













El procesamiento eficiente de datos es crucial para empresas y organizaciones que dependen de análisis de grandes datos para tomar decisiones informadas. Un factor clave que influye significativamente en el rendimiento del procesamiento de datos es el formato de almacenamiento de los datos. Este artículo explora el impacto de diferentes formatos de almacenamiento, específicamente Parquet, Avro y ORC, en el rendimiento de las consultas y los costos en entornos de grandes datos en la Plataforma de Google Cloud (GCP). Este artículo proporciona referencias, discute las implicaciones de costo y ofrece recomendaciones sobre la selección del formato apropiado basado en casos de uso específicos.
Introducción a los Formatos de Almacenamiento en Grandes Datos
Los formatos de almacenamiento de datos son la base de cualquier entorno de procesamiento de grandes datos. Definen cómo se almacenan, leen y escriben los datos, impactando directamente la eficiencia de almacenamiento, el rendimiento de consultas y la velocidad de recuperación de datos. En el ecosistema de grandes datos, los formatos columnares como Parquet y ORC y los formatos de filas como Avro se utilizan ampliamente debido a su rendimiento optimizado para tipos específicos de consultas y tareas de procesamiento.
- Parquet: Parquet es un formato de almacenamiento columnar optimizado para operaciones de lectura pesada y análisis. Es altamente eficiente en términos de compresión y codificación, lo que lo hace ideal para escenarios en los que se prioriza el rendimiento de lectura y la eficiencia de almacenamiento.
- Avro: Avro es un formato de almacenamiento de filas diseñado para la serialización de datos. Es conocido por sus capacidades de evolución de esquema y se utiliza a menudo para operaciones de escritura pesadas donde se necesita serializar y deserializar los datos rápidamente.
- ORC (Optimizado por Fila y Columna):ORC es un formato de almacenamiento en columnas similar a Parquet, pero optimizado tanto para operaciones de lectura como de escritura. ORC es altamente eficiente en términos de compresión, lo que reduce los costos de almacenamiento y acelera la recuperación de datos.
Objetivo de la Investigación
El objetivo principal de esta investigación es evaluar cómo diferentes formatos de almacenamiento (Parquet, Avro, ORC) afectan el rendimiento de consultas y los costos en entornos de big data. Este artículo busca proporcionar benchmarks basados en diferentes tipos de consultas y volúmenes de datos para ayudar a los ingenieros de datos y arquitectos a elegir el formato más adecuado para sus casos de uso específicos.
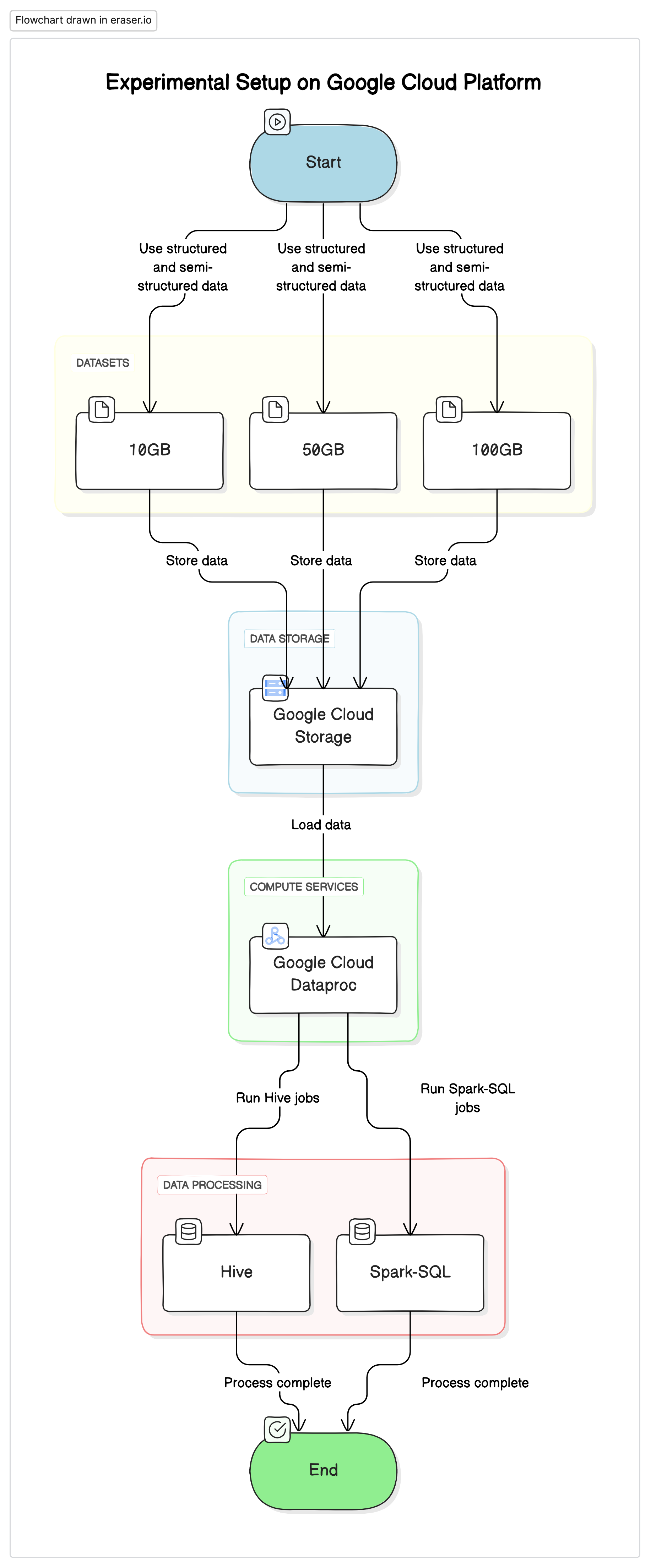
Configuración Experimental
Para realizar esta investigación, utilizamos una configuración estandarizada en la Plataforma de Servicios en la Nube de Google (GCP), con Google Cloud Storage como repositorio de datos y Google Cloud Dataproc para ejecutar trabajos de Hive y Spark-SQL. Los datos utilizados en los experimentos eran una mezcla de conjuntos de datos estructurados y semi-estructurados para simular escenarios reales.
Componentes Clave
- Google Cloud Storage:Se utilizó para almacenar los conjuntos de datos en diferentes formatos (Parquet, Avro, ORC).
- Google Cloud Dataproc:Un servicio administrado que utiliza Apache Hadoop y Apache Spark para ejecutar trabajos de Hive y Spark-SQL.
- Conjuntos de Datos:Tres conjuntos de datos de tamaños variables (10GB, 50GB, 100GB) con tipos de datos mixtos.
# Initialize PySpark and set up Google Cloud Storage as file system
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("BigDataQueryPerformance") \
.config("spark.jars.packages", "com.google.cloud.bigdataoss:gcs-connector:hadoop3-2.2.5") \
.getOrCreate()
# Configure the access to Google Cloud Storage
spark.conf.set("fs.gs.impl", "com.google.cloud.hadoop.fs.gcs.GoogleHadoopFileSystem")
spark.conf.set("fs.gs.auth.service.account.enable", "true")
spark.conf.set("google.cloud.auth.service.account.json.keyfile", "/path/to/your-service-account-file.json")
Consultas de Prueba
- Consultas SELECT simples:Retiro básico de todas las columnas de una tabla
- Consultas de filtrado:Consultas SELECT con cláusulas WHERE para filtrar filas específicas
- Consultas de agregación:Consultas que incluyen GROUP BY y funciones agregadas como SUM, AVG, etc..
- Consultas de unión:Consultas que unen dos o más tablas en una clave común
Resultados y Análisis
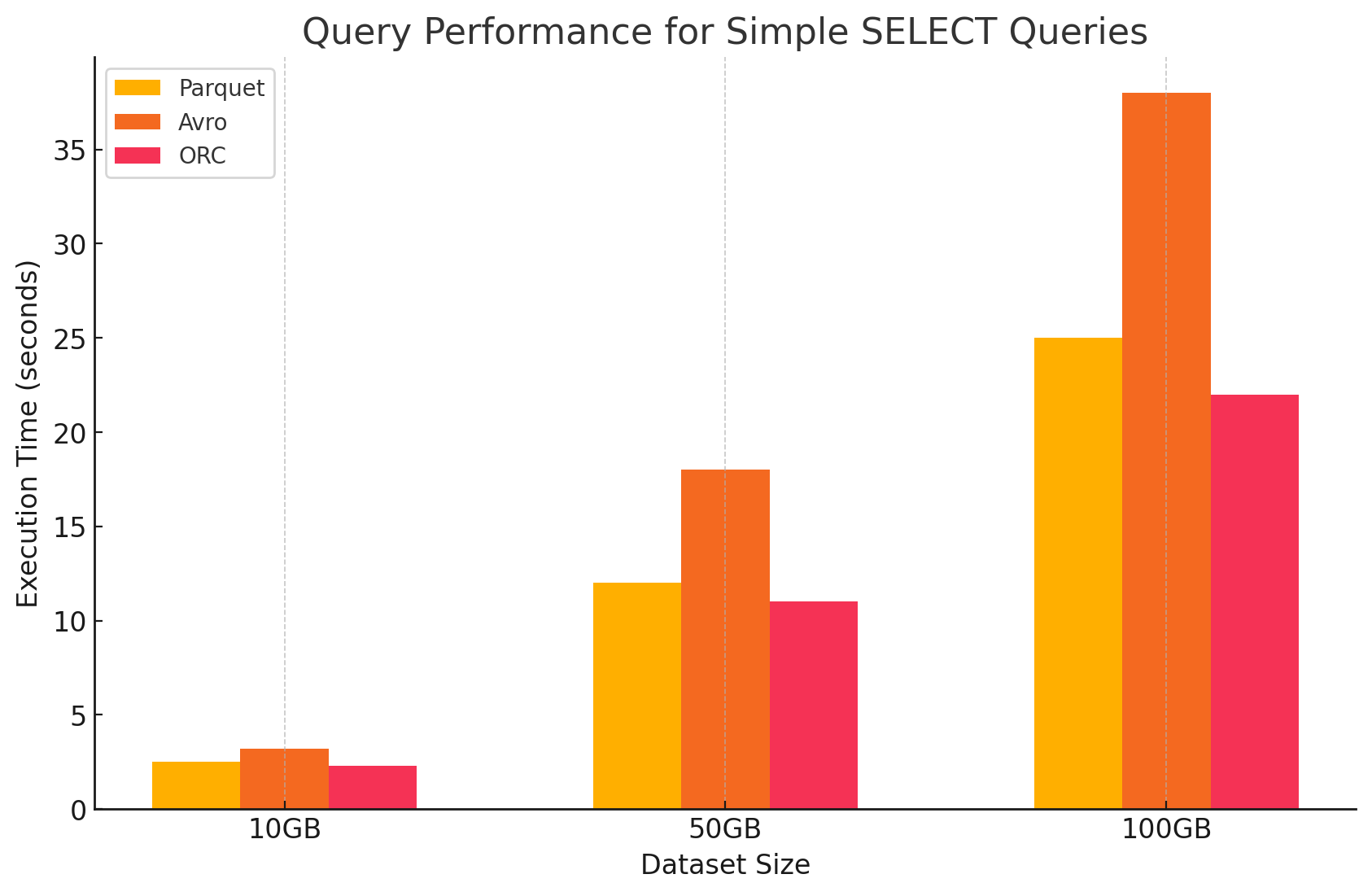
1. Consultas SELECT simples
- Parquet: Tuvo un rendimiento excepcional debido a su formato de almacenamiento en columnas, que permitió una rápida lectura de columnas específicas. Los archivos Parquet están altamente comprimidos, reduciendo la cantidad de datos leídos del disco, lo que resultó en tiempos de ejecución de consultas más rápidos.
# Simple SELECT query on Parquet file
parquet_df.select("column1", "column2").show()
- Avro: Avro tuvo un rendimiento moderado. Siendo un formato basado en filas, Avro requiere la lectura de la fila completa, incluso cuando solo se necesitan columnas específicas. Esto aumenta las operaciones de E/S, llevando a un rendimiento de consulta más lento en comparación con Parquet y ORC.
-- Simple SELECT query on Avro file in Hive
CREATE EXTERNAL TABLE avro_table
STORED AS AVRO
LOCATION 'gs://your-bucket/dataset.avro';
SELECT column1, column2 FROM avro_table;
- ORC: ORC mostró un rendimiento similar a Parquet, con una compresión un poco mejor y técnicas de almacenamiento optimizadas que mejoraron las velocidades de lectura. Los archivos ORC también son columnares, lo que los hace adecuados para consultas SELECT que solo recuperan columnas específicas.
# Simple SELECT query on ORC file
orc_df.select("column1", "column2").show()
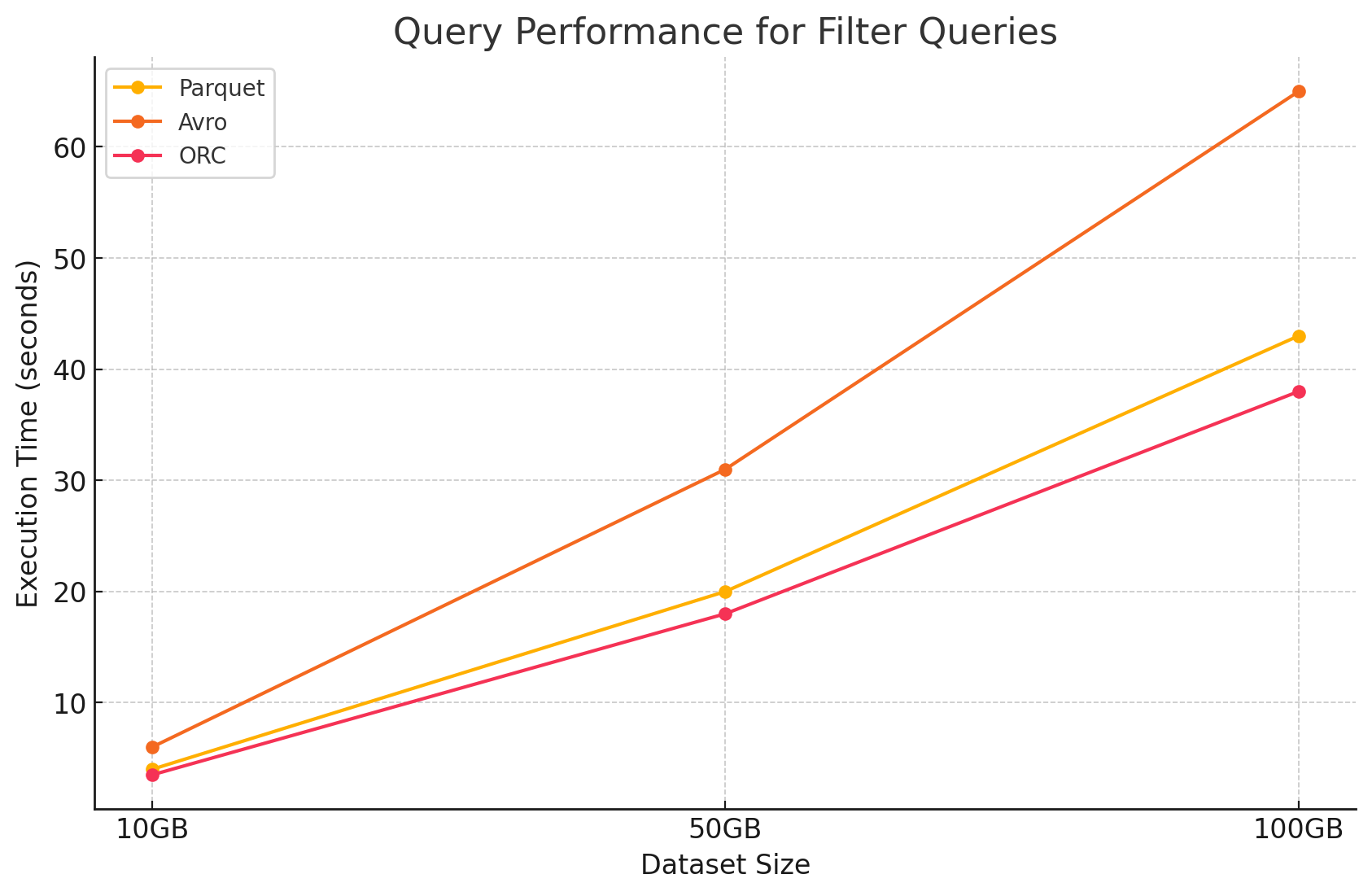
2. Consultas de filtrado
- Parquet: Parquet mantuvo su ventaja de rendimiento debido a su naturaleza en columnas y la capacidad para saltar columnas irrelevantes rápidamente. Sin embargo, el rendimiento fue ligeramente afectado por la necesidad de escanear más filas para aplicar filtros.
# Filter query on Parquet file
filtered_parquet_df = parquet_df.filter(parquet_df.column1 == 'some_value')
filtered_parquet_df.show()
- Avro:Se redujo ulteriormente la performance debido a la necesidad de leer filas enteras y aplicar filtros a través de todas las columnas, aumentando el tiempo de procesamiento.
-- Filter query on Avro file in Hive
SELECT * FROM avro_table WHERE column1 = 'some_value';
- ORC:Este superó ligeramente a Parquet en consultas de filtro debido a su característica de desplazamiento de predicado, que permite filtrar directamente a nivel de almacenamiento antes de que los datos se carguen en memoria.
# Filter query on ORC file
filtered_orc_df = orc_df.filter(orc_df.column1 == 'some_value')
filtered_orc_df.show()
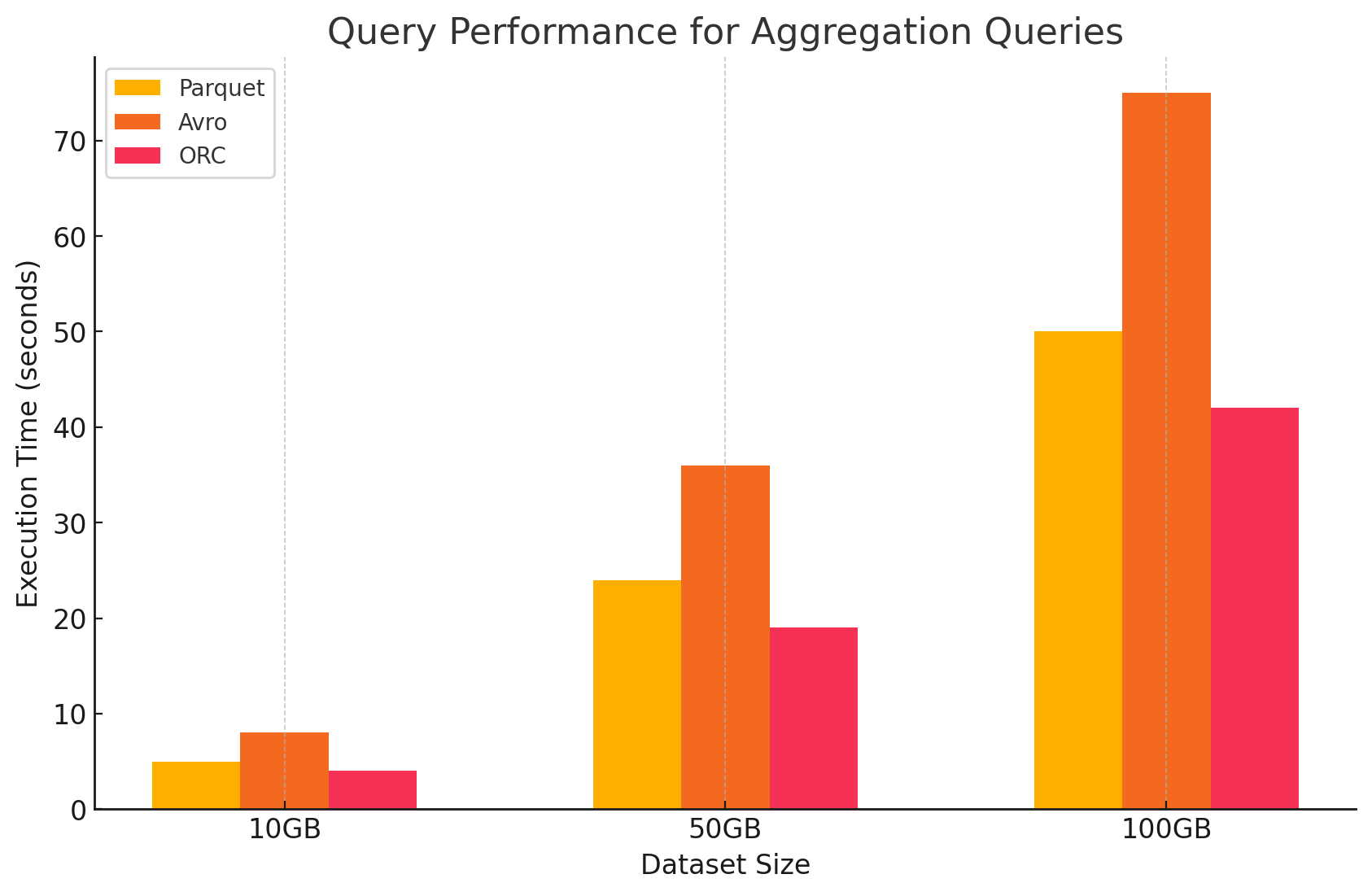
3. Consultas de Agrupación
- Parquet:Parquet tuvo un buen rendimiento, pero un poco menos eficiente que ORC. El formato columnar beneficia las operaciones de agrupación al acceder rápidamente a las columnas requeridas, pero Parquet carece de algunas optimizaciones integradas que ofrece ORC.
# Aggregation query on Parquet file
agg_parquet_df = parquet_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_parquet_df.show()
- Avro:Avro se retrasó debido a su almacenamiento basado en filas, que requiere explorar y procesar todas las columnas para cada fila, aumentando el sobrecarga computacional.
-- Aggregation query on Avro file in Hive
SELECT column1, SUM(column2), AVG(column3) FROM avro_table GROUP BY column1;
- ORC:ORC superó a ambos Parquet y Avro en consultas de agrupación. Las indexaciones avanzadas y los algoritmos de compresión integrados de ORC permitieron un acceso de datos más rápido y redujeron las operaciones de E/S, lo que lo hizo muy adecuado para tareas de agrupación.
# Aggregation query on ORC file
agg_orc_df = orc_df.groupBy("column1").agg({"column2": "sum", "column3": "avg"})
agg_orc_df.show()
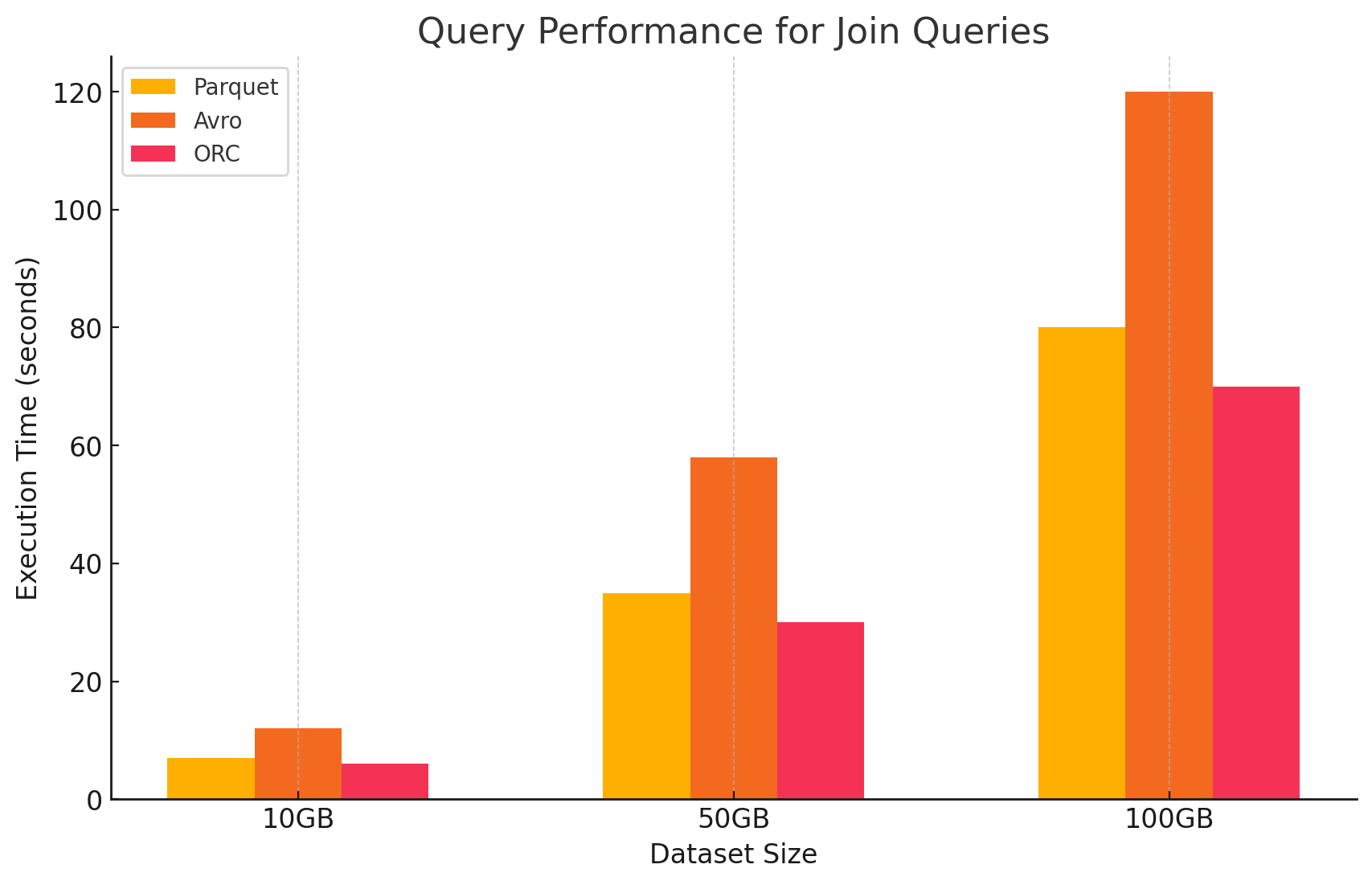
4. Consultas de Uniones
- Parquet:Parquet funcionó bien, pero no tan eficientemente como ORC en operaciones de unión debido a su menor optimización en la lectura de datos para condiciones de unión.
# Join query between Parquet and ORC files
joined_df = parquet_df.join(orc_df, parquet_df.key == orc_df.key)
joined_df.show()
- ORC:ORC destacó en consultas de uniones, beneficiándose de la indexación avanzada y las capacidades de desplazamiento de predicado, lo que minimizó la cantidad de datos explorados y procesados durante las operaciones de unión.
# Join query between two ORC files
joined_orc_df = orc_df.join(other_orc_df, orc_df.key == other_orc_df.key)
joined_orc_df.show()
- Avro: Avro tuvo dificultades considerables con operaciones de unión, principalmente debido al alto overhead de la lectura de filas completas y la falta de optimizaciones por columnas para las claves de unión.
-- Join query between Parquet and Avro files in Hive
SELECT a.column1, b.column2
FROM parquet_table a
JOIN avro_table b
ON a.key = b.key;
Impacto del Formato de Almacenamiento en los Costos
1. Eficiencia de Almacenamiento y Costo
- Parquet y ORC (formatos de almacenamiento columnar)
- Compresión y costo de almacenamiento:Tanto Parquet como ORC son formatos de almacenamiento columnar que ofrecen altas tasas de compresión, especialmente para conjuntos de datos con muchos valores repetidos o similares dentro de las columnas. Esta alta compresión reduce la tamaño de los datos totales, lo que a su vez reduce los costos de almacenamiento, particularmente en entornos en los que los costos de almacenamiento se facturan por GB.
- Idóneo para cargas de trabajo de análisis:Debido a su naturaleza columnar, estos formatos son ideales para cargas de trabajo de análisis donde solo se consultan columnas específicas con frecuencia. Esto significa que se leen menos datos del almacenamiento, reduciendo tanto las operaciones de E/S como los costos asociados.
- Avro (formato basado en filas)
- Compresión y costo de almacenamiento: Avro generalmente proporciona tasas de compresión más bajas que los formatos columnares como Parquet y ORC porque almacena los datos fila por fila. Esto puede llevar a mayores costos de almacenamiento, especialmente para grandes conjuntos de datos con muchas columnas, ya que se debe leer toda la fila, incluso si solo se necesitan unas pocas columnas.
- Mejor para cargas de trabajo con muchas escrituras: Aunque Avro puede resultar en mayores costos de almacenamiento debido a una menor compresión, es más adecuado para cargas de trabajo con muchas escrituras, donde los datos se escriben o se anexan continuamente. El costo asociado con el almacenamiento puede compensarse con las ganancias de eficiencia en la serialización y deserialización de datos.
2. Rendimiento y costo del procesamiento de datos
- Parquet y ORC (formatos columnares)
- Costes de procesamiento reducidos: Estos formatos están optimizados para operaciones con un elevado nivel de lecturas, lo que los hace altamente eficientes para consultar grandes conjuntos de datos. Dado que sólo permiten la lectura de las columnas relevantes necesarias para una consulta, reducen la cantidad de datos procesados. Esto conduce a un uso menor de la CPU y a tiempos de ejecución de consultas más rápidos, lo que puede reducir significativamente los costes computacionales en un entorno en el cloud donde los recursos de computación se facturan según el uso.
- Funciones avanzadas para la optimización de costes: ORC, en particular, incluye características como la desplazamiento de predicados y estadísticas integradas, que permiten a los motores de consulta saltar la lectura de datos innecesarios. Esto reduce ulteriormente las operaciones de E/S y mejora la eficiencia de las consultas, optimizando los costes.
- Avro (formatos basados en filas)
- Costos de procesamiento más altos: Dado que Avro es un formato basado en filas, generalmente requiere más operaciones de E/S para leer filas completas, incluso cuando solo se necesitan unas pocas columnas. Esto puede llevar a un aumento en los costos computacionales debido a un mayor uso de la CPU y a tiempos de ejecución de consultas más largos, especialmente en entornos con muchas lecturas.
- Eficiente para streaming y serialización: A pesar de los mayores costos de procesamiento en las consultas, Avro es adecuado para tareas de streaming y serialización, donde la velocidad de escritura rápida y la evolución de esquemas son más críticas.
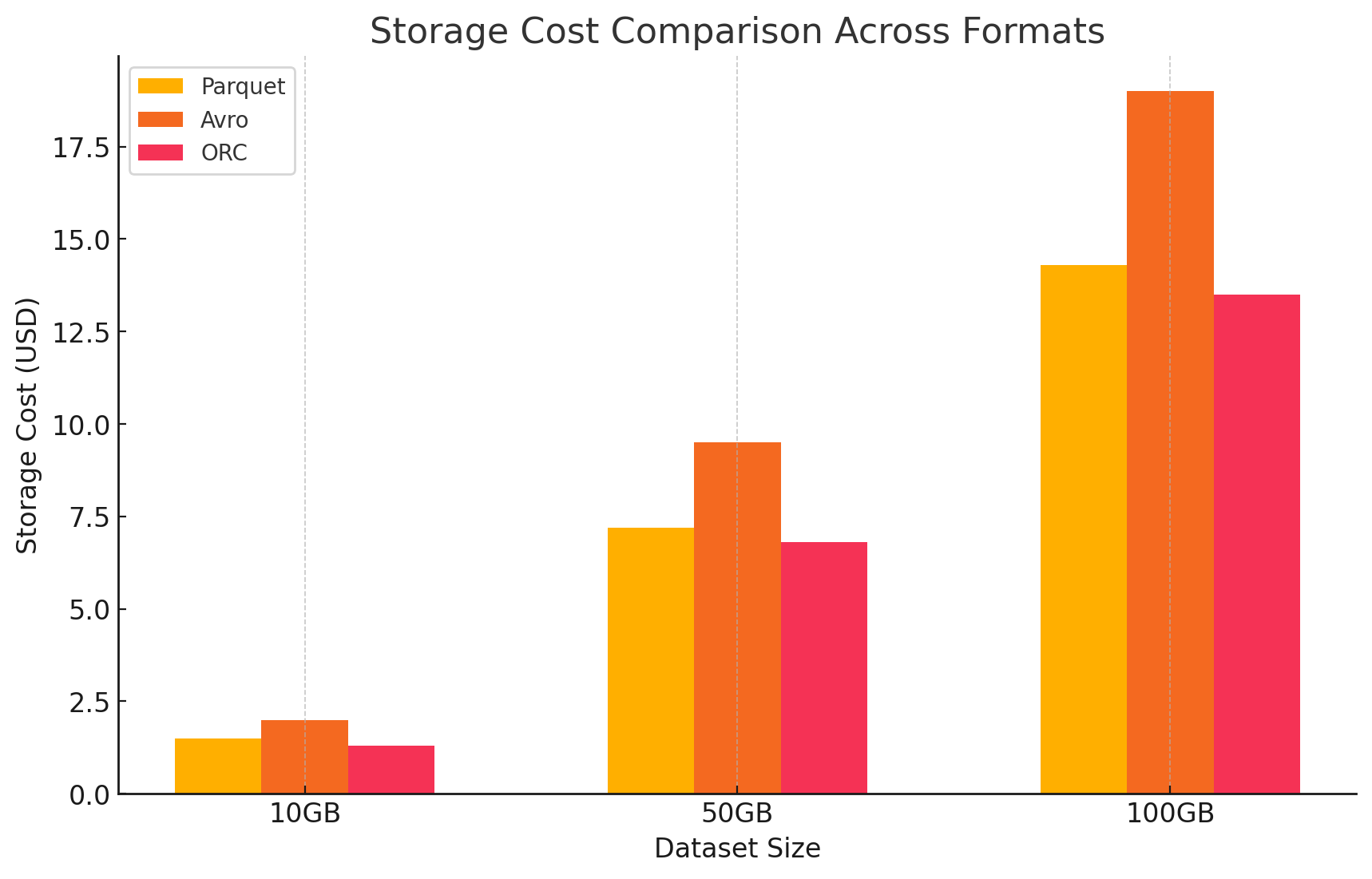
3. Análisis de costos con detalles de precios
- Para cuantificar el impacto de costo de cada formato de almacenamiento, realizamos un experimento usando GCP. Calculamos los costos asociados tanto con el almacenamiento como con el procesamiento de datos para cada formato, basándonos en los modelos de precios de GCP.
- Costos de almacenamiento de Google Cloud
- Costo de almacenamiento: Esto se calcula basado en la cantidad de datos almacenados en cada formato. GCP cobra por GB por mes para los datos almacenados en Google Cloud Storage. Las proporciones de compresión alcanzadas por cada formato impactan directamente estos costos. Los formatos columnares como Parquet y ORC típicamente tienen mejores proporciones de compresión que los formatos basados en filas como Avro, lo que resulta en costos de almacenamiento más bajos.
- Aquí hay un ejemplo de cómo se calculan los costos de almacenamiento:
- Parquet: La alta compresión redujo el tamaño de los datos, disminuyendo los costos de almacenamiento
- ORC: Similar a Parquet, la compresión avanzada de ORC también redujo efectivamente los costos de almacenamiento
- Avro: La eficiencia de compresión más baja llevó a mayores costos de almacenamiento en comparación con Parquet y ORC
# Example of how to save data back to Google Cloud Storage in different formats
# Save DataFrame as Parque
parquet_df.write.parquet("gs://your-bucket/output_parquet")
# Save DataFrame as Avro
avro_df.write.format("avro").save("gs://your-bucket/output_avro")
# Save DataFrame as ORC
orc_df.write.orc("gs://your-bucket/output_orc")
- Costos de procesamiento de datos
- Los costos de procesamiento de datos se calcularon basados en los recursos de cómputo requeridos para realizar varias consultas utilizando Dataproc en GCP. GCP cobra por el uso de Dataproc según el tamaño del clúster y la duración para la que se utilizan los recursos.
- Costos de cómputo:
- Parquet y ORC:Debido a su eficiente almacenamiento columnar, estos formatos redujeron la cantidad de datos leídos y procesados, lo que resultó en menores costos de procesamiento. Las tiempos de ejecución de consulta más rápidos también contribuyeron a los ahorros, especialmente para consultas complejas que implican grandes conjuntos de datos.
- Avro:Avro requería más recursos de cómputo debido a su formato basado en filas, lo que aumentó la cantidad de datos leídos y procesados. Esto resultó en mayores costos, particularmente para operaciones con un gran volumen de lecturas.
Conclusión
La elección del formato de almacenamiento en entornos de big data impacta significativamente tanto en el rendimiento de consultas como en los costos. La investigación y los experimentos mencionados demuestran los siguientes puntos clave:
- Parquet y ORC: Estos formatos de columnas proporcionan excelente compresión, lo que reduce los costos de almacenamiento. Su capacidad para leer eficientemente solo las columnas necesarias mejora notablemente el rendimiento de consultas y reduce los costos de procesamiento de datos. ORC supera levemente a Parquet en ciertos tipos de consultas debido a sus características de índice avanzadas y optimización, lo que lo hace una opción excelente para cargas de trabajo mixtas que requieren tanto un alto rendimiento de lectura como de escritura.
- Avro: Aunque Avro no es tan eficiente en términos de compresión y rendimiento de consulta como Parquet y ORC, destaca en casos de uso que requieren operaciones de escritura rápidas y evolución del esquema. Este formato es ideal para escenarios que incluyen serialización de datos y flujo de datos donde se priorizan el rendimiento de escritura y la flexibilidad en detrimento de la eficiencia en lectura.
- Eficiencia costosa: En un entorno en la nube como GCP, donde los costos están estrechamente relacionados con el uso de almacenamiento y cómputo, elegir el formato correcto puede llevar a ahorros significativos de costos. Para cargas de trabajo de análisis que son principalmente pesadas en lecturas, Parquet y ORC son las opciones más económicas. Para aplicaciones que requieren una ingestión de datos rápida y un manejo flexible del esquema, Avro es una opción adecuada a pesar de sus mayores costos de almacenamiento y cómputo.
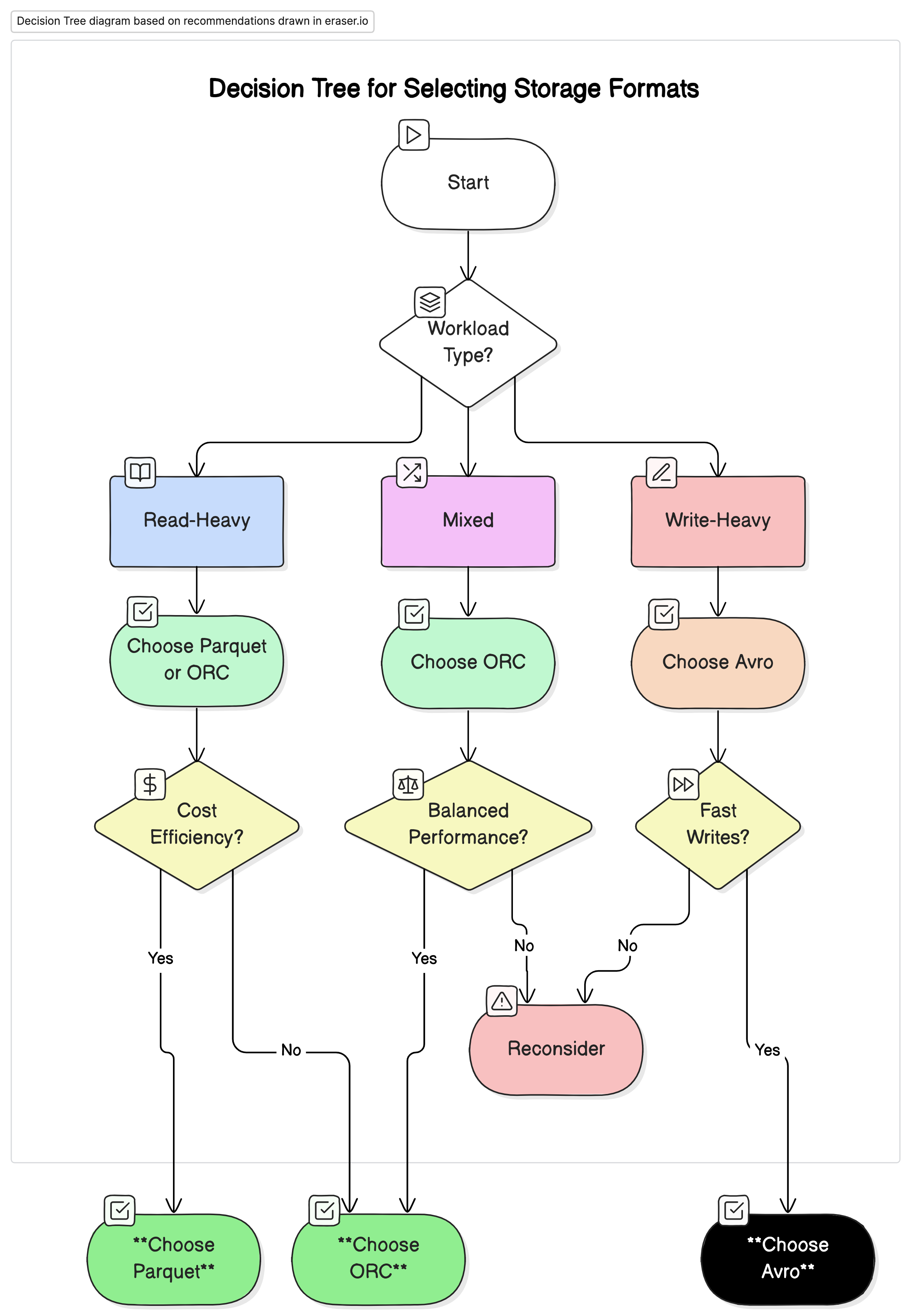
Recomendaciones
Basándonos en nuestro análisis, recomendamos lo siguiente:
- Para cargas de trabajo analíticas con un alto nivel de lectura: Utilice Parquet o ORC. Estos formatos ofrecen un rendimiento superior y una eficiencia de costo mejorada debido a su alta compresión y un mejor rendimiento de consulta optimizado.
- Para cargas de trabajo con un alto nivel de escritura y serialización: Utilice Avro. Es mejor adaptado para escenarios donde las escrituras rápidas y la evolución del esquema son críticas, como el flujo de datos y los sistemas de mensajería.
- Para cargas de trabajo mixtas: ORC ofrece un rendimiento balanceado tanto para operaciones de lectura como de escritura, lo que lo hace una opción ideal para entornos donde las cargas de trabajo de datos varían.
Pensamientos finales
Seleccionar el formato de almacenamiento correcto para entornos de grandes datos es crucial para optimizar tanto el rendimiento como el costo. Comprender las fortalezas y debilidades de cada formato permite a los ingenieros de datos personalizar su arquitectura de datos a casos de uso específicos, maximizando la eficiencia y minimizando los gastos. Con el continuo crecimiento de los volúmenes de datos, tomar decisiones informadas sobre los formatos de almacenamiento se convertirá cada vez en más importante para mantener soluciones de datos escalables y eficientes.
Mediante una evaluación cuidadosa de las métricas de rendimiento y las implicaciones de costo presentadas en este artículo, las organizaciones pueden elegir el formato de almacenamiento que mejor se ajuste a sus necesidades operacionales y objetivos financieros.
Source:
https://dzone.com/articles/performance-and-cost-implications-parquet-avro-orc