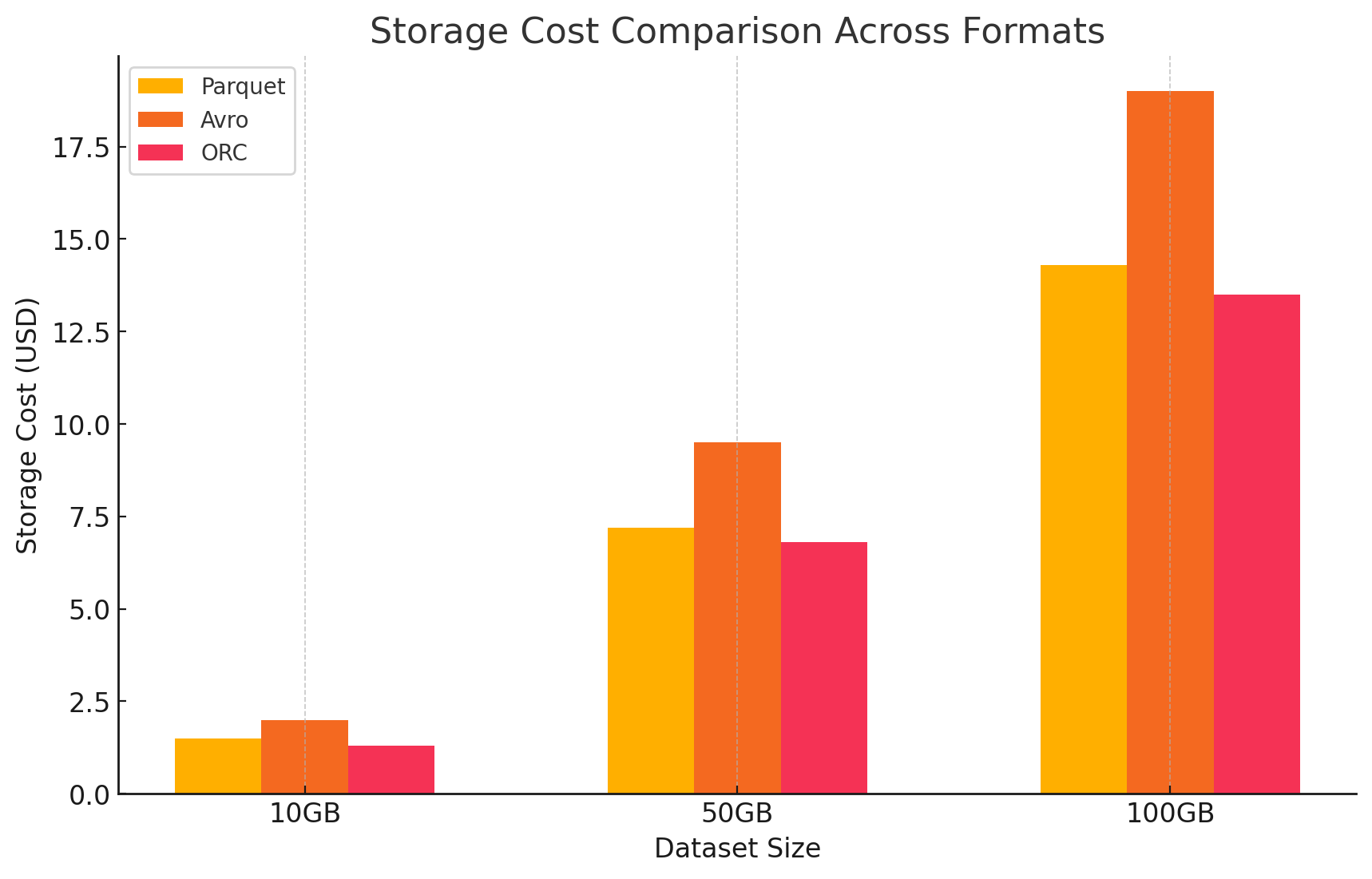
저장 형식이 비용에 미치는 영향
1. 저장 효율과 비용
- Parquet와 ORC (칼럼형 형식)
- 압축과 저장 비용: Parquet와 ORC는 모두 칼럼형 저장 형식으로, 특히 칼럼 내에서 많은 반복되거나 유사한 값을 가진 데이터셋에 대해 높은 압축률을 제공합니다. 이러한 높은 압축은 전체 데이터 크기를 줄이고, 따라서 스토리지 비용을 낮춥니다. 특히 클라우드 환경에서 스토리지는 GB 단위로 요금제가 적용되므로 이에 더욱 유리합니다.
- 분석 작업에 최적: 칼럼형 특성 때문에 이러한 형식은 자주 조회되는 특정 칼럼들만 있는 분석 작업을 위한理想的입니다. 이는 스토리지에서 덜 데이터를 읽어들이는 것을 의미하며, I/O 연산 및 관련 비용을 줄입니다.
- Avro (행 기반 형식)
- 압축 및 저장 비용: Avro는 데이터를 행 단위로 저장하기 때문에 Parquet나 ORC와 같은 컬럼 형식보다 일반적으로 더 낮은 압축률을 제공합니다. 이는 특히 많은 열을 가진 대규모 데이터 세트에서 더 높은 저장 비용을 초래할 수 있습니다. 필요한 열이 몇 개뿐이어도 한 행의 모든 데이터를 읽어야 하기 때문입니다.
- 쓰기 작업이 많은 워크로드에 적합: Avro는 낮은 압축률로 인해 더 높은 저장 비용이 발생할 수 있지만, 데이터가 지속적으로 기록되거나 추가되는 쓰기 작업이 많은 워크로드에 더 적합합니다. 저장과 관련된 비용은 데이터 직렬화 및 역직렬화의 효율성 향상으로 상쇄될 수 있습니다.
2. 데이터 처리 성능 및 비용
- Parquet과 ORC (열 형식)
- 처리 비용 감소:이러한 형식은 읽기 중요한 operaion을 위해 최적화되어 있으며, 대량의 데이터셋을 쿼리하는 것에 대해 매우 효율적입니다. 쿼리에 필요한 열에 대한 みずから 읽기가 가능하므로, 처리되는 데이터 量을 감소시키고 있습니다. 이로 인해 CPU 사용량을 낮추고 쿼리 실행 시간을 빨라 짐에 대해 computational cost를 significantly 낮추는 것이 가능합니다. 이러한 cloud environment에서는 compute resource를 사용에 따라 billing 하는 것입니다.
- cost optimization에 대한 先进的 기능:ORC 특히, 述語 推奨(predicate push-down)과 내장 통계 등의 기능을 포함하고 있습니다. 이러한 기능은 query engine가 읽을 필요없는 데이터를 건너뛰게 하는 것을 도와줍니다. 이로 인해 I/O operaion을 추가로 줄여주고 쿼리 성능을 더욱 빨라 짐을 optimization을 도와줍니다.
- Avro (행 기반 형식)
- 높은 처리 비용: Avro는 행 기반 형식이기 때문에 필요한 열이 몇 개뿐이어도 전체 행을 읽어야 하므로 일반적으로 더 많은 I/O 작업이 필요합니다. 이는 특히 읽기 중심의 환경에서 CPU 사용량 증가와 쿼리 실행 시간 연장으로 인해 처리 비용이 증가할 수 있습니다.
- 스트리밍 및 직렬화에 효율적: 쿼리 처리 비용이 더 높음에도 불구하고 Avro는 빠른 쓰기 속도와 스키마 진화가 중요한 스트리밍 및 직렬화 작업에 잘 맞습니다.
3. 가격 세부사항을 포함한 비용 분석
- 각 저장 형식의 비용 영향을 정량화하기 위해 GCP를 사용하여 실험을 수행했습니다. GCP의 가격 모델을 기반으로 각 형식의 저장 및 데이터 처리와 관련된 비용을 계산했습니다.
- 구글 雲 스토리지 비용
- 스토리지 비용:이 구문은 각 형식에 저장된 데이터 量에 따라 계산되며, GCP는 Google Cloud Storage에 저장된 데이터에 대해 GB당 한 달에 한 번의 요금을 charges한다. 각 형식의 압축 비율이 이에 직면하여 요금을 결정한다. 열 기반 형식인 Avro와 달리, 열 기반 형식인 Parquet과 ORC은 좋은 압축 비율을 달성하여 스토리지 비용을 낮추는 것이 一般的하다.
- 스토리지 비용이 어떻게 계산되는지 샘플이 다음과 같다:
- Parquet:高标准壓縮으로 데이터 크기를 减小시켰으며, 스토리지 비용을 낮춰 왔다
- ORC:Parquet과 유사하게, ORC의 고급 압축이 스토리지 비용을 효율적으로 descended减少했다
- Avro:낮은 압축 효율이 Parquet과 ORC와 비교해서 스토리지 비용을 높이게 했다
# Example of how to save data back to Google Cloud Storage in different formats
# Save DataFrame as Parque
parquet_df.write.parquet("gs://your-bucket/output_parquet")
# Save DataFrame as Avro
avro_df.write.format("avro").save("gs://your-bucket/output_avro")
# Save DataFrame as ORC
orc_df.write.orc("gs://your-bucket/output_orc")
- 데이터 처리 비용
- GCP의 Dataproc을 사용하여 다양한 쿼리를 실행하는 데 필요한 computation 자원의 크기와 리소스를 사용한 시간에 따라 데이터 처리 비용이 계산되었습니다. GCP는 dataproc의 사용에 따라 クラス터 사이즈와 리소스를 사용한 시간에 따라 요금이 收取되며, 이를 基に 데이터 처리 비용을 계산합니다.
- 计算机 비용:
- Parquet과 ORC: 高效な列存储机制으로 이러한 형식은 데이터 읽어들이고 처리하는 量을 减少시키고, compute 비용을 낮추었습니다. 特别是, 이들은 大队列 데이터를 사용한 错綜複雑한 쿼리에 대한 실행 시간을 abbreviate하는 것에 따라 절감되었습니다.
- Avro:Avro는 行기 구조의 형식으로 计算机 자원의 사용을 증가시키고, 데이터 읽어들이고 처리하는 量을 증가시켰습니다. 이러한 이유로, 특히 読み取り 중요 operaion에 대해 비용이 높았습니다.
결론
대용량 데이터 환경에서의 저장 형식 선택은 쿼리 성능과 비용에 중요한 영향을 미칩니다. 위의 연구와 실험은 다음과 같은 핵심 포인트를 보여줍니다.
- Parquet와 ORC: 이런 열형식은 우수한 압축 기능을 제공하여 저장 비용을 줄입니다. 필요한 열만 효율적으로 읽는 능력으로 쿼리 성능을大幅하게 향상시키고 데이터 처리 비용을降低了합니다. ORC는 고급 인덱싱과 최적화 기능으로 특정 쿼리 형식에서 Parquet보다 약간 더 우수한 성능을 보여냅니다. 이는 읽기와 쓰기 성능이 높은 혼합적인 작업負荷에 적합한 선택입니다.
- Avro: Avro는 압축과 쿼리 성능 면에서 Parquet와 ORC에 비해 덜 효율적입니다. 그러나 빠른 쓰기 연산과 스키마 진화를 요구하는 경우에는 우수합니다. 이 형식은 데이터 직렬화와 스트리밍과 관련된 시나리오에서, 쓰기 성능과 유연성이 읽기 효율을 우선시하는 경우에理想的합니다.
- 비용 효율성: GCP와 같은 클라우드 환경에서, 저장과 계산 사용에 가까이 연관된 비용으로 인해 올바른 형식을 선택하면 큰 비용 절감이 가능합니다. 주로 읽기가重的인 분석 작업負荷의 경우, Parquet와 ORC가 가장 비용 효율적인 옵션입니다. 빠른 데이터 적재와 유연한 스키마 관리를 요구하는 응용 프로그램의 경우, Avro는 더 높은 저장과 계산 비용을 감수하고도 적절한 선택입니다.
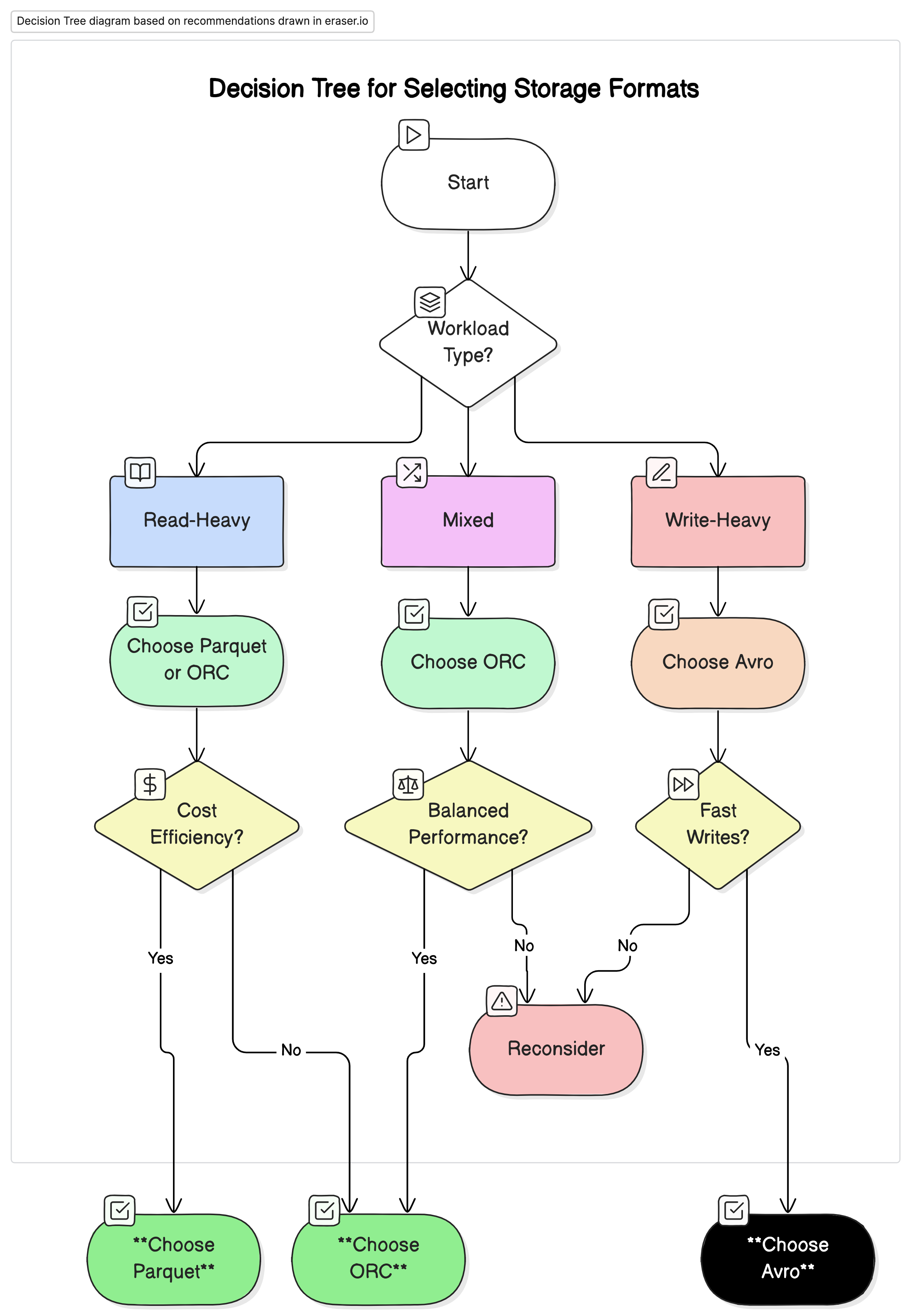
建議
우리의 분석을 바탕으로 다음과 같은 것을 권장합니다.
- 읽기 중심의 분석 워크로드에 적합: Parquet 또는 ORC를 사용하세요. 이 형식들은 높은 압축률과 최적화된 쿼리 성능 덕분에 뛰어난 성능과 비용 효율성을 제공합니다.
- 쓰기 중심의 워크로드와 직렬화에 적합: Avro를 사용하세요. 빠른 쓰기 속도와 스키마 진화가 중요한 데이터 스트리밍 및 메시징 시스템과 같은 시나리오에 더 적합합니다.
- 혼합 워크로드에 적합: ORC는 읽기 및 쓰기 작업 모두에 균형 잡힌 성능을 제공하여 데이터 작업량이 다양하게 변하는 환경에 이상적인 선택입니다.
최종 생각
빅데이터 환경에서 적절한 저장 형식을 선택하는 것은 성능과 비용을 최적화하는 데 매우 중요합니다. 각 형식의 강점과 약점을 이해하면 데이터 엔지니어들이 특정 사용 사례에 맞는 데이터 아키텍처를 설계할 수 있어 효율성을 극대화하고 비용을 최소화할 수 있습니다. 데이터 볼륨이 계속 증가함에 따라 저장 형식에 대한 신중한 결정은 확장 가능하고 비용 효율적인 데이터 솔루션을 유지하는 데 더욱 중요해질 것입니다.
이 문서에 제시된 성능 ベンチマーク 및 비용 가치 사항을 精 calculatorsion하여, 조직은 자신의 운영 需要과 财务 목표에 가장 적절한 저장 형식을 선택할 수 있습니다.
Source:
https://dzone.com/articles/performance-and-cost-implications-parquet-avro-orc